Spark(一)概述
- 一.概述
- 1.了解Spark
- 2.Spark核心组件
- 2.1 两大计算核心组件
- 2.2 两大资源核心组件
- 2.3 ApplicationMaster
- 2.4 并行度
- 3.DAG
- 二.Spark环境搭建
- 1.Local环境模式
- 2.Standalone
- 3.Standalone-HA
- 4.SparkOnYarn
- (1)两种模式
- (2)准备工作
- (3)配置Spark相关的jar包
- (4)启动
- (5)两种模式演示 — 以SparkPi为例
- 三.Spark入门案例 — WordCount
- 1.本地测试
- 2.Yarn测试
一.概述
1.了解Spark

Spark是一个在单节点机器或集群上,支持机器学习的大数据领域统一的数据分析/计算/处理引擎
Spark产生背景
Hadoop的mapreduce存在局限性:
1)只有map和reduce操作
2)mapreduce的中间结果落地到磁盘,不能充分的利用内存
3)适合批处理所以不能进行实时计算
4)编程过于复杂
为什么使用spark
spark可以进行实时的计算,因为使用内存相对于mepreduce速度更快
spark中间结果放到内存,mapreduce中间结果落地到磁盘。速度上比mapreduce要更快
spark大部分算子都没有shffer阶段,不会频繁的落地磁盘,降低磁盘IO,并且省略了排序的步骤
Spark组成
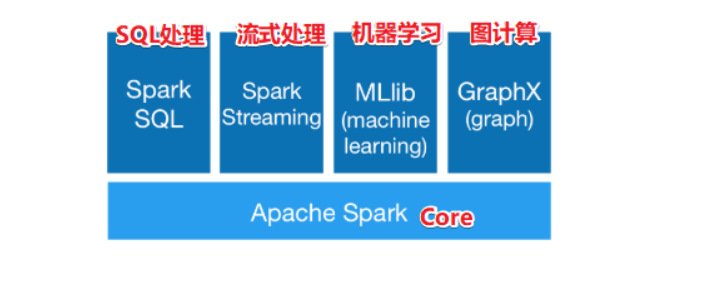
Spark core
实现了Spark的基本功能、包括任务调度、内存管理、错误恢复与存储系统交互等模块。spark core中还包含了对弹性分布式数据集(resileent distributed dataset)的定义
RDD弹性分布式数据集,是个抽象的概念,RDD是只读的,能通过RDD的转换算子产生新的RDD
Spark SQL
是spark用来操作结构化数据的程序,通过SPARK SQL,我们可以使用SQL或者HIVE(HQL)来查询数据,支持多种数据源,比如HIVE表就是JSON等,除了提供SQL查询接口,还支持将SQL和传统的RDD结合,开发者可以在一个应用中同时使用SQL和编程的方式(API)进行数据的查询分析
Spark Streaming
是Spark提供的对实时数据进行流式计算的组件,比如网页服务器日志,或者是消息队列都是数据流
MLLib
是Spark中提供常见的机器学习功能的程序库,包括很多机器学习算法,比如分类、回归、聚类、协同过滤等
GraphX
是用于图计算,比如社交网络的朋友关系图
2.Spark核心组件
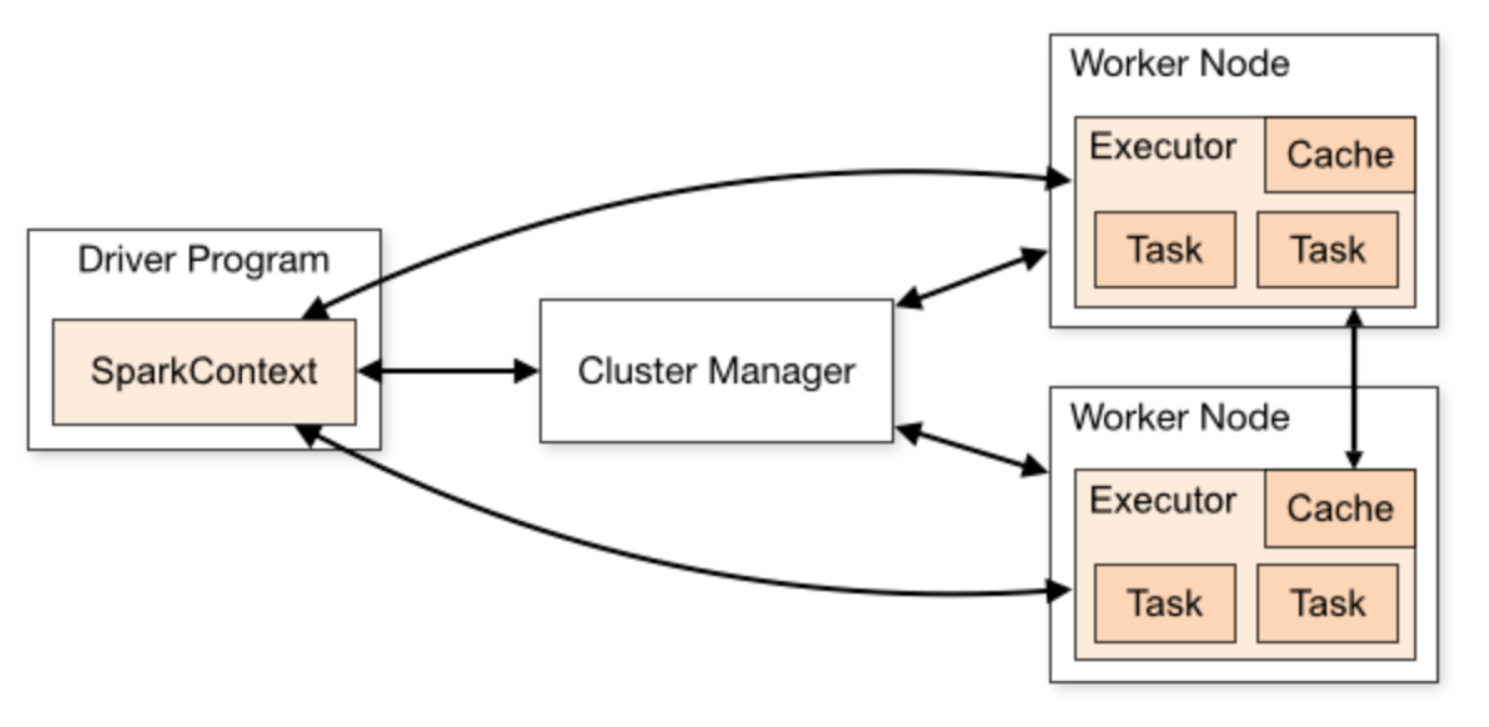
2.1 两大计算核心组件
1.Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作
Driver 在Spark 作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在Executor之间调度任务(task)
- 跟踪Executor的执行情况
- 通过UI展示查询运行情况
