我是靠谱客的博主 欣慰万宝路,这篇文章主要介绍Spark 概述 | Spark 与 Hadoop的区别一、Spark是什么二、Spark的核心模块二、Spark VS Hadoop,现在分享给大家,希望可以做个参考。
文章目录
- 一、Spark是什么
- 二、Spark的核心模块
- 二、Spark VS Hadoop
一、Spark是什么

Spark是一个基于内存的快速、通用、可扩展的大数据分析计算引擎
二、Spark的核心模块
如下图所示,Spark共有以下几个模块:

Spark Core:提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX,MLlib都是在Spark Core的基础上进行扩展的Spark SQL:是用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据Spark Streaming:是针对实时数据进行流失计算的组件,提供了丰富的处理数据流的APISpark MLlib:一个机器学习算法库,它不仅提供了模型评估、数据导入等额外功能,还提供了一些更底层的机器学习原语Spark GraphX:面向图计算提供的框架与算法库
Spark比Hadoop出现的时间较晚,它的主要功能是数据计算,所以Spark一直被认为是Hadoop框架的升级版
二、Spark VS Hadoop
Spark是基于内存计算的,Hadoop的计算框架MapReduce是基于磁盘计算的
MapReduce每次计算都会把中间结果放入磁盘当中,进行迭代计算的时候,会再次把中间结果读到内存当中再进行计算,这就导致了MapReduce计算的速度很慢,因为每次都要读磁盘,如下图所示:
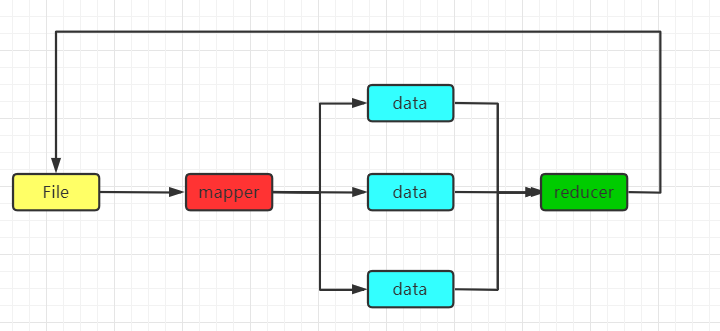
而Spark则是根据内存进行计算的,他把中间结果存到了内存中,这使得速度加快了不少:
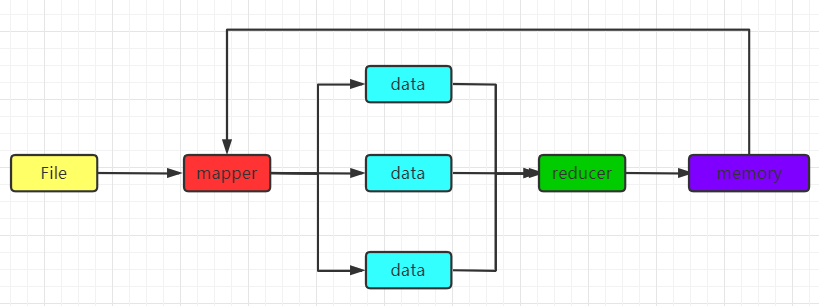
众所周知,内存的速度要比磁盘快很多,官网也给出了,两个计算引擎的速度对比:
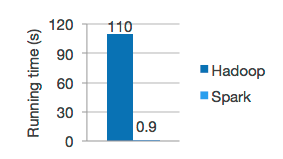
由于现在内存价格昂贵,Spark还并不能完全替代MapReduce
最后
以上就是欣慰万宝路最近收集整理的关于Spark 概述 | Spark 与 Hadoop的区别一、Spark是什么二、Spark的核心模块二、Spark VS Hadoop的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复