目前主流的三大分布式计算系统分别为Hadoop、Spark和Strom,它们三者之间有什么区别呢?今天加米谷大数据就来简单介绍一下。

Storm与Spark Streaming的区别
(1)Apache Storm:是一个分布式的,可靠的,容错的数据流处理系统。
Storm可用于:“流处理”之中,实时处理消息并更新数据库;用户行为日志有准事实的查询需求,对数据流做连续查询;还可被用于“分布式RPC”等。
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
大数据开发零基础需要学习什么内容?(4)Storm实时开发
(2)Spark Streaming:是Spark上的一个流式处理框架,可以面向海量数据实现高吞吐量、高容错的实时计算。
Spark Streaming支持多种类型数据源,包括Kafka、Flume、trwitter、zeroMQ、Kinesis以及TCP sockets等。
大数据开发零基础需要学习什么内容?(3)Spark生态体系
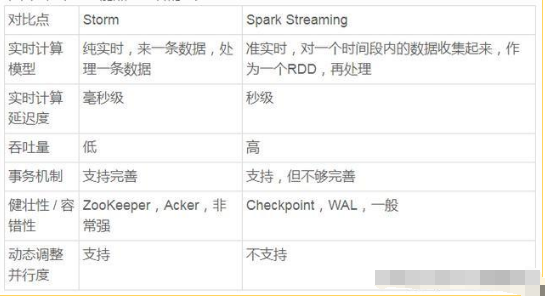
(3)二者对比:
某些功能点上两者的差别:
最重要的区别:
Spark Streaming是微批处理;storm是按条处理,逐个处理流式数据事件,比Spark Streaming更实时。
Storm是纯实时,在实时性和容错方面优于Spark Streaming(准实时) ;
Storm的事务机制、健壮性 / 容错性、动态调整并行度等特性,优于Spark Streaming;
Spark Streaming 集成性与吞吐量方面优于Storm,更适用于大数据背景(Spark Streaming通过RDD不仅能够与Spark上的所有组件无缝衔接共享数据,可以在程序中无缝进行延迟批处理、交互式查询等操作,还能非常容易地与Kafka、Flume等分布式日志收集框架进行集成);
应用场景上:
1)对于Storm来说:
用于需要纯实时数据处理的场景,比如实时金融系统,要求纯实时进行金融交易和分析;
在实时计算中,要求强大可靠的事务机制,即数据的处理完全精准,一条也不能多,一条也不能少,可以使用Storm;
针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),可以考虑用Storm;
如果一个大数据应用系统,不需要在中间执行SQL交互式查询、复杂的transformation算子等,就是纯粹的实时计算,Storm是比较好的选择;
2)对于Spark Streaming来说:
不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming;
如果一个项目除了实时计算,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,应首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
Storm和Hadoop的区别
(4)Hadoop:是一个分布式系统基础架构,专为离线和大规模数据分析而设计。
Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力。
Hadoop的适用场景:海量数据的离线分析处理,大规模Web信息搜索,数据密集型并行计算。
0基础入门大数据开发需要学习什么内容?(2)Hadoop体系
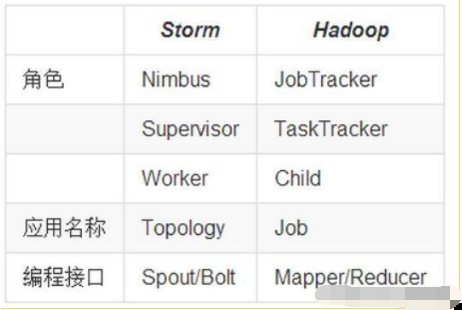
(5)Storm和Hadoop的区别:
Hadoop用于离线计算,Storm用于实时计算;
Hadoop上运行的是MapReduce jobs,而在Storm上运行的是topology;
Hadoop的数据保存在磁盘中,使用磁盘作为中间交换的介质,而storm的数据是通过网络传输进来,一直在内存中流转;
Hadoop处理的数据保存在文件系统中,一批一批;Storm处理的数据保存在内存中,源源不断;
Hadoop擅长批处理、吞吐量大、做全量数据的离线分析,Storm的优势是数据的实时分析,以实时性高被广泛应用,单位时间内的吞吐量要小于Hadoop;
处理过程:Hadoop是分Map阶段到Reduce阶段,Storm是由用户定义处理流程,流程中可以包含多个步骤,每个步骤可以是数据源(Spout)或处理逻辑(Bolt);
Storm与Hadoop的编程模型相似:
更多干货加小编微信:

(6)Hadoop、Spark和Strom:
Hadoop当前大数据管理标准之一,运用在当前很多商业应用系统。可以轻松地集成结构化、半结构化甚至非结构化数据集。
Spark采用了内存计算。从多迭代批处理出发,允许将数据载入内存作反复查询,此外还融合数据仓库,流处理和图形计算等多种计算范式。Spark构建在HDFS上,能与Hadoop很好的结合。它的RDD是一个很大的特点。
Storm用于处理高速、大型数据流的分布式实时计算系统。为Hadoop添加了可靠的实时数据处理功能。
最后
以上就是义气纸鹤最近收集整理的关于大数据计算:Storm和Spark Streaming、Hadoop有什么区别?Storm与Spark Streaming的区别Storm和Hadoop的区别的全部内容,更多相关大数据计算:Storm和Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复