实际上,我们无法准确地描述Driver 的定义,因为在整个的编程过程中没有看到任何有关Driver 的字眼。所以简单理解,所谓的Driver就是驱使整个应用运行起来的程序,也称之为Driver类
2.Spark Executor是集群中工作节点(Worker)中的一个JVM进程,负责在Spark作业中运行具体任务(task),任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor节点上继续运行
Executor 有两个核心功能
- 负责运行组成Spark应用的任务,并将结果返回给驱动器进程
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD 是直接缓存在Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算
Spark Executor是集群中运行在工作节点(Worker)中的一个JVM进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点Executor的内存大小和使用的虚拟CPU核(Core)数量
–num-executors 配置Executor的数量
–executor-memory 配置每个Executor的内存大小
–executor-cores 配置每个Executor的虚拟 CPU core 数量
2.2 两大资源核心组件
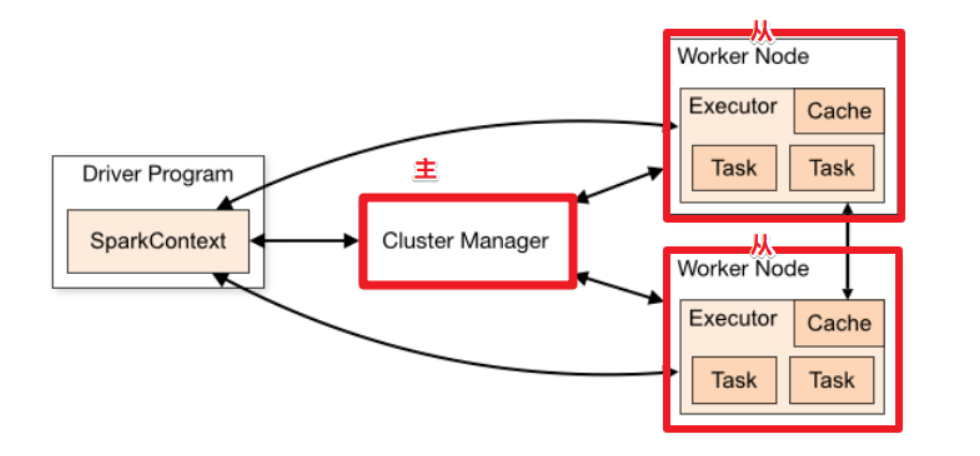
Master(cluster manager)& Worker
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于Yarn 环境中的 RM, 而Worker也是进程,一个 Worker运行在集群中的一台服务器上,由Master分配资源对数据进行并行的处理和计算,类似于Yarn环境中NM
2.3 ApplicationMaster
Hadoop用户向YARN 集群提交应用程序时,提交程序中应该包含ApplicationMaster,用于向资源调度器申请执行任务的资源容器Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况
说的简单点就是,ResourceManager(资源)和Driver(计算)之间的解耦合靠的就是ApplicationMaster
2.4 并行度
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改
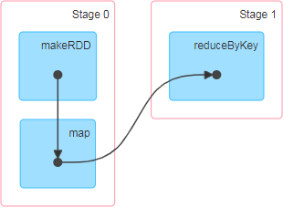
3.DAG
大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop 所承载的MapReduce,它将计算分为两个阶段,分别为 Map 阶段 和 Reduce 阶段。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个Job 的串联,以完成一个完整的算法,例如迭代计算。 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持DAG 的框架被划分为第二代计算引擎。如Tez以及更上层的Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的Tez 和Oozie 来说,大多还是批处理的任务。接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 ob内部的DAG支持(不跨越 Job),以及实时计算
