一、填空题(每题1分,共15分)
1、列举数字图像处理的三个应用领域 医学 、天文学 、 军事
2、存储一幅大小为1024*1024,256个灰度级的图像,需要 8M bit。
3、亮度鉴别实验表明,韦伯比越大,则亮度鉴别能力越 差 。
4、直方图均衡化适用于增强直方图呈 尖峰 分布的图像。
5、依据图像的保真度,图像压缩可分为 无损压缩 和 有损压缩
6、图像压缩是建立在图像存在 编码冗余 、 像素间冗余 、 心理视觉冗余 三种冗余基础上。
7、对于彩色图像,通常用以区别颜色的特性是 色调 、 饱和度
亮度 。
8、对于拉普拉斯算子运算过程中图像出现负值的情况,写出一种标定方法:
![]()
二、选择题(每题2分,共20分)
1、采用幂次变换进行灰度变换时,当幂次取大于1时,该变换是针对如下哪一类图像进行增强。( B )
A 图像整体偏暗 B 图像整体偏亮
C图像细节淹没在暗背景中 D图像同时存在过亮和过暗背景
2、图像灰度方差说明了图像哪一个属性。( B )
A 平均灰度 B 图像对比度
C 图像整体亮度 D图像细节
3、计算机显示器主要采用哪一种彩色模型( A )
A、RGB B、CMY或CMYK C、HSI D、HSV
4、采用模板[-1 1]T主要检测( A )方向的边缘。
A.水平 B.45° C.垂直 D.135°
5、下列算法中属于图象锐化处理的是:( C )
A.低通滤波 B.加权平均法 C.高通滤波 D. 中值滤波
6、维纳滤波器通常用于( C )
A、去噪 B、减小图像动态范围 C、复原图像 D、平滑图像
7、彩色图像增强时, C 处理可以采用RGB彩色模型。
A. 直方图均衡化 B. 同态滤波
C. 加权均值滤波 D. 中值滤波
8、__B__滤波器在对图像复原过程中需要计算噪声功率谱和图像功率谱。
A. 逆滤波 B. 维纳滤波
C. 约束最小二乘滤波 D. 同态滤波
9、高通滤波后的图像通常较暗,为改善这种情况,将高通滤波器的转移函数加上一常数量以便引入一些低频分量。这样的滤波器叫 B 。
A. 巴特沃斯高通滤波器 B. 高频提升滤波器
C. 高频加强滤波器 D. 理想高通滤波器
10、图象与灰度直方图间的对应关系是 B __
A.一一对应 B.多对一 C.一对多 D.都不
三、判断题(每题1分,共10分)
1、马赫带效应是指图像不同灰度级条带之间在灰度交界处存在的毛边现象。( √ )
2、高斯低通滤波器在选择小的截止频率时存在振铃效应和模糊现象。( × )
3、均值平滑滤波器可用于锐化图像边缘。( × )
4、高频加强滤波器可以有效增强图像边缘和灰度平滑区的对比度。( √ )
5、图像取反操作适用于增强图像主体灰度偏亮的图像。( × )
6、彩色图像增强时采用RGB模型进行直方图均衡化可以在不改变图像颜色的基础上对图像的亮度进行对比度增强。( × )
7、变换编码常用于有损压缩。( √ )
8、同态滤波器可以同时实现动态范围压缩和对比度增强。( √ )
9、拉普拉斯算子可用于图像的平滑处理。( × )
10、当计算机显示器显示的颜色偏蓝时,提高红色和绿色分量可以对颜色进行校正。( √ )
四、简答题(每题5分,共20分)
1、逆滤波时,为什么在图像存在噪声时,不能采用全滤波?试采用逆滤波原理说明,并给出正确的处理方法。
复原由退化函数退化的图像最直接的方法是直接逆滤波。在该方法中,用退化函数除退化图像的傅立叶变换来计算原始图像的傅立叶变换。
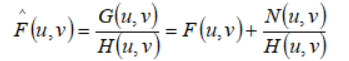
由上式可以看到,即使我们知道退化函数,也可能无法准确复原未退化的图像。因为噪声是一个随机函数,其傅氏变换未知。当退化为0或非常小的值,N(u,v)/H(u,v)之比很容易决定的值。一种解决该问题的方法实现值滤波的频率时期接近原点值。
2、当在白天进入一个黑暗剧场时,在能看清并找到空座位时需要适应一段时间,试述发生这种现象的视觉原理。
答:人的视觉绝对不能同时在整个亮度适应范围工作,它是利用改变其亮度适应级来完成亮度适应的。即所谓的亮度适应范围。同整个亮度适应范围相比,能同时鉴别的光强度级的总范围很小。因此,白天进入黑暗剧场时,人的视觉系统需要改变亮度适应级,因此,需要适应一段时间,亮度适应级才能被改变。
3、简述梯度法与Laplacian算子检测边缘的异同点?
