
本文是【Predict Future Sales】用深度学习玩转销量预测的续集,主要介绍另一个强大的机器学习算法–随机森林(Random Forest,下文简称RF)在销量预测实例中的应用。github: https://github.com/alexshuang/predict_future_sales/blob/master/predict_future_sale_rf.ipynb
Look at Data Quickly
通常情况下,拿到这类tabular数据集之后,我会先大致浏览数据中各个字段的含义,并构建一个基础模型来试探这个数据集,根据反馈结果再重新深入理解各个字段的具体含义,深挖它们的特征和关联,也就是EDA(Exploratory Data Analysis)。
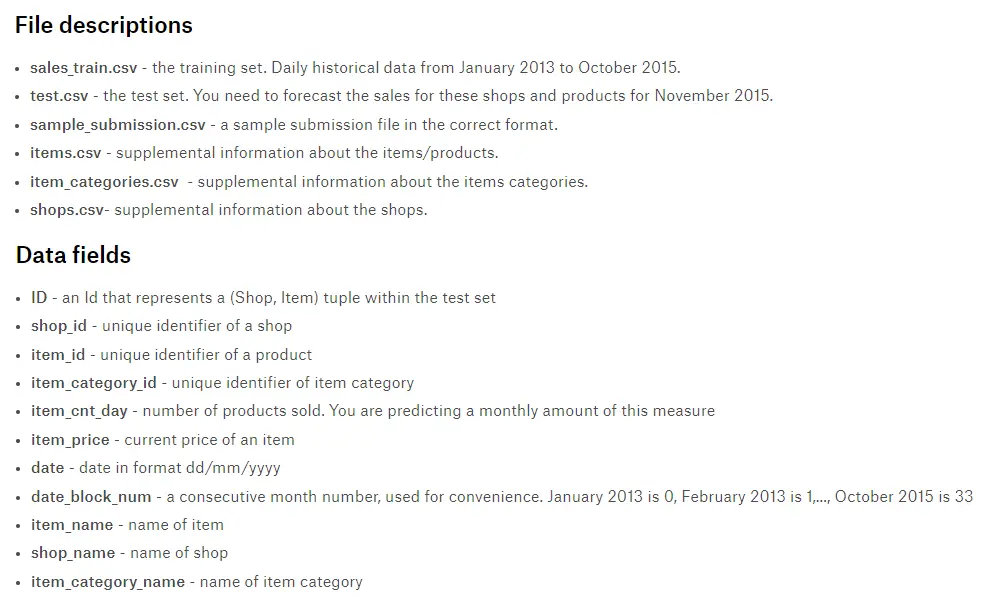
数据描述告诉我们,sale_train.csv可以通过shop_id、item_id、item_category_id来合并items.csv、item_categories.csv和shops.csv。
预测目标:item_cnt_month–商品月销量,也称为因变量(depend variable),需要根据item_cnt_day按月统计所有商店里每件商品的销量。为了简化模型,官方将item_cnt_month的取值范围限制在[0, 20]。
完成了item_cnt_month的统计后,字段date和item_cnt_day都不再需要了,但考虑到相同月份的商品价格也有可能会有变化,因此需要计算出商品的月均价–item_price_month,来替代item_price。
train = train.merge(shops, on='shop_id')
train = train.merge(items, on='item_id')
train = train.merge(cats, on='item_category_id')
train.drop('item_category_id', 1, inplace=True)
g = train.groupby(['date_block_num','shop_id','item_id']).agg({'item_cnt_day': ['sum']})
g.columns = ['item_cnt_month']
g.item_cnt_month = g.item_cnt_month.clip(0, 20)
train = train.merge(g.reset_index(), how='left', on=['date_block_num','shop_id','item_id'])
g = train.groupby(['date_block_num','shop_id','item_id']).agg({'item_price': ['mean']})
g.columns = ['item_price_month']
train = train.merge(g.reset_index(), how='left', on=['date_block_num','shop_id','item_id'])
train.drop(['date', 'item_price', 'item_cnt_day'], 1, inplace=True)
train.drop_duplicates(inplace=True)
train = train.sort_values('date_block_num').reset_index(drop=True)
除了合并数据外,还需要通过proc_df()将category类型的数据转化为int或float类型。
train_cats(train)