这里所谓的有向无环图,并不是真正意义的图形,而是由Spark程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观, 更便于理解,可以用于表示程序的拓扑结构。DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环
二.Spark环境搭建
Spark依赖于Hadoop,建议有Hadoop环境再搭建Spark
1.Local环境模式
前提准备
-
一台Linux服务器
-
JDK8
JDK8下载
JDK8安装 -
Linux环境不需要SDK(本地环境需要)
Scala安装及语言入门 -
Spark安装包(文章末网盘)
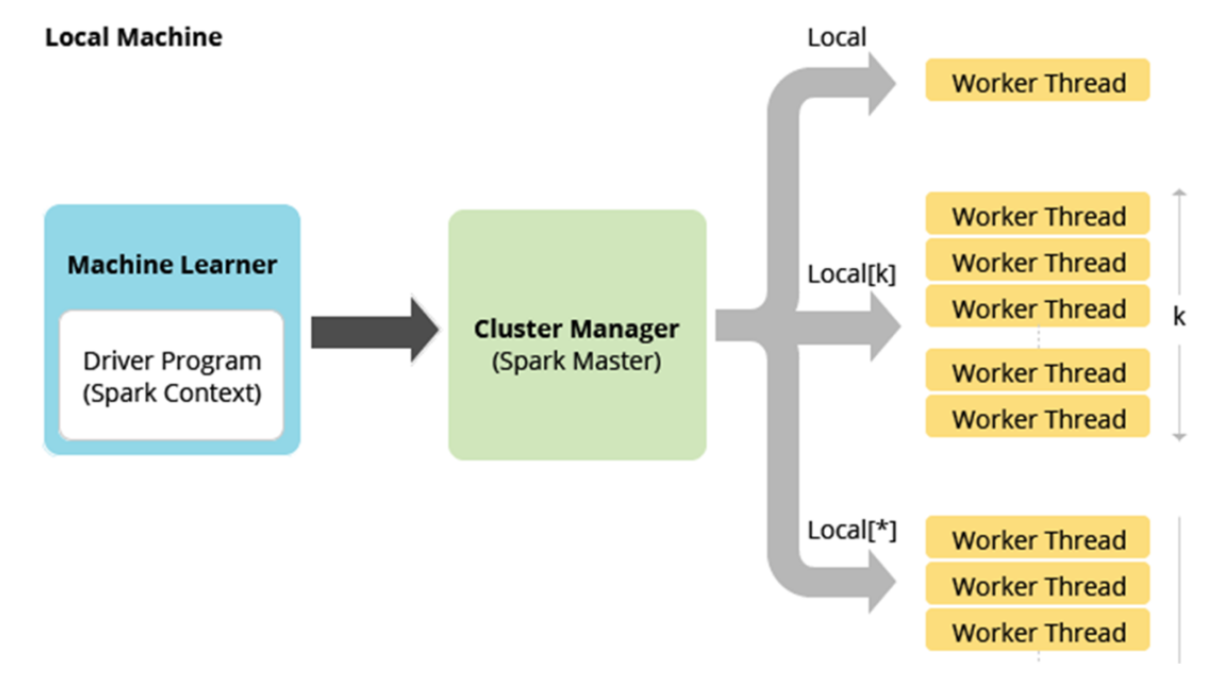
Local原理
多个线程模拟Worker Thread
安装步骤
- 上传安装包到一个文件下,解压
tar -zxvf spark.tgz -C /opt/module
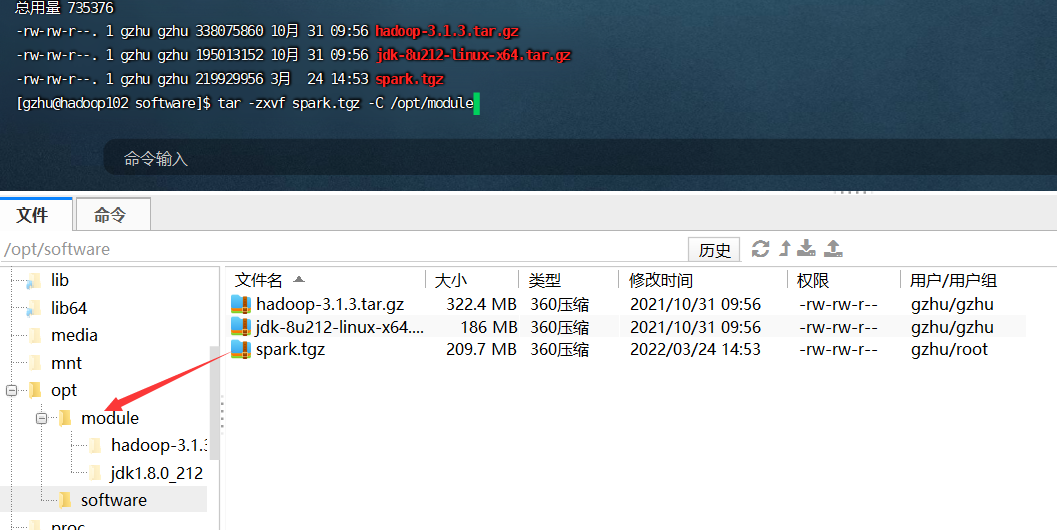
2.文件目录
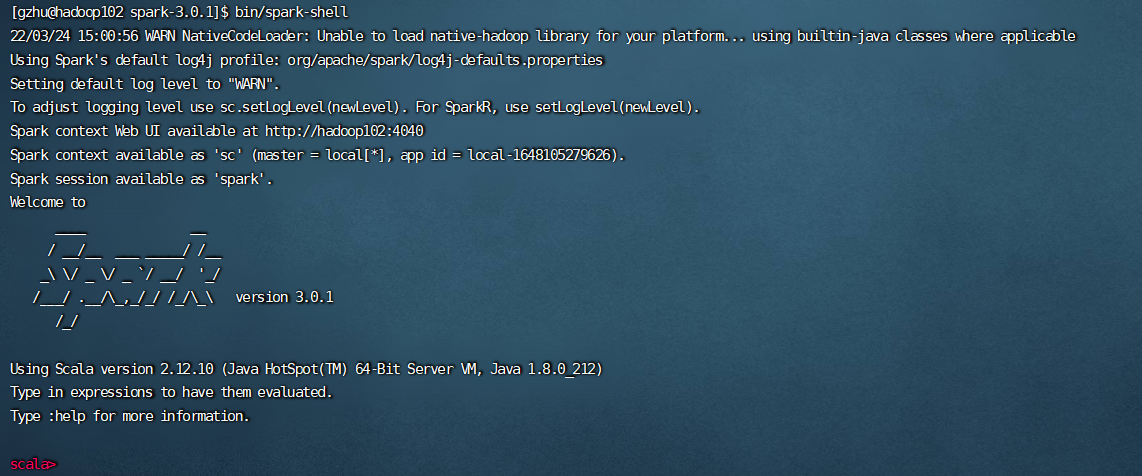
启动
[gzhu@hadoop102 spark-3.0.1]$ bin/spark-shell
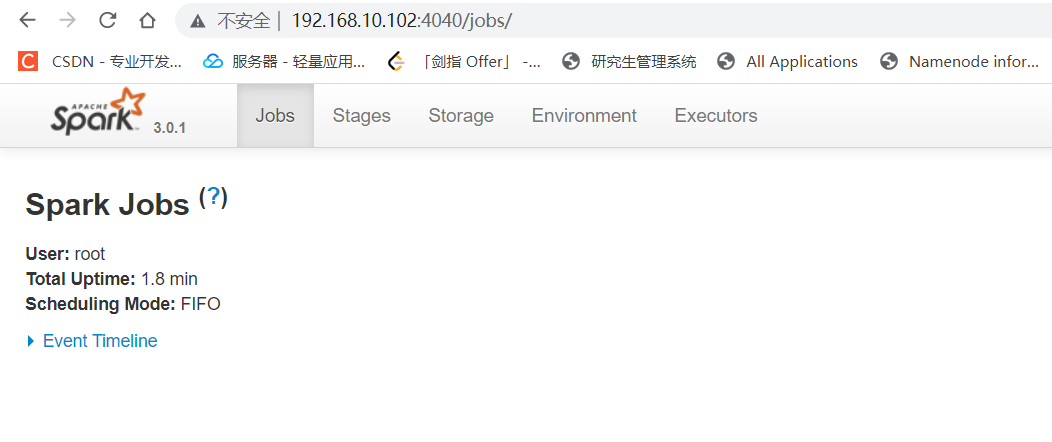
访问:ip:4040
测试
在某个目录下创建一个words.txt文件
hello me you her
hello me you
hello me
hello
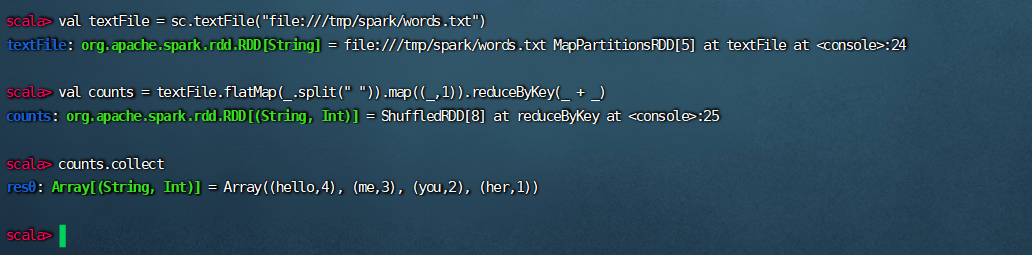
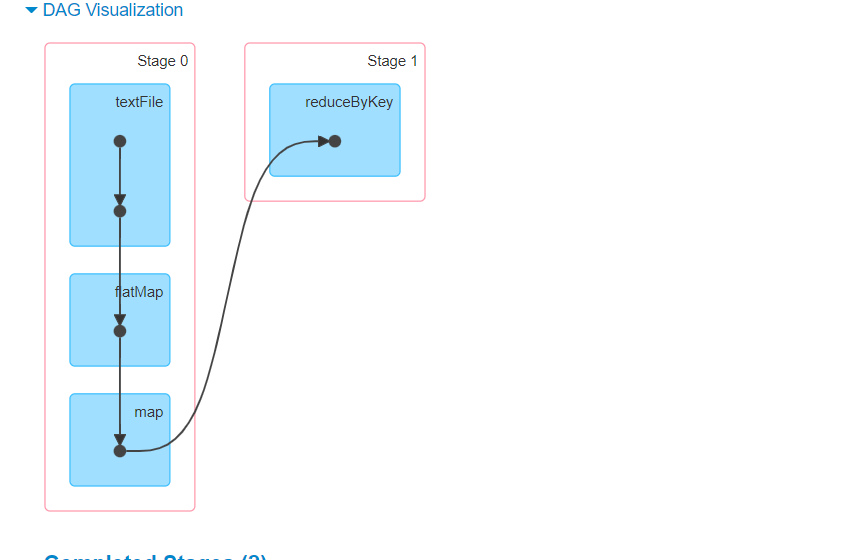
val textFile = sc.textFile("file:///tmp/spark/words.txt")
val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
counts.collect
2.Standalone
前提准备
- 三台服务器
- JDK1.8
- Hadoop环境
Hadoop概述
原理
一台做主,两台做从
配置步骤
1.集群规划
-
node1:master
-
ndoe2:worker/slave
-
node3:worker/slave
2.配置slaves/workers
进入配置目录
cd /opt/module/spark-3.0.1/conf
修改配置文件名称
mv slaves.template slaves
vim slaves
添加两个从节点地址
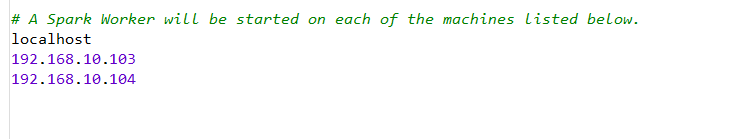
