文章目录
- 一、DataWorks 简介
- 1.1 DataWorks 的功能概述
- 1.2 DataWorks 产品特点
- 1.3 DataWorks 产品优势
- 1.4 应用场景 (助力企业搭建大数据信息平台)
- 二、DataWorks 基本概念
- 2.1 组织与项目空间
- 2.2 任务(Task)
- 2.3 工作流、节点、依赖关系
- 2.4 任务(Task)类别
- 2.5 实例(Instance)
- 2.6 资源与函数
- 三、DataWorks 功能架构
- 3.1 功能模块
- 3.2 组织管理
- 3.3 项目管理
- 3.4 数据开发
- 3.5 数据管理
- 3.6 运维中心
- 四、DataWorks 角色隔离
- 4.1 DataWorks 中的角色
- 五、DataWorks 开发流程
- 5.1 新建项目空间
- 5.2 添加组织成员+项目成员
- 5.3 数据开发
- 5.4 数据开发流程
- 5.5 数据输入
- 5.6 数据加工
- 5.7 数据输出
- 5.8 代码发布
- 5.9 生产调度
- 5.10 生产运维
- 六、DataWorks 数据开发
- 6.1 数据开发总览
- 6.2 任务开发
- 6.3 任务类型
- 6.4 脚本开发
- 6.5 函数管理
- 6.6 发布管理
- 6.7 导入本地文件
- 七、DataWorks 调度配置
- 7.1 调度周期配置
- 7.2 调度参数配置
- 7.3 DataWorks 中的参数功能
- 7.4 调度依赖关系
- 7.5 跨周期依赖
- 八、数据管理
- 8.1 数据管理
- 8.2 全局概览
- 8.3 数据表的管理操作
- 8.4 数据权限
- 九、DataWorks 运维管理
- 9.1 运维管理
- 9.2 运维有关的权限
- 9.3 运维概览
- 9.4 手动任务 & 周期任务
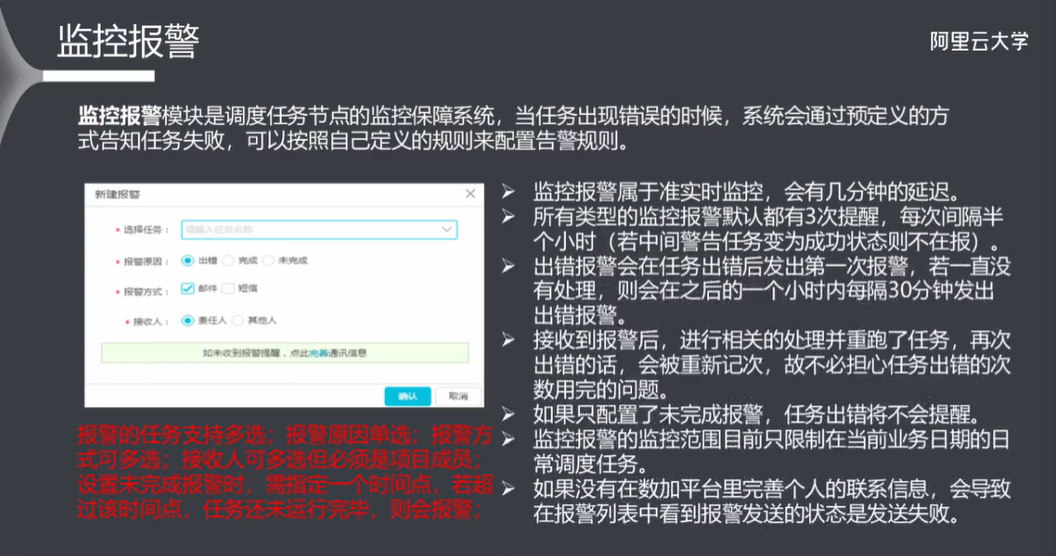
