案例:android 源码,c++ 的测试程序frameworksbasemediatestsaudiotestsshared_mem_test.cpp 共享内存测试
JAVA层AudioTrack 测试程序:
frameworksbasemediatestsMediaFrameworkTestsrccomandroidmediaframeworktestfunctionalaudioMediaAudioTrackTest.java
一、AudioTrack
AudioTrack 在使用的时候都会传入一些声音的属性。
AudioTrack 建过程的主要工作:
b.1 使用AudioTrack的属性, 根据AudioPolicy找到对应的output、playbackThread
b.2 在playbackThread中创建对应的track,建立与AudioTrack 的共享内存
根据AudioPolicy找到对应的output :
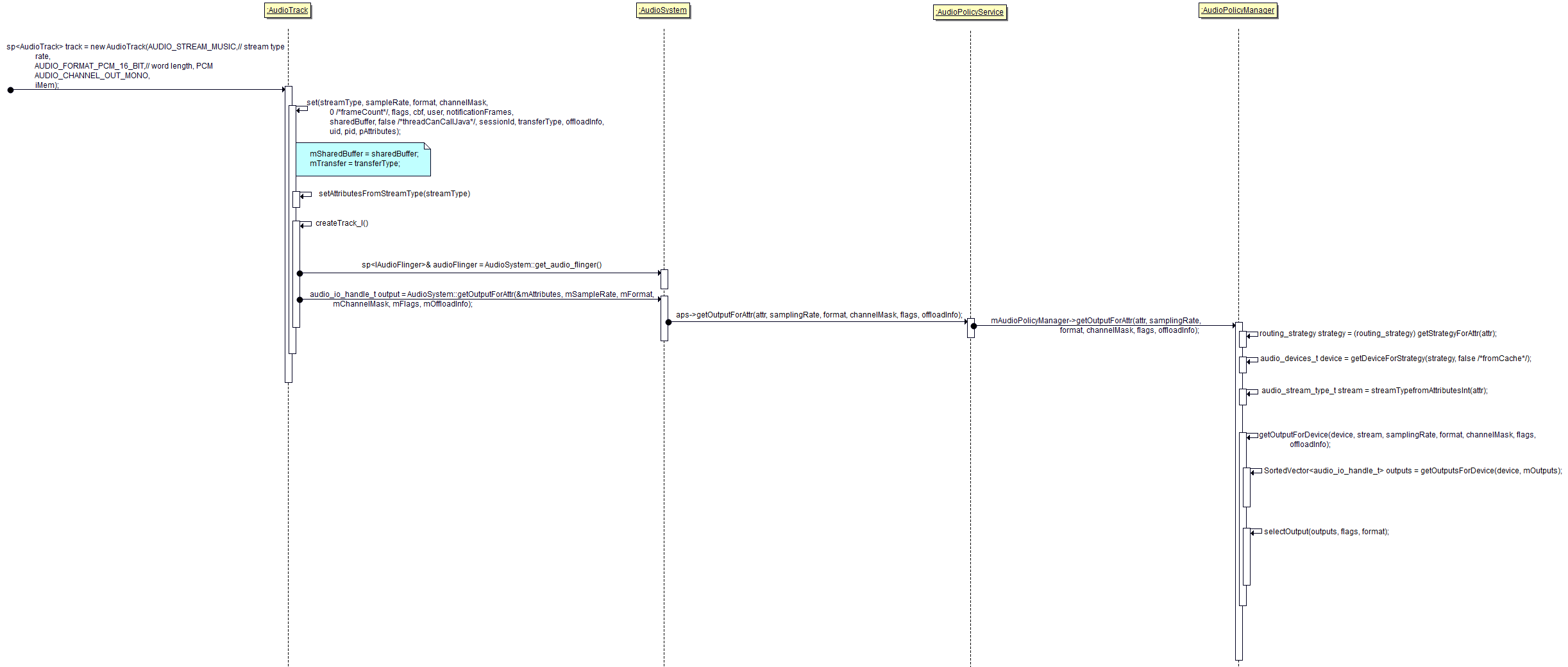
根据UML 图可以看出 ,选择一个output流程:
a. APP构造AudioTrack时指定了 stream type
b. AudioTrack::setAttributesFromStreamType 根据设置下来的StreamType设置属性
void AudioTrack::setAttributesFromStreamType(audio_stream_type_t streamType) {
mAttributes.flags = 0x0;
switch(streamType) {
case AUDIO_STREAM_DEFAULT:
case AUDIO_STREAM_MUSIC:
mAttributes.content_type = AUDIO_CONTENT_TYPE_MUSIC;
mAttributes.usage = AUDIO_USAGE_MEDIA;
break;
case AUDIO_STREAM_VOICE_CALL:
mAttributes.content_type = AUDIO_CONTENT_TYPE_SPEECH;
mAttributes.usage = AUDIO_USAGE_VOICE_COMMUNICATION;
break;
case AUDIO_STREAM_ENFORCED_AUDIBLE:
mAttributes.flags |= AUDIO_FLAG_AUDIBILITY_ENFORCED;
// intended fall through, attributes in common with STREAM_SYSTEM
case AUDIO_STREAM_SYSTEM:
mAttributes.content_type = AUDIO_CONTENT_TYPE_SONIFICATION;
mAttributes.usage = AUDIO_USAGE_ASSISTANCE_SONIFICATION;
break;
case AUDIO_STREAM_RING:
mAttributes.content_type = AUDIO_CONTENT_TYPE_SONIFICATION;
mAttributes.usage = AUDIO_USAGE_NOTIFICATION_TELEPHONY_RINGTONE;
break;
case AUDIO_STREAM_ALARM:
mAttributes.content_type = AUDIO_CONTENT_TYPE_SONIFICATION;
mAttributes.usage = AUDIO_USAGE_ALARM;
break;
case AUDIO_STREAM_NOTIFICATION:
mAttributes.content_type = AUDIO_CONTENT_TYPE_SONIFICATION;
mAttributes.usage = AUDIO_USAGE_NOTIFICATION;
break;
case AUDIO_STREAM_BLUETOOTH_SCO:
mAttributes.content_type = AUDIO_CONTENT_TYPE_SPEECH;
mAttributes.usage = AUDIO_USAGE_VOICE_COMMUNICATION;
mAttributes.flags |= AUDIO_FLAG_SCO;
break;
case AUDIO_STREAM_DTMF:
mAttributes.content_type = AUDIO_CONTENT_TYPE_SONIFICATION;
mAttributes.usage = AUDIO_USAGE_VOICE_COMMUNICATION_SIGNALLING;
break;
case AUDIO_STREAM_TTS:
mAttributes.content_type = AUDIO_CONTENT_TYPE_SPEECH;
mAttributes.usage = AUDIO_USAGE_ASSISTANCE_ACCESSIBILITY;
break;
default:
ALOGE("invalid stream type %d when converting to attributes", streamType);
}
}
c. AudioPolicyManager::getStrategyForAttr 再根据属性获取声音的Strategy,Strategy就是声音的类别。
uint32_t AudioPolicyManager::getStrategyForAttr(const audio_attributes_t *attr) {
// flags to strategy mapping
if ((attr->flags & AUDIO_FLAG_AUDIBILITY_ENFORCED) == AUDIO_FLAG_AUDIBILITY_ENFORCED) {
return (uint32_t) STRATEGY_ENFORCED_AUDIBLE;
}
// usage to strategy mapping
switch (attr->usage) {
case AUDIO_USAGE_MEDIA:
case AUDIO_USAGE_GAME:
case AUDIO_USAGE_ASSISTANCE_ACCESSIBILITY:
case AUDIO_USAGE_ASSISTANCE_NAVIGATION_GUIDANCE:
case AUDIO_USAGE_ASSISTANCE_SONIFICATION:
return (uint32_t) STRATEGY_MEDIA;
