
作者:林骥
来源:林骥
引言
本文是我写的人工智能系列的第 8 篇文章,文末有前面 7 篇文章的链接,推荐你阅读、分享和交流。
1. 决策树算法简介
决策树是一种应用非常广泛的算法,比如语音识别、人脸识别、医疗诊断、模式识别等。
决策树算法既可以解决分类问题(对应的目标值是类别型的数据),也能解决回归问题(输出结果也可以是连续的数值)。
相比其他算法,决策树有一个非常明显的优势,就是可以很直观地进行可视化,分类规则好理解,让非专业的人也容易看明白。
比如某个周末,你根据天气等情况决定是否出门,如果降雨就不出门,否则看是否有雾霾……这个决策的过程,可以画成这样一颗树形图:
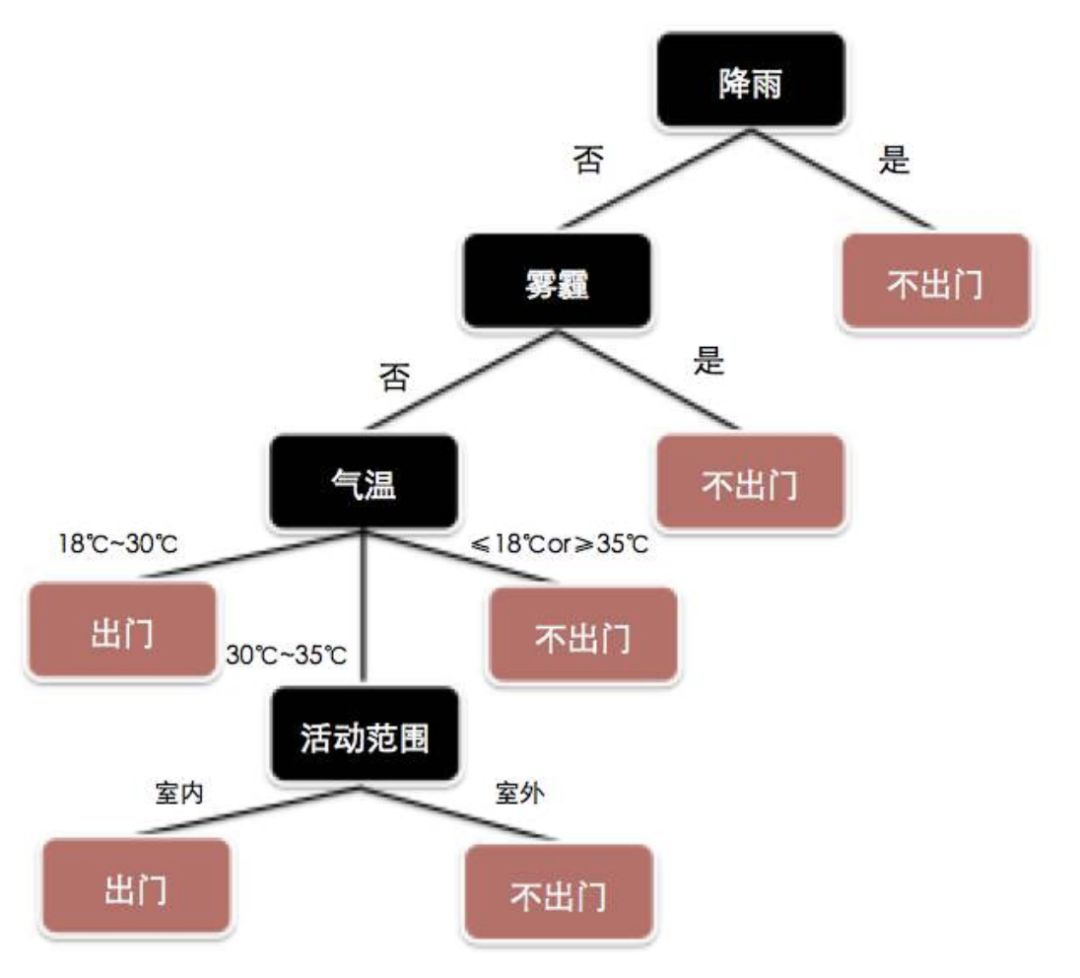
下面我们以 sklearn 中的葡萄酒数据集为例,给定一些数据指标,比如酒精度等,利用决策树算法,可以判断出葡萄酒的类别。
2. 加载数据
为了方便利用图形进行可视化演示,我们只选取其中 2 个特征:第 1 个特征(酒精度)和第 7 个特征(黄酮量),并绘制出 3 类葡萄酒相应的散点图。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 加载葡萄酒的数据集
wine = datasets.load_wine()
# 为了方便可视化,只选取 2 个特征
X = wine.data[:, [0, 6]]
y = wine.target
# 绘制散点图
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.scatter(X[y==2, 0], X[y==2, 1])
plt.show()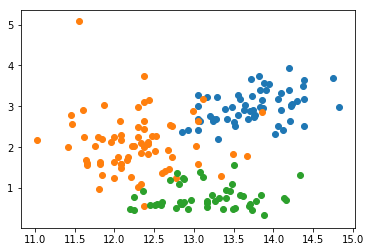
在上面的散点图中,颜色代表葡萄酒的类别,横轴代表酒精度,纵轴代表黄酮量。
3. 调用算法
和调用其他算法的方法一样,我们先把数据集拆分为训练集和测试集,然后指定相关参数,这里我们指定决策树的最大深度等于 2,并对算法进行评分。
from sklearn.model_selection import train_test_split
from sklearn import tree
# 拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 调用决策树分类算法
dtc = tree.DecisionTreeClassifier(max_depth=2)
dtc.fit(X_train, y_train)
# 算法评分
print('训练得分:', dtc.score(X_train, y_train))
print('测试得分:', dtc.score(X_test, y_test))训练得分:0.9172932330827067
测试得分:0.8666666666666667从上面的结果可以看出,决策树算法的训练得分和测试得分都还不错。
假如设置 max_depth = 1,那么算法评分很低,就会出现欠拟合的问题。
假如设置 max_depth = 10,那么虽然算法的评分变高了,但是决策树变得过于复杂,就会出现过拟合的问题。
关于模型复杂度的问题讨论,可以参考:模型越复杂越好吗?