- 9.5 监控报警
- 十、DataWorks 项目管理
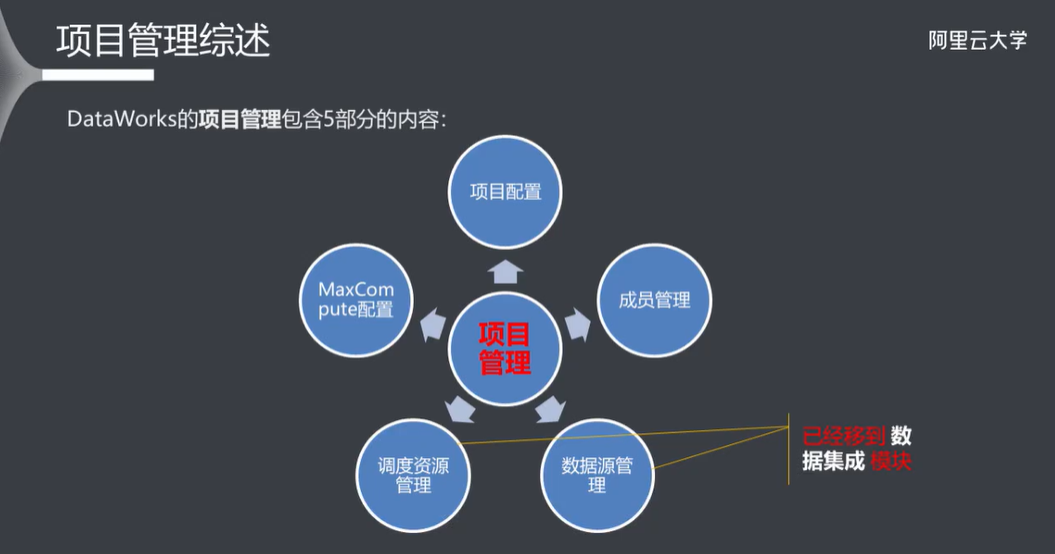
- 10.1 项目管理综述
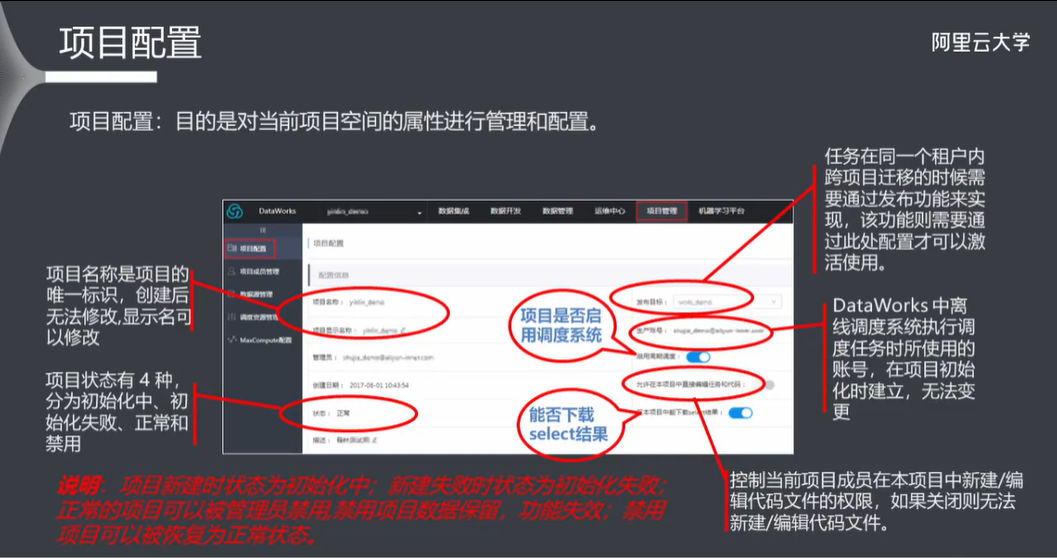
- 10.2 项目配置
- 10.3 项目成员管理
- 10.4 调度资源管理
一、DataWorks 简介
DataWorks(数据工场,原大数据开发套件)是阿里云重要的PaaS平台产品,提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
DataWorks支持多种计算和存储引擎服务,包括离线计算MaxCompute、开源大数据引擎E-MapReduce、实时计算(基于Flink)、机器学习PAI、图计算服务Graph Compute和交互式分析服务等,并且支持用户自定义接入计算和存储服务。DataWorks提供全链路智能大数据及AI开发和治理服务。