3.配置master
进入配置目录
cd /opt/module/spark-3.0.1/conf
修改配置文件名称
mv spark-env.sh.template spark-env.sh
修改配置文件
vim spark-env.sh
增加如下内容:
## 设置JAVA安装目录
JAVA_HOME=/opt/module/jdk1.8.0_212
## HADOOP软件配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需要,先提前配上
HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
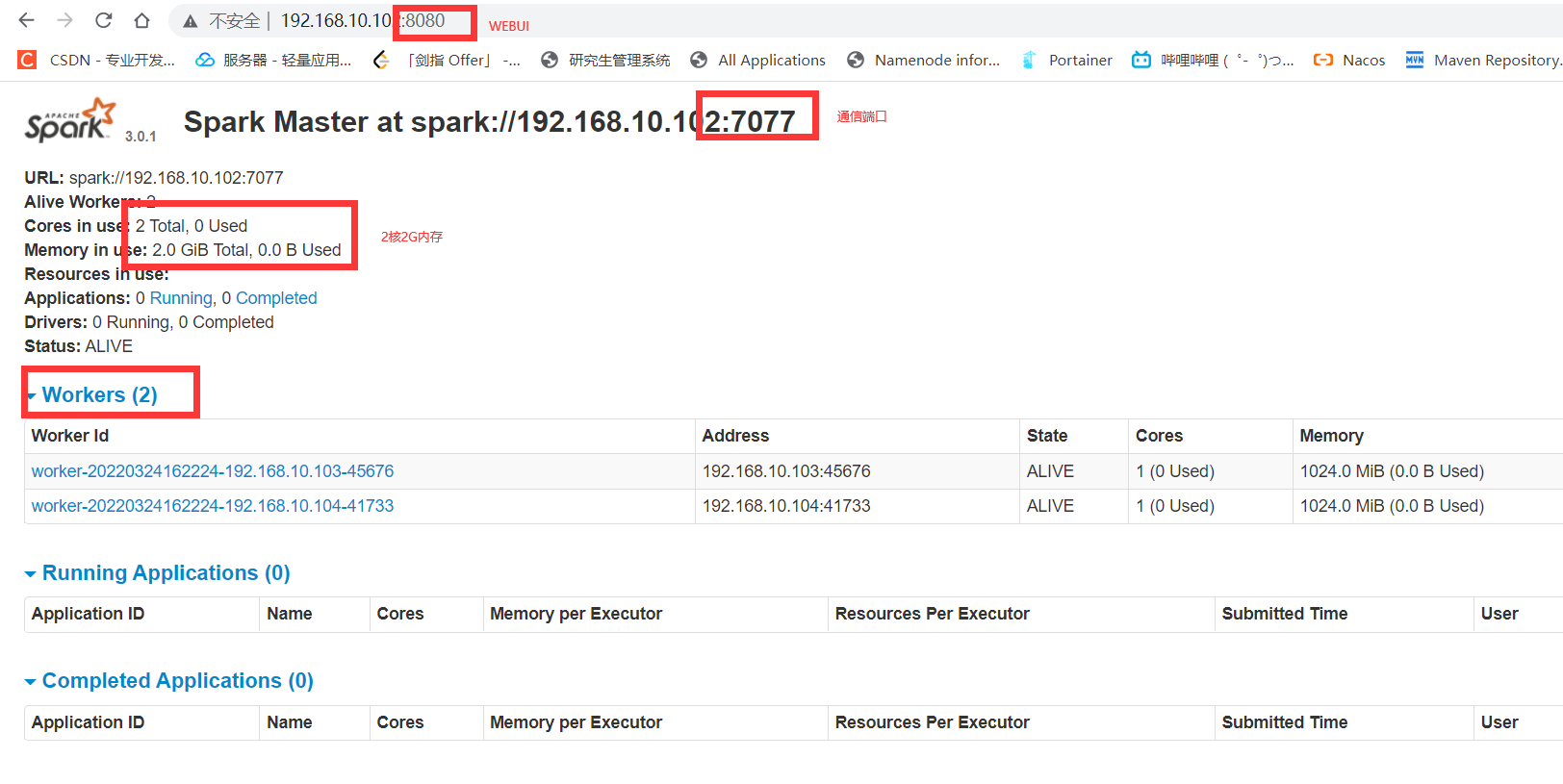
SPARK_MASTER_HOST=192.168.10.102
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
分发
scp -r /opt/module/spark-3.0.1 gzhu@192.168.10.103:/opt/module
scp -r /opt/module/spark-3.0.1 gzhu@192.168.10.104:/opt/module
启动集群
进入sbin目录
cd /opt/module/spark-3.0.1/sbin
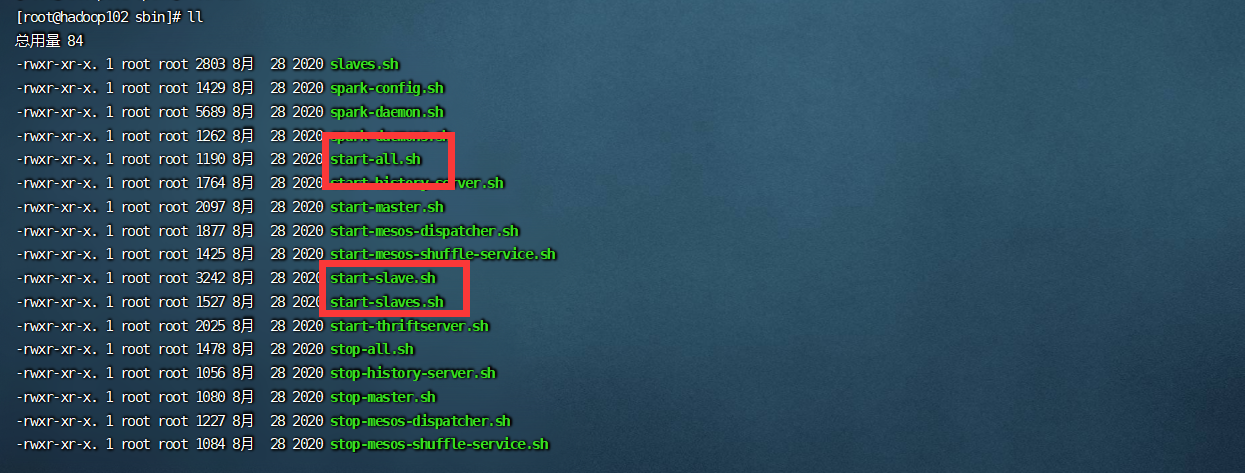
[gzhu@hadoop102 sbin]$ ./start-all.sh
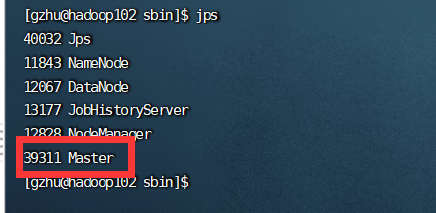

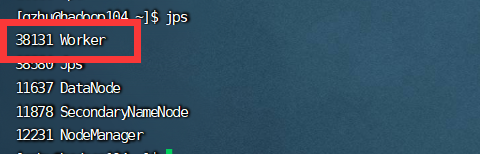
启动
cd /opt/module/spark-3.0.1/bin
./spark-shell --master spark://192.168.10.102:7077
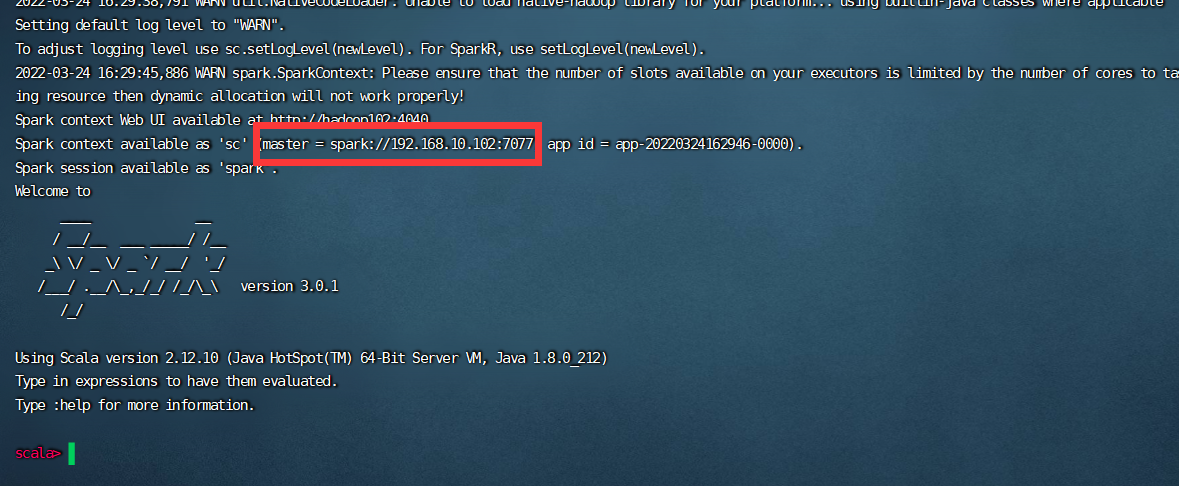
8080查看集群状态,7077通信端口,4040查看具体任务
将words上传到HDFS
hadoop fs -put /tmp/spark/words /input/spark
val textFile = sc.textFile("hdfs://192.168.10.102:8020/input/spark/words")
val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
counts.collect
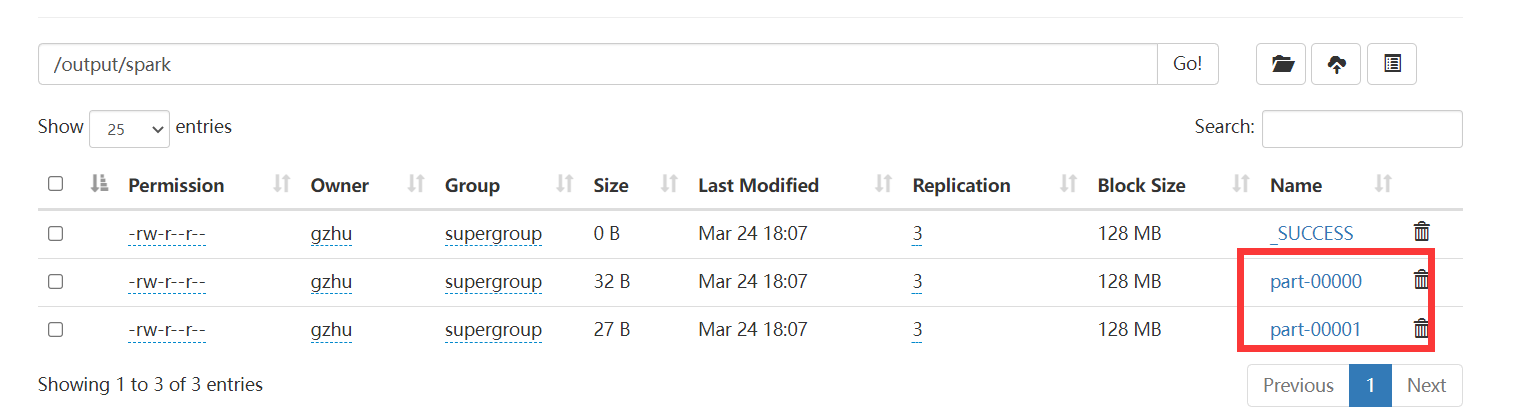
counts.saveAsTextFile("hdfs://192.168.10.102:8020/output/spark")
8020是HDFS的NN的通信端口
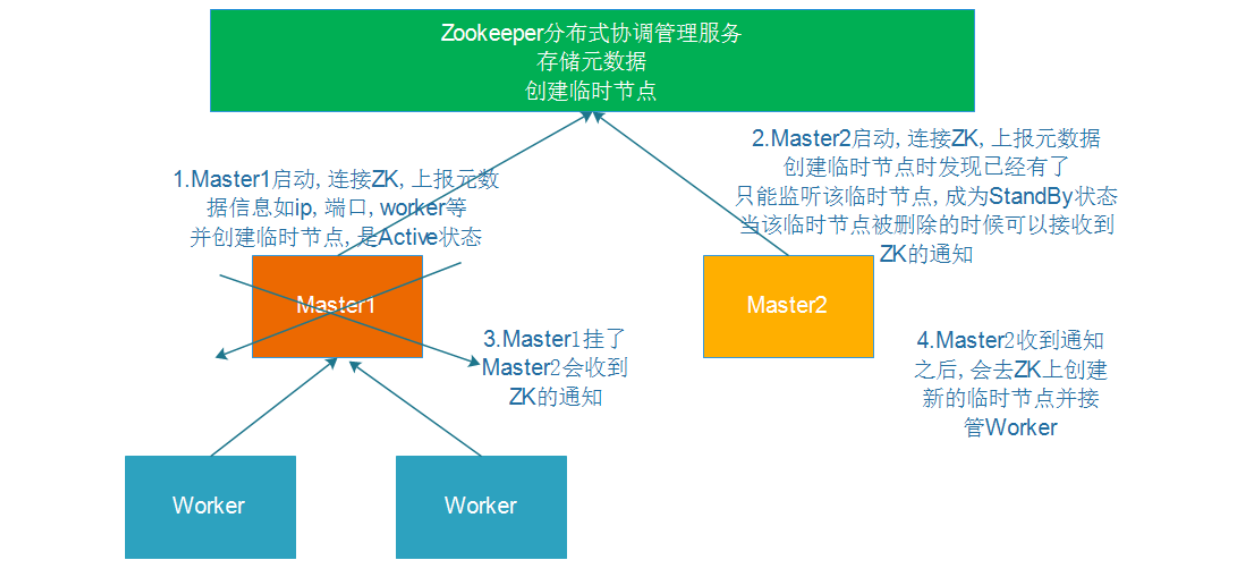
3.Standalone-HA
原理如图,不再具体操作
4.SparkOnYarn
(1)两种模式
client模式
Spark的Driver驱动,运行在提交任务的客户端上
