
前言
Redis与MySQL的双写一致性如何保证?不管是工作还是面试,这都是老生常谈的问题。近期,我打算在公司做一期《分布式环境下如何保证数据一致性》的培训,所以决定把课题相关的资料好好整理了一下,希望可以成体系的研究一下。
本文系统的介绍了 Redis 与 DB 双写数据一致性解决方案。当然,文章会参照最新的一些文章(毕竟知识点也就这么点东西),但是解决了内容重复、冗余的Bug,并且会重点介绍【多级缓存的一致性问题解决方案】。
你可能需要的文章:
- 高性能系统架构设计之:多级缓存
- Redis为什么快?基于内存就完事了?不要无视Redis如此完美的数据结构
正文
一、CAP理论
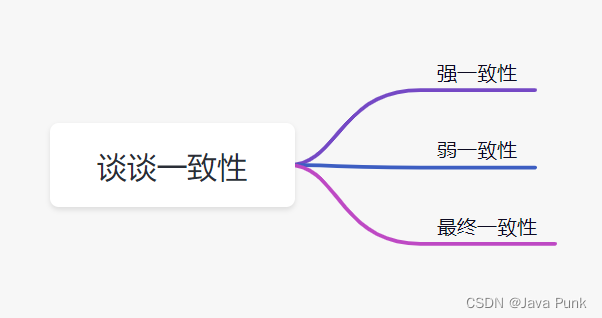
所谓的一致性就是数据保持一致,在分布式系统中,可以理解为多个节点中数据的值是一致的。
- 强一致性:这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大;
- 弱一致性:这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态;
- 最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型。
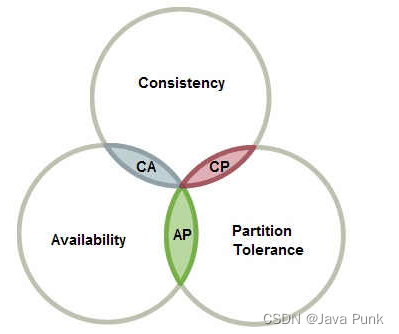
CAP理论,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。分布式系统要么满足CA,要么CP,要么AP,无法同时满足CAP。
因为使用缓存提升性能,就是会有数据更新的延迟,如果需要数据库和缓存数据保持强一致,就不适合使用缓存。但是,通过一些方案优化处理,是可以保证弱一致性,最终一致性的。
所以,我们在设计时结合业务仔细思考是否适合用缓存,然后缓存一定要设置过期时间,这个时间太短、或者太长都不好:
- 太短的话:请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势;
- 太长的话:缓存中的脏数据会使系统长时间处于一个延迟的状态,而且系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
重要:缓存是通过牺牲强一致性来提高性能的,这是由CAP理论决定的,缓存系统适用的场景就是非强一致性的场景,它属于 CAP 中的 AP。
二、常见方案
3种常用方案可以保证缓存与数据库数据的一致性:
- 延时双删;
- 重试机制删除缓存;
- 读取 biglog 异步删除缓存;
2.1 延时双删
方案:先删除缓存 → 再更新数据库 → 休眠一会(比如1秒),再次删除缓存 → 待后续请求落到DB后,将查询数据更新到缓存,去报后续请求一直落到缓存上。
第二次删除的目的,是确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据,因为删除缓存和更新DB之间会有时间差。
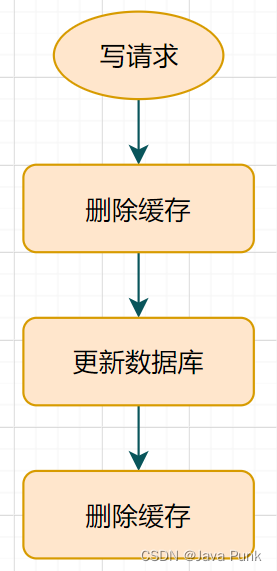
这个休眠一会,一般多久呢?是1秒吗?
休眠时间 ≈ 读业务逻辑数据的耗时 + 几百毫秒。
2.2 重试机制删除缓存
考虑一个问题:如果延时双删策略的第二步删除缓存失败了呢?