case AUDIO_USAGE_VOICE_COMMUNICATION:
return (uint32_t) STRATEGY_PHONE;
case AUDIO_USAGE_VOICE_COMMUNICATION_SIGNALLING:
return (uint32_t) STRATEGY_DTMF;
case AUDIO_USAGE_ALARM:
case AUDIO_USAGE_NOTIFICATION_TELEPHONY_RINGTONE:
return (uint32_t) STRATEGY_SONIFICATION;
case AUDIO_USAGE_NOTIFICATION:
case AUDIO_USAGE_NOTIFICATION_COMMUNICATION_REQUEST:
case AUDIO_USAGE_NOTIFICATION_COMMUNICATION_INSTANT:
case AUDIO_USAGE_NOTIFICATION_COMMUNICATION_DELAYED:
case AUDIO_USAGE_NOTIFICATION_EVENT:
return (uint32_t) STRATEGY_SONIFICATION_RESPECTFUL;
case AUDIO_USAGE_UNKNOWN:
default:
return (uint32_t) STRATEGY_MEDIA;
}
}
d. AudioPolicyManager::getDeviceForStrategy 再根据声音的类别,来获取从那个Device播放,这个选着过程就是根据一定的优先级从可用的availableOutputDeviceTypes 列表中,选出可用的device。
audio_devices_t AudioPolicyManager::getDeviceForStrategy(routing_strategy strategy,
bool fromCache)
{
uint32_t device = AUDIO_DEVICE_NONE;
......
audio_devices_t availableOutputDeviceTypes = mAvailableOutputDevices.types();
switch (strategy) {
.......
case STRATEGY_SONIFICATION_RESPECTFUL:
.......
break;
.....
case STRATEGY_DTMF:
if (!isInCall()) {
// when off call, DTMF strategy follows the same rules as MEDIA strategy
device = getDeviceForStrategy(STRATEGY_MEDIA, false /*fromCache*/);
break;
}
// when in call, DTMF and PHONE strategies follow the same rules
// FALL THROUGH
...
}
return device;
}
e. AudioPolicyManager::getOutputForDevice 最后根据Device 获取output
e.1 AudioPolicyManager::getOutputsForDevice
e.2 output = selectOutput(outputs, flags, format);也许会有多个output支持一个Device ,那么就从中选取一个output用来输出
在AudioPolicyManager里面定义了一个mOutputs变量如下:表示已打开的output。
// list of descriptors for outputs currently opened
DefaultKeyedVector<audio_io_handle_t, sp<AudioOutputDescriptor> > mOutputs;从定义可以看出每一个output都有一个AudioOutputDescriptor,每一个AudioOutputDescriptor里面都定义有一个 const sp<IOProfile> mProfile; mProfile就是来自于配置文件(/system/etc/audio_policy.conf)里面的对应的output的参数。
所以当我们调用到getOutputsForDevice这一步时,可以看到他的参数是,device 当前音频流的配置,和mOutputs。然后在mOutputs里面的每一个output去看是否能找到这device,如果找到,就添加到outputs返回去,这说明,可能找到多个符合这条音频流的output,所以才有 selectOutput(outputs, flags, format) 这一步。
SortedVector<audio_io_handle_t> outputs = getOutputsForDevice(device, mOutputs);
SortedVector<audio_io_handle_t> AudioPolicyManager::getOutputsForDevice(audio_devices_t device,
DefaultKeyedVector<audio_io_handle_t, sp<AudioOutputDescriptor> > openOutputs)
{
SortedVector<audio_io_handle_t> outputs;
ALOGVV("getOutputsForDevice() device %04x", device);
for (size_t i = 0; i < openOutputs.size(); i++) {
ALOGVV("output %d isDuplicated=%d device=%04x",
i, openOutputs.valueAt(i)->isDuplicated(), openOutputs.valueAt(i)->supportedDevices());
if ((device & openOutputs.valueAt(i)->supportedDevices()) == device) {
ALOGVV("getOutputsForDevice() found output %d", openOutputs.keyAt(i));
outputs.add(openOutputs.keyAt(i));
}
}
return outputs;
}selectOutput 函数怎么从多个outputs里面选择出最正确的那一个output呢?
