我是靠谱客的博主 忧郁豆芽,这篇文章主要介绍美团在Redis上踩过的一些坑-4.redis内存使用优化转载请注明出处哈:http://carlosfu.iteye.com/blog/2254154 ,现在分享给大家,希望可以做个参考。
转载请注明出处哈:http://carlosfu.iteye.com/blog/2254154
一、背景: 选择合适的使用场景
很多时候Redis被误解并乱用了,造成的Redis印象:耗内存、价格成本很高:
1. 为了“赶时髦”或者对于Mysql的“误解”在一个并发量很低的系统使用Redis,将原来放在Mysql数据全部放在Redis中。
----(Redis比较适用于高并发系统,如果是一些复杂Mis系统,用Redis反而麻烦,因为单从功能讲Mysql要更为强大,而且Mysql的性能其实已经足够了。)
2. 觉得Redis就是个KV缓存
-----(Redis支持多数据结构,并且具有很多其他丰富的功能)
3. 喜欢做各种对比,比如Mysql, Hbase, Redis等等
-----(每种数据库都有自己的使用场景,比如Hbase吧,我们系统的个性化数据有1T,此时放在Redis根本就不合适,而是将一些热点数据放在Redis)
总之就是在合适的场景,选择合适的数据库产品。
附赠两个名言:
Evan Weaver, Twitter, March 2009 写道
Everything runs from memory in Web 2.0!
Tim Gray 写道
Tape is Dead, Disk is Tape, Flash is Disk, RAM Locality is king.
(磁带已死,磁盘是新磁带,闪存是新磁盘,随机存储器局部性是为王道)
(磁带已死,磁盘是新磁带,闪存是新磁盘,随机存储器局部性是为王道)
二、一次string转化为hash的优化
1. 场景:
用户id: userId,
用户微博数量:weiboCount
| userId(用户id) | weiboCount(微博数) |
| 1 | 2000 |
| 2 | 10 |
| 3 | 288 |
| .... | ... |
| 1000000 | 1000 |
2. 实现方法:
(1) 使用Redis字符串数据结构, userId为key, weiboCount作为Value
(2) 使用Redis哈希结构,hashkey只有一个, key="allUserWeiboCount",field=userId,fieldValue= weiboCount
(3) 使用Redis哈希结构, hashkey为多个, key=userId/100, field=userId%100, fieldValue= weiboCount
前两种比较容易理解,第三种方案解释一下:每个hashKey存放100个hash-kv,field=userId%100,也就是
| userId | hashKey | field |
| 1 | 0 | 1 |
| 2 | 0 | 2 |
| 3 | 0 | 3 |
| ... | .... | ... |
| 99 | 0 | 99 |
| 100 | 1 | 0 |
| 101 | 1 | 1 |
| .... | ... | ... |
| 9999 | 99 | 99 |
| 100000 | 1000 | 0 |
注意:
为了排除共享对象的问题,在真实测试时候所有key,field,value都用字符串类型。
3. 获取方法:
#获取userId=5003用户的微博数
(1) get u:5003
(2) hget allUser u:5003
(3) hget u:50 f:3
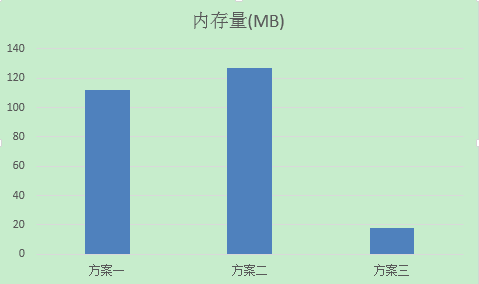
4. 内存占用量对比(100万用户 userId u:1~u:1000000)
#方法一 Memory
used_memory:118002640
used_memory_human:112.54M
used_memory_rss:127504384
used_memory_peak:118002640
used_memory_peak_human:112.54M
used_memory_lua:36864
mem_fragmentation_ratio:1.08
mem_allocator:jemalloc-3.6.0
---------------------------------------------------
#方法二 Memory
used_memory:134002968
used_memory_human:127.80M
used_memory_rss:144261120
used_memory_peak:134002968
used_memory_peak_human:127.80M
used_memory_lua:36864
mem_fragmentation_ratio:1.08
mem_allocator:jemalloc-3.6.0
--------------------------------------------------------
#方法三 Memory
used_memory:19249088
used_memory_human:18.36M
used_memory_rss:26558464
used_memory_peak:134002968
used_memory_peak_human:127.80M
used_memory_lua:36864
mem_fragmentation_ratio:1.38
mem_allocator:jemalloc-3.6.0
那么为什么第三种能少那么多内存呢?之前有人说用了共享对象的原因,现在我将key,field,value全部都变成了字符串,仍然还是节约很多内存。
之前我也怀疑过是hashkey,field的字节数少造成的,但是我们下面通过一个实验看就清楚是为什么了。当我将hash-max-ziplist-entries设置为2并且重启后,所有的hashkey都变为了hashtable编码。
同时我们看到了内存从18.36M变为了122.30M,变化还是很大的。
127.0.0.1:8000> object encoding u:8417
"ziplist"
127.0.0.1:8000> config set hash-max-ziplist-entries 2
OK
127.0.0.1:8000> debug reload
OK
(1.08s)
127.0.0.1:8000> config get hash-max-ziplist-entries
1) "hash-max-ziplist-entries"