1.1 DataWorks 的功能概述
全面托管的调度
- DataWorks提供强大的调度功能,详情请参见调度配置。
- 支持根据时间、依赖关系,进行任务触发的机制。详情请参见时间属性和依赖关系。
- 支持每日千万级别的任务,根据DAG关系准确、准时地运行。
- 支持分钟、小时、天、周和月多种调度周期配置。
- 完全托管的服务,无需关心调度的服务器资源问题。
- 提供隔离功能,确保不同租户之间的任务不会相互影响。
DataWorks支持离线同步、Shell、ODPS SQL、ODPS MR等多种节点类型,通过节点之间的相互依赖,对复杂的数据进行分析处理。
- 数据转化:依托MaxCompute强大的能力,保证了大数据的分析处理性能。
- 数据同步:依托DataWorks中数据集成的强力支撑,支持超过20种数据源,为您提供稳定高效的数据传输功能。
可视化开发
- DataWorks提供可视化的代码开发、工作流设计器页面,无需搭配任何开发工具,简单拖拽和开发,即可完成复杂的数据分析任务。只要有浏览器有网络,您即可随时随地进行开发工作。
监控告警
- 运维中心提供可视化的任务监控管理工具,支持以DAG图的形式展示任务运行时的全局情况,详情请参见运维中心。
1.2 DataWorks 产品特点

1.3 DataWorks 产品优势

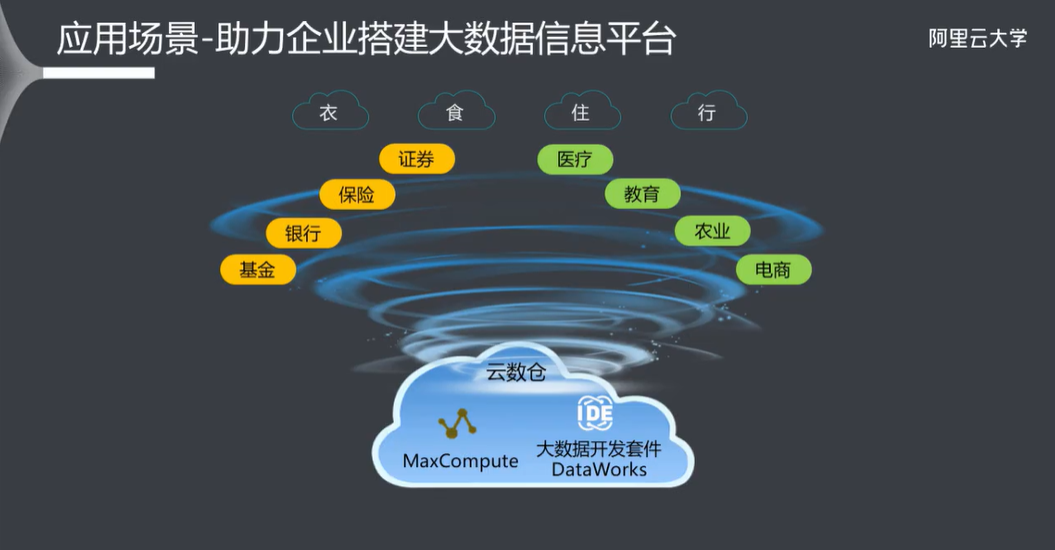
1.4 应用场景 (助力企业搭建大数据信息平台)
二、DataWorks 基本概念
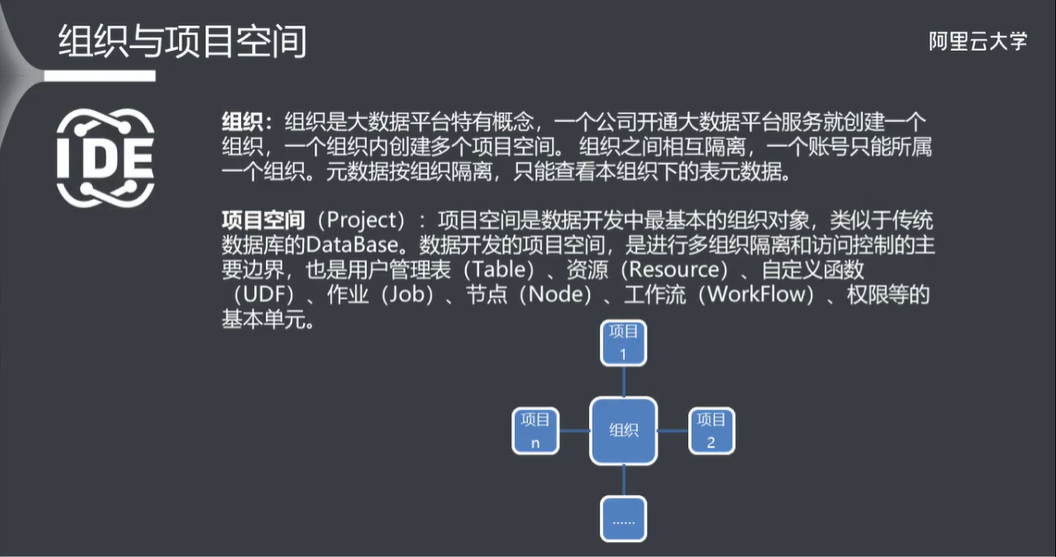
2.1 组织与项目空间
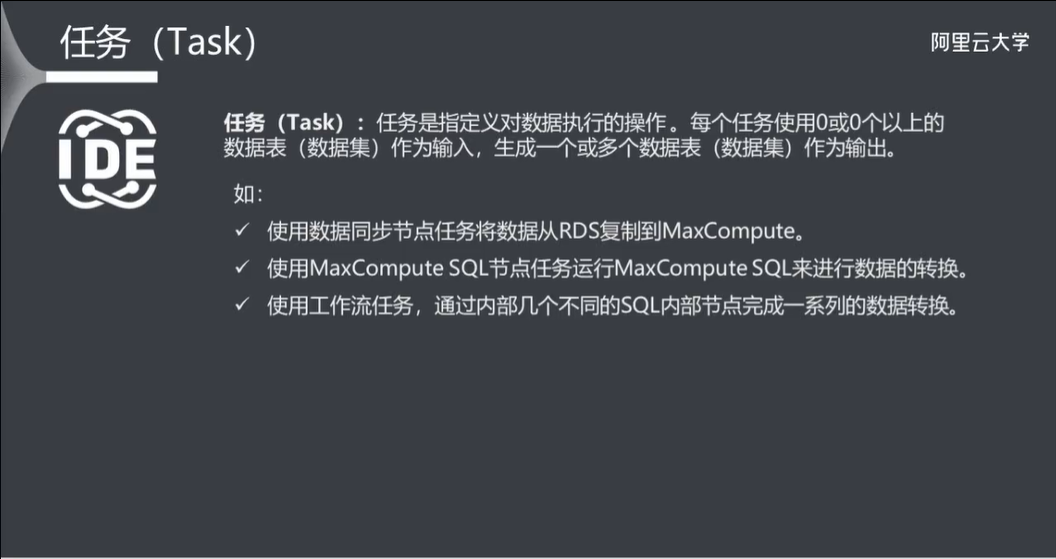
2.2 任务(Task)
2.3 工作流、节点、依赖关系

2.4 任务(Task)类别

2.5 实例(Instance)

说明:在阿里云大数据开发平台中,节点任务在执行时会被实例化,并以MaxCompute 实例的形式存在。实例会经历未运行、等待时间/等待资源、运行中,成功/失败几个状态。