a.APP创建AudioTrack的时候会传入flag
b.output 对应的profile(/system/etc/audio_policy.conf)中也有flag。
c.使用a,b 中作比较,取出bit数最高的(吻合度最高)的output
d.c 步选出多个output,那么primary output 支持,那么就选这个output
f .否者就选多个中的第一个。
audio_io_handle_t AudioPolicyManager::selectOutput(const SortedVector<audio_io_handle_t>& outputs,
audio_output_flags_t flags,
audio_format_t format)
{
// select one output among several that provide a path to a particular device or set of
// devices (the list was previously build by getOutputsForDevice()).
// The priority is as follows:
// 1: the output with the highest number of requested policy flags
// 2: the primary output
// 3: the first output in the list
if (outputs.size() == 0) {
return 0;
}
if (outputs.size() == 1) {
return outputs[0];
}
int maxCommonFlags = 0;
audio_io_handle_t outputFlags = 0;
audio_io_handle_t outputPrimary = 0;
for (size_t i = 0; i < outputs.size(); i++) {
sp<AudioOutputDescriptor> outputDesc = mOutputs.valueFor(outputs[i]);
if (!outputDesc->isDuplicated()) {
// if a valid format is specified, skip output if not compatible
if (format != AUDIO_FORMAT_INVALID) {
if (outputDesc->mFlags & AUDIO_OUTPUT_FLAG_DIRECT) {
if (format != outputDesc->mFormat) {
continue;
}