答:梯度算子和Laplacian检测边缘对应的模板分别为
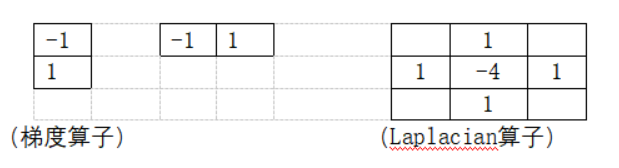
(梯度算子) (Laplacian算子) (2分)
梯度算子是利用阶跃边缘灰度变化的一阶导数特性,认为极大值点对应于边缘点;而Laplacian算子检测边缘是利用阶跃边缘灰度变化的二阶导数特性,认为边缘点是零交叉点。
相同点都能用于检测边缘,且都对噪声敏感。(1分)
4、将高频加强和直方图均衡相结合是得到边缘锐化和对比度增强的有效方法。上述两个操作的先后顺序对结果有影响吗?为什么?
答:有影响,应先进行高频加强,再进行直方图均衡化。
高频加强是针对通过高通滤波后的图像整体偏暗,因此通过提高平均灰度的亮度,使图像的视觉鉴别能力提高。再通过直方图均衡化将图像的窄带动态范围变为宽带动态范围,从而达到提高对比度的效果。若先进行直方图均衡化,再进行高频加强,对于图像亮度呈现较强的两极现象时,例如多数像素主要分布在极暗区域,而少数像素存在于极亮区域时,先直方图均衡化会导致图像被漂白,再进行高频加强,获得的图像边缘不突出,图像的对比度较差。
五、问答题(共35分)
1、设一幅图像有如图所示直方图,对该图像进行直方图均衡化,写出均衡化过程,并画出均衡化后的直方图。若在原图像一行上连续8个像素的灰度值分别为:0、1、2、3、4、5、6、7,则均衡后,他们的灰度值为多少?
(15分)
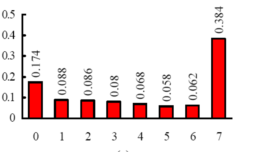
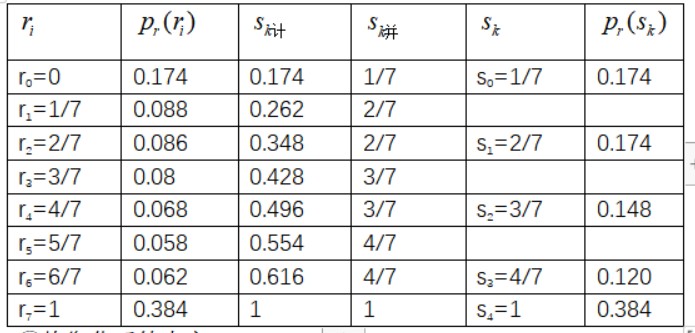
答:①,k=0,1,…7,用累积分布函数(CDF)作为变换函数T[r]处理时,均衡化的结果使动态范围增大。
|
|
|
|
|
|
|
| r0=0 | 0.174 | 0.174 | 1/7 | s0=1/7 | 0.174 |
| r1=1/7 | 0.088 | 0.262 | 2/7 |
|
|
| r2=2/7 | 0.086 | 0.348 | 2/7 | s1=2/7 | 0.174 |
| r3=3/7 | 0.08 | 0.428 | 3/7 |
|
|
| r4=4/7 | 0.068 | 0.496 | 3/7 | s2=3/7 | 0.148 |
| r5=5/7 | 0.058 | 0.554 | 4/7 |
|
|
| r6=6/7 | 0.062 | 0.616 | 4/7 | s3=4/7 | 0.120 |
| r7=1 | 0.384 | 1 | 1 | s4=1 | 0.384 |
②均衡化后的直方图:
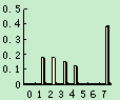
③0、1、2、3、4、5、6、7均衡化后的灰度值依次为1、2、2、3、3、4、4、7
2、对下列信源符号进行Huffman编码,并计算其冗余度和压缩率。(10分)
| 符号 | a1 | a2 | a3 | a4 | a5 | a6 |
| 概率 | 0.1 | 0.4 | 0.06 | 0.1 | 0.04 | 0.3 |
解:霍夫曼编码:
霍夫曼化简后的信源编码:
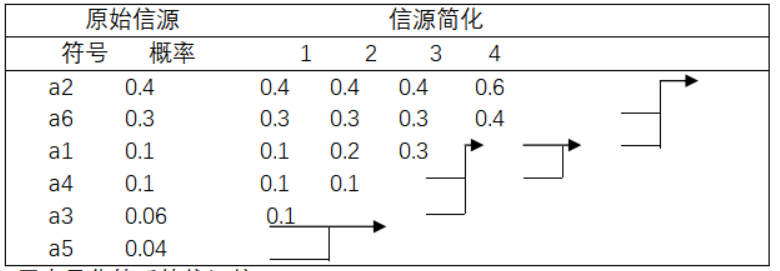
从最小的信源开始一直到原始的信源
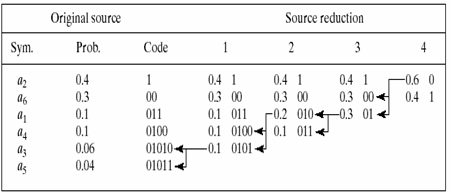
编码的平均长度:

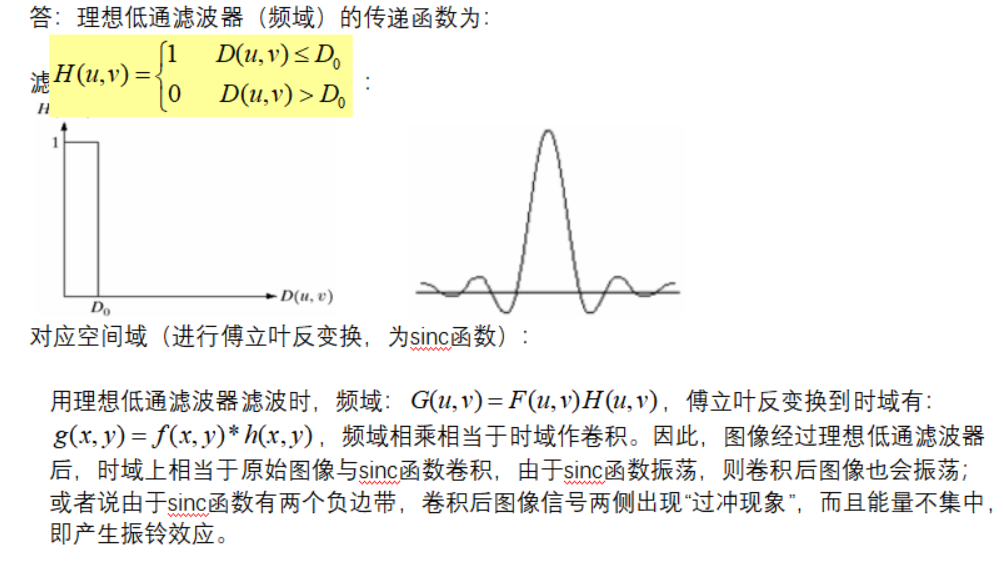
3、理想低通滤波器的截止频率选择不恰当时,会有很强的振铃效应。试从原理上解释振铃效应的产生原因。(10分)
答:理想低通滤波器(频域)的传递函数为:
1、给定 0-1 矩阵,求连通域。
https://blog.csdn.net/lxy_2011/article/details/78852414
2、写一个函数,求灰度图的直方图。
3、写一个均值滤波(中值滤波)。
4、写出高斯算子,Sobel 算子,拉普拉斯算子等,以及它们梯度方向上的区别。
sobel 算子