df, y, nas = proc_df(train, 'item_cnt_month')
proc_df()是Fastai Library的库函数,它将dataframe中category类型的数据转化为one-hot code,并对int、float类型的NaN数据做median fillna(),fillna()的结果返回给nas。train_cats()将所有object类型的转换为category类型。
数据处理完毕,接下来就是用Random Forest模型来试探数据。
m = RandomForestRegressor(n_jobs=-1)
%time m.fit(df, y)
m.score(df, y)
CPU times: user 2min 45s, sys: 142 ms, total: 2min 45s
Wall time: 1min 26s
0.9243853945527375
RF用法非常简单,只用三行代码就完成了模型训练和测试。sklearn提供了两种RF模型:RandomForestRegressor、RandomForestClassifier。前者是回归模型、后者是分类模型。超参n_jobs=-1指的是模型会根据CPU核心数为创建工作线程。RF是通过CPU来训练的,如果你的CPU能力有限或是在google colab上训练,可以按照后续介绍的操作来减少训练样本个数。
m.score()的返回值是 R 2 R^2 R2 score,Coefficient of determination:
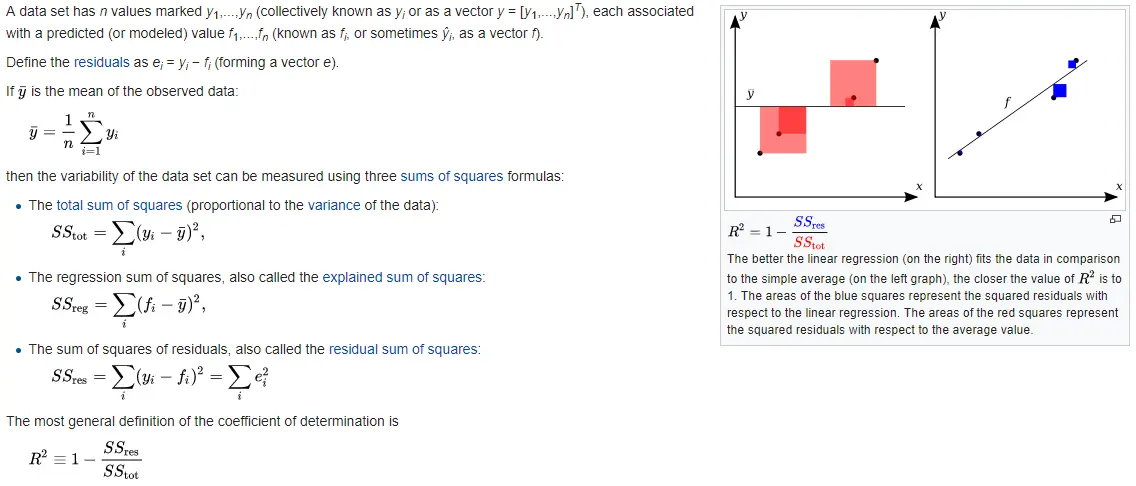
- S S t o t SS_{tot} SStot表示数据的方差有多大。
- S S r e s SS_{res} SSres则是RMSE。
- S S r e s SS_{res} SSres/ S S t o t SS_{tot} SStot,如果模型预测的准确率是平均水平,即图中 y − y^- y−所示的水平直线,则 S S r e s SS_{res} SSres/ S S t o t SS_{tot} SStot = 1, R 2 R^2 R2 = 0。
- R 2 R^2 R2 = 1 - S S r e s SS_{res} SSres/ S S t o t SS_{tot} SStot, R 2 R^2 R2的取值范围是[- ∞ infty ∞, 1],越接近于1表示模型的预测准确率越高,反之,如果 R 2 R^2 R2 < 0,就表示模型的预测准确率不如平均水平。
简单地说, R 2 R^2 R2是以平均预测值为基点来判断模型优劣的检验指标。打个比方,某校队要在同年级学生中选拔运动员,如果 S S t o t SS_{tot} SStot表示所有学生的平均身高,那么 R 2 R^2 R2越大,就表示该学生身高越突出,越符合选拔标准。
R 2 R^2 R2虽然不是放之海内皆准的衡量标准(不是所有运动员都需要是高个子),但也是一项普适指标(身高在大多数运动中都是重要因素)。这个数据集的metric是RMSE。
0.924是个不错的分数,但没有被validation set验证过的模型是不可靠的,因此我们需要创建validation set,用来检验模型的泛化能力。
对于时间序列类型的数据,validation set必须位于距离目标最近的时间段(latest time period),即2015年10月份(date_block_num == 33)。也就是说,我们用2015年10月之前的销售数据来训练模型,用以预测下一个月的月销量,通过计算模型预测值和真实值的 R 2 R^2 R2和RMSE就可以检测模型的预测准确率。我们的最终目标是预测2015年11月的销量。