优点:Driver的程序结果可以在客户端控制台查看
缺点:Driver和集群的通信成本高
cluster模式
Driver驱动运行在Yarn集群上
优点:Driver交给Yarn管理,减少管理成本,可在Yarn日志中查看Driver的程序结果。且通信成本低
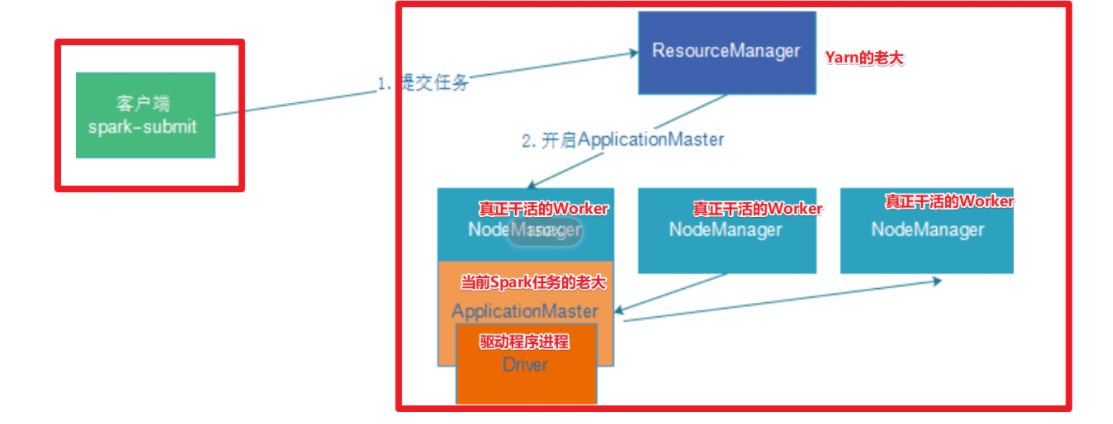
-
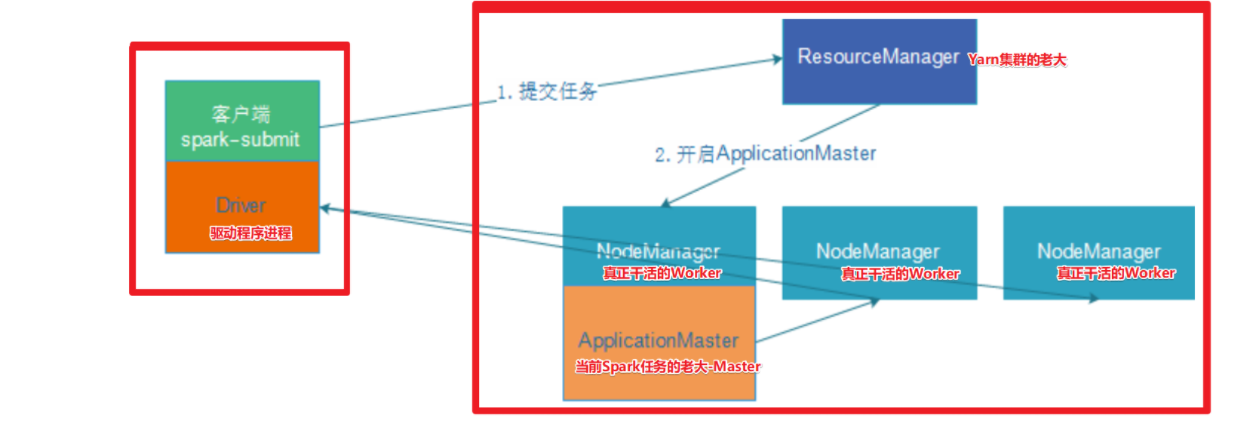
在 YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动
ApplicationMaster -
随后ResourceManager分配container,在合适的NodeManager上启动 ApplicationMaster,此时的ApplicationMaster就是Driver
-
Driver启动后向ResourceManager申请Executor内存,ResourceManager 接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程
-
Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行
main函数 -
之后执行到 Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将 task 分发到各个Executor上执行
(2)准备工作
1.关闭Yarn内存检查,Spark会占用较多内存,不关闭会有限制
cd /opt/module/hadoop-3.1.3/etc/hadoop
vim yarn-site.xml
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
scp -r yarn-site.xml gzhu@192.168.10.103:$PWD
scp -r yarn-site.xml gzhu@192.168.10.104:$PWD
2.配置Spark历史服务器整合Yarn
cd /opt/module/spark-3.0.1/conf
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://192.168.10.102:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address 192.168.10.102:18080
注意:sparklog需要手动创建
hadoop fs -mkdir -p /sparklog
scp -r spark-defaults.conf gzhu@192.168.10.103:$PWD
scp -r spark-defaults.conf gzhu@192.168.10.104:$PWD
修改配置文件
vim spark-env.sh
增加如下内容:
## 配置spark历史日志存储地址
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://192.168.10.102:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