索贝尔算子(Sobeloperator)主要用作边缘检测,在技术上,它是一离散性差分算
子,用来运算图像亮度函数的灰度之近似值。在图像的任何一点使用此算子,将会产生对应的灰度矢量或是其法矢量

拉普拉斯算子
Laplace 算子和 Sobel 算子一样,属于空间锐化滤波操作。起本质与前面的 Spatial Filter 操作大同小异,下面就通过 Laplace 算子来介绍一下空间锐化滤波,并对 OpenCV 中提供的 Laplacian 函数进行一些说明。
- 数学原理
离散函数的导数退化成了差分,一维一阶差分公式和二阶差分公式分别为
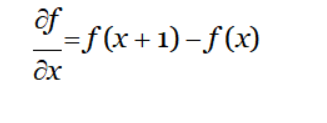

5、常用的特征提取方法。
- SIFT(尺度不变特征变换)
- SIFT 特征提取的实质
在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT 所查找到的关键点是一些十分突出、不会因光照、仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
- SIFT 特征提取的方法
- 构建 DOG 尺度空间:
模拟图像数据的多尺度特征,大尺度抓住概貌特征,小尺度注重细节特征。通过构建高斯金字塔(每一层用不同的参数σ做高斯模糊(加权)),保证图像在任何尺度都能有对应的特征点,即保证尺度不变性。
关键点搜索和定位:
确定是否为关键点,需要将该点与同尺度空间不同σ值的图像中的相邻点比较,如果该点为 max 或 min,则为一个特征点。找到所有特征点后,要去除低对比度和不稳定的边缘效应的点,留下具有代表性的关键点(比如,正方形旋转后变为菱形,如果用边缘做识别,4 条边就完全不一样,就会错误;如果用角点识别,则稳定一些)。去除这些点的好处是增强匹配的抗噪能力和稳定性。最后,对离散的点做曲线拟合,得到精确的关键点的位置和尺度信息。
方向赋值:
为了实现旋转不变性,需要根据检测到的关键点的局部图像结构为特征点赋值。具体做法是用梯度方向直方图。在计算直方图时,每个加入直方图的采样点都使用圆形高斯函数进行加权处理,也就是进行高斯平滑。这主要是因为 SIFT 算法只考虑了尺度和旋转不变形,没有考虑仿射不变性。通过高斯平滑,可以使关键点附近的梯度幅值有较大权重,从而部分弥补没考虑仿射不变形产生的特征点不稳定。注意,一个关键点可能具有多个关键方向,这有利于增强图像匹配的鲁棒性。
关键点描述子的生成:
关键点描述子不但包括关键点,还包括关键点周围对其有贡献的像素点。这样可使关键点有更多的不变特性,提高目标匹配效率。在描述子采样区域时,需要考虑旋转后进行双线性插值,防止因旋转图像出现白点。同时,为了保证旋转不变性,要以特征点为中心,在附近领域内旋转θ角,然后计算采样区域的梯度直方图,形成 n 维 SIFT 特征矢量(如 128-SIFT)。最后,为了去除光照变化的影响,需要对特征矢量进行归一化处理。
- SIFT 特征提取的优点
1、SIFT 特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;
2、独特性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配;
3、多量性,即使少数的几个物体也可以产生大量的 SIFT 特征向量;高速性,经优化的 SIFT 匹配算法甚至可以达到实时的要求;
4、可扩展性,可以很方便的与其他形式的特征向量进行联合;
5、需要较少的经验主义知识,易于开发。
SIFT 特征提取的缺点
1、实时性不高,因为要不断地要进行下采样和插值等操作;
2、有时特征点较少(比如模糊图像);
3、对边缘光滑的目标无法准确提取特征(比如边缘平滑的图像,检测出的特征点过少,对圆更是无能为力)。
- SIFT 特征提取可以解决的问题:
目标的自身状态、场景所处的环境和成像器材的成像特性等因素影响图像配准/目标识别跟踪的性能。而 SIFT 算法在一定程度上可解决:
目标的旋转、缩放、平移(RST)