} else if (!audio_is_linear_pcm(format)) {
continue;
}
}
int commonFlags = popcount(outputDesc->mProfile->mFlags & flags);
if (commonFlags > maxCommonFlags) {
outputFlags = outputs[i];
maxCommonFlags = commonFlags;
ALOGV("selectOutput() commonFlags for output %d, %04x", outputs[i], commonFlags);
}
if (outputDesc->mProfile->mFlags & AUDIO_OUTPUT_FLAG_PRIMARY) {
outputPrimary = outputs[i];
}
}
}
if (outputFlags != 0) {
return outputFlags;
}
if (outputPrimary != 0) {
return outputPrimary;
}
return outputs[0];
}
找到对应的 playbackThread,并且创建track建立共享内存。
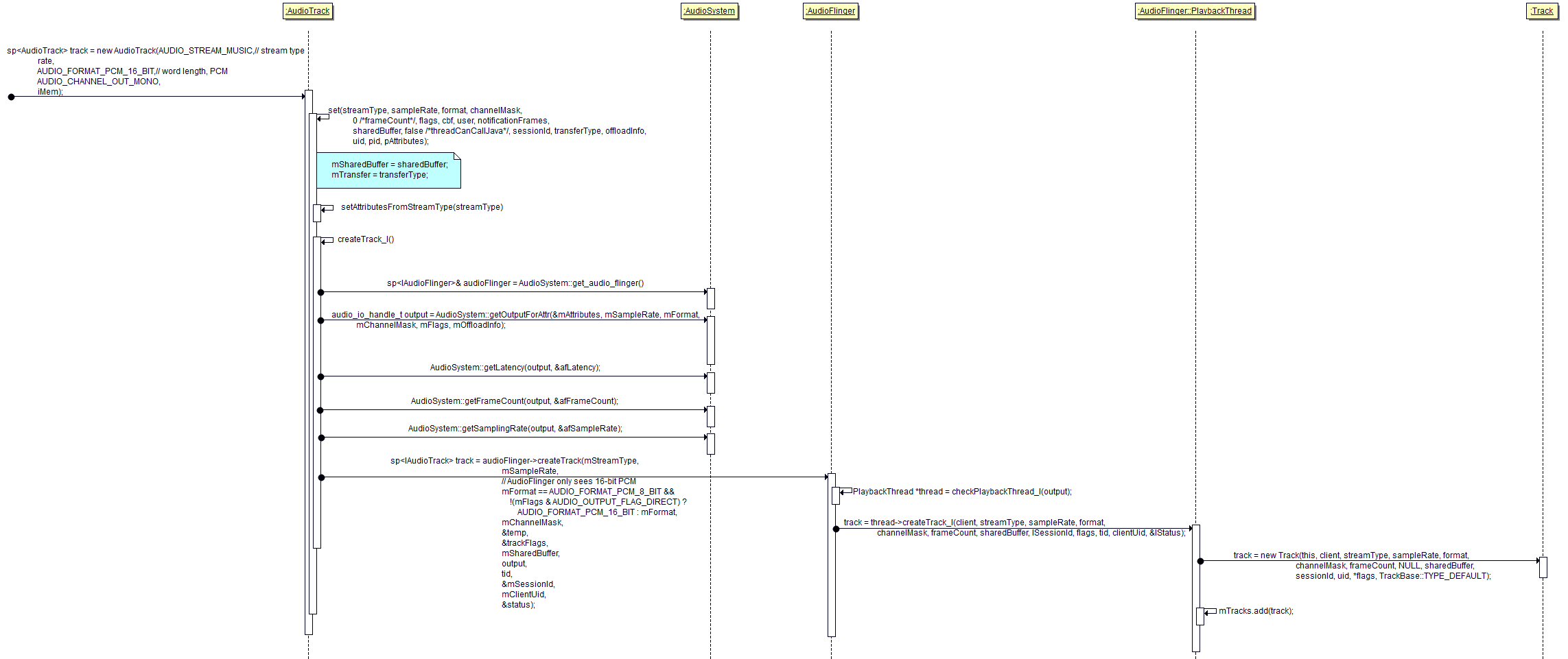
共享内存的分配:
每一个AudioTrack都对应了一个track。他们之间存在一块共享内存,APP可以直接访问块内存,PlaybackThread也可访问这块内存
APP给AudioTrack 音频数据有两种方式:一次性提供(MODE_STATIC)、边播放边提供(MODE_STREAM)
先看一下AudioTrack 和 Track 之间的数据流向框图:
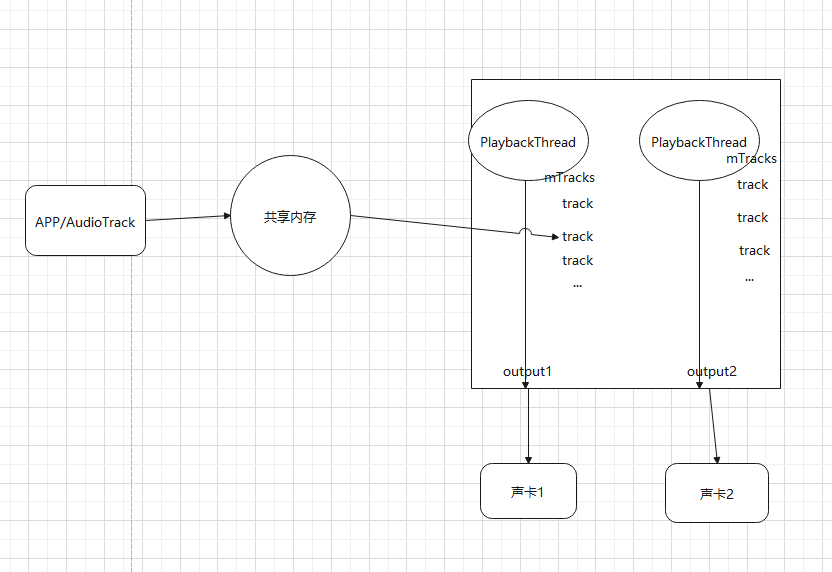
1、音频数据存在于buffer中,这个buffer是有谁创建?
MODE_STATIC:
由 APP 创建共享内存,因为APP知道数据的大小。
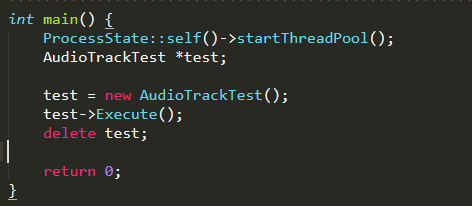
看一下之前C++demo 里面的frameworksbasemediatestsaudiotestsshared_mem_test.cpp new AudioTrack时:直接把共享内存的地址传递下去了。只要传了这个地址,他就知道你是要用MODE_STATIC这种形式进行传递。
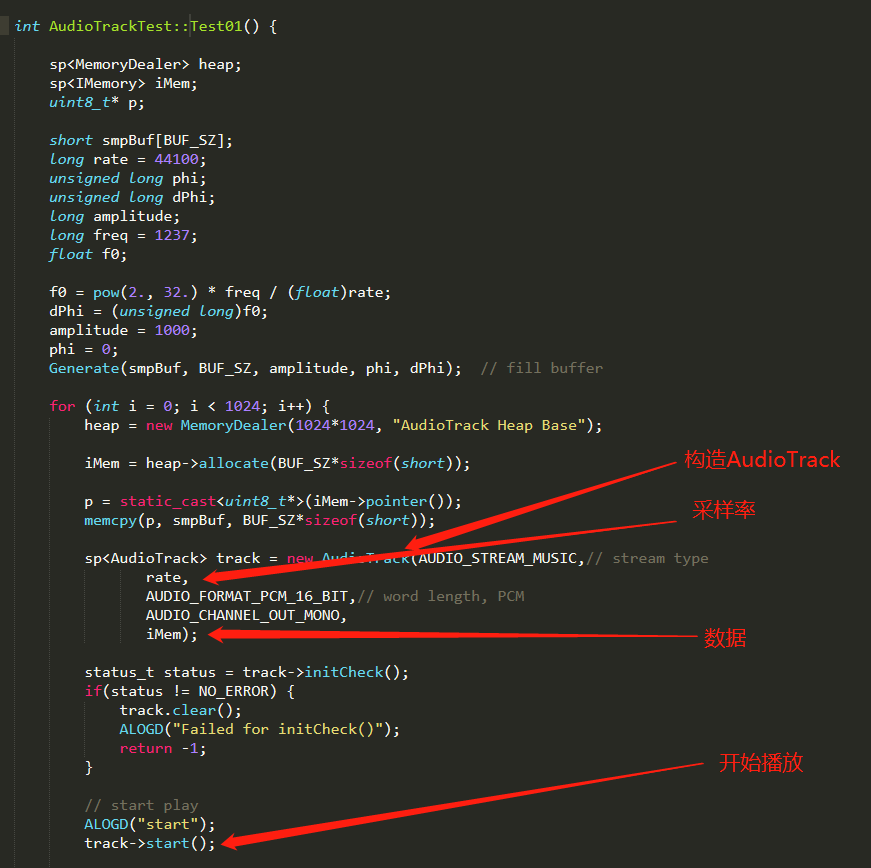
int AudioTrackTest::Test01() {
sp<MemoryDealer> heap;
sp<IMemory> iMem;
uint8_t* p;
....