结论:删除失败,会导致可能出现脏数据。
针对性的解决办法:失败那就多删除几次,保证删除缓存一定会成功,所以,就引入了重试机制。
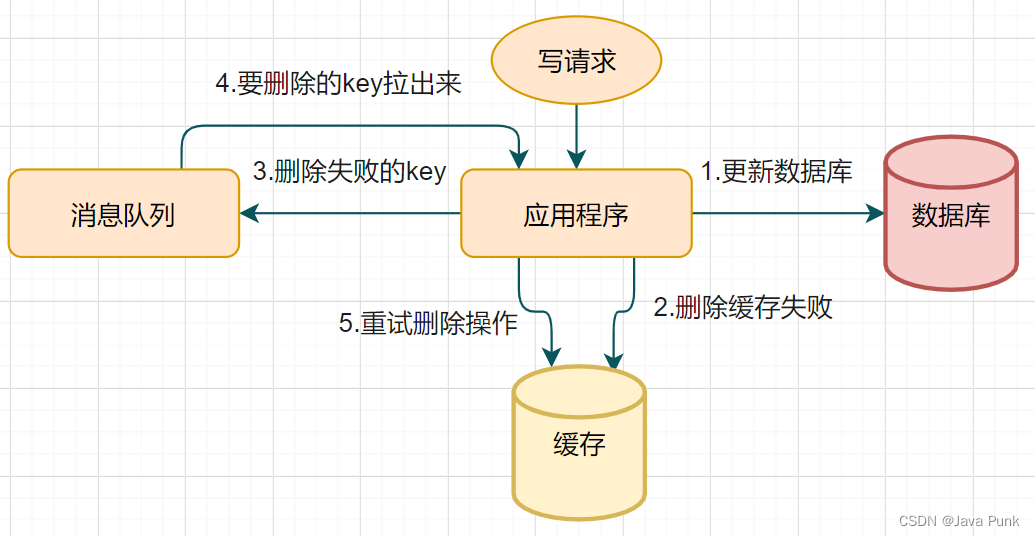
重试机制方案:写请求更新数据库 → 如果缓存因为某些原因删除失败 → 把删除失败的key放到消息队列 → 消费消息队列的消息,获取要删除的key → 重试删除缓存操作。
重试的方案还有很多,除了消息中间件,如:RocketMQ,还可以使用重试机制,如:spring-Retry,Guava-Retry...
2.3 biglog 异步删除缓存
问题:重试机制删除缓存还可以,但是它的缺点也很明显。
- 使用 Retry 机制,会造成大量业务代码的入侵;
- 如果删除失败源于系统问题,那失败就是必然, Retry 重试就会变成死循环导致系统卡死;
解决方案:跳出业务代码的圈子,其实我们还可以通过数据库的 binlog 日志,异步淘汰失败的key。
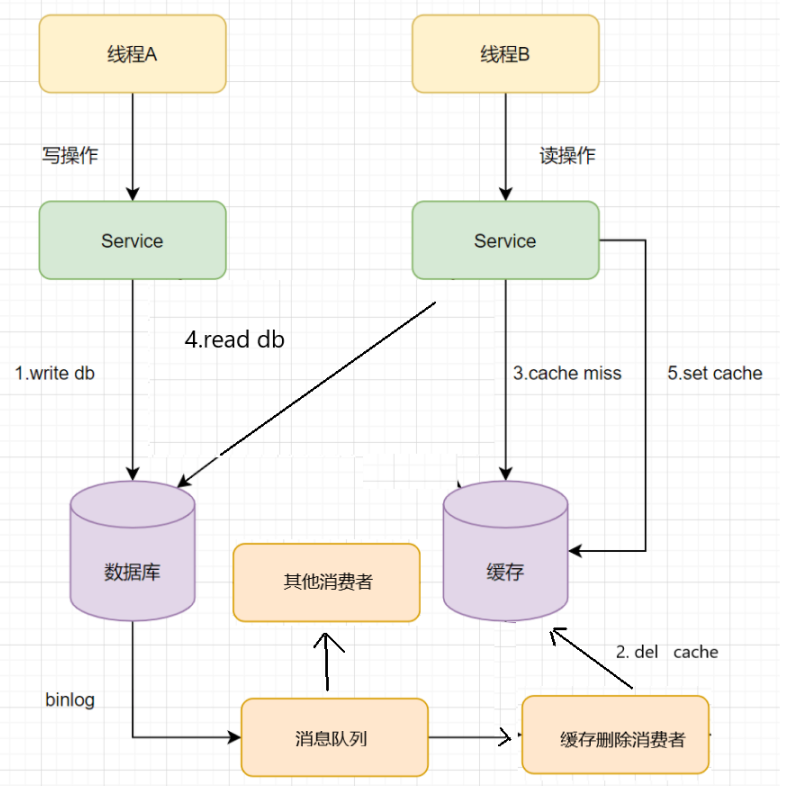
以 Mysql 为例:可以使用阿里的 canal 将 binlog 日志采集发送到 RocketMQ 队列里面,然后编写一个简单的缓存删除消息者订阅 binlog 日志,根据更新 log 删除缓存,并且通过 ACK 机制确认处理这条更新 log,保证数据与缓存的一致性。
问题 - 1:异步删除策略,非常依赖 MQ 中间件的稳定性,而 MQ 有一个典型的问题,就是“消费丢失和重复消费”,如何避免?