图像仿射/投影变换(视点 viewpoint) 光照影响(illumination)
目标遮挡(occlusion) 杂物场景(clutter)
噪声
- HOG(方向梯度直方图)
- HOG 特征提取的实质
通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog 特征结合 SVM 分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。
- HOG 特征提取的方法
1、灰度化;
2、采用 Gamma 校正法对输入图像进行颜色空间的标准化(归一化),目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
3、计算图像每个像素的梯度(包括大小和方向),主要是为了捕获轮廓信息,同时进一步弱化光照的干扰;
4、将图像划分成小 cells(例如 6*6 像素/cell);
5、统计每个 cell 的梯度直方图(不同梯度的个数),即可形成每个 cell 的
descriptor;
6、将每几个 cell 组成一个 block(例如 3*3 个 cell/block),一个 block 内所有 cell
的特征 descriptor 串联起来便得到该 block 的 HOG 特征 descriptor。
7、将图像 image 内的所有 block 的 HOG 特征 descriptor 串联起来就可以得到该image(你要检测的目标)的 HOG 特征 descriptor 了。这个就是最终的可供分类使用的特征向量了。
6、常用的目标检测方法。
- 滑动窗口目标检测
- R-CNN 系列 - Two Stage 目标检测算法
1、R-CNN
2、Fast R-CNN
3、Faster R-CNN R-FCN
⚫ YOLO、SSD - One Stage 目标检测算法
1 、 YOLO : You Only Look Once
2、SSD : Single Shot MultiBox Detector
7、常用的边缘提取方法。
Canny 算子边缘检测
Canny 边缘检测算法基于一个多阶边缘算子,是由 John F. Canny 于 1986 年首先提出的[46],他不但给出了边缘检测的方法,也提出了边缘检测的计算理论。Canny
Sobel 算子边缘检测同上
8、常用的插值方法。
最邻近元法
双线性内插法
三次内插法
9、常用的图像分割算法。
基于阈值的分割方法
灰度阈值分割法是一种最常用的并行区域技术,它是图像分割中应用数量最多的一类。
其中 T 为阈值;对于物体的图像元素, g(i, j) =1,对于背景的图像元素g(i, j) =0。
- 基于边缘的分割方法
基于边缘的分割方法是指通过边缘检测,即检测灰度级或者结构具有突变的地方,确定一个区域的终结,即另一个区域开始的地方。不同的图像灰度不同,边界处一般有明显的边缘,利用此特征可以分割图像。
- 基于小波变换的分割方法
基于小波变换的阈值图像分割方法的基本思想是首先由二进小波变换将图像的直方图分解为不同层次的小波系数,然后依据给定的分割准则和小波系数选择阈值门限,最后利用阈值标出图像分割的区域。整个分割过程是从粗到细,由尺度变化来控制,即起始分割由粗略的 L2(R)子空间上投影的直方图来实现,如果分割不理想,则利用直方图在精细的子空间上的小波系数逐步细化图像分割。分割算法的计算会与图像尺寸大小呈线性变化。
- 基于神经网络的分割方法
近年来,人工神经网络识别技术已经引起了广泛的关注,并应用于图像分割。基于神经网络的分割方法的基本思想是通过训练多层感知机来得到线性决策函数,然后用决策函数对像素进行分类来达到分割的目的。这种方法需要大量的训练数据。神经网络存在巨量的连接,容易引入空间信息,能较好地解决图像中的噪声和不均匀问题。选择何种网络结构是这种方法要解决的主要问题。
10、写一个图像 resize 函数(放大和缩小)。
11、彩色图像、灰度图像、二值图像和索引图像区别?(索引图像到底是啥?)