2.6 资源与函数
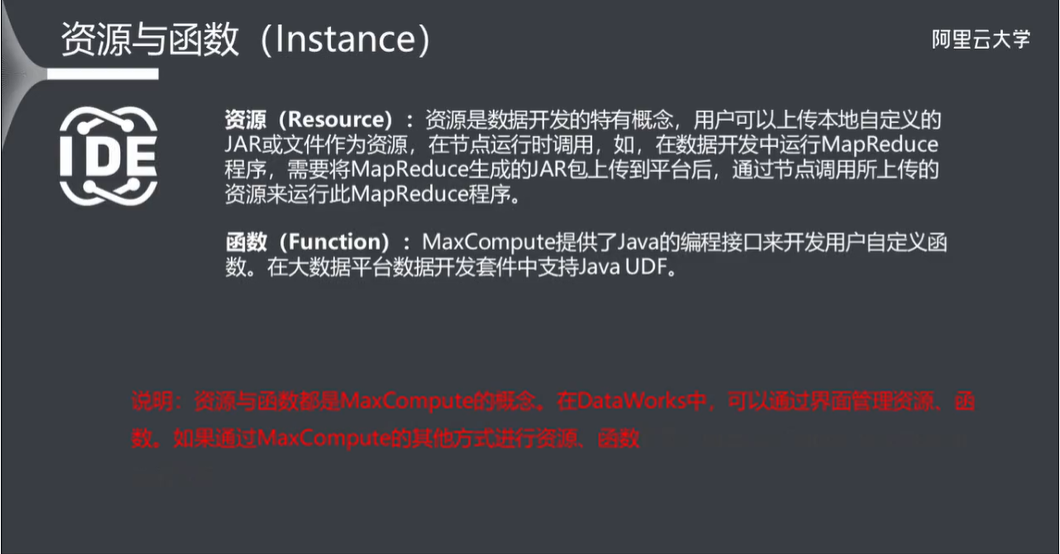
说明:资源与函数都是 MaxCompute 的概念。
三、DataWorks 功能架构
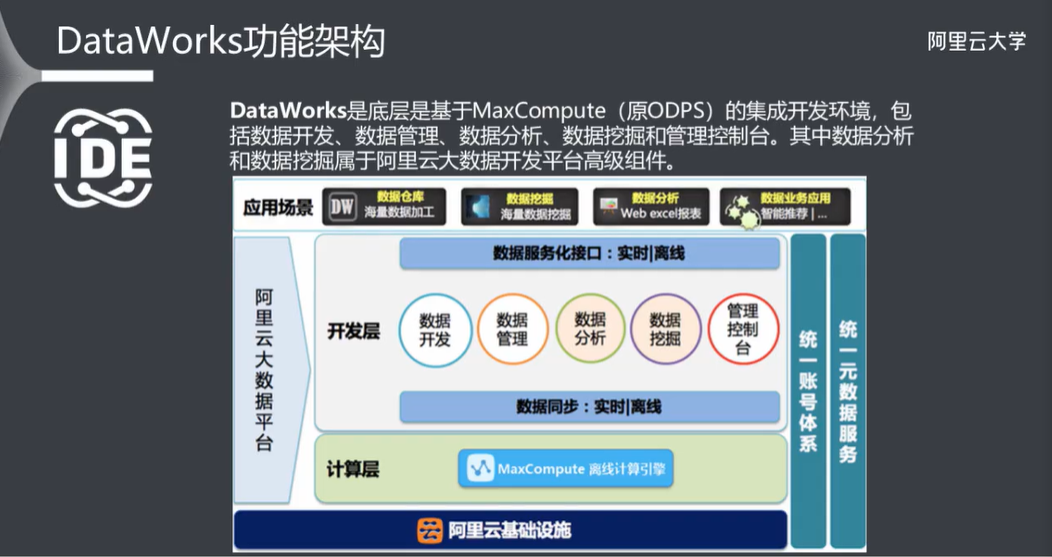
3.1 功能模块
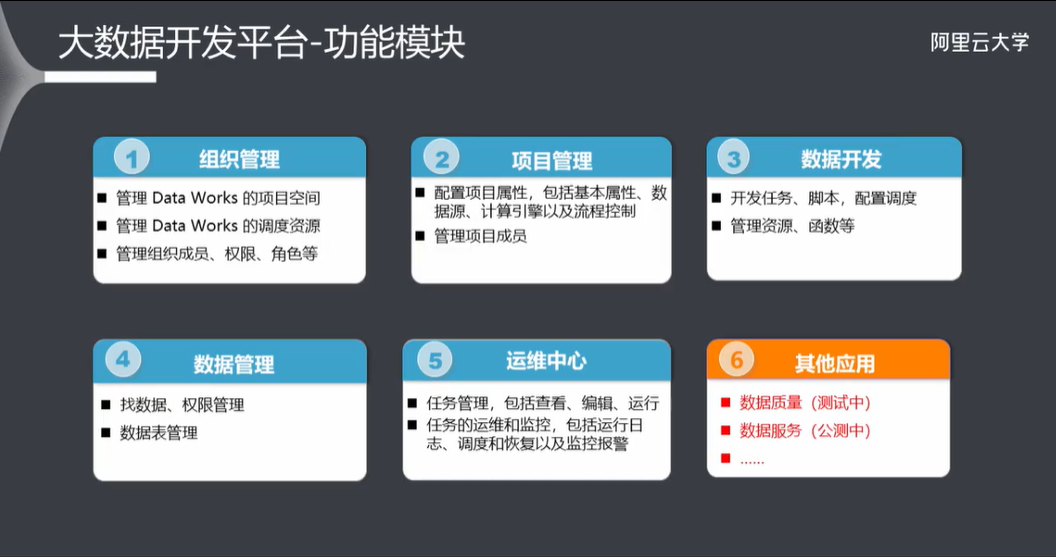
3.2 组织管理
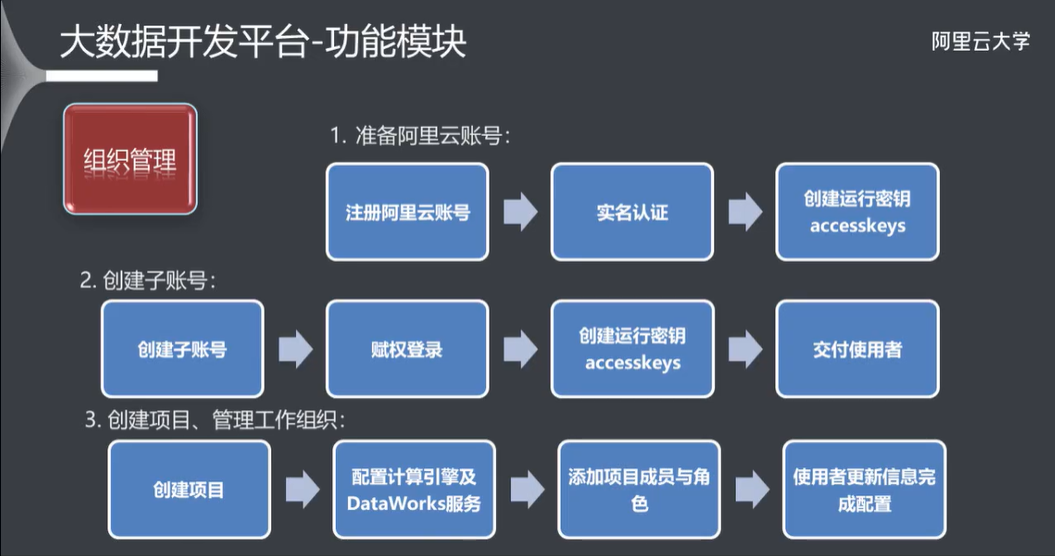
3.3 项目管理
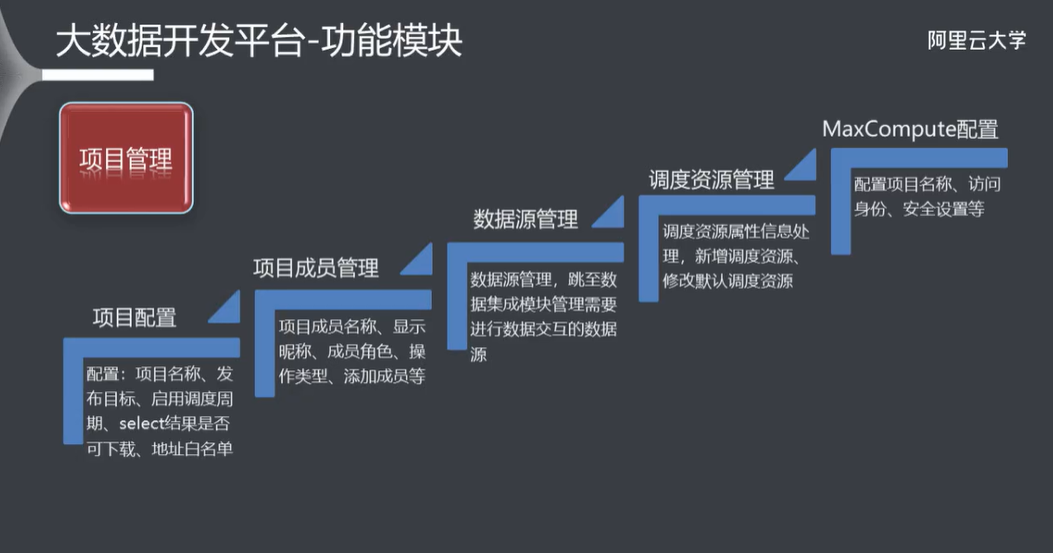
3.4 数据开发
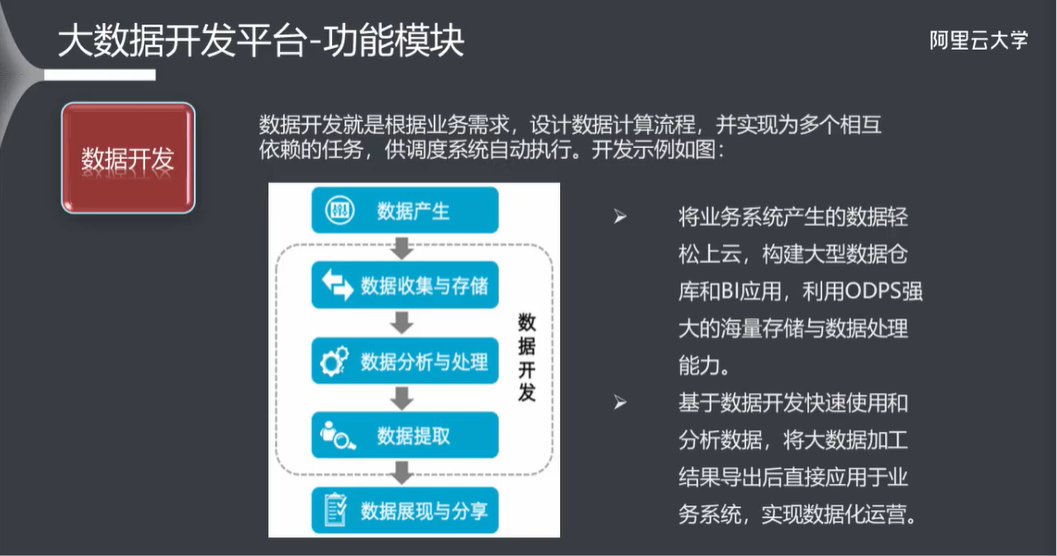
3.5 数据管理

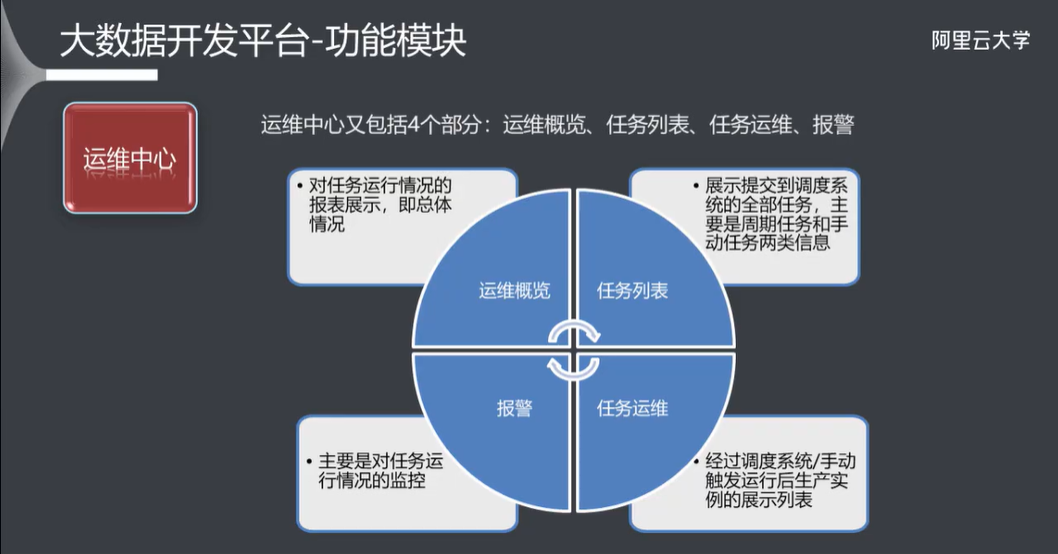