def split_by_len(x, n): return x[:n].copy(), x[n:].copy()
n = df.shape[0] - 220000
trn_x, val_x = split_by_len(df, n)
trn_y, val_y = split_by_len(y, n)
trn_df, val_df = split_by_len(train, n)
len(trn_x), len(val_x)
这里我获取最近时间段的220000行(和test set规模相同)作为validation set。
def rmse(x, t): return np.sqrt(np.mean((x - t) ** 2))
def show_results(m):
res = [m.score(trn_x, trn_y), m.score(val_x, val_y)]
if hasattr(m, 'oob_score_'): res.append(m.oob_score_)
res.append(rmse(m.predict(val_x), val_y))
return res
m = RandomForestRegressor(n_jobs=-1, oob_score=True)
%time m.fit(trn_x, trn_y)
show_results(m)
[0.9238985285348011, -0.02553727954247975, 0.47282664895215065, 2.334026797384531]
show_results()返回的不仅有 R 2 R^2 R2,还有oob score和validation set的RMSE score。oob score类似于validation score,来自于RF自带的validation set,至于为何oob score和validation score存在较大差距,我们留待后文详解,在这里你只要知道它也是验证模型泛化效果的指标即可。
从validation set的 R 2 R^2 R2 score来看,模型的预测准确率还达不到平均准确率,模型无法根据输入的数据进行预测。train set的 R 2 R^2 R2 score之所以高,是因为模型只是记住了train set每个样本的最终结果,并没有学会如何判断样本间的差异,它过拟合了。接下来我们需要对数据进行深入挖掘,也就是EDA。
泛化效果差为什么是数据而不是模型的问题?
机器学习的三元素:数据、算力和算法。机器学习的核心是大数据,而所谓的数据,不仅是你拥有了多少数据,更重要的是你对这些数据有多深的理解。这就是为什么真正能将人工智能应用于各行各业的主导者不是BAT这类有算法有算力的互联网公司,而是那些深耕行业多年、拥有数据理解数据的传统行业公司。
EDA
sales_train.csv
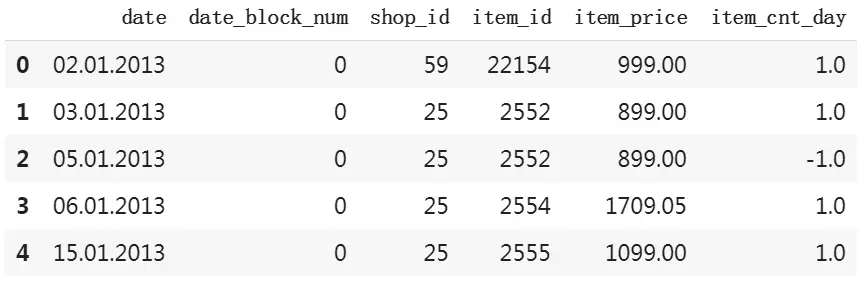
我们知道,销量跟售价有着非常密切的关系,例如通过打折就能促销,而且售价越高的商品销量越低,反之亦然。因此我们先分析销量和售价的关系:
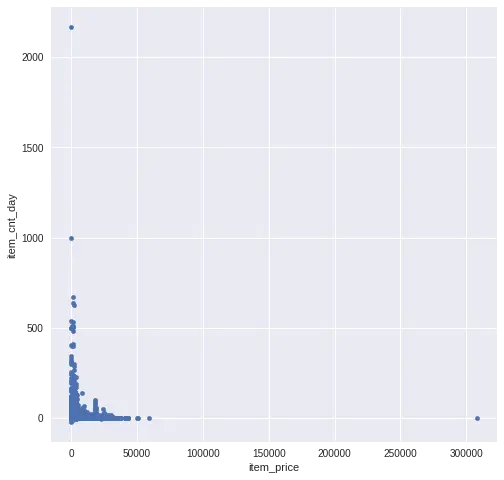
可以看到,大部分的商品单价都在10万之内,日销量在1000之内,和预想的一样,销量和售价呈反比。数据集中有3个样本是超出这两个范围的,应该把它们当作误差剔除掉,另外有样本的售价存在输入错误(<= 0),我们用字段的中间值(2499)来填充。
train = train[(train.item_price < 100000) & (train.item_cnt_day <= 1000)]
train.loc[train.item_price <= 0, 'item_price'] = 2499.0
为什么要剔除这些数据?