- 彩色图像:每个像素由 R、G、B 三个分量表示,每个通道取值范围 0~255。数据类型一般为 8 位无符号整形。
- 灰度图像:每个像素只有一个采样颜色的图像,这类图像通常显示为从最暗黑色到最亮的白色的灰度。
- 二值图像(黑白图像):每个像素点只有两种可能,0 和 1.0 代表黑色,1 代表白色。数据类型通常为 1 个二进制位。
- 索引图像,即它的文件结构比较复杂,除了存放图像的二维矩阵外,还包括一个称之为颜色索引矩阵 MAP 的二维数组。MAP 的大小由存放图像的矩阵元素值域决定,如矩阵元素值域为[0,255],则 MAP 矩阵的大小为 256Ⅹ3,用 MAP=[RGB]表示。MAP 中每一行的三个元素分别指定该行对应颜色的红、绿、蓝单色值,MAP 中每一行对应图像矩阵像素的一个灰度值,如某一像素的灰度值为 64,则该像素就与 MAP 中的第64 行建立了映射关系,该像素在屏幕上的实际颜色由第 64 行的[RGB]组合决定。也就是说,图像在屏幕上显示时,每一像素的颜色由存放在矩阵中该像素的灰度值作为索引通过检索颜色索引矩阵 MAP 得到。索引图像的数据类型一般为 8 位无符号整形
(int8),相应索引矩阵 MAP 的大小为 256Ⅹ3,因此一般索引图像只能同时显示 256种颜色,但通过改变索引矩阵,颜色的类型可以调整。索引图像的数据类型也可采用双精度浮点型(double)。索引图像一般用于存放色彩要求比较简单的图像,如 Windows中色彩构成比较简单的壁纸多采用索引图像存放,如果图像的色彩比较复杂,就要用到 RGB 真彩色图像。
12、深度学习中目标检测的常用方法,异同
13、给定摄像头范围和图像大小求分辨率。
14、如何检测图片中的汽车,并识别车型,如果有遮挡怎么办?
15、数字识别的流程。
16、介绍神经网络、SVM、AdaBoost、kNN…(每一个都可能深入问各种细节)
17、写梯度下降代码。
18、卷积神经网络与神经网络的区别。
以图片为例,神经网络是将图片的所有像素点作为输入然后训练网络模型进行预测,而卷积神经网络则是先通过不同的卷积核对原始图像进行卷积提取特征,然后池化,然后反复这样的操作最后提取能够标识图片特征的像素点,最后将这些能够代表图片特征的像素点作为神经网络的输入进行预测。
19、卷积层的作用、pooling 层的作用,全连接层的作用。
fc:
1、分类器的作用。对前层的特征进行一个加权和,(卷积层是将数据输入映射到隐层特征空间)将特征空间通过线性变换映射到样本标记空间(也就是 label);
2、1*1 卷积等价于 fc;跟原 feature map 一样大小的卷积也等价于 fc,也就是输入是一个 5*3*3 的 feature map,用一个 3x3x5 的卷积去计算就是 fc 。
3、全连接层参数冗余,用 global average pooling 替代。在 feature map 每个channel 上使用 gap,然后得到 channel 个结果,分别对应相应的类别的 confidence score,最后输入给 softmax。这样做减少参数,防止过拟合。
4、迁移学习中,目标域和源域差别较大,不用 fc 的网络比用 fc 的网络效果差
5、卷积层本来就是全连接的一种简化形式:不全连接+参数共享,按照局部视野的启发, 把局部之外的弱影响直接抹为零影响,同时还保留了空间位置信息。这样大大减少了参数并且使得训练变得可控。
6、fc 利用的是上一层所有输入来计算,抛弃了卷积层不同位置的权值共享。对它来说, 输入的不同位置出现同一个 pattern 是不等价的,因此不适合用于输出对于每个位置寻找类似 pattern 的 task,比如 segmentation、edge detection 以及 end-to-end 的object detection 等等,而比较适合用于 classification。
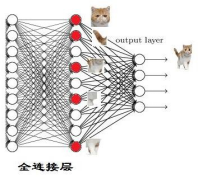
conv: 1.相当于一个特征提取器来提取特征
2.提供了位置信息
3.减少了参数个数pooling: 1.提取特征
2.减少参数
激活函数:增加网络的非线性表达能力
20、过拟合和欠拟合分别是什么,如何改善。
21、1x1 卷积和的作用。
1*1 卷积等价于 fc;跟原 feature map 一样大小的卷积也等价于 fc
22、计算卷积神经网络某一层参数量。
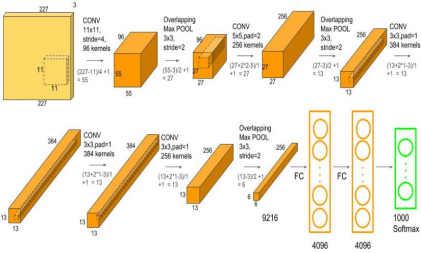

22、opencv 遍历像素的方式?
- 使用 at<typename>(i,j)
- 使用指针来遍历(更高效比第一个)
- 采用.data 进行遍历(更高效比第一个)
23、LBP 原理?
主要思想:原始的 LBP 算子定义在像素 3*3 的邻域内,以邻域中心像素为阈值,相邻的 8 个像素的灰度值与邻域中心的像素值进行比较,若周围像素大于中心像素值,则该像素点的位置被标记为 1,否则为 0。这样,3*3 邻域内的 8 个点经过比较可产生 8 位二进制数, 将这 8 位二进制数依次排列形成一个二进制数字,这个二进制数字就是中心像素的 LBP 值,
LBP 值共有 2828 种可能,因此 LBP 值有 256 种。中心像素的 LBP 值反映了该像素周围区域的纹理信息。 (备注:计算 LBP 特征的图像必须是灰度图,如果是彩色图,需要先转换成灰度图。)
24、HOG 特征计算过程,还有介绍一个应用 HOG 特征的应用?