Generate(smpBuf, BUF_SZ, amplitude, phi, dPhi); // fill buffer
for (int i = 0; i < 1024; i++) {
heap = new MemoryDealer(1024*1024, "AudioTrack Heap Base");
iMem = heap->allocate(BUF_SZ*sizeof(short));
p = static_cast<uint8_t*>(iMem->pointer());
memcpy(p, smpBuf, BUF_SZ*sizeof(short));
sp<AudioTrack> track = new AudioTrack(AUDIO_STREAM_MUSIC,// stream type
rate,
AUDIO_FORMAT_PCM_16_BIT,// word length, PCM
AUDIO_CHANNEL_OUT_MONO,
iMem);//直接把共享内存的地址传下去了
...
}
...
track->start();
}
return 0;
}
MODE_STREAM:
由PlaybackThread创建共享内存,方便APP使用。我么看一下java层创建 AudioTrack ,他可以在构造函数里面指定是MODE_STREAM还是MODE_STATIC
@LargeTest
public void testPlaybackHeadPositionAfterInit() throws Exception {
// constants for test
final String TEST_NAME = "testPlaybackHeadPositionAfterInit";
final int TEST_SR = 22050;
final int TEST_CONF = AudioFormat.CHANNEL_OUT_STEREO;
final int TEST_FORMAT = AudioFormat.ENCODING_PCM_16BIT;
final int TEST_MODE = AudioTrack.MODE_STREAM;
final int TEST_STREAM_TYPE = AudioManager.STREAM_MUSIC;
//-------- initialization --------------
AudioTrack track = new AudioTrack(TEST_STREAM_TYPE, TEST_SR, TEST_CONF, TEST_FORMAT,
AudioTrack.getMinBufferSize(TEST_SR, TEST_CONF, TEST_FORMAT), TEST_MODE);
//-------- test --------------
assumeTrue(TEST_NAME, track.getState() == AudioTrack.STATE_INITIALIZED);
assertTrue(TEST_NAME, track.getPlaybackHeadPosition() == 0);
//-------- tear down --------------
track.release();
}在java里面new AudioTrack 会跑到AudioTrack.java里面,然后调用native_setup 函数,里面的mDataLoadMode就是模式
public AudioTrack(AudioAttributes attributes, AudioFormat format, int bufferSizeInBytes,
int mode, int sessionId)
{
......
audioParamCheck(rate, channelMask, encoding, mode);
......
// native initialization
int initResult = native_setup(new WeakReference<AudioTrack>(this), mAttributes,
mSampleRate, mChannels, mAudioFormat,
mNativeBufferSizeInBytes, mDataLoadMode, session);
.......
if (mDataLoadMode == MODE_STATIC) {
mState = STATE_NO_STATIC_DATA;
} else {
mState = STATE_INITIALIZED;
}
}接下来会跑到android_media_AudioTrack.cpp 的android_media_AudioTrack_setup函数:进行判断是否需要在应用侧创建地址。
static jint
android_media_AudioTrack_setup(JNIEnv *env, jobject thiz, jobject weak_this,
jobject jaa,
jint sampleRateInHertz, jint javaChannelMask,
jint audioFormat, jint buffSizeInBytes, jint memoryMode, jintArray jSession) {
....
// create the native AudioTrack object
sp<AudioTrack> lpTrack = new AudioTrack();
....
switch (memoryMode) {
case MODE_STREAM://没有分配地址,直接调用set
status = lpTrack->set(
AUDIO_STREAM_DEFAULT,// stream type, but more info conveyed in paa (last argument)
sampleRateInHertz,
format,// word length, PCM
nativeChannelMask,
frameCount,
AUDIO_OUTPUT_FLAG_NONE,
audioCallback, &(lpJniStorage->mCallbackData),//callback, callback data (user)
0,// notificationFrames == 0 since not using EVENT_MORE_DATA to feed the AudioTrack
0,// shared mem
true,// thread can call Java
sessionId,// audio session ID
AudioTrack::TRANSFER_SYNC,
NULL, // default offloadInfo
-1, -1, // default uid, pid values
paa);
break;
case MODE_STATIC:
// AudioTrack is using shared memory
//如果是MODE_STATIC ,在这里就会分配地址了,然后再调用set
if (!lpJniStorage->allocSharedMem(buffSizeInBytes)) {
ALOGE("Error creating AudioTrack in static mode: error creating mem heap base");
goto native_init_failure;
}
status = lpTrack->set(
AUDIO_STREAM_DEFAULT,// stream type, but more info conveyed in paa (last argument)
sampleRateInHertz,
format,// word length, PCM
nativeChannelMask,
frameCount,
AUDIO_OUTPUT_FLAG_NONE,
audioCallback, &(lpJniStorage->mCallbackData),//callback, callback data (user));
0,// notificationFrames == 0 since not using EVENT_MORE_DATA to feed the AudioTrack
lpJniStorage->mMemBase,// shared mem
true,// thread can call Java
sessionId,// audio session ID
AudioTrack::TRANSFER_SHARED,
NULL, // default offloadInfo
-1, -1, // default uid, pid values
paa);
break;
default:
ALOGE("Unknown mode %d", memoryMode);
goto native_init_failure;
}
...
