LSTM(long short-term memory,LSTM):长短时记忆网络,是循环神经网络(recurrent neural network,RNN)的一个重要结构,循环神经的主要用途是处理和预测序列数据。全连接神经网络(感知机,BP神经网络,RBF 神经网络等)或卷积神经网络模型中,网络结构都是从输入层到隐含层再到输出层,层与层之间是全连接或部分连接,每层节点之间是无连接的。然而循环神经网络为了刻画一个序列的当前的输出信息和之前信息的关系。从结构上说,循环神经网络会记忆之前的信息,并利用之前记忆的信息影响后面节点的输出。循环神经网络的隐藏层之间的节点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。
网络的具体结构以及意义,参考下文
https://www.jianshu.com/p/9dc9f41f0b29
下面是我的数据预测:
# -*- coding: utf-8 -*-
"""
LSTM prediction
@author: ljq
"""
#导入库函数
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
#读取数据
data= read_csv('data_s.csv') #csv文件 n*1 ,n代表样本数,反应时间序列,1维数据
values1 = data.values;
dataset=values1[:,0].reshape(-1,1)#注意将一维数组,转化为2维数组
dataset = dataset.astype('float32')#将数据转化为32位浮点型,防止0数据
# convert an array of values into a dataset matrix
def create_dataset(dataset, look_back=1):#后一个数据和前look_back个数据有关系
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
dataX.append(a) #.apeend方法追加元素
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY) #生成输入数据和输出数据
numpy.random.seed(7)#随机数生成时算法所用开始的整数值
# normalize the dataset
scaler = MinMaxScaler(feature_range=(0, 1))#归一化0-1
dataset = scaler.fit_transform(dataset)
# split into train and test sets #训练集和测试集分割
train_size = int(len(dataset) * 0.67)#%67的训练集,剩下测试集
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]#训练集和测试集
# use this function to prepare the train and test datasets for modeling
look_back = 1
trainX , trainY = create_dataset(train, look_back)#训练输入输出
testX,testY=create_dataset(test, look_back)#测试输入输出
#reshape input to be [samples, time steps, features]#注意转化数据维数
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
#建立LSTM模型
model = Sequential()
model.add(LSTM(11, input_shape=(1, look_back)))#隐层11个神经元 (可以断调整此参数提高预测精度)
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')#评价函数mse,优化器adam
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)#100次迭代
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
#数据反归一化
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# plot baseline and predictions
plt.figure(figsize=(20,6))
l1,=plt.plot(scaler.inverse_transform(dataset),color='red',linewidth=5,linestyle='--')
l2,=plt.plot(trainPredictPlot,color='k',linewidth=4.5)
l3,=plt.plot(testPredictPlot,color='g',linewidth=4.5)
plt.ylabel('Height m')
plt.legend([l1,l2,l3],('raw-data','true-values','pre-values'),loc='best')
plt.title('LSTM Gait Prediction')
plt.show()
以下是实验结果: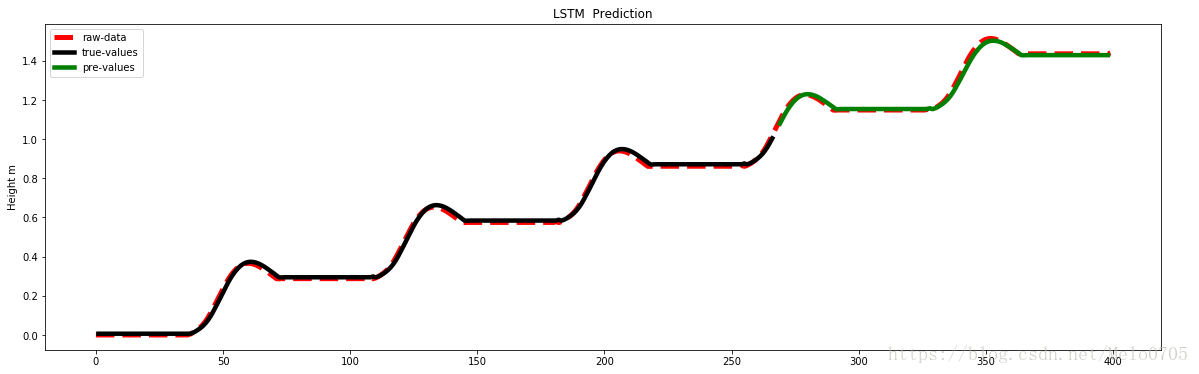
下面介绍程序中的一些用法及注释:
Pandas数据导入:可参考官方文档 :
https://pandas.pydata.org/pandas-docs/stable/api.html#input-output
#举一个简单的例子 用一下pandas读数据
import pandas as pd
#Read data
data = pd.read_excel(r'C:Users1042zylDesktoppptdata.xlsx',sheet_name=3,index_col = None)
#Normalization 规范化量程在0-1
data = (data - data.min()) / (data.max() - data.min())
#Export excel
data.to_excel('1.xlsx')
batch_size 大小选择:太小,算法难以收敛;适当增大,收敛快,精度上升;过大,时间最优但是陷入局部最优。且越大对内存要求也在增加。
numpy中的: 对象.shape():读取对象的维度。对象.shape(0)读取行数; 对象.shape(1)读取列数,。注意list(列表)是没有shape属性的,需要把它转化为 np.shape(x)或者np.arrray(x).shape. 扩展:numpy 中转置:np.transpose(x)或者np.arrray(x).T
注意这里的np.array(x)只是将数据化成numpy要求,维度并没有变化。
numpy 中的reshape用法参考官网
https://docs.scipy.org/doc/numpy/reference/generated/numpy.reshape.html
对其中的一句做解释,One shape dimension can be -1. In this case, the value is inferred from the length of the array and remaining dimensions.-1代表不确定数,当行数不确定[-1,1];当列数不确定[1,-1]

注意设置.reshape(数据,newspace=(行数,k个1,列数)) 可以实现增加维数。
最后
以上就是曾经冬日最近收集整理的关于深度学习之LSTM时间序列预测的全部内容,更多相关深度学习之LSTM时间序列预测内容请搜索靠谱客的其他文章。








发表评论 取消回复