1、HOG 特征:
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog 特征结合 SVM 分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。需要提醒的是,HOG+SVM 进行行人检测的方法是法国研究人员 Dalal 在 2005 的 CVPR 上提出的,而如今虽然有很多行人检测算法不断提出, 但基本都是以 HOG+SVM 的思路为主。
- 主要思想:
在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。(本质:梯度的统计信息,而梯度主要存在于边缘的地方)。
- 具体的实现方法是:
首先将图像分成小的连通区域,我们把它叫细胞单元。然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。
- 提高性能:
把这些局部直方图在图像的更大的范围内(我们把它叫区间或 block)进行对比度归一化
(contrast-normalized),所采用的方法是:先计算各直方图在这个区间(block)中的密度,然后根据这个密度对区间中的各个细胞单元做归一化。通过这个归一化后,能对光照变化和阴影获得更好的效果。
- 优点:
与其他的特征描述方法相比,HOG 有很多优点。首先,由于 HOG 是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此 HOG 特征是特别适合于做图像中的人体检测的。
2、HOG 特征提取算法的实现过程: 大概过程:
HOG 特征提取方法就是将一个 image(你要检测的目标或者扫描窗口): 1)灰度化(将图像看做一个 x,y,z(灰度)的三维图像);
2)采用 Gamma 校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰; 3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
- 将图像划分成小 cells(例如 6*6 像素/cell);
- 统计每个 cell 的梯度直方图(不同梯度的个数),即可形成每个 cell 的 descriptor; 6)将每几个 cell 组成一个 block(例如 3*3 个 cell/block),一个 block 内所有 cell 的特征 descriptor 串联起来便得到该 block 的 HOG 特征 descriptor。
7)将图像 image 内的所有 block 的 HOG 特征 descriptor 串联起来就可以得到该image(你要检测的目标)的 HOG 特征 descriptor 了。这个就是最终的可供分类使用的特征向量了。
25、opencv 里面 mat 有哪些构造函数?
- 创建 Mat
1、无参构造方法: Mat::Mat()
2、创建行数为 rows,列为 col,类型为 type 的图像(图像元素类型,如 CV_8UC3 等) Mat::Mat(int rows, int cols, int type)
3、创建大小为 size,类型为 type 的图像
Mat::Mat(Size size, int type)
4、创建行数为 rows,列数为 col,类型为 type 的图像,并将所有元素初始化为值 s Mat::Mat(int rows, int cols, int type, const Scalar& s)
5、创建大小为 size,类型为 type 的图像,并将所有元素初始化为值 s Mat::Mat(Size size, int type, const Scalar& s)
6、将 m 赋值给新创建的对象,此处不会对图像数据进行复制,m 和新对象 共用图像数据
Mat::Mat(const Mat& m)
7、创建行数为 rows,列数为 col,类型为 type 的图像,此构造函数不创建图像数据所需内存,而是直接使用 data 所指内存,图像的行步长由 step 指定
Mat::Mat(int rows, int cols, int type, void* data, size_t step=AUTO_STEP) 8、创建大小为 size,类型为 type 的图像,此构造函数不创建图像数据所需内存,而是直接使用 data 所指内存,图像的行步长由 step 指定
Mat::Mat(Size size, int type, void* data, size_t step=AUTO_STEP)
9、创建的新图像为 m 的一部分,具体的范围由 rowRange 和 colRange 指定,此构造函数也不进行图像数据的复制操作,新图像与 m 共用图像数据Mat::Mat(const Mat& m, const Range& rowRange, const Range& colRange)
10、创建的新图像为 m 的一部分,具体的范围 roi 指定,此构造函数也不进行图像数据的复制操作,新图像与 m 共用图像数据
Mat::Mat(const Mat& m, const Rect& roi)
- Mat 中相关成员的意义
1、data
Mat 对象中的一个指针,指向存放矩阵数据的内存(uchar* data) 2、dims
矩阵的维度,3*4 的矩阵维度为 2 维,3*4*5 的矩阵维度为 3 维
3、channels
矩阵通道,矩阵中的每一个矩阵元素拥有的值的个数,比如说 3 * 4 矩阵中一共 12 个元素,如果每个元素有三个值,那么就说这个矩阵是 3 通道的,即 channels = 3。常见的是一张彩色图片有红、绿、蓝三个通道。
4、depth
深度,即每一个像素的位数,也就是每个通道的位数。在 opencv 的 Mat.depth()中得到的是一个 0 – 6 的数字,分别代表不同的位数:enum { CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6 },可见 0 和 1 都
代表 8 位, 2 和 3 都代表 16 位,4 和 5 代表 32 位,6 代表 64 位。
5、elemSize
矩阵中每个元素的大小,每个元素包含 channels 个通道。如果 Mat 中的数据的数据类型是 CV_8U 那么 elemSize = 1;是 CV_8UC3 那么 elemSize = 3,是 CV_16UC2 那么 elemSize = 4。
6、elemSize1
矩阵中数据类型的大小,即 elemSize/channels,也就是 depth 对应的位数。
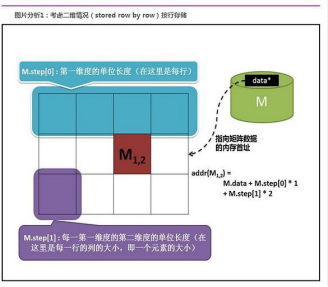
7、step
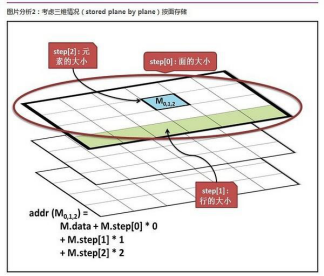
是一个数组,定义了矩阵的布局,参考下图若矩阵有 n 维,则 step 数组大小为 n
step[n-1] = elemSize(每个矩阵元素的数据大小) step[n-2] = size(1 维)*elemSize
step[n-3] = size(2 维)*size(1 维)*elemSize
...