scp -r spark-env.sh gzhu@192.168.10.103:$PWD
scp -r spark-env.sh gzhu@192.168.10.104:$PWD
(3)配置Spark相关的jar包
在HDFS上创建存储spark相关jar包的目录
hadoop fs -mkdir -p /spark/jars/
上传$SPARK_HOME/jars所有jar包到HDFS
hadoop fs -put /opt/module/spark-3.0.1/jars/* /spark/jars/
在hadoop1上修改spark-defaults.conf
vim /opt/module/spark-3.0.1/conf/spark-defaults.conf
添加内容
spark.yarn.jars hdfs://192.168.10.102:8020/spark/jars/*
分发
scp -r spark-defaults.conf gzhu@192.168.10.103:$PWD
scp -r spark-defaults.conf gzhu@192.168.10.104:$PWD
(4)启动
启动Hadoop集群,Master,两个Worker
启动Spark的历史服务器
cd /opt/module/spark-3.0.1/sbin
./start-history-server.sh
(5)两种模式演示 — 以SparkPi为例
client模式
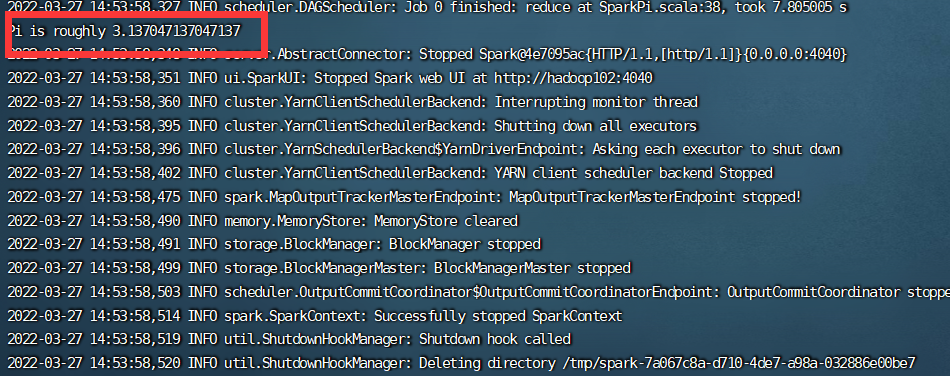
启动Hadoop和Yarn后,运行,可以在控制台看到结果
SPARK_HOME=/opt/module/spark-3.0.1
${SPARK_HOME}/bin/spark-submit
--master yarn
--deploy-mode client
--driver-memory 512m
--driver-cores 1
--executor-memory 512m
--num-executors 2
--executor-cores 1
--class org.apache.spark.examples.SparkPi
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar
10
cluster模式
SPARK_HOME=/opt/module/spark-3.0.1
${SPARK_HOME}/bin/spark-submit
--master yarn
--deploy-mode cluster
--driver-memory 512m
--executor-memory 512m
--num-executors 1
--class org.apache.spark.examples.SparkPi
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar
10
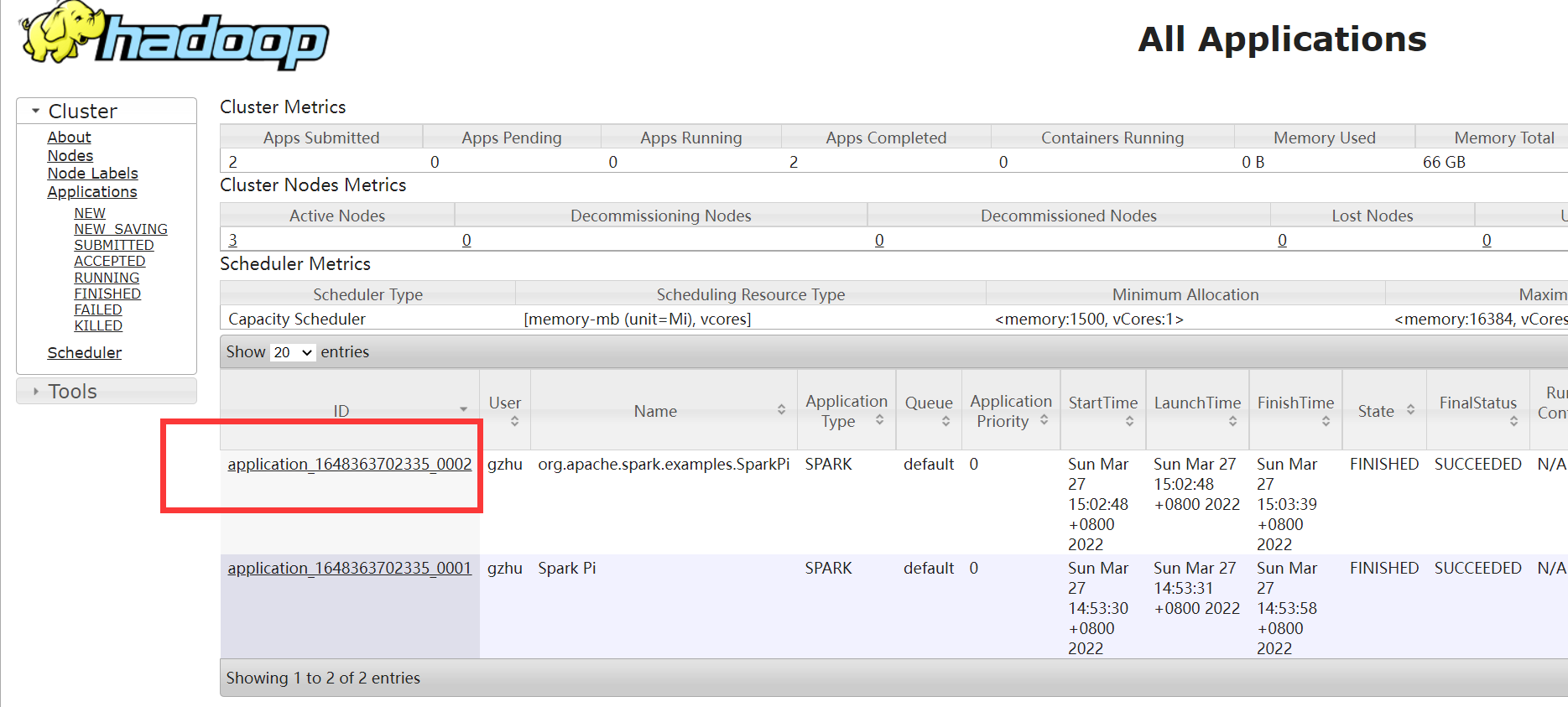
Yarn页面可以看到运行成功