return (jint) AUDIOTRACK_ERROR_SETUP_NATIVEINITFAILED;
}在UML 图里面我们可以看见,最后是调用
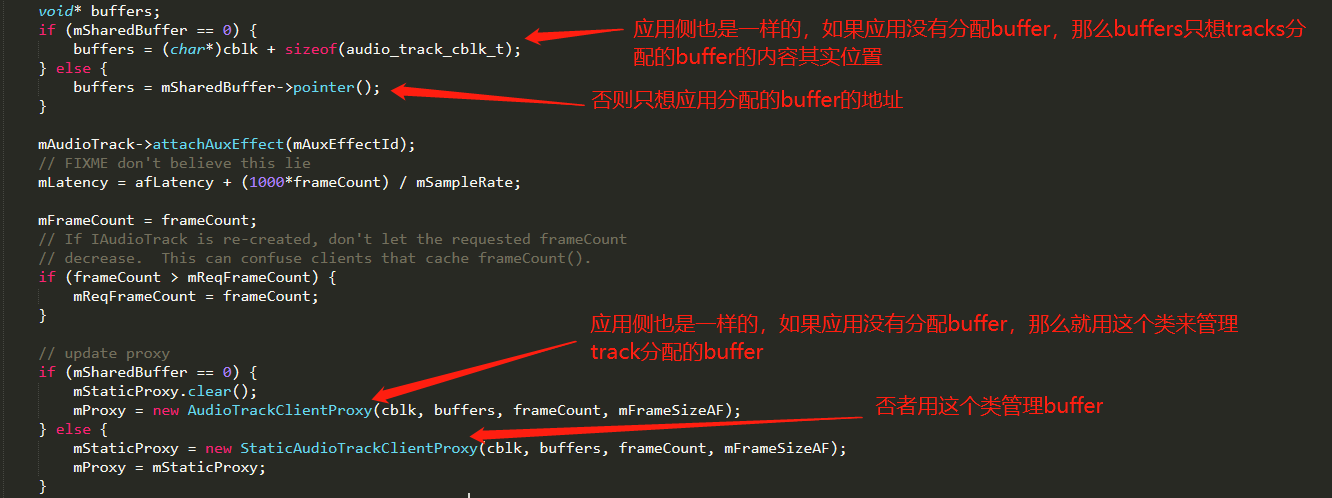
track = new Track(this, client, streamType, sampleRate, format, channelMask, frameCount, NULL, sharedBuffer,sessionId, uid, *flags, TrackBase::TYPE_DEFAULT);去创建一个Track,而分配共享内存的地方在Track的基类TrackBase构造函数里面,
AudioFlinger::ThreadBase::TrackBase::TrackBase(...)
{
size_t size = sizeof(audio_track_cblk_t);
size_t bufferSize = (buffer == NULL ? roundup(frameCount) : frameCount) * mFrameSize;
if (buffer == NULL && alloc == ALLOC_CBLK) {
size += bufferSize;//如果应用没有分配共享内存,那我这里就计算一下一共要分配多大的共享内存 共享内存由 头部+内容两部分组成
}
if (client != 0) {
mCblkMemory = client->heap()->allocate(size);//开始分配共享内存!!!!!!
if (mCblkMemory == 0 ||
(mCblk = static_cast<audio_track_cblk_t *>(mCblkMemory->pointer())) == NULL) {
ALOGE("not enough memory for AudioTrack size=%u", size);
client->heap()->dump("AudioTrack");
mCblkMemory.clear();
return;
}
} else {
// this syntax avoids calling the audio_track_cblk_t constructor twice
mCblk = (audio_track_cblk_t *) new uint8_t[size];
// assume mCblk != NULL
}
// construct the shared structure in-place.
if (mCblk != NULL) {
new(mCblk) audio_track_cblk_t();
switch (alloc) {
case ALLOC_READONLY: {
case ALLOC_PIPE:
case ALLOC_CBLK:
// clear all buffers
if (buffer == NULL) {//如果buffer==空,说明应用没有分配共享内存,那就把mBuffer指向我们底层分配的位置
mBuffer = (char*)mCblk + sizeof(audio_track_cblk_t);
memset(mBuffer, 0, bufferSize);
} else {
mBuffer = buffer;
}
break;
case ALLOC_LOCAL:
case ALLOC_NONE:
}
}
}
在应用程序这一侧,应该也有管理buffer东西,那他们在哪儿?他们的位置在AudioTrack::createTrack_l 函数里面。
2、 APP提供数据, PlaybackThread消耗数据, 如何同步?
MODE_STATIC:
无需同步,APP构造好,PlaybackThread直接消耗完。
MODE_STREAM:
需要同步,生产者,消费者问题。使用环形buffer 来控制数据同步。
音频数据的传递
在应用侧,我们每创建一个AudioTrack都会在PlaybackThread侧创建一个track线程与之对应,那么音频数据是怎么传递?