实际上,知识都是成体系的,MQ 的问题就用 MQ 的手段解决就好了,这里不展开说了,越说越分散没个头。以 RocketMQ 举例:
- 为了确保一定消费成功:在消费的时候,我们就需要注入一个消费回调,失败了过一会就再重试消费;
- 为了确保只消费一次:在消费的时候,做一个 setnx 原子性验证,保证不做重复的操作;
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs);
delcache(key); //执行真正删除
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //返回消费成功
}
});业务实现消费回调的时候:
- 当且仅当此回调函数返回 ConsumeConcurrentlyStatus.CONSUME_SUCCESS,RocketMQ 才会认为这批消息(默认是1条)是消费完成的;
- 返回 ConsumeConcurrentlyStatus.RECONSUME_LATER,RocketMQ 会认为是失败了。
其实,除了 RocketMQ 方式的发布和订阅,使用 Redis 的 pub/sub订阅也可以实现异步删除的功能。
Redis通过 publish 和 subscribe 命令实现订阅和发布的功能。订阅者可以通过 subscribe 向redis server 订阅自己感兴趣的消息类型。redis 将信息类型称为通道(channel)。当发布者通过 publish 命令向 redis server 发送特定类型的信息时,订阅该消息类型的全部订阅者都会收到此消息。
问题 - 2:如果数据库不是单库,而是集群部署的主从数据库呢?
因为主从 DB 同步存在延时时间。如果删除缓存之后,数据同步到备库之前已经有请求过来时, 「会从备库中读到脏数据」,如何解决呢?解决方案如下流程图:
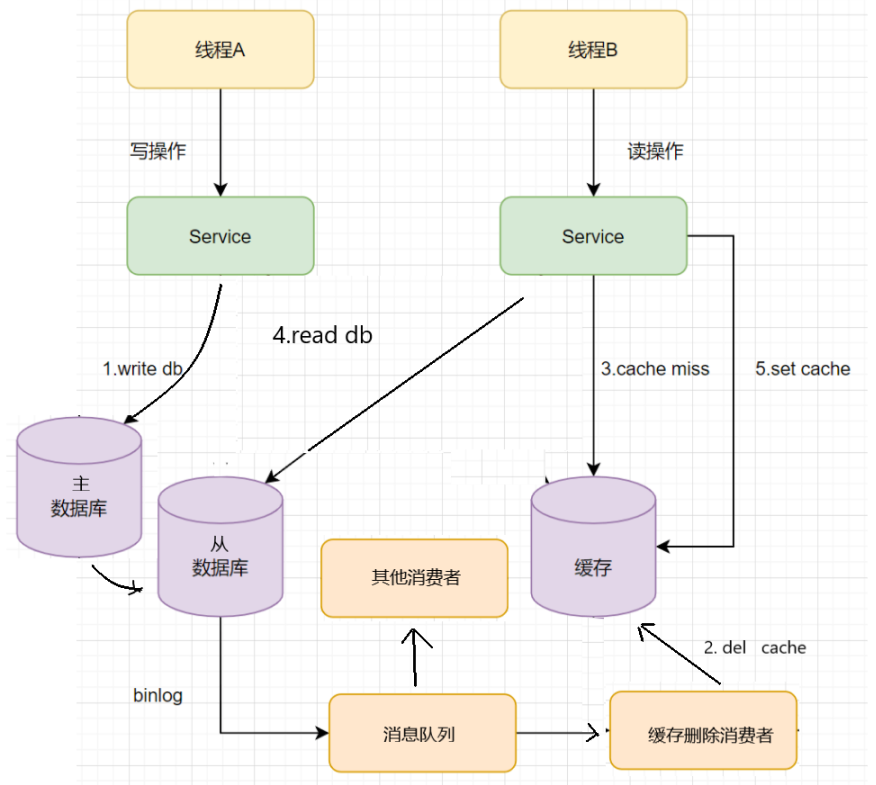