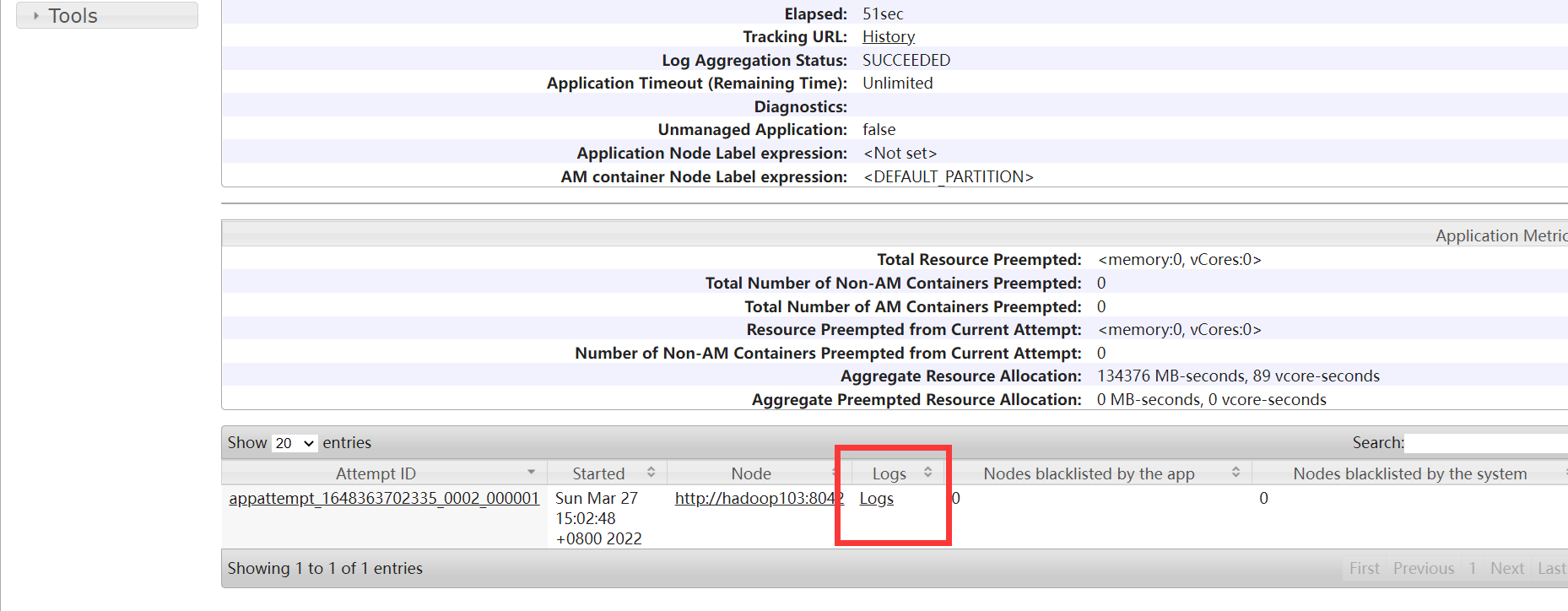
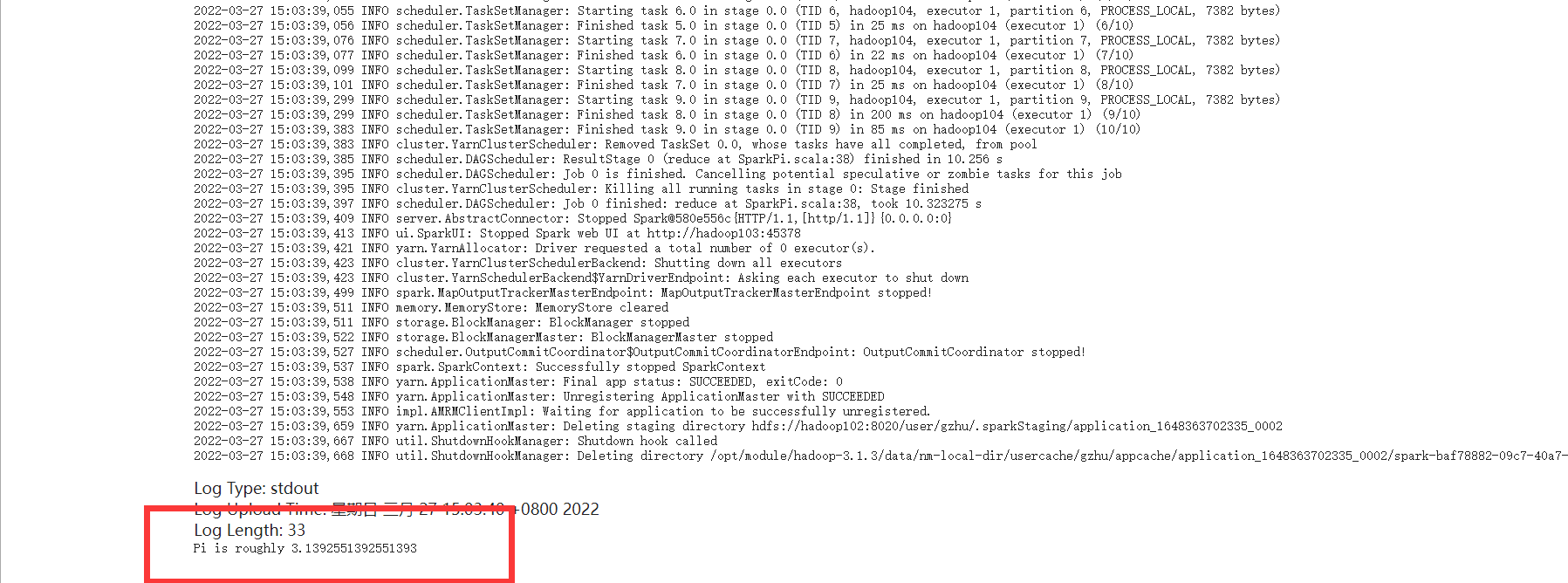
spark-shell和spark-submit
spark-shell:spark应用交互式窗口,启动后可以直接编写spark代码,即时运行,一般在学习测试时使用
spark-submit:用来将spark任务/程序的jar包提交到spark集群(一般都是提交到Yarn集群)
三.Spark入门案例 — WordCount
1.本地测试
导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.gzhu</groupId>
<artifactId>Spark-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<encoding>UTF-8</encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.11</scala.version>
<spark.version>3.0.1</spark.version>
<hadoop.version>2.7.5</hadoop.version>
</properties>
<dependencies>
<!--依赖Scala语言-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--SparkCore依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-streaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--SparkSQL依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- SparkMlLib机器学习模块,里面有ALS推荐算法-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<!-- 指定编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
scala代码
object WordCount {
def main(args: Array[String]): Unit = {
// 1.准备SparkContext上下文执行环境
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
// 2.读取数据,RDD存储每一行
val lines: RDD[String] = sc.textFile("F:\input\wordcount")
// 3.数据操作,每一行处理,形成一个个单词
val words: RDD[String] = lines.flatMap(_.split(" "))
// 每个单词赋值1
val wordAndOne: RDD[(String, Int)] = words.map((_,1))
// 分组聚合
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