step[0] = size(n-1 维)*size(n-2 维)*...size(1 维)*elemSize 8、step1
step1 也是一个数组,为 step/elemSize1,若矩阵有 n 维,则 step1[n- 1]=channels。
9、type
矩阵元素的类型,即创建 Mat 时传递的类型,例如 CV_8UC3、CV_16UC2 等。
26、如何将 buffer 类型转化为 mat 类型? 27、opencv 如何读取 png 格式的图片? 28、opencv 如何读取内存图片?
29、opencv 里面有哪些库?
一、core 模块
1、Mat - 基本图像容器
二、imgproc 模块
1、图像平滑处理
-
- 高斯滤波器 (Gaussian Filter)
- 中值滤波器 (Median Filter)
- 双边滤波 (Bilateral Filter) 2、形态学变换
-
- 腐蚀(Erosion)
- 膨胀 (Dilation)
- 开运算 (Opening)
- 闭运算(Closing)
- 形态梯度(Morphological Gradient)
- 顶帽(Top Hat)
- 黑帽(Black Hat) 3、图像金字塔
4、阈值操作
5、给图像添加边界
6、图像卷积
-
- 函数 filter2D 就可以生成滤波器
- Sobel 导数
- Laplace 算子
-
- Canny 边缘检测
- 霍夫线变换
- 霍夫圆变换
7、 Remapping 重映射
8、 仿射变换
9、 直方图均衡化
10、模板匹配
30、用过 opencv 里面哪些函数?
31、opencv 里面为啥是 bgr 存储图片而不是人们常听的 rgb?
32、你说 opencv 里面的 HOG+SVM 效果很差?他就直接来了句为啥很差?差了就不改了? 差了就要换其他方法?
33、讲讲 HOG 特征?他在 dpm 里面怎么设计的,你改过吗?HOG 能检测边缘吗?里面的核函数是啥?那 hog 检测边缘和 canny 有啥区别?
34、如何求一张图片的均值?
35、如何写程序将图像放大缩小?
36、如何遍历一遍求一张图片的方差?
37、高斯噪声和椒盐噪声
38、常用的图像空间
39、HSV 和 HSI 区别:
解释 1、hsv 里面的 v 指的是 RGB 里面的最大的值,v = max(max(r,g),b); 而 HSI 的I 是平均值,I=(r+g+b) / 3; 另外两个分量应该是一样的,如果只是需要 h 或者 s 的话可以用 matlab 自带的 rgb2hsv 了。
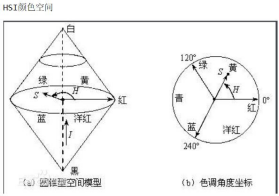
解释 2、HSV 颜色空间
HSV(hue,saturation,value)颜色空间的模型对应于圆柱坐标系中的一个圆锥形子集,圆锥的顶面对应于 V=1. 它包含 RGB 模型中的 R=1,G=1,B=1 三个面,所代表的颜色较亮。色彩 H 由绕 V 轴的旋转角给定。红色对应于角度 0°,绿色对应于角度 120°,蓝色对应于角度 240°。在 HSV 颜色模型中,每一种颜色和它的补色相差 180° 。 饱和度 S 取值从 0 到 1,所以圆锥顶面的半径为 1。HSV 颜色模型所代表的颜色域是 CIE 色度图的一个子集,这个 模型中饱和度为百分之百的颜色,其纯度一般小于百分之百。在圆锥的顶点(即原点)处,V=0,H 和 S 无定义, 代表黑色。圆锥的顶面中心处 S=0,V=1,H 无定义,代表白色。从该点到原点代表亮度渐暗的灰色,即具有不同 灰度的灰色。对于这些点, S=0,H 的值无定义。可以说,HSV 模型中的 V 轴对应于 RGB 颜色空间中的主对角线。 在圆锥顶面的圆周上的颜色,V=1,S=1,这种颜色是纯色。HSV 模型对应于画家配色的方法。画家用改变色浓和 色深的方法从某种纯色获得不同色调的颜色,在一种纯色中加入白
色以改变色浓,加入黑色以改变色深,同时 加入不同比例的白色,黑色即可获得各种不同的色调。
HSI 色彩空间是从人的视觉系统出发,用色调(Hue)、色饱和度(Saturation 或Chroma)和亮度 (Intensity 或 Brightness)来描述色彩。HSI 色彩空间可以用一个圆锥空间模型来描述。用这种 描述 HIS 色彩空间的圆锥模型相当复杂,但确能把色调、亮度和色饱和度的变化情形表现得很清楚。 通常把色调和饱和度通称为色度,用来表示颜色的类别与深浅程度。由于人的视觉对亮度的敏感 程度远强于对颜色浓淡的敏感程度,为了便于色彩处理和识别,人的视觉系统经常采用 HSI 色彩空间, 它比 RGB 色彩空间更符合人的视觉特性。在图像处理和计算机视觉中大量算法都可在 HSI 色彩空间中 方便地使用,它们可以分开处理而且是相互独立的。因此,在 HSI 色彩空间可以大大简化图像分析 和处理的工作量。HSI 色彩空间和 RGB 色彩空间只是同一物理量的不同表示法,因而它们之间存在着 转换关系。