很多人对数据有种误解,以为通过大数据可以精准预测人的个性(需求和行为),实际上,这恰是数据分析师正在面临的窘境。大数据时代,数据公司已经收集了我们在互联网上的每一次点击,但直到现在,都没有哪家旅游公司能为我推送最合适我的个性化出行服务。实际上,算法只能预测人的共性部分,那么那些个性突出的样本就变成了误差,会给算法带来麻烦。
除了售价,影响商品销量的还有时间因素。玩具卖得最好的时节自然是圣诞节期间。
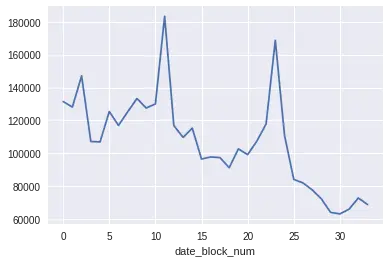
Figure 2是所有商品按月份统计的销量图,和预期相同,每年从11月开始到第二年2月是销售旺季,12月(圣诞季)达到全年销售顶点,而每年3月到10月的销量波动幅度都不大。除此之外,近3年来,每年的销售量都在下滑,这也跟俄罗斯的宏观经济吻合。从2014年开始,俄罗斯经济受到全球经济放缓、石油危机等因素的影响,可以说到现在都还没有结束,而且加上智能设备、电子游戏对传统玩具的冲击,人们减少玩具采买也在情理之中。
除了销量下滑,商品上下架也是要考虑的问题,尤其是那些只在test set出现的新商品。
item_last = np.unique(g.loc[31:].reset_index().item_id.values)
item_all = np.unique(g.reset_index().item_id.values)
n_item_outdated = len(list(set(item_all) - set(item_last)))
n_item_outdated, n_item_outdated / len(item_all)
(14620, 0.6704576722003118)
最近三个月(包括test月)的所有商品,33%的商品是新上架的商品。换句话说,用旧商品的销售数据预测新商品的销量,难度可想而知。
商店也存在新开和关张的情况,从最近三个月的数据统计来看,已经有14家门店关张了。已经关张的店铺数据还能不能用,这都是值得考虑的。
shop_last = np.unique(g.loc[31:].reset_index().shop_id.values)
shop_all = np.unique(g.reset_index().shop_id.values)
n_shop_closed = len(list(set(shop_all) - set(shop_last)))
n_shop_closed, n_shop_closed / len(shop_all)
(14, 0.23333333333333334)
不仅是train set,test set中也有train set中没有出现过新商品:
len(list(set(test.item_id) - set(test.item_id).intersection(set(train.item_id)))),
len(list(set(test.item_id))), len(test)
(363, 5100, 214200)
test set的商品有5100种,其中363种是train set所有没有出现的新商品,这就又给预测模型增加了不小难度。
Shops.csv

仔细观察可以发现shop_name是有规律的,它通过’ '分隔,第一个字段是城市名,第二个字段(如果有的话)是店铺的类型(ТЦ、ТРЦ、ТК …),后面的字段则是店名。
其中shop_id为(0,57),(10, 11),(1, 58)这三对店铺,它们的shop_name只是有一些拼写差异,可以认为是同一家店,因此对它们做合并处理。40号店和39号店的店名几乎完全相同,我猜40号店是39号店更名后的结果,所以也把两个店合并起来。
# Якутск Орджоникидзе, 56
train.loc[train.shop_id == 0, 'shop_id'] = 57
# Якутск ТЦ "Центральный"
train.loc[train.shop_id == 1, 'shop_id'] = 58
# Жуковский ул. Чкалова 39м²
train.loc[train.shop_id == 10, 'shop_id'] = 11
train.loc[train.shop_id == 39, 'shop_id'] = 40
shops.loc[shops.shop_name == 'Сергиев Посад ТЦ "7Я"', 'shop_name'] = 'СергиевПосад ТЦ "7Я"'
shops.loc[shops.shop_name == 'Цифровой склад 1С-Онлайн', 'shop_name'] = 'Цифровойсклад 1С-Онлайн'
shops['city'] = shops.shop_name.str.split(' ').map(lambda x: x[0])
shops.loc[shops.city == '!Якутск', 'city'] = 'Якутск'
shops['shop_type'] = shops.shop_name.str.split(' ')
.map(lambda x: 'ТЦ' if 'ТЦ' == x[1] else 'ТРЦ' if 'ТРЦ' == x[1] else