3.6 运维中心
四、DataWorks 角色隔离
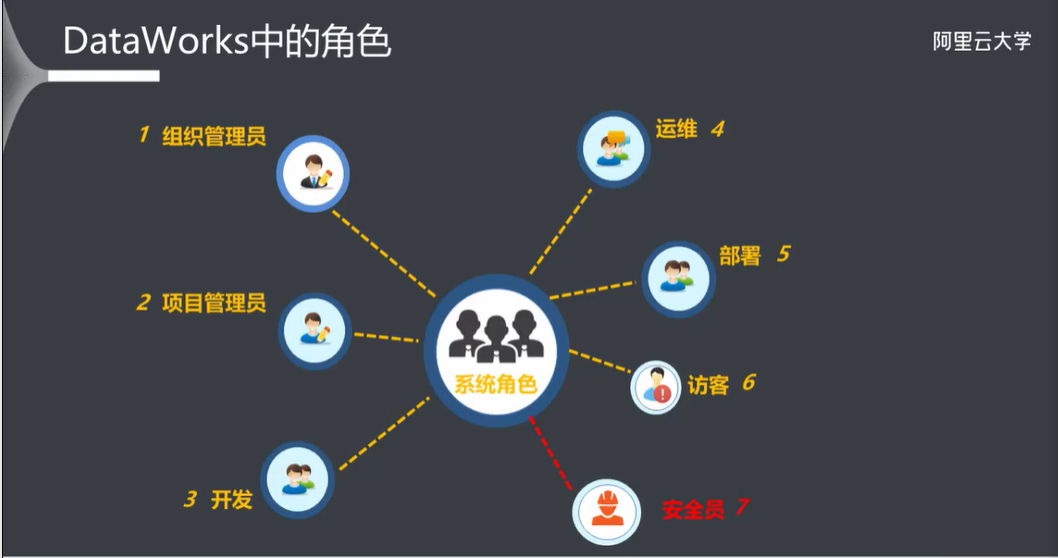
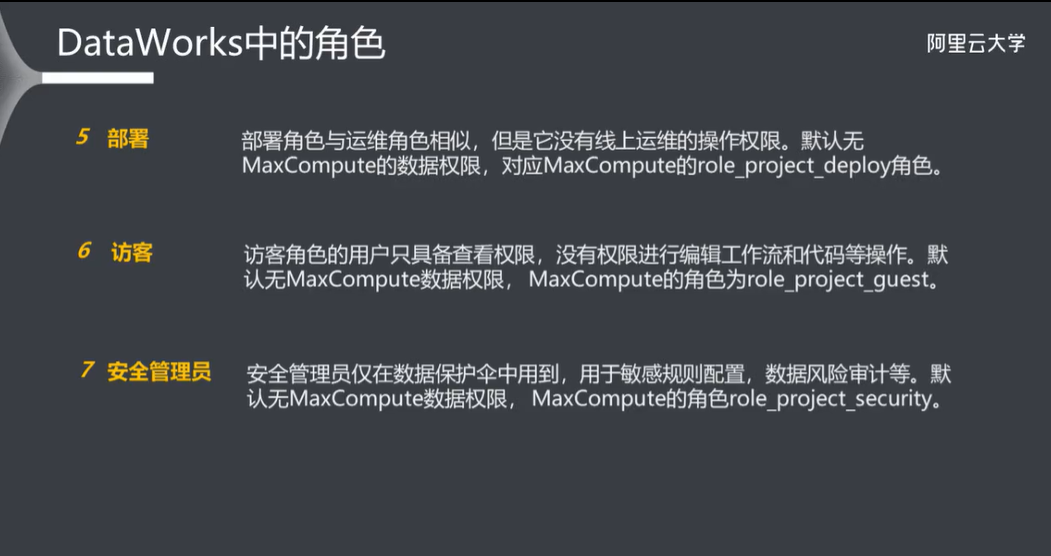
4.1 DataWorks 中的角色


五、DataWorks 开发流程
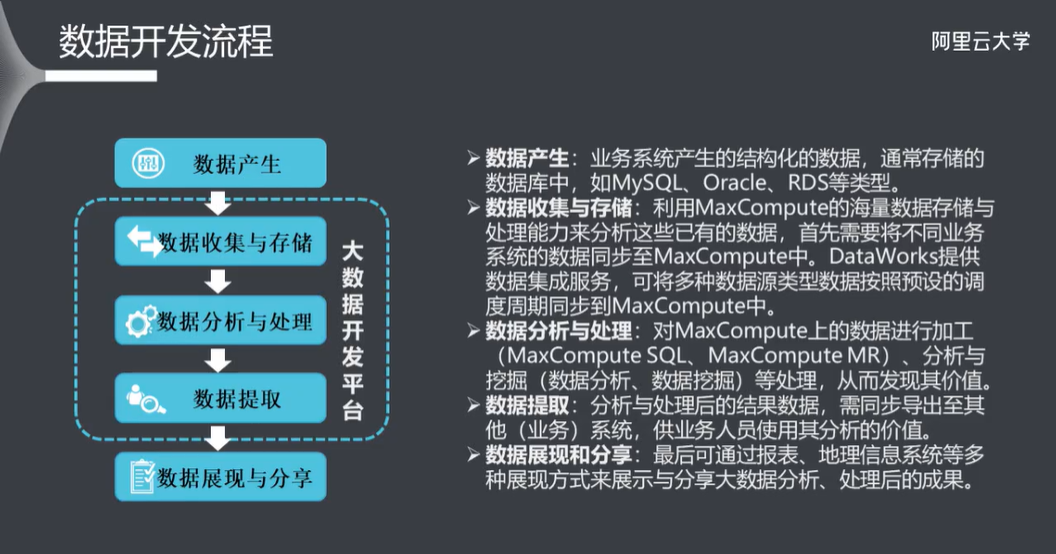
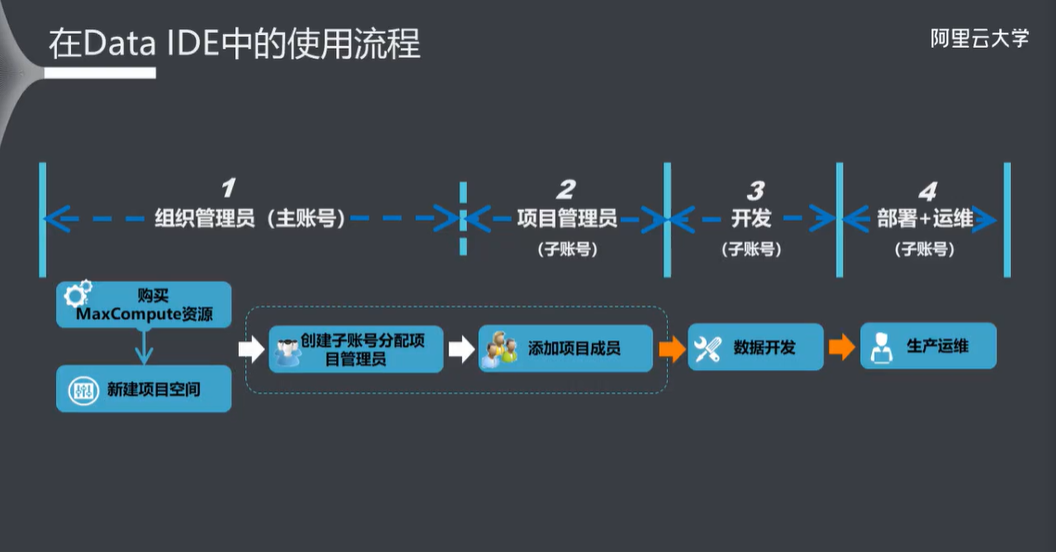
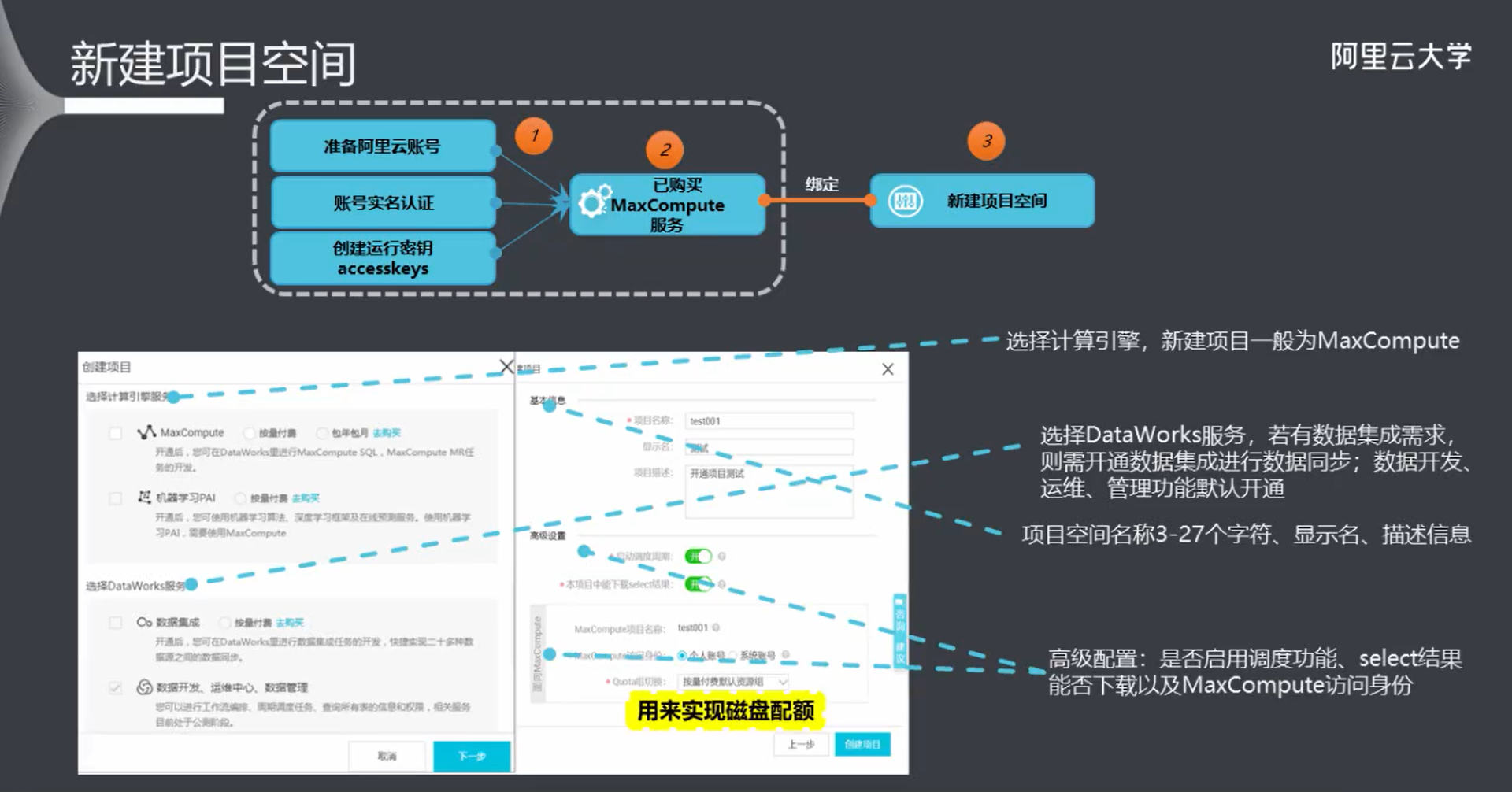
5.1 新建项目空间
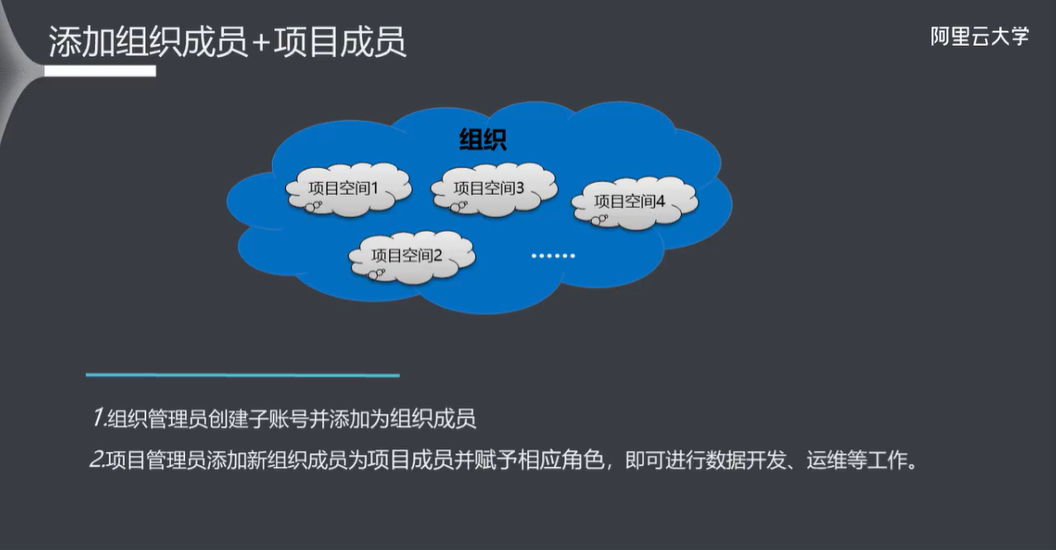
5.2 添加组织成员+项目成员
5.3 数据开发

5.4 数据开发流程
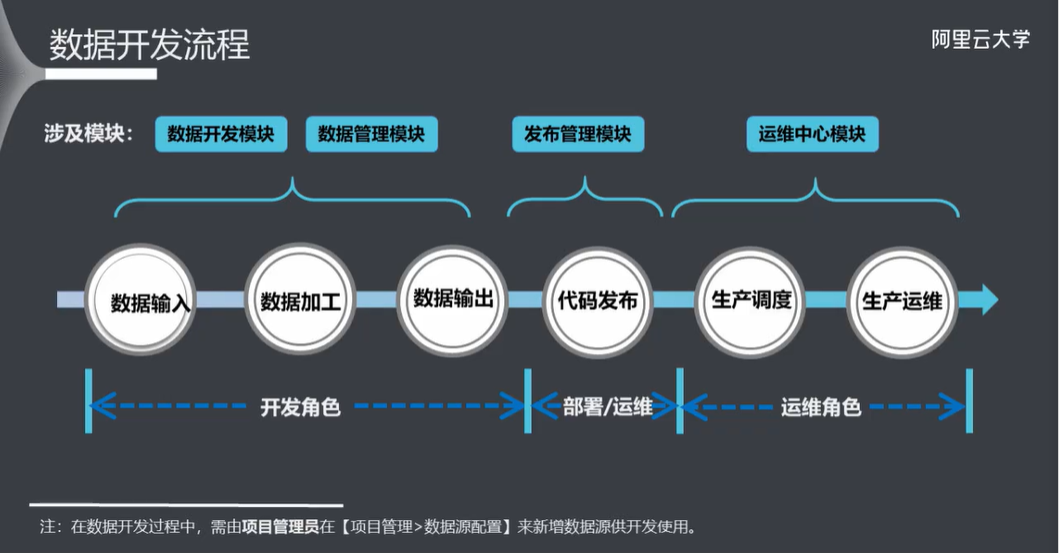
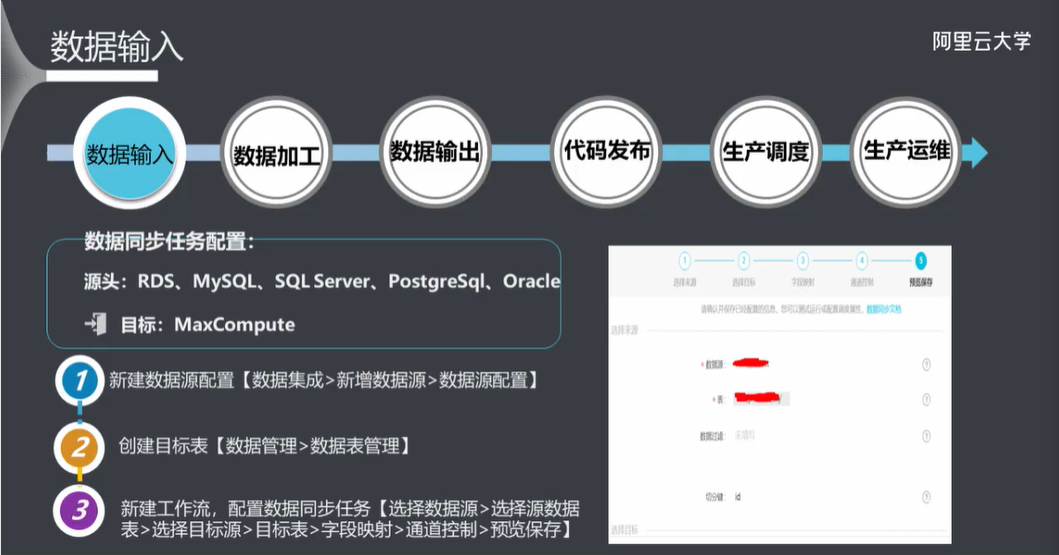