4. 决策边界
为了更加直观地看到算法的分类效果,我们定义一个绘制决策边界的函数,画出分类的边界线。
from matplotlib.colors import ListedColormap
# 定义绘制决策边界的函数
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
# 绘制决策边界
plot_decision_boundary(dtc, axis=[11, 15, 0, 6])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.scatter(X[y==2, 0], X[y==2, 1])
plt.show()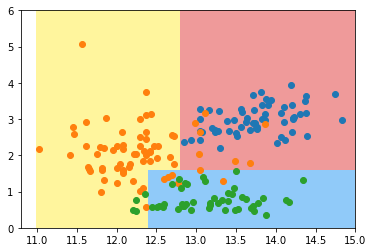
从图中也可以直观地看出,大部分数据点的分类是基本准确的,这也说明决策树算法的效果还不错。
5. 树形图
为了能够更加直观地理解决策树算法,我们可以用树形图来展示算法的结果。
# 导入相关库,需要先安装 graphviz 和 pydotplus,并在电脑中 Graphviz 软件
import pydotplus
from sklearn.tree import export_graphviz
from IPython.display import Image
from io import StringIO
# 将对象写入内存中
dot_data = StringIO()
# 生成决策树结构
tree.export_graphviz(dtc, class_names=wine.target_names,
feature_names=[wine.feature_names[0], wine.feature_names[6]],
rounded=True, filled=True, out_file = dot_data)
# 生成树形图并展示出来
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())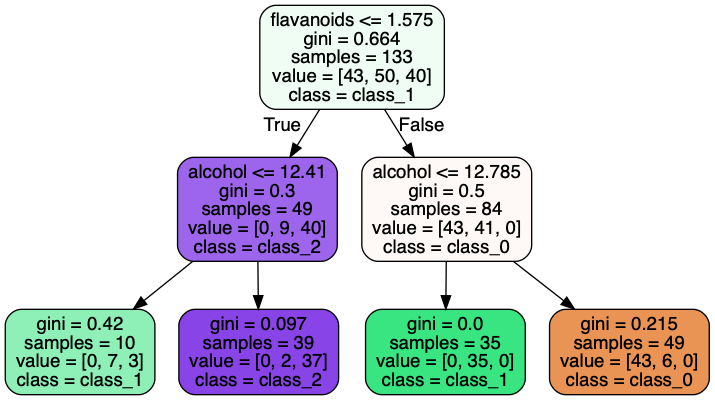
6. 结果解读
从上面的树形图来看,在葡萄酒数据的训练集中,有 133 个数据,划分为 3 个类别,数量分别是 43、50、40 个,对应的标签分别是 class_0、class_1、class_2,其中 class_1 的数量最多,所以最上面的根节点认为,类别为 class_1 的可能性最大,Gini 系数为 0.664,它是利用下面的公式计算出来的:
1 - (43/133)**2 - (50/133)**2 - (40/133)**2
在决策树算法中,Gini 系数代表样本的不确定性。当每个类别的数量越趋近于平均值,Gini 系数就越大,也就越不确定。
比如扔硬币的游戏,在一般情况下,正反两面的概率都是 50%,此时 Gini 系数等于 0.5,你猜中的概率也是 50%;假如你对硬币做了手脚,把两面都变成正面图案,此时Gini 系数等于 0, 也就是说,不确定性为 0,你能明确地知道肯定是正面。
在上面葡萄酒的例子中,当黄酮量 <= 1.575 时,有 49 个样本,3 个类别的数量分别是 0、9、40 个,其中 class_2 的数量最多,Gini 系数为 0.3,比上面的节点要低,说明分类结果变得更加确定。当酒精量 > 12.41 时,有 39 个样本,3 个类别的数量分别是 0、2、37个,Gini 系数为 0.097,此时分类结果变得更加确定为 class_2。
树形图中其他节点的结果含义类似,在此不再赘述。
小结
本文介绍了决策树算法的应用,以葡萄酒数据集为例,演示了决策树算法的实现过程,绘制了直观易懂的决策边界和树形图,并对决策结果做了详细解读。
虽然决策树算法有很多优点,比如高效、易懂,但是也有它的不足之处,比如当参数设置不当时,很容易出现过拟合的问题。
为了避免决策树算法出现过拟合的问题,可以使用「集成学习」的方法,融合多种不同的算法,也就是俗话讲的「三个臭皮匠,赛过诸葛亮」。
关于「集成学习」的方法,本文限于篇幅,这里就不多做介绍了,我下次再写。
作者:林骥,公众号 ID:linjiwx,从 2008 年开始从事数据分析工作,网名数据化分析,用数据化解分析难题,让数据更有价值,让分析更有效。敬请关注。

最后
以上就是着急寒风最近收集整理的关于决策树算法应用及结果解读的全部内容,更多相关决策树算法应用及结果解读内容请搜索靠谱客的其他文章。








发表评论 取消回复