'ТК' if 'ТК' == x[1] else 'ТРК' if 'ТРК' == x[1] else 'МТРЦ' if 'МТРЦ' == x[1] else 'other')
shops['city_code'] = LabelEncoder().fit_transform(shops['city']).astype(np.int8)
shops['shop_type_code'] = LabelEncoder().fit_transform(shops['shop_type']).astype(np.int8)
之所以要提前生成city和shop_type的one-hot code: city_code、shop_type_code,是因为数据样本太大(6百多万行),将str类型转换为int类型可以节省很多内存空间,避免后续feature engineering出现内存不足的情况。
Items.csv
item_name也是可以深挖的字段,即将括号内字符串提取出来作为额外特征,为简化数据量,我只提取最后的两个特征。
item_names = items.item_name.values
pat = re.compile(r'((.*?))', re.S)
features = []
for o in item_names:
features.append(re.findall(pat, o)[-2:])
item_categories.csv
item_category_name可以通过’-'分割出商品的主类型和子类型。
cats.loc[32, 'item_category_name'] = 'Карты оплаты - Кино, Музыка, Игры'
cats['type'] = cats['item_category_name'].str.split('-').map(lambda x: x[0].strip())
cats['subtype'] = cats['item_category_name'].str.split('-').map(lambda x: x[1].strip() if len(x) > 1 else np.nan)
cats['type_code'] = LabelEncoder().fit_transform(cats['type']).astype(np.int8)
cats['subtype_code'] = LabelEncoder().fit_transform(cats['subtype'].fillna('xxx')).astype(np.int8)
Feature Engineering
特征工程(Feature engineering,下文简称FE)的目的是挖掘更多对机器学习算法有帮助的特征,让算法可以学习区分样本间的差异。
首先,把清理后的数据合并起来。如果在后续操作中出现内存不足的错误,你需要删除某些特征,例如’item_f1_code’、'item_f2_code’字段。
train = train[(train.item_price < 100000) & (train.item_cnt_day <= 1000)]
train.loc[train.item_price <= 0, 'item_price'] = 2499.0
# Якутск Орджоникидзе, 56
train.loc[train.shop_id == 0, 'shop_id'] = 57
test.loc[test.shop_id == 0, 'shop_id'] = 57
# Якутск ТЦ "Центральный"
train.loc[train.shop_id == 1, 'shop_id'] = 58
test.loc[test.shop_id == 1, 'shop_id'] = 58
# Жуковский ул. Чкалова 39м²
train.loc[train.shop_id == 10, 'shop_id'] = 11
test.loc[test.shop_id == 10, 'shop_id'] = 11
train.loc[train.shop_id == 39, 'shop_id'] = 40
test.loc[test.shop_id == 39, 'shop_id'] = 40
shops.loc[shops.shop_name == 'Сергиев Посад ТЦ "7Я"', 'shop_name'] = 'СергиевПосад ТЦ "7Я"'
shops.loc[shops.shop_name == 'Цифровой склад 1С-Онлайн', 'shop_name'] = 'Цифровойсклад 1С-Онлайн'
shops['city'] = shops.shop_name.str.split(' ').map(lambda x: x[0])
shops.loc[shops.city == '!Якутск', 'city'] = 'Якутск'
shops['shop_type'] = shops.shop_name.str.split(' ')