针对上面的情况,我们可以在从库读取 binglog 日志,然后进行分发和消费的操作,用昨晚删除的方式避免脏数据的出现。
以上每一种方案都有自己的适用场景,在分布式系统中,缓存和数据库同时存在,如果有写操作的时候,「先操作数据库,再操作缓存」的双删策略,如下:
- 读取缓存中是否有相关数据;
- 如果缓存中有相关数据 value,则返回;
- 如果缓存中没有相关数据,则从数据库读取相关数据放入缓存中 key->value,再返回;
- 如果有更新数据,则先更新数据库,再删除缓存;
- 为了保证第四步删除缓存成功,使用 binlog 异步删除;
- 如果是主从数据库,binglog 取自于从库;
- 如果是一主多从,每个从库都要采集binlog,然后消费端收到最后一台binlog数据才删除缓存,或者为了简单,收到一次更新log,删除一次缓存。
三、多级缓存方案
了解到了我们为什么要使用缓存,以及缓存能解决我们什么样的问题,紧接着又有新的问题产生了:Redis 服务可以减轻 DB 的压力,那如果大量的请求全部落在 Redis 服务上,Redsi 的压力如何解决?单纯的整合Redis缓存,那么可能出现如下的问题:
- 热点数据的大量访问,能对系统造成各种网络开销,影响系统的性能;
- 一旦集中式缓存发生雪崩了,或者缓存被击穿了,能造成数据库的压力增大,可能会被打死,造成数据库挂机状态,进而造成服务宕机;
- 缓存雪崩,访问全部打在数据库上,数据库也可能会被打死;
- ......
为了解决以上可能出现的问题,让缓存层更稳定,健壮,现在多采用【多级缓存】方案。多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻 Tomcat 压力,提升服务性能。
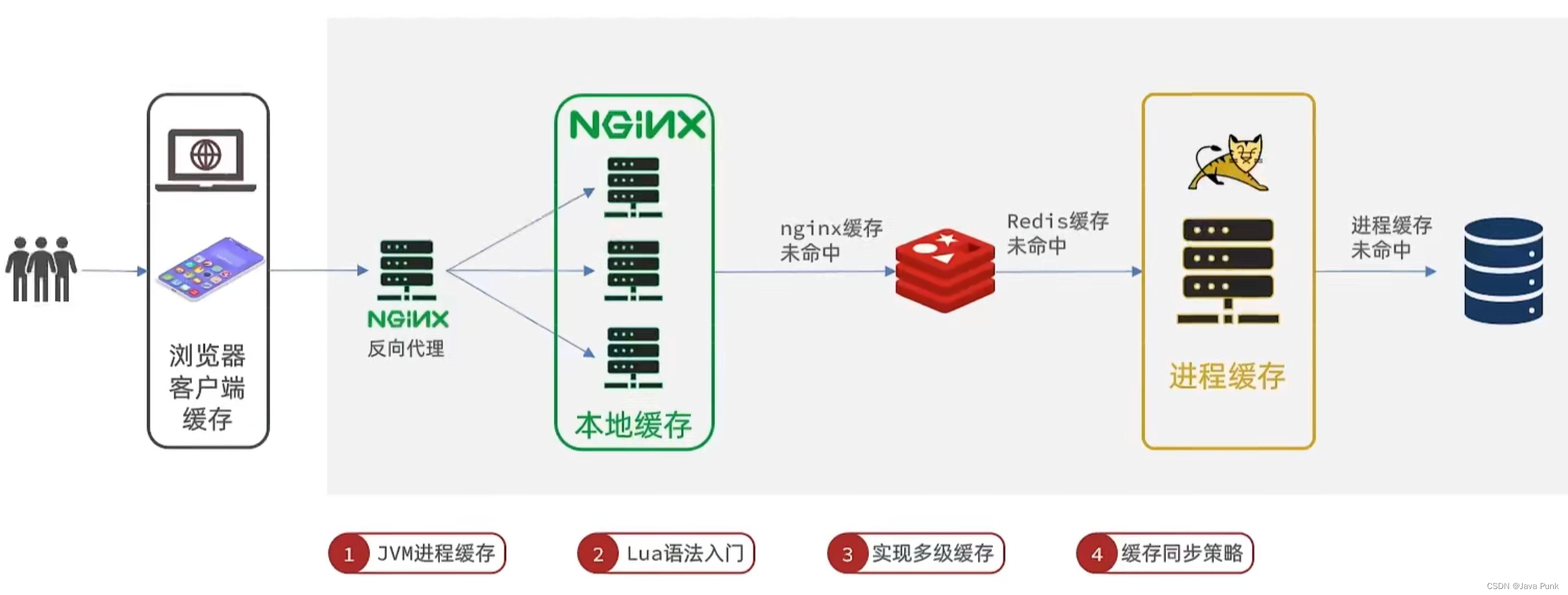
下面选取2种简单的缓存架构,简单讲解一下原理:
3.1 二级缓存架构
二级缓存架构分级:
- 1级为本地缓存,或者进程内的缓存(如:Ehcache):速度快,进程内可用;