// 4.收集结果,直接到控制台
result.foreach(println)
// 保存到本地文件
result.repartition(1).saveAsTextFile("F:\output\wordcount")
// 5.关闭上下文
sc.stop()
}
}
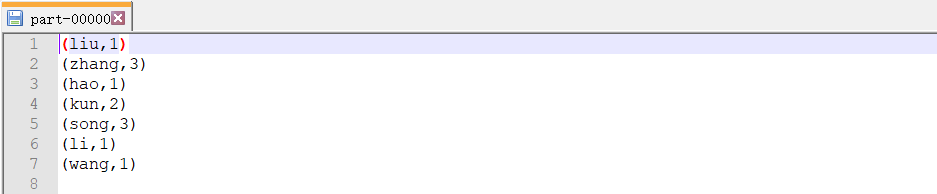
结果

2.Yarn测试
object WordCountYarn {
def main(args: Array[String]): Unit = {
if(args.length < 2){
println("请输入input路径和output路径")
System.exit(1)
}
// 1.准备SparkContext上下文执行环境
val conf = new SparkConf().setAppName("wc")
val sc = new SparkContext(conf)
// 2.读取数据,RDD存储每一行
val lines: RDD[String] = sc.textFile(args(0))
// 3.数据操作,每一行处理,形成一个个单词
val words: RDD[String] = lines.flatMap(_.split(" "))
// 每个单词赋值1
val wordAndOne: RDD[(String, Int)] = words.map((_,1))
// 分组聚合
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
// 4.保存到指定文件
result.repartition(1).saveAsTextFile(args(1))
// 5.关闭上下文
sc.stop()
}
}
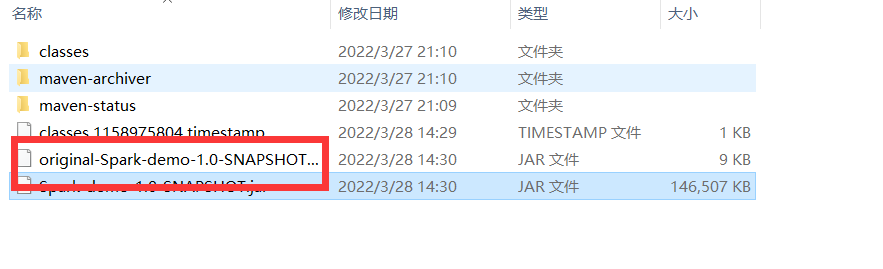
打包
我们只需要不包含依赖的jar包
上传到服务器
提交任务
SPARK_HOME=/opt/module/spark-3.0.1
${SPARK_HOME}/bin/spark-submit
--master yarn
--deploy-mode cluster
--driver-memory 512m
--executor-memory 512m
--num-executors 1
--class com.gzhu.wordcount.WordCountYarn
/tmp/spark/wc.jar
hdfs://192.168.10.102:8020/input/spark/words
hdfs://192.168.10.102:8020/output/wordcount
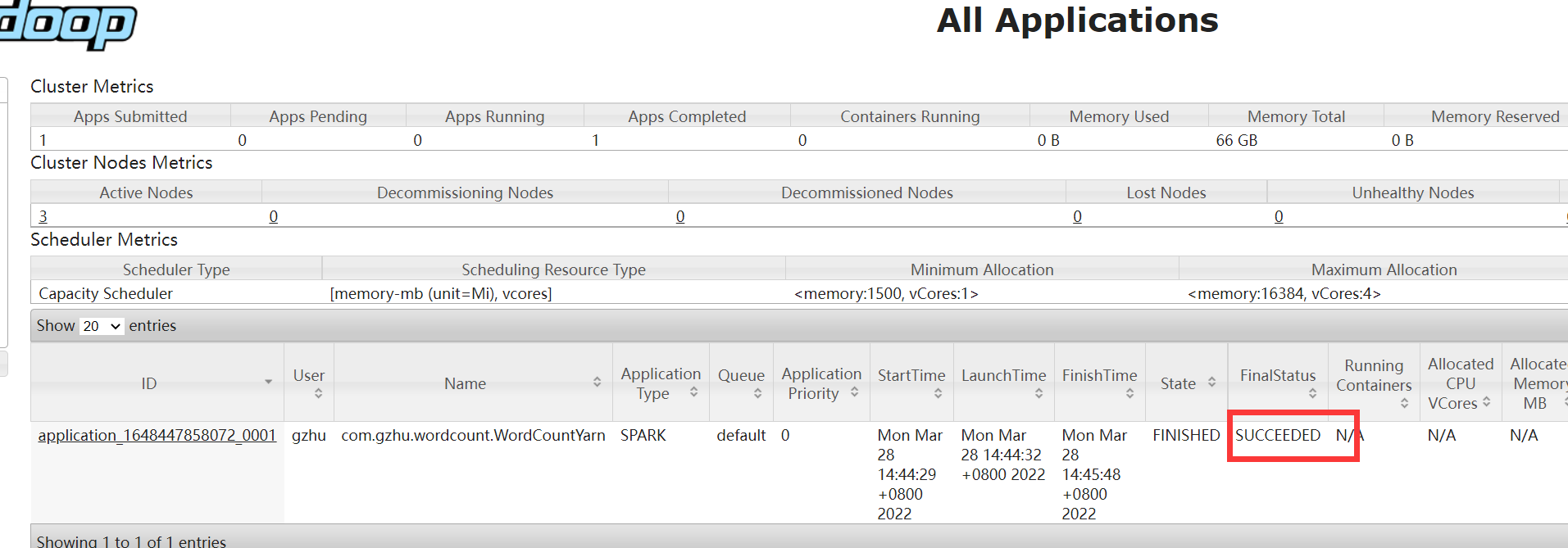
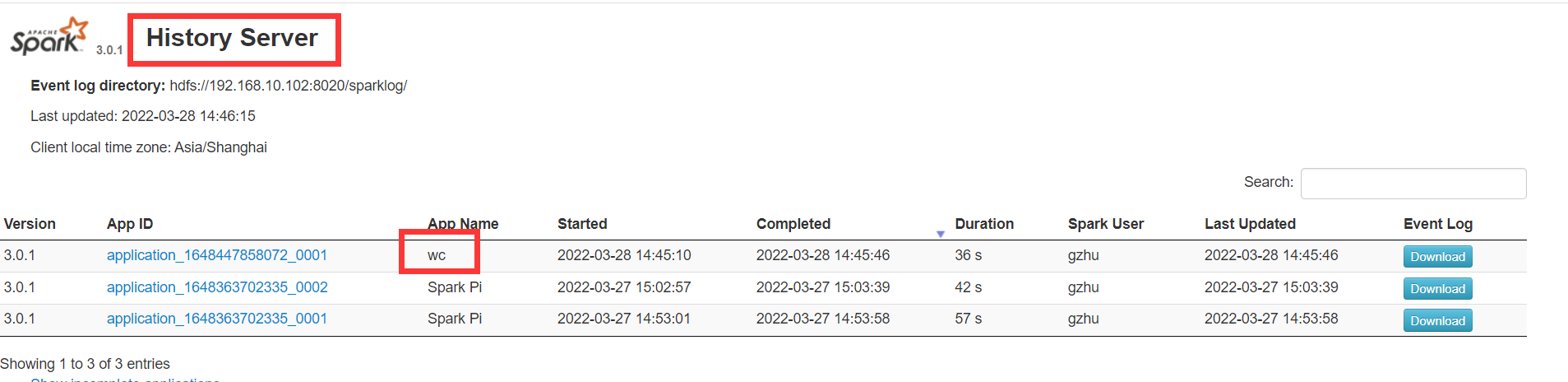
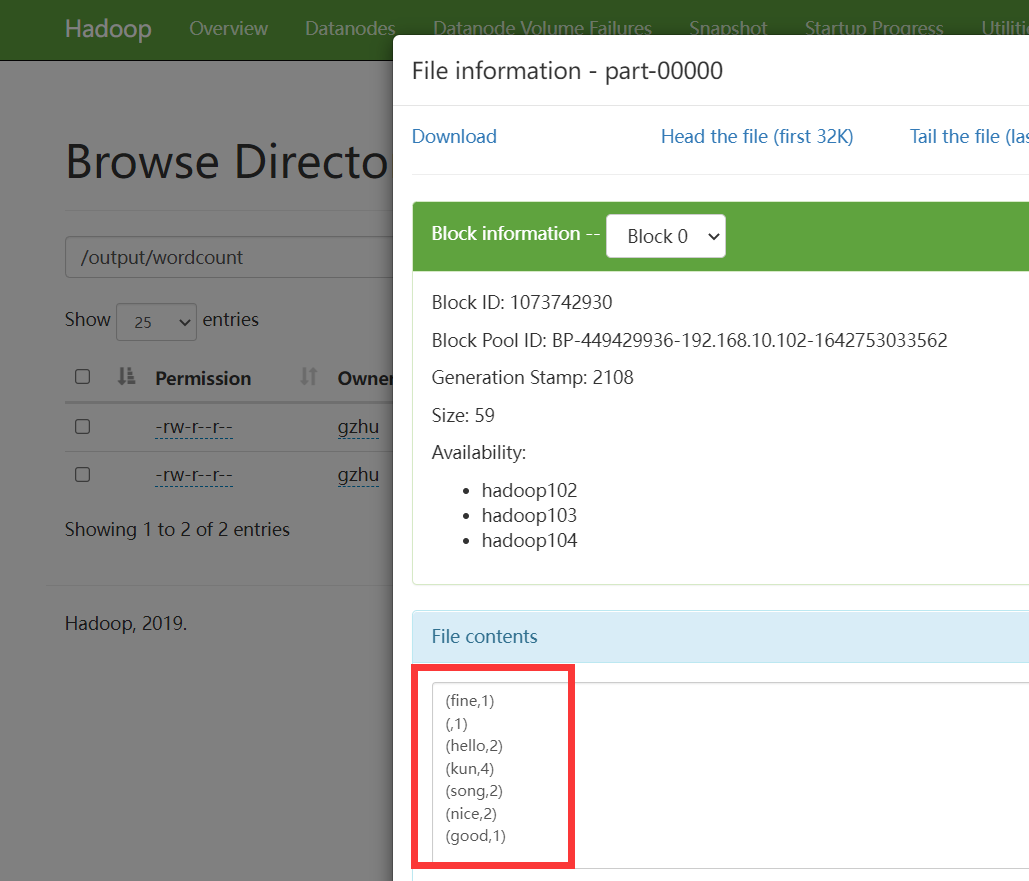
HDFS查看结果
最后
以上就是标致学姐最近收集整理的关于Spark(一)概述的全部内容,更多相关Spark(一)概述内容请搜索靠谱客的其他文章。








发表评论 取消回复