.map(lambda x: 'ТЦ' if 'ТЦ' == x[1] else 'ТРЦ' if 'ТРЦ' == x[1] else
'ТК' if 'ТК' == x[1] else 'ТРК' if 'ТРК' == x[1] else 'МТРЦ' if 'МТРЦ' == x[1] else 'other')
shops['city_code'] = LabelEncoder().fit_transform(shops['city']).astype(np.int8)
shops['shop_type_code'] = LabelEncoder().fit_transform(shops['shop_type']).astype(np.int8)
shops = shops[['shop_id', 'city_code', 'shop_type_code']]
cats.loc[32, 'item_category_name'] = 'Карты оплаты - Кино, Музыка, Игры'
cats['type'] = cats['item_category_name'].str.split('-').map(lambda x: x[0].strip())
cats['subtype'] = cats['item_category_name'].str.split('-').map(lambda x: x[1].strip() if len(x) > 1 else np.nan)
cats['type_code'] = LabelEncoder().fit_transform(cats['type']).astype(np.int8)
cats['subtype_code'] = LabelEncoder().fit_transform(cats['subtype'].fillna('xxx')).astype(np.int8)
cats = cats[['item_category_id', 'type_code', 'subtype_code']]
item_names = items.item_name.values
pat = re.compile(r'((.*?))', re.S)
item_f1, item_f2, features = [], [], []
for o in item_names:
features.append(re.findall(pat, o)[-2:])
for o in features:
if len(o) == 0:
item_f1.append(np.nan)
item_f2.append(np.nan)
elif len(o) == 1:
item_f1.append(o[0])
item_f2.append(np.nan)
else:
item_f1.append(o[1])
item_f2.append(o[0])
items['item_f1'] = pd.Series(item_f1)
items['item_f2'] = pd.Series(item_f2)
items['item_f1_code'] = LabelEncoder().fit_transform(items['item_f1'].fillna('xxx')).astype(np.int16)
items['item_f2_code'] = LabelEncoder().fit_transform(items['item_f2'].fillna('xxx')).astype(np.uint8)
items.drop(['item_f1', 'item_f2'], 1, inplace=True)
items.drop(['item_name'], 1, inplace=True)
Feature engineering的内容:
- 增加lag features
- 增加mean encoding features
- 增加price trend features
- 增加the resident or new item features
- 增加year、month
Lag features
lag features也称为滞后特征,它是一种将时间序列(time series)数据集转化为可监督学习数据集的常用技术。例如,matrix = lag_feature(matrix, [1,2,3,6,12], ‘item_cnt_month’),指的是为每个样本增加同一商品在上个月、2个月前、3个月前、半年前、一年前的月销量字段,这样一来,每个样本都跟它以前时间的数据建立了联系,数据就有了时间序列特征,机器学习算法就可以根据这些特征规律预测未来。你可以把它看作是一种滑动窗口技术,可以通过调解滑动步长,将不同时间节点的数据串起来。
Mean encoding
不管是哪种机器学习模型,它都需要将categorical特征(str)转化为数字(int or float),这个过程称为编码。Mean encoding就是常用的编码技术,和它对应的有one-hot encoding、label encoding。
