首先来聊聊什么是Spark?为什么现在那么多人都用Spark?
Spark简介:
Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以分布式处理大量集数据的,将大量集数据先拆分,分别进行计算,然后再将计算后的结果进行合并。
为什么使用Spark
Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,而且比MapReduce平均快10倍以上的计算速度;因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
Spark优势
- 速度快
■基于内存数据处理, 比MR快100个数量级以上(逻辑回归算法测试)
■基于硬盘数据处理,比MR快10个数量级以上 - 易用性
■支持Java、 Scala、 Python、 R语言
■交互式shell方便开发测试 - 通用性
■一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习
■多种运行模式
■YARN、 Mesos、 EC2、 Kubernetes、 Standalone(独立模式)、 Local(本地模式)
Spark技术
- Spark Core
■核心组件,分布式计算引擎 - SparkSQL
■高性能的基于Hadoop的SQL解决方案 - Spark Streaming
■可以实现高吞吐量、具备容错机制的准实时流处理系统 - Spark GraphX
■分布式图处理框架 - Spark MLlib
■构建在Spark_上的分布式机器学习库
架构核心组件
1.Application
说明:
建立在Spark.上的用户程序,包括Driver代码和运行在集群各节点Executor中的代码
2.Driver program
说明:
驱动程序,Application中的main函数并创建SparkContext
3.Cluster Manager
说明:
在集群(Standalone、 Mesos、YARN) . 上获取资源的外部服务
4.Worker Node
说明:
集群中任何可以运行Application代码的节点
5.Executor
说明:
某个Application运行在worker节点上的一个进程 就像jdk的运行环境
6.Task
说明:
被送到某个Executor上的工作单元
7.Job
说明:
包含多个Task组成的并行计算,往往由Spark Action触发生成,一个Application中往往会产生多个Job
8.Stage
说明:
每个Job会被拆分成多组Task,作为一个TaskSet, 其名称为Stage 有一个或多个task任务
安装与配置
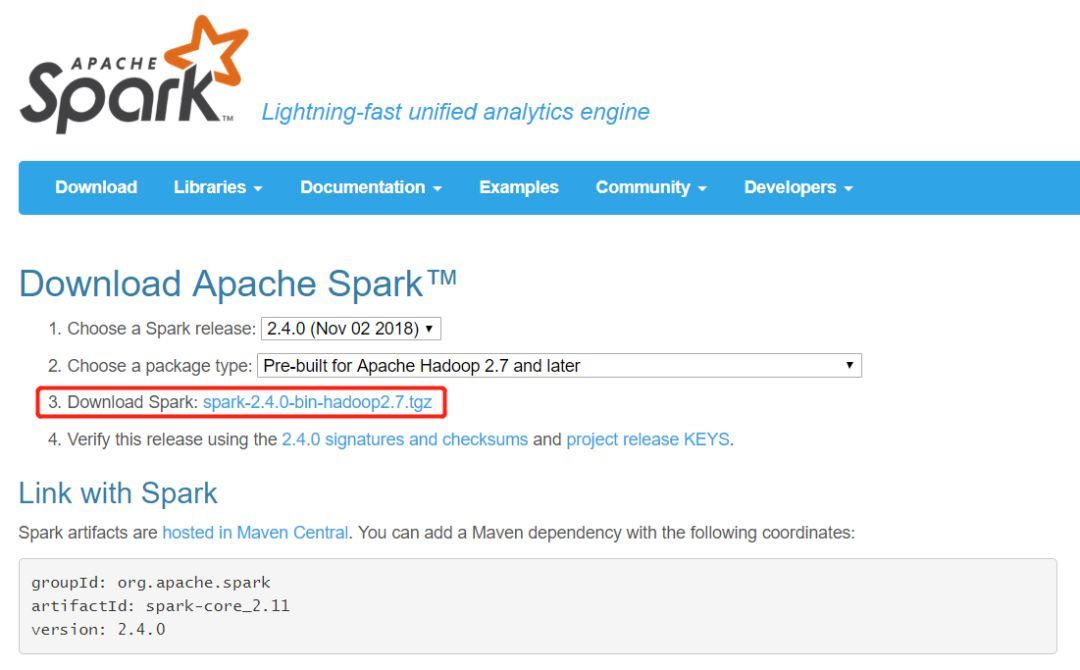
我们要安装Spark,首先需要到Saprk官网去下载对应的安装包,Spark官网:http://spark.apache.org/downloads.html
第一步点击我下图中标记的红框框住的蓝色链接部分即可
下载好安装包后,直接拖到linux系统下的opt目录下进行解压
tar -zxf spark-2.4.0-bin-hadoop2.7.tgz
解压后在opt目录下创建子目录soft并把解压后的文件夹重新命名放入其中
mv spark-2.4.0-bin-hadoop2.7 soft/spark240
在conf里配置slaves 和 spark-env.sh
首先把文件名spark-env.sh.template 改成spark-env.sh并修改内容
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加以下内容在文件最后:
<!--主节点IP-->
export SPARK_MASTER_HOST=192.168.5.150
<!--任务提交端口-->
export SPARK_MASTER_PORT=7077
<!--每个worker使用2核,视自己的虚拟机创建的时候内核而定-->
export SPARK_WORKER_CORES=2
<!--每个worker使用3g内存,视自己的虚拟机创建的时候内存而定-->
export SPARK_WORKER_MEMORY=3g
<!--修改spark监视窗口的端口默认8080-->
export SPARK_MASTER_WEBUI_PORT=8888
把文件名slaves.template改成slaves
cp slaves.template slaves
vi slaves
默认slaves现在就主机一台
由于配的是单机,不是集群,所以不用Slaves(配置worker从机节点),就是localhost,不用改设置
到spark-config.sh配置jdk环境变量
cd /opt/soft/spark240/sbin
vi spark-config.sh
添加jdk路径在文件最后:
export JAVA_HOME=/opt/soft/jdk180
启动spark
到主节点spark的sbin下运行
cd /opt/soft/spark240/sbin
启动命令
./start-all.sh
jps 查看到多出一个Master,worker进程
jps
2281 DataNode
2451 SecondaryNameNode
1848 Master
2617 ResourceManager
2149 NameNode
1934 Worker
2532 NodeManager
2904 Jps说明已经启动成功!
在bin目录下进入shell操作界面
cd …/bin/
./spark-shell
当出现有spark的英文图像时,表示已经进入操作界面可以进行操作了!如下图所示:
后续还会有更多关于spark的干货,记得关注小编!
最后
以上就是激情万宝路最近收集整理的关于Spark简介以及最详细安装教程的全部内容,更多相关Spark简介以及最详细安装教程内容请搜索靠谱客的其他文章。








发表评论 取消回复