我们做数据分析的时候常常会遇到这样两个场景,一个是统计历史数据,这个就是要分析历史保存的日志。我们会使用hadoop,具体框架可以设计为:
1.flume收集日志;
2.HDFS输入路径存储日志;
3.MapReduce计算,将结果输出到HDFS输出路径;
4.hive+sqoop实现将结果转储到mysql
5.我们会使用crontab定时执行一个脚本来做
具体这里就不展开来说了,我会在另一个帖子讲到。这里我们详细介绍第二个场景:实时计算。这个用的比较多的如天猫双十一实时展示交易额,还有比如说银行等。
实现实时计算要用到storm或者spark等,这里我介绍flume+kafka+storm方案。
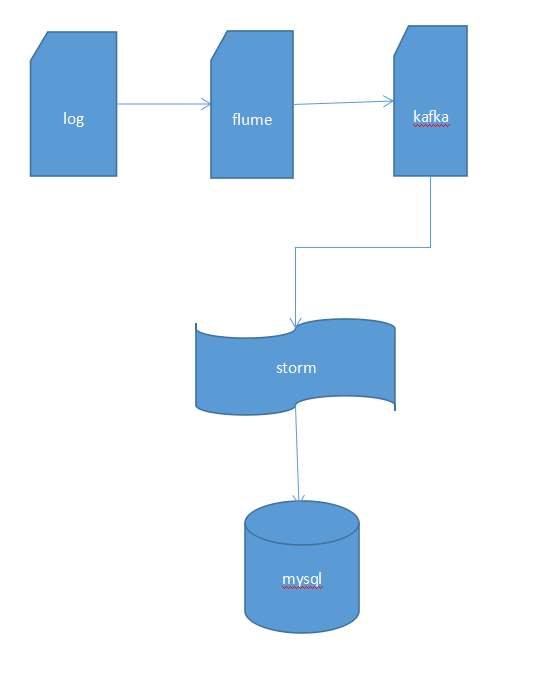
使用flume采集日志数据,flume是一个分布式、可靠和高可用的海量日志采集、聚合和传输的系统。它的核心是一个agent,其中包含3个组件,source、channel和sink。Agent会监控日志目录,通过source组件将日志搜集到channel中缓存起来,当sink处理完之后会将缓存的记录删除,已经扫描过的文件会添加.COMPLETED后缀,下次不会重新扫描该文件。
因为日志搜集的速度和日志处理的速度是不一样的,所以加了一个kafka组件,其实也是作为一个缓冲的作用。Sink将日志中一行数据作为消息发布到kafka中,storm通过kafkaSpout来消费kafka消息,storm消费完一条消息需要对kafkaSpout回应(比如我们自定义bolt时如果是继承BaseRichBolt,需要显示调用collector.ack(tuple)和collector.fail(tuple)),这样才不会重复消费消息。
Storm从kafka中拿到一条数据,通过解析字符串,对日志做一定的日志清洗工作,然后计算之后可以将数据存到mysql,然后就可以在前端展示了。
我们需要自定义DailyStatisticsAnalysisTopology来处理任务代码如下:
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.2.0</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- kafka整合storm -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.3</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>0.9.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.30</version>
</dependency>
</dependencies>
<build>
<finalName>Storm_DailyStatisticsAnalysis</finalName>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.wyd.kafkastorm.DailyStatisticsAnalysisTopology</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
-----------------------------------------------------------------------------------------------
public class DailyStatisticsAnalysisTopology {
private static String topicName = "dailyStatisticsAnalysis";
private static String zkRoot = "/stormKafka/"+topicName;
public static void main(String[] args) {
BrokerHosts hosts = new ZkHosts("192.168.*.*:2181");
SpoutConfig spoutConfig = new SpoutConfig(hosts,topicName,zkRoot,UUID.randomUUID().toString());
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafkaSpout",kafkaSpout);
builder.setBolt("dailyStatisticsAnalysisBolt", new
DailyStatisticsAnalysisBolt
(), 2).shuffleGrouping("kafkaSpout");
Config conf = new Config();
conf.setDebug(true);
if(args != null && args.length > 0) {
conf.setNumWorkers(1);
try {
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}catch (Exception e) {
e.printStackTrace();
}
} else {
conf.setMaxSpoutPending(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("dailyAnalysis", conf, builder.createTopology());
}
}
}
-----------------------------------------------------------------------------
public class
DailyStatisticsAnalysisBolt
extends BaseRichBolt {
/**
*
*/
private static final long serialVersionUID = 2262767962772699286L;
private OutputCollector _collector;
LogInfoHandler loginfohandler = new LogInfoHandler();
@Override
public void execute(Tuple tuple) {
// 存入mysql
try{
String value = tuple.getString(0);
loginfohandler.splitHandl(value);
DbUtil.insert(loginfohandler.getTarget(), loginfohandler.getTime(),
loginfohandler.getDistrictServer(), loginfohandler.getChannel(), loginfohandler.getCounts());
_collector.ack(tuple);
}catch(Exception e){
_collector.fail(tuple);
e.printStackTrace();
}
}
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this._collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
-----------------------------------------------------------------------------
进入maven项目的根目录执行mvn
assembly:assembly
打包成功后会生成两个jar包:

将他们上传到storm目录下,执行
nohup bin/storm jar Storm_DailyStatisticsAnalysis.jar com.wyd.kafkastorm.DailyStatisticsAnalysisTopology &
最后
以上就是欣喜草丛最近收集整理的关于flume+kafka+storm整合实现实时计算小案例的全部内容,更多相关flume+kafka+storm整合实现实时计算小案例内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复