‘shop_id’,‘item_id’,‘city_code’,'shop_type_code‘,'type_code’等都是label code,例如总共有50个city,就用[0, 49]给每个city一个编号。【Predict Future Sales】用深度学习玩转销量预测已经聊过label code和one-hot code的弊端,即code之间无法建立关联,而mean encoding则在一定程度上解决了这个问题。
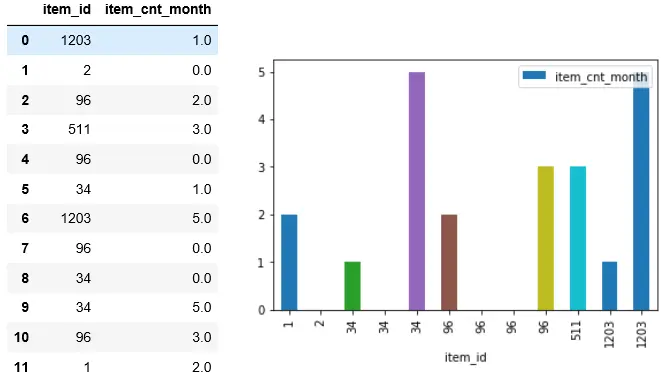
Figure 3是我从数据集中随机摘取的一个片段,从图中可以看到,相同’item_id’的’item_cnt_month’是随机分布的,通常情况下,数据的随机性越大,数据的误差就越大,不利于机器学习算法。
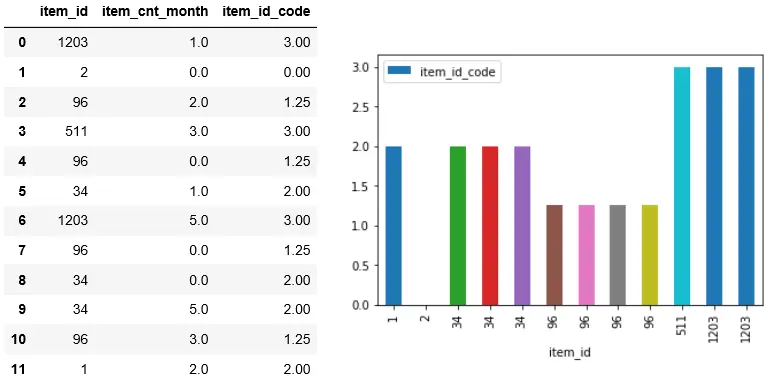
Figure 4中的’item_id_code’字段就是item_id的mean encoding,即将所有相同item_id的item_cnt_month相加求和,再除以item_id出现的频率。可以看到,item_id_code的图形比Figure 3的随机性要小得多,有利于算法利用item_id这个特征来区分样本。
g = df.groupby(by='item_id').item_cnt_month.agg({'item_cnt_month': 'mean'})
g.columns = ['item_id_code']
df2 = df.merge(g.reset_index(), on='item_id', how='left')
实际上,item_id_code既有item_id的频率特征也包含了因变量(item_cnt_month)与item_id的关联。然而,正因为它囊括了因变量的部分数据,因此有data leakage的可能,但这个风险在time series数据集中并不存在,毕竟数据集的特征都是从过去的time中获取的。
Price trend features
前面已经分析过,销量和售价呈反比,因此我们为每个样本增加的售价涨跌趋势特征(前一个月的)。
Revenue trend features
我们已经知道validation set和test set都会出现train set所没有的新商品,借助商店revenue趋势特征可以帮助算法预测新商品在现有店铺的销量。
The resident or new item features
'item_shop_last_sale’和’item_last_sale’用以纪录距离最近一次销售之间隔了几个月,通过它可以和之前月份的数据建立关联。'item_shop_first_sale’和’item_first_sale’则是用于表示新商品的特征。
Trainning
和前面的流程一样,通过proc_df()将category数据数字化、填充NaN数据。用最后两个月的数据分别构建validation set和test set。
trn_idxs = df[df.date_block_num < 22].index.values
val_idxs = df[df.date_block_num == 22].index.values
test_idxs = df[df.date_block_num == 23].index.values
trn_x, trn_y = df.loc[trn_idxs].copy(), y[trn_idxs].copy()
val_x, val_y = df.loc[val_idxs].copy(), y[val_idxs].copy()
test_x = df.loc[test_idxs].copy()
如果你的机器算力有限,或是想要减少模型训练的时间,可以通过set_rf_samples()来设置每颗决策树最大的随机采样数。当然如果条件允许,用完整的数据集训练效果更好。
# set_rf_samples(50000)
# len(trn_x), 50000 / len(trn_x)
# (6115195, 0.008176354147332997)
m = RandomForestRegressor(n_estimators=40, n_jobs=-1, min_samples_leaf=3, max_features=0.5, oob_score=True)
%time m.fit(trn_x, trn_y)
show_results(m)
[0.5325591159079617,
0.3752106515417507,
0.5227038231220662,
0.8979843084539196]
我用完整的数据集训练的结果:valid set的RMSE为0.898。相比“Look at Data Quickly”时的模型有了很大的进步。另外,模型超参也增加几个新面孔:
- n_estimators: 决策树的数量,一般来说决策树越多模型就越准确。Forest,指的就是由大量决策树共同作用,这也称为Model Ensembling。
- min_samples_leaf: 可以把它理解为模型在做出预测前所要经过的决策次数,min_samples_leaf的值越大表示决策次数越少,过少的决策会降低模型预测准确率,但过多的决策又容易overfitting。常用参数为:1、3、5、10。
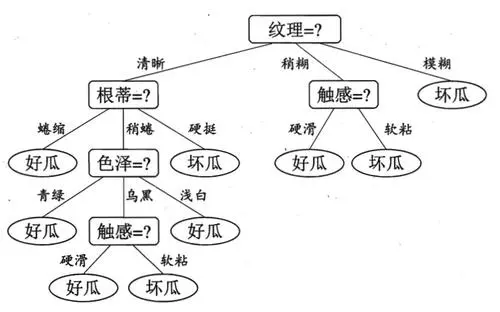
