1 概述&背景
1.1 概述
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
1.2 背景
需求1:采集本地服务器日志文件上传到HDFS(数据源-本地服务器日志 目标存储系统:HDFS)
方案:编写代码读取本地服务器日志文件,通过HDFS客户端上传文件到HDFS
扩展需求2:采集Kafka集群数据(HBASE数据,MySQL数据等等),上传到HDFS(Kafka集群,HBASE,MySql等等)
方案:需要重新编写代码,针对不同的数据源,目标存储系统对接不同的客户端。
问题描述:1.现实中数据源的来源类型很多,目标存储系统类型很多。2.数据采集对接各种各样的数据源,各种各样的目标存储系统。如果换一个数据源或者目标存储系统,需要重新编写代码,非常麻烦。在这个背景下,Cloudera公司封装了一个框架Flume-提供一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
2 工作机制
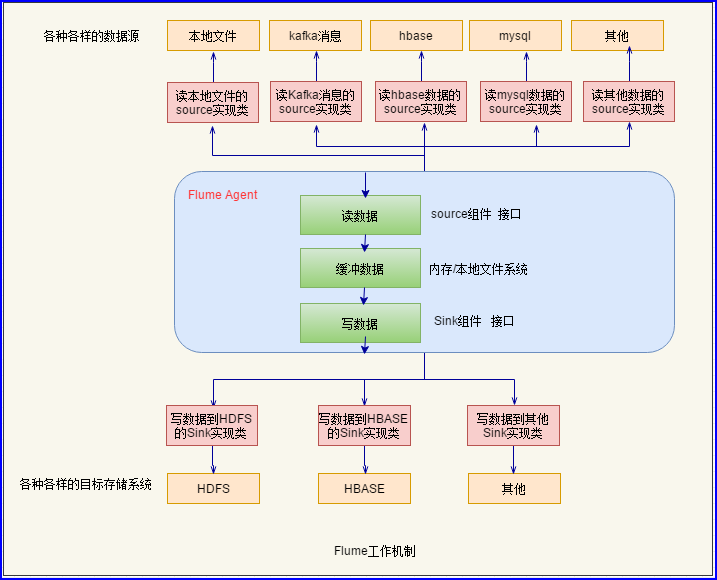
1.可以启动Flume的agent程序进行数据采集
2.每个agent程序中包含三大组件:
source
channel
sink
3.agent程序可以根据需要在多台机器上启动
缓冲数据Channel产生背景:
由于产生数据的速度不确定,一般由业务系统产生。例如某个时间段,用户量很多的时候,产生的数据很快,在某个时间段用户量很少的时候,产生数据的速度很慢,业务系统产生数据有波动,会导致数据读写不匹配,从而在读与写之间加了一个缓存数据(内存,本地文件系统)。
常见的实现类已经存在库里了,只需要写配置文件即可。
最后
以上就是失眠豆芽最近收集整理的关于Flume工作机制1 概述&背景2 工作机制的全部内容,更多相关Flume工作机制1内容请搜索靠谱客的其他文章。








发表评论 取消回复