参考文档:
详解HBase架构原理 - Steven.Chow - 博客园
Hbase原理、基本概念、基本架构 - 飞鱼德蒙 - 博客园
05. HBase WAL解析
HBase学习之路 (七)HBase 原理
基本信息:HBase在Hadoop之上提供了类似于Bigtable的能力,实时读写的分布式数据库
HBase原理:
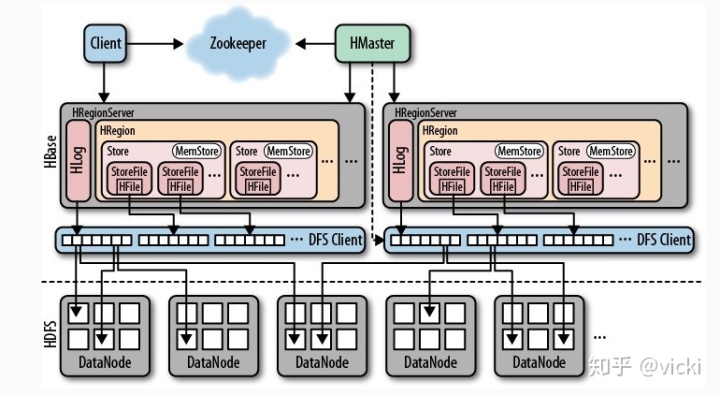
HBase内部组件:
client---客户端包含了访问Hbase的接口,同时在缓存中维护着已经访问过的Region的位置信息,用来加快后续数据访问的过程
zookeeper--1.Zookeeper可以帮助选举出一个master作为集群的总管,并保证在任何时刻总有唯一一个master在运行,这就避免master的“单点失效”问题;2.Zookeeper会实时监测每个Region服务端的状态,当某个Region服务器发生故障时,Zookeeper会通知Master;3.存储所有Region的寻址入口
master---1.Region server分配region;2.发现失效的Region server并重新分配其上的region;3.HDFS上的垃圾文件回收
分片服务器---1.Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求;2.负责切分正在运行过程中变的过大的region;3.一个服务器上有多个分片
分片---1.table在行的方向上分隔为多个Region;2.不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上
Hlog---用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。
store---每一个region由一个或多个store组成
StoreFile--memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存
问题:
数据热点问题产生原因:在HBase中,表会被划分为1...n个Region,被托管在RegionServer中。
Region二个重要的属性:StartKey与EndKey表示这个Region维护的rowKey范围,当我们要读/写数据时,如果rowKey落在某个start-end key范围内,那么就会定位到目标region并且读/写到相关的数据
数据库表部分rowkey规则不合理,某个时间段的数据都被分配到同一个Region服务器,导致该服务器请求过大超过其负荷
Region规划不合理,表均加了32个盐导致Region数量过多,分片过多影响HBase读写效率
Hbase监听后台:Ambari
基本操作命令:put写 get读 delete删除 scan扫描
命令行进入案例:
参考:https://blog.csdn.net/m0_37809146/article/details/91128061
$klist---查看当前用户是否有操作HBase权限,如果没有使用kinit登录
$kinit ceshi_user
$klist--有权限治好进入HBase命令行
hbase(main)..>list ----查询所有表
hbase(main)..>desc ‘表名’---查看表基本信息
hbase(main)..>put ‘表名’, ‘行键’,‘列族:列’,‘值’---新增(修改)列值
hbase(main)..> get '表明','rowkey’ ---获取指定行中所有列的数据信息
最后
以上就是跳跃樱桃最近收集整理的关于hbase 修改表名_HBase个人总结的全部内容,更多相关hbase内容请搜索靠谱客的其他文章。








发表评论 取消回复