MODE_STATIC 模式,数据是已经全部在buffer里面了,只需要PlaybackThread慢慢取出来用就行了。
MODE_STREAM 模式,APP和PlaybackThread 就是一个在往共享buffer里面写数据,一个使用里面的数据,APP使用abtainbuffer获取一个buffer的空白地址,然后填充数据,然后release掉
PlaybackThread 这一侧也是使用abtainbuffer获取一个有数据的buffer地址,然后使用掉,然后release buffer。
APP写数据具体时序图:
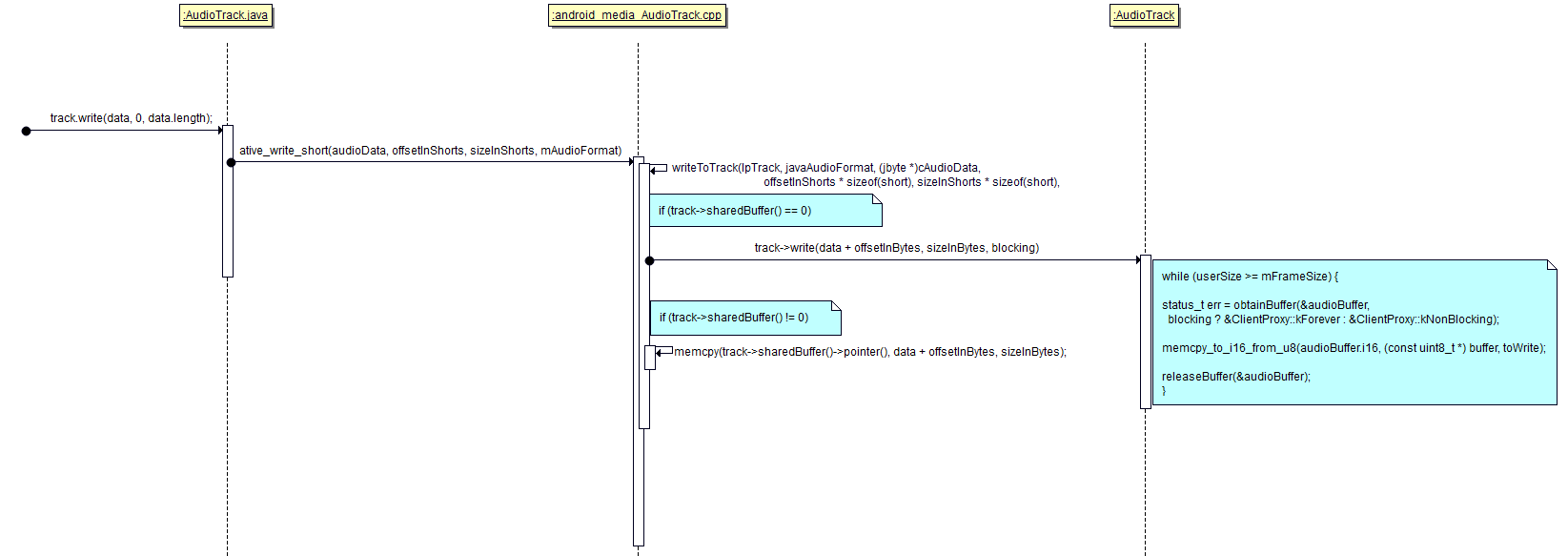
对于MODE_STREAM 模式,PlaybackThread 这边消化数据是怎么做的呢?在之前讲过,如果是MODE_STREAM, PlaybackThread 这一侧会new 一个AudioTrackClientProxy对象,那么这个对象里面就会有obtainBuffer 和releaseBuffer 函数。在obtainBuffer 里面取出buffer里面有数据的位置进行消费,然后调用releaseBuffer 释放消费过的buffer里面的位置,然后再调整Buffer里面有数据的位置(mPosition = newPosition;),方便下一次调用obtainBuffer 直接使用数据。
音频数据传递总结
a. APP创建AudioTrack, playbackThread创建对应的Track
它们之间通过共享内存传递音频数据
b. APP有2种使用共享内存的方式:
b.1 MODE_STATIC:
APP创建共享内存, APP一次性填充数据
b.2 MODE_STREAM:
APP使用obtainBuffer获得空白内存, 填充数据后使用releaseBuffer释放内存
c. playbackThread使用obtainBuffer获得含有数据的内存, 使用数据后使用releaseBuffer释放内存
d. AudioTrack中含有mProxy, 它被用来管理共享内存, 里面含有obtainBuffer, releaseBuffer函数
Track中含有mServerProxy, 它被用来管理共享内存, 里面含有obtainBuffer, releaseBuffer函数
对于不同的MODE, 这些Proxy指向不同的对象
e. 对于MODE_STREAM, APP和playbackThread使用环型缓冲区的方式传递数据
PlaybackThread处理流程
假设有两个应用程序,每个应用程序都会创建AudioTrack,和与之对应的Track,他们之间通过共享内存进行数据传递,现在假设第一个应用程序传递的音频是双通道,采样率是44KHZ,每个采样点的深度是16位,另一个应用程序传递的音频试试单通道,采样率是22khz,每个采样点的深度是8位,儿硬件支持的格式只有一种,那怎么办呢?-----音频重采样。在PlaybackThread里面会有一个mAudioMixer对象进行重采样:把这些七七八八的音频格式转换为硬件支持的统一的格式输出。重采样之后,会把多路的音频混合在一起,这就叫混音。