2) "2"
127.0.0.1:8000> info memory
# Memory
used_memory:128241008
used_memory_human:122.30M
used_memory_rss:137662464
used_memory_peak:134002968
used_memory_peak_human:127.80M
used_memory_lua:36864
mem_fragmentation_ratio:1.07
mem_allocator:jemalloc-3.6.0
127.0.0.1:8000> object encoding u:8417
"hashtable"
内存使用量:
5. 导入数据代码(不考虑代码优雅性,单纯为了测试,勿喷)
注意:
为了排除共享对象的问题,这里所有key,field,value都用字符串类型。
package com.carlosfu.redis;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import org.junit.Test;
import redis.clients.jedis.Jedis;
/**
* 一次string-hash优化
*
* @author carlosfu
* @Date 2015-11-8
* @Time 下午7:27:45
*/
public class TestRedisMemoryOptimize {
private final static int TOTAL_USER_COUNT = 1000000;
private final static String HOST = "127.0.0.1";
private final static int PORT = 6379;
/**
* 纯字符串
*/
@Test
public void testString() {
int mBatchSize = 2000;
Jedis jedis = null;
try {
jedis = new Jedis(HOST, PORT);
List<String> kvsList = new ArrayList<String>(mBatchSize);
for (int i = 1; i <= TOTAL_USER_COUNT; i++) {
String key = "u:" + i;
kvsList.add(key);
String value = "v:" + i;
kvsList.add(value);
if (i % mBatchSize == 0) {
System.out.println(i);
jedis.mset(kvsList.toArray(new String[kvsList.size()]));
kvsList = new ArrayList<String>(mBatchSize);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
}
}
/**
* 纯hash
*/
@Test
public void testHash() {
int mBatchSize = 2000;
String hashKey = "allUser";
Jedis jedis = null;
try {
jedis = new Jedis(HOST, PORT);
Map<String, String> kvMap = new HashMap<String, String>();
for (int i = 1; i <= TOTAL_USER_COUNT; i++) {
String key = "u:" + i;
String value = "v:" + i;
kvMap.put(key, value);
if (i % mBatchSize == 0) {
System.out.println(i);
jedis.hmset(hashKey, kvMap);
kvMap = new HashMap<String, String>();
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
}
}
/**
* segment hash
*/
@Test
public void testSegmentHash() {
int segment = 100;
Jedis jedis = null;
try {
jedis = new Jedis(HOST, PORT);
Map<String, String> kvMap = new HashMap<String, String>();
for (int i = 1; i <= TOTAL_USER_COUNT; i++) {
String key = "f:" + String.valueOf(i % segment);
String value = "v:" + i;
kvMap.put(key, value);
if (i % segment == 0) {
System.out.println(i);
int hash = (i - 1) / segment;
jedis.hmset("u:" + String.valueOf(hash), kvMap);
kvMap = new HashMap<String, String>();
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}
三、结果对比
redis核心对象 数据类型 + 编码方式 + ptr 分段hash也不会造成drift
| 方案 | 优点 | 缺点 |
| string | 直观、容易理解 |
|
| hash | 直观、容易理解、整合整体 |
|
| segment-hash | 内存占用量小,虽然理解不够直观,但是总体上是最优的。 | 理解不够直观。 |
四、结论:
在使用Redis时,要选择合理的数据结构解决实际问题,那样既可以提高效率又可以节省内存。所以此次优化方案三为最佳。
附图一张:redis其实是一把瑞士军刀:

最后
以上就是忧郁豆芽最近收集整理的关于美团在Redis上踩过的一些坑-4.redis内存使用优化转载请注明出处哈:http://carlosfu.iteye.com/blog/2254154 的全部内容,更多相关美团在Redis上踩过的一些坑-4.redis内存使用优化转载请注明出处哈:http://carlosfu.iteye.com/blog/2254154 内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复