- max_features: 模型做决策的过程就是在决策树上建立分叉的过程,每个分叉都是对一个特征做判断的结果,如Figure 5所示,RF为了增加随机性,每个分叉所选取的特征都是来自于一个随机的特征子集,而max_features可以控制特征子集的建立。max_features=0.5,指的是每次决策时按1/2的比例随机划分待决策的特征为两个子集。常用的参数为:0.5、log2、sqrt。
Feature importance
从Figure 5可以看出,RF是通过判断特征来做预测的,那最好的情况是,所选取的所有特征都是核心特征。例如,要判断样本是猫还是狗,那么,“有没有毛”这个特征就属于没用的特征,而“耳朵下垂”这个特征就可以区分猫和狗。Feature importance就是用来判断特征有用与否的指标。
fi = rf_feat_importance(m, trn_x)
fi.plot('cols', 'imp', 'barh', figsize=(10, 8))
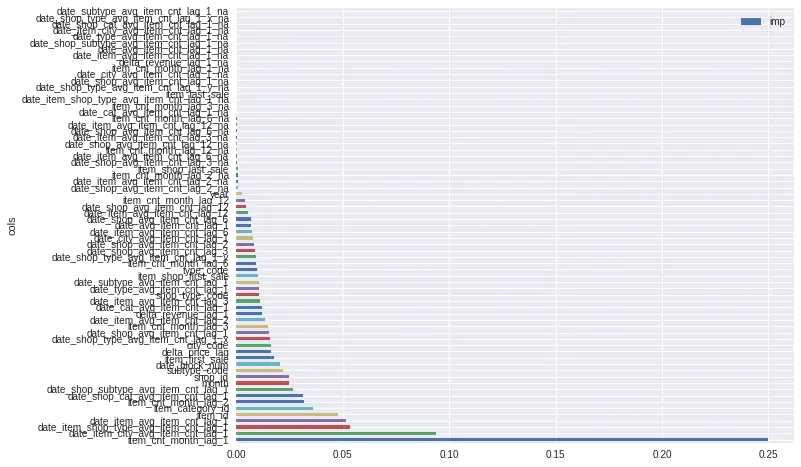
可以看到数据集中很多特征的重要性接近于0,因此接下来我们只选取feature importance大于0.004的特征。
m = RandomForestRegressor(n_estimators=40, n_jobs=-1, min_samples_leaf=4, max_features=0.5, oob_score=True)
%time m.fit(trn_x, trn_y)
show_results(m)
[0.5283864898099666,
0.37657590348293346,
0.5200241416189362,
0.8970026613695433]
重新训练后,可以看到score所有提升。
接着我经过调整’min_samples_leaf’和’max_features’,我发现min_samples_leaf=3,max_features=0.5的超参效果最佳,并将决策树增加到120后重新训练。
m = RandomForestRegressor(n_estimators=120, n_jobs=-1, min_samples_leaf=3, max_features=0.5, oob_score=True)
%time m.fit(trn_x, trn_y)
show_results(m)
[0.5384021046588424,
0.38571421105968695,
0.5286384392316963,
0.8904041458506617]
可以看到,选取更多的决策树效果明显,但训练时间也更长。为了减少训练时间,我把决策数增加到400的同时将采样数限制在50万。
set_rf_samples(500000)
m = RandomForestRegressor(n_estimators=400, n_jobs=-1, min_samples_leaf=3, max_features=0.5, oob_score=True)
%time m.fit(trn_x, trn_y)
show_results(m)
[0.6248771505427018,
0.40001388910585356,
0.5843704869177022,
0.8799794652507853]
最终RMSE是0.8799,在LB上排名16,对于没有完整训练的模型来说还是不错的。
Submission
yp = m.predict(test_x)
test = pd.read_csv(f'{PATH}/test.csv').set_index('ID')
sub = pd.DataFrame({'ID': test.index.values, 'item_cnt_month': yp})
sub.to_csv('submission.csv', index=False)
在预测test set之前,你最好还是把valid set重新加入train set,并重新训练,我这里是为了节省时间所以没有重新训练模型。我在LB上的score比validation set’s score要差一些,这其实也属于正常情况,毕竟我也只是训练了部分数据,而且正如我在【Predict Future Sales】用深度学习玩转销量预测 所说的那样,Public LB的可信度并不比validation set’s score更高。
另外,你如果有兴趣,也可以用其他模型试试,如xgboost、LightGBM以及前作介绍的深度神经网络,或者把它们的结果ensembling起来,这样预测的效果可能会更好。
END
总结一下,本文主要介绍了Random Forest的用法,以及时间序列数据集的特征工程方法。通过这个案例,你应该可以感觉到,对于真实世界的问题,尤其是time series、tabular data等问题,通过特征工程挖掘数据特征以及特征间的关联,比用哪个算法要重要得多得多得多。
Refences
- 【Predict Future Sales】用深度学习玩转销量预测
最后
以上就是怕黑口红最近收集整理的关于【Predict Future Sales】玩转销量预测 part2的全部内容,更多相关【Predict内容请搜索靠谱客的其他文章。








发表评论 取消回复