- 2级为集中式缓存(如:Redis):可同时为多节点提供服务;
| 数据库 | 本地缓存 | 分布式缓存 | |
|---|---|---|---|
| 存储位置 | 存盘,数据不丢失 | 不存盘,之前的数据丢失 | 不存盘,数据丢失 |
| 持久化 | 可以 | 不可以 | 可以 |
| 访问速度 | 慢 | 最快 | 快 |
| 可扩展 | 可存在其他机器的硬盘 | 只能存在本机内存 | 可存在其他机器的内存 |
| 使用场景 | 需要实现持久化保存 | 需要快速访问,但需要考虑内存大小 | 1)需要快速访问,不需要考虑内存大小 2)需要实现持久化,但会丢失一些数据 3)需要让缓存集中在一起,访问任一机器上内存中的数据都可以从缓存中得到 |
问题 - 1:为什么要将本地缓存与集中式缓存的结合使用?
假设一个项目场景:有这么一个网站,某个页面每天的访问量是 1000万,每个页面从缓存读取的数据是 50K。缓存数据存放在一个 Redis 服务,机器使用千兆网卡。那么这个 Redis 一天要承受 500G 的数据流。而网站一般都会有高峰期和低峰期,两个时间流量的差异可能是百倍以上。假设高峰期每秒要承受的流量比平均值高 50 倍,也就是说高峰期 Redis 服务每秒要传输超过 250 兆的数据。请注意这个 250 兆的单位是 byte,而千兆网卡的单位是“bit” ,你懂了吗? 这已经远远超过 Redis 服务的网卡带宽。
面对如此场景,一般我们会怎么做?
- 网卡从千兆升级到万兆:很多人不知道,这个看似简单的操作其实相当麻烦,特别是一些云主机根本没有万兆网卡给你使用,要命;
- 搭建 Redis 集群,将流量分摊在多台缓存机器上。
相对而言,第二种方法是更合理的,技术上也相对成熟。为了提升性能,我们准备了5 台 Redis 服务来支撑业务量。
看似没毛病,实际上问题也不小:本身缓存的数据量并不大,1000 万高频次的缓存读写 Redis 也能轻松应付,可是因为带宽的问题就不得不付出 5 倍的成本?你不考虑成本但是有人会把成本放在第一位啊!!