在mAudioMixer里面有一个mState对象,mState里面有一个hook函数,对应不同的函数,如果应用程序送过来的音频数据真好处于手机静音状态,那么就会调用process__nop 函数,不发出声音;如果应用程序送过来的音频数据格式正好是声卡设备支持的格式,那么就会调用process__genericNoResampling函数,表示不重采样;如果应用程序送过来的音频数据格式不是声卡设备支持的格式,那么就会调用process__genericResampling函数,表示进程重采样处理。如果需要重新采样,那么mState里面的outputTemp将会被使用,outputTemp的作用就是存放每个经过处理,或者不需要经过重采样处理的数据。mState里面还有一个track_t结构体,这个结构体里面还有mainBuffer ,用来保存重采样,或者不处理的最终的数据;resampler表示重采样器,还有一个hook函数,他指向不同的函数,比如track__nop(表示对这一路音频静音,其他路的音频还是可以播出)track__Resample;track__NoResample 。。。于是这里就出现了两个hook函数,他们是包含关系,第二个hook属于track_t结构体,但是track_t结构体被定义在mState里面,PlaybackThread 中,每一个track,都对应这一个track_t结构体。那么这两种hook是什么关系呢?他们是怎么调用呢?先逐个分析mState.tracks[x]的数据, 根据它的格式确定tracks[x].hook,再确定总的mState.hook。最后也就是调用总的mState.hook即可, 它会再去调用每一个mState.tracks[x].hook。
接下来看一下PlaybackThread处理的流程
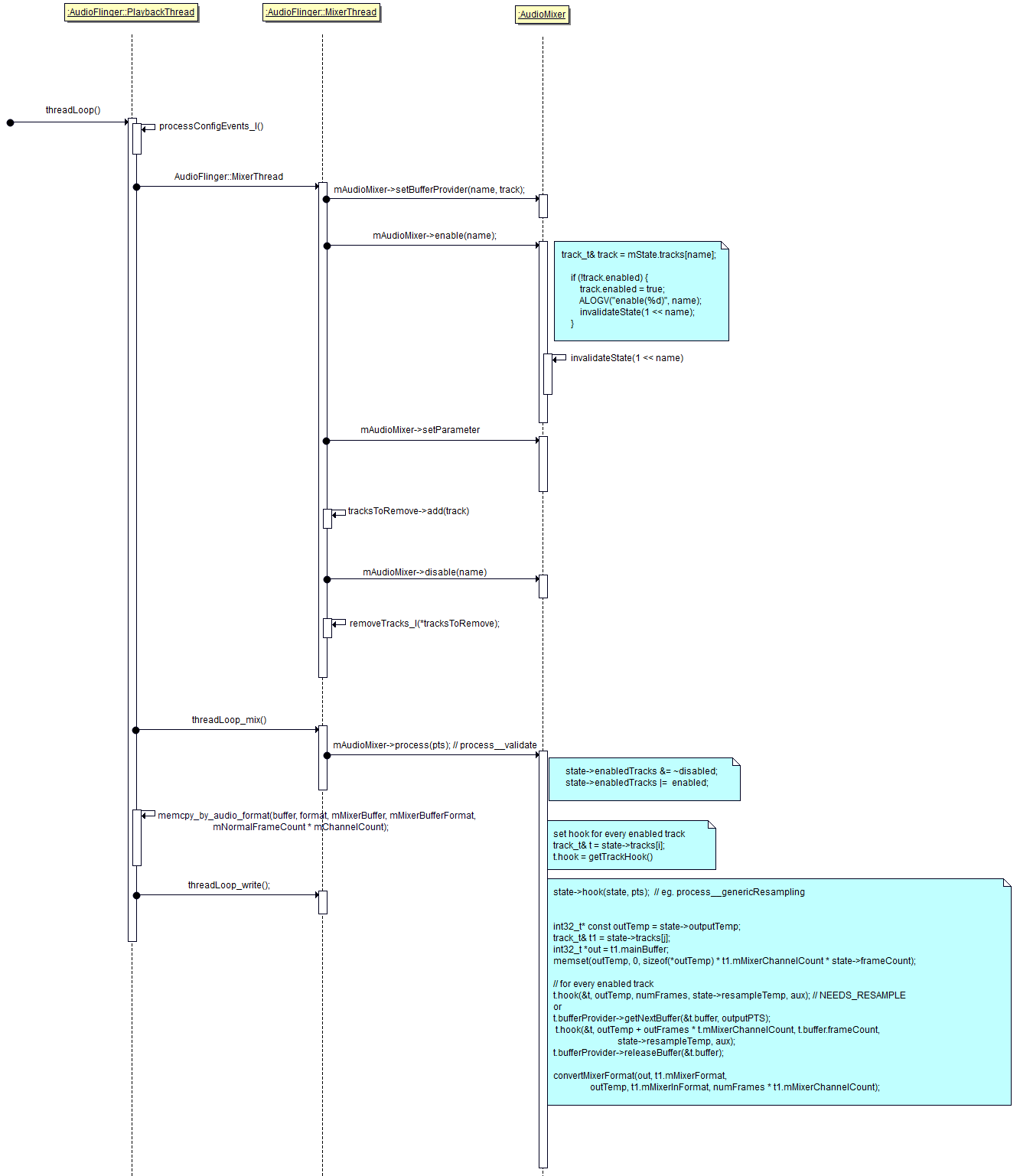
prepareTracks_l(&tracksToRemove):确定哪些track有数据,哪些track需要播放。
threadLoop_mix():设置每一个track的hook函数,调用总的hook函数,处理数据,把数据放在outputTemp。
PlaybackThread处理流程总结
a. prepareTracks_l :
确定enabled track, disabled track
对于enabled track, 设置mState.tracks[x]中的参数
b. threadLoop_mix : 处理数据(比如重采样)、混音
确定hook:
逐个分析mState.tracks[x]的数据, 根据它的格式确定tracks[x].hook
再确定总的mState.hook
调用hook:
调用总的mState.hook即可, 它会再去调用每一个mState.tracks[x].hook
混音后的数据会放在mState.outputTemp临时BUFFER中
然后转换格式后存入 thread.mMixerBuffer
c. memcpy_by_audio_format :
把数据从thread.mMixerBuffer或thread.mEffectBuffer复制到thread.mSinkBuffer
d. threadLoop_write:
把thread.mSinkBuffer写到声卡上
e. threadLoop_exit
最后
以上就是勤奋百合最近收集整理的关于android audio模块(二)的全部内容,更多相关android内容请搜索靠谱客的其他文章。








发表评论 取消回复