40、简述你熟悉的聚类算法并说明其优缺点。
41、常用的图像空间。
RGB 颜色空间 :在计算机技术中使用最广泛的颜色空间是 RGB 颜色空间,它是一种与人的视觉系统结构密切相关的模型。根据人眼睛的结构,所有的颜色都可以看成三个基本颜色-红色(red)、绿色(green)和蓝色(blue)的不同组合,大部分显示器都采用这种颜色模型。对一幅三通道彩色数字图像对每个图像像素(x,y),需要指出三个矢量分量 R、G、B
CMY 是工业印刷采用的颜色空间。它与 RGB 对应。简单的类比 RGB 来源于是物体发光,而 CMY 是依据反射光得到的。具体应用如打印机:一般采用四色墨盒,即 CMY 加黑色墨盒。青(C)、品(M)、黄(Y)
HSV(Hue, Saturation, Value)是根据颜色的直观特性由 A. R. Smith 在 1978 年创建的一种颜色空间, 也称六角锥体模型(Hexcone Model)。HSV 色系对用户来说是一种直观的颜色模型,对于颜色,人们直观的会问”什么颜色?深浅如何?明暗如何?“, 而 HSV 色系则直观的表示了这些信息。每一种颜色都是由色相(Hue,简 H),饱和度
(Saturation,简 S)和色明度(Value,简 V)所表示的。这个模型中颜色的参数分别是:色调(H),饱和度(S),亮度(V)。
HSI〔Hue-Saturation-Intensity(Lightness),HSI 或 HSL〕:当人观察一个彩色物
体时, 用色调、 饱和度、 亮度来描述物体的颜色。 HSI 〔 Hue-Saturation- Intensity(Lightness),HSI 或 HSL〕颜色模型用 H、S、I 三参数描述颜色特性,其中H 定义颜色的波长,称为色调;S 表示颜色的深浅程度,称为饱和度;I 表示强度或亮度。在 HSI 颜色模型的双六棱锥表示,I 是强度轴,色调 H 的角度范围为[0,2π],其中,纯红色的角度为 0,纯绿色的角度为 2π/3,纯蓝色的角度为 4π/3。
Lab 颜色空间颜色空间用于计算机色调调整和彩色校正。它独立于设备的彩色模型实现。这一方法用来把设备映射到模型及模型本社的彩色分布质量变化。
YUV(亦称 YCrCb)是被欧洲电视系统所采用的一种颜色编码方法。YUV 主要用于优化彩色视频信号的传输,使其向后相容老式黑白电视。
42、简述你熟悉的聚类算法并说明其优缺点。
43、请描述以下任一概念:SIFT/SURF LDA/PCA
44、请说出使用过的分类器和实现原理。
45 、Random Forest 的随机性表现在哪里。
46、Graph-cut 的基本原理和应用。
47、 GMM 的基本原理和应用。
48、用具体算法举例说明监督学习和非监督学习的区别
49、为什么要用数字信号处理
50、小波变换原理
51、3A 算法,图像降噪,ISP 算法,bm3d 算法原理,相机传感器传输的格式
52、机器学习实现车牌识别
53、红黑树,二叉平衡树的原理和应用
54、简述 hough 变换的原理。请列举一些你觉得能够用 HOUGHT 变换提取的形状。理由是什么?
55、图像特征:了解哪些图像像相关的特征(特征描写叙述,特征算子)。并举例用什么地方?
56 摄像机拍摄图像与现实世界是什么变换?在这样的变换中有哪些量不变的?请写出这样的变换的代数表达式?
57、Deep Learning 听说过多少,并举出眼下哪些领域应用到 Deep learning 技术?
58、图像增强与图像恢复是否是同一个概念?假设是。请解释什么是图像增强(图像恢复);假设不是,请说明其各自特点和应用领域,以及差异?
一个很好的练习教程
https://zhuanlan.zhihu.com/p/112057607
中文原版:https://github.com/gzr2017/ImageProcessing100Wen
最后
以上就是现实酒窝最近收集整理的关于重拾图形图像处理 ---- 笔试题 一个很好的练习教程的全部内容,更多相关重拾图形图像处理内容请搜索靠谱客的其他文章。








发表评论 取消回复