所以,我们还有第三种方案:根据二八原则,我们把20%的热点数据,放在本地缓存,那么 Redis 上至少降低 80%的带宽流量,如此一来,甚至于一个很小的 Redis 集群可以轻松应付。这就是为什么要进程内和进程外缓存结合使用的答案。
问题 - 2:为什么要引入本地缓存?
相对于IO操作,Ehcache速度快,效率高;相对于Redis,Ehcache在进程内,比 Redis 的服务器距离应用服务器更近。所以:DB + Redis + LocalCache = 高效存储,高效访问。
问题 - 3:数据一致性问题?
好了,我们该步入正题了,二级缓存的数据一致性如何保证?
由于本地缓存只支持被该应用进程访问,一般无法被其他应用进程访问,如果对应的数据库数据存在数据更新,则需要同步更新不同节点的本地缓存副本,来保证数据一致性。本地缓存的更新,复杂度较高并且容易出错,如:基于 Redis 的发布订阅机制、或者消息队列MQ来同步更新各个部署节点。
延续上面说到的【 biglog 异步删除缓存】策略,可以通过biglog同步,来保障二级缓存的数据一致性,具体的架构如下:
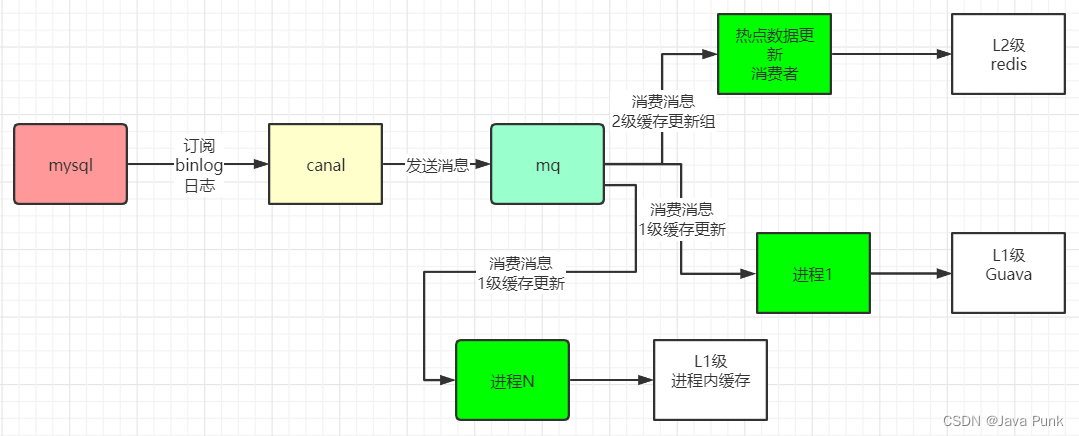
RocketMQ 是支持广播模式的: 对于更新Redis来说,一个实例消费消息,完成 Redis 的更新;对于更新 Guava 或者其他1级缓存来说,每一个实例都需要消费消息,更新自己的存储。
@RocketMQMessageListener(topic = "seckillgood", consumerGroup = "UpdateGuava", messageModel = MessageModel.BROADCASTING)问题 - 4:二级缓存缓存击穿解决方案
- 设置热点数据永远不过期;
- 如果过期则或者在快过期之前更新,如有变化,主动刷新缓存数据,同时也能保障数据一致性;
- 加互斥锁,保障缓存中的数据,被第一次请求回填。注意:此方案不适用于超高并发场景。
3.2 三级缓存架构
相比于二级缓存架构,三级缓存增加了接入层,如:Nginx。 三级缓存架构分级:
- 1级为本地缓存,或者进程内的缓存(如:Ehcache):速度快,进程内可用;
- 2级为集中式缓存(如:Redis):可同时为多节点提供服务;
- 3级为接入层缓存(如:Nginx):速度快,进程内可用;
对于高并发的请求,接入层 Nginx 有着巨大的作用,能反向代理,负载均衡,动静分离以及和 Lua 整合,可以实现请求定向分发等非常有用的功能,同理 Nginx 层也可以实现缓存的功能。
利用接入层 Nginx 的进程内缓存,缓存极热数据的高并发访问。在接入层,当请求过来时,判断本地缓存中是否存在,如果存在着直接返回请求结果(或者展现静态资源的数据),这样的请求不会直接发送到后端服务层,减少了跨网络传输,大大缩短访问路径。
问题 - 1:如何使用 Nginx 作为L3本地缓存?
我这里要介绍的,是使用 Nginx Lua 共享字典的方式实现三级缓存。
- 声明一个共享内存区域 name,以充当基于 Lua 字典
ngx.shared.<name>的共享存储。
syntax:lua_shared_dict <name> <size>
default: no
context: http
phase: depends on usage- 设置参数 siz 接受大小单位,如:k,m。
http {
# 指定缓存信息
lua_shared_dict seckill_cache 128m;
...
}- 然后在 lua 脚本中使用:local shared_memory = ngx.shared.seckill_cache,就可以取到放在共享内存中的数据。对共享内存的操作也是如 get,set 之类。
-优先从缓存获取,否则访问上游接口
local seckill_cache = ngx.shared.seckill_cache
local goodIdCacheKey = "goodId_" .. goodId
local goodCache = seckill_cache:get(goodIdCacheKey)
if goodCache == "" or goodCache == nil then
ngx.log(ngx.DEBUG,"cache not hited " .. goodId)
-- 回源上游接口,比如Java 后端rest接口
local res = ngx.location.capture("/stock-provider/api/seckill/good/detail/v1", {
method = ngx.HTTP_POST,
-- args = requestBody , -- 重要:将请求参数,原样向上游传递
always_forward_body = false, -- 也可以设置为false 仅转发put和post请求方式中的body.
})
-- 返回上游接口的响应体 body
goodCache = res.body;
-- 单位为s
seckill_cache:set(goodIdCacheKey, goodCache, 10 * 60 * 60)
end
ngx.say(goodCache);问题 - 2:Lua 共享内存的淘汰机制?
ngx.shared.DICT 的实现是采用红黑树实现,当申请的缓存被占用完后如果有新数据需要存储则采用 LRU 算法淘汰掉“多余”的数据。
LRU算法:当数据在最近一段时间经常被访问,那么它在以后也会经常被访问,对于此类经常访问的数据,我们需要其能够快速命中,而不常访问的数据,我们在容量超出限制时,会将其淘汰。
问题 - 3:数据一致性问题?
3级缓存主要用于极热数据,如秒杀的商品数据(对于秒杀这样的场景,瞬间有十几万甚至上百万的请求要同时读取商品。如果没有命中本地缓存,可能导致缓存击穿。
为了防止缓存击穿,同时也保持数据一致性,具体的方案为:
- 数据预热(或者叫预加载);
- 设置热点数据永远不过期,通过 ngx.shared.DICT的缓存的LRU机制去淘汰;
- 如果缓存主动更新,在快过期之前更新,如有变化,通过订阅变化的机制,主动本地刷新;
- 提供兜底方案,如果本地缓存没有,则通过后端服务获取数据,然后缓存起来。
总结
1. 简单了解下缓存击穿与缓存穿透的简单区别:
- 缓存击穿:指数据库中有数据,但是缓存中没有,大量的请求打到数据库;
- 缓存穿透:指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
2. 缓存和DB的数据一致性如何保证:
- 分布式系统中,缓存和数据库同时存在,先操作数据库,再操作缓存。
- 为了保证删除缓存成功,根据适用场景,可以选择延时双删,重试机制删除缓存,或者使用 binlog 异步删除策略;
- 针对 binlog 异步删除策略:如果是主从数据库,binglog 要取自于从库;如果是一主多从,每个从库都要采集binlog,然后消费端收到最后一台binlog数据才删除缓存,或者干错简单处理 - 收到一次更新 log,就删除一次缓存;
- 多级缓存方案中,由于进程内缓存的存在,所以每次有更新操作,要利用 MQ 的广播模式通知到每台服务器进行数据同步;
3. 很重要的一点:
使用缓存提升性能就会有数据更新的延迟,就无法使数据库和缓存数据保持强一致,所以上树的各种优化方案,都是以保证弱一致性,最终一致性为前提的。
最后
以上就是悦耳画板最近收集整理的关于Redis 与 DB 的数据一致 / 双写一致性问题前言正文总结的全部内容,更多相关Redis内容请搜索靠谱客的其他文章。








发表评论 取消回复