5.5 数据输入
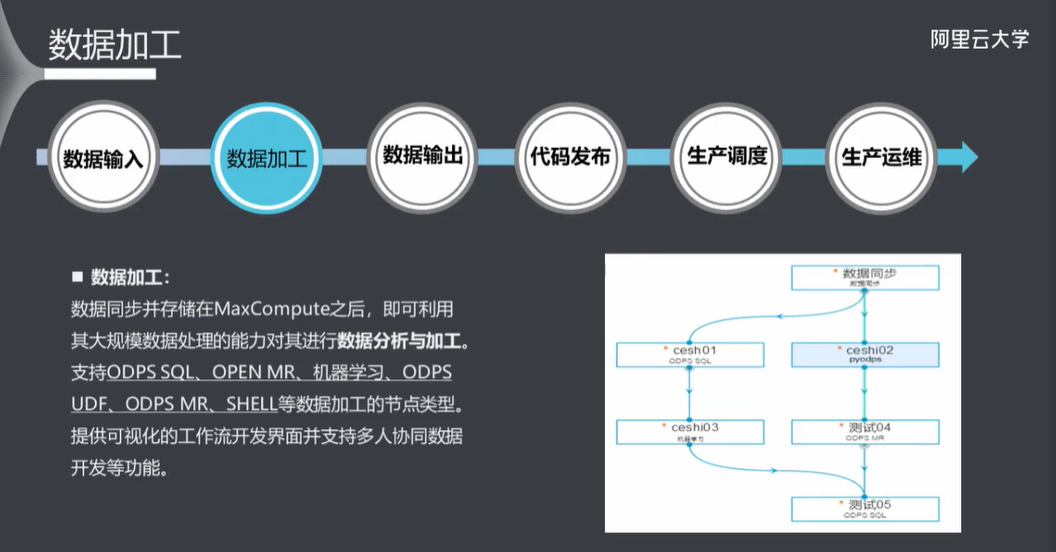
5.6 数据加工
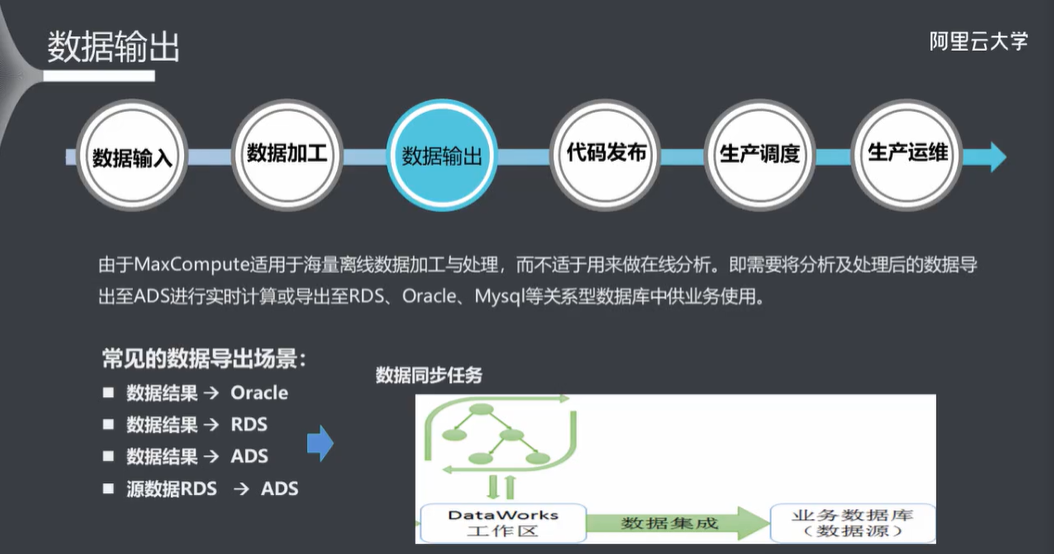
5.7 数据输出
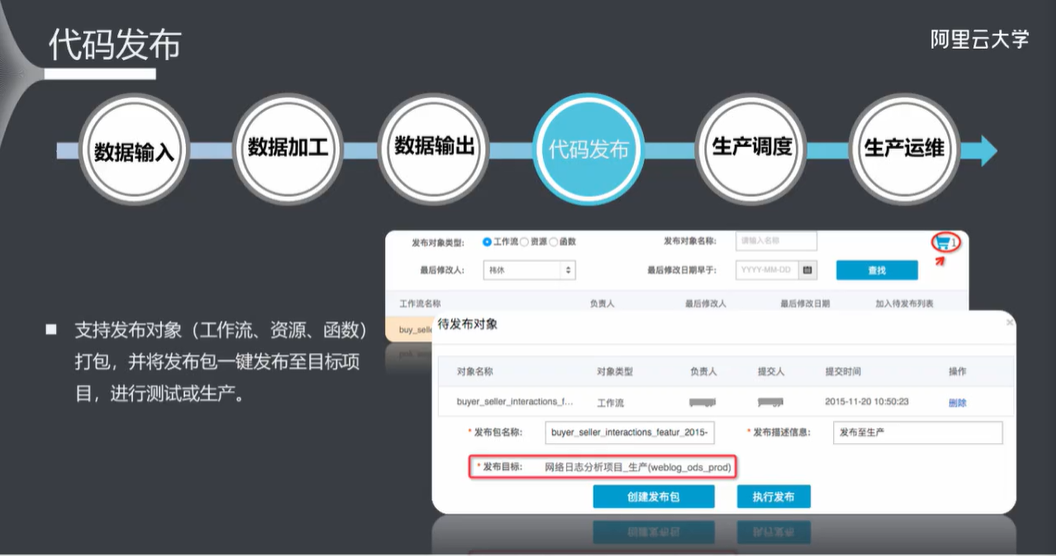
5.8 代码发布
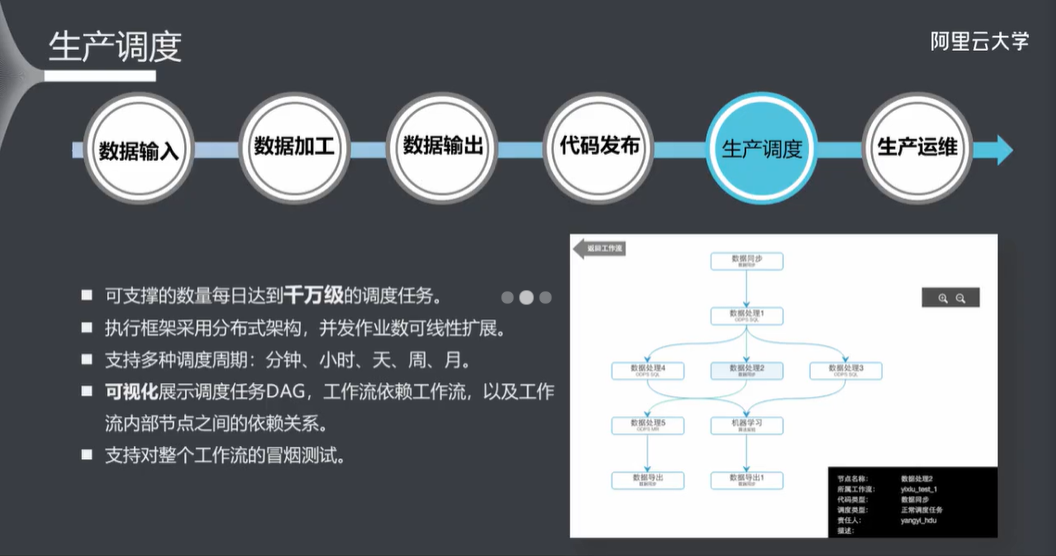
5.9 生产调度
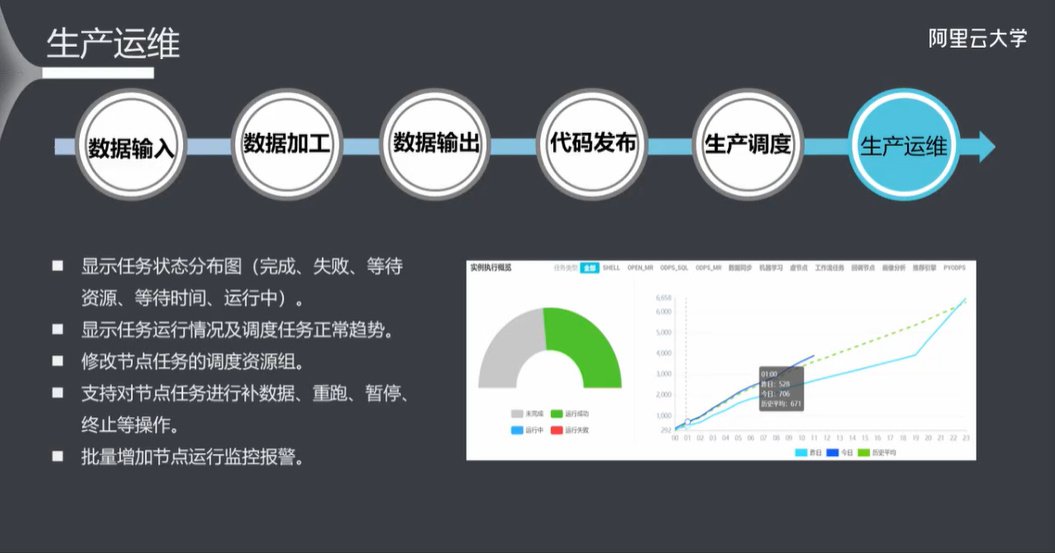
5.10 生产运维
六、DataWorks 数据开发
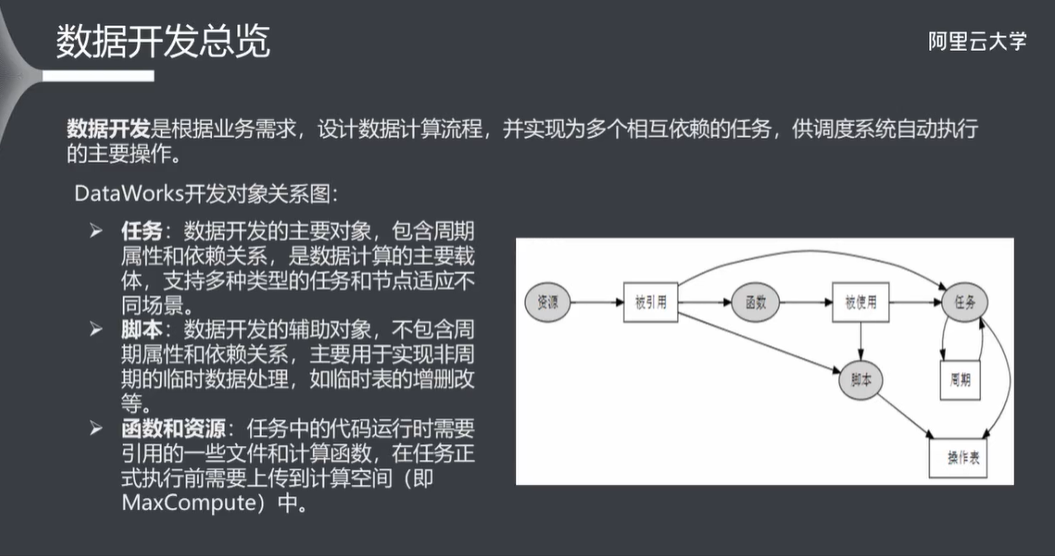
6.1 数据开发总览
四种运行方式:
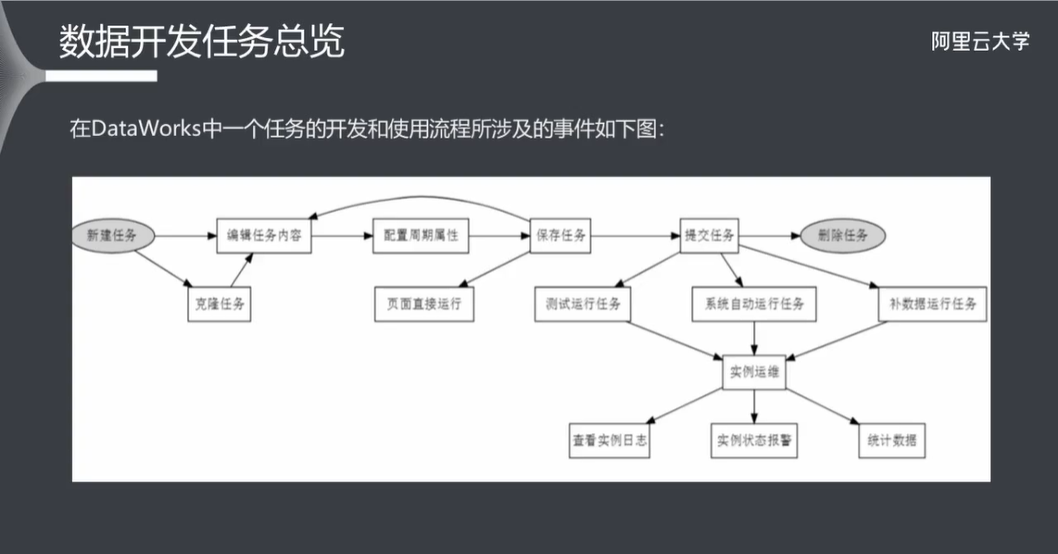

数据开发模块中除了组织管理员权限外,其余角色包括:项目管理员、开发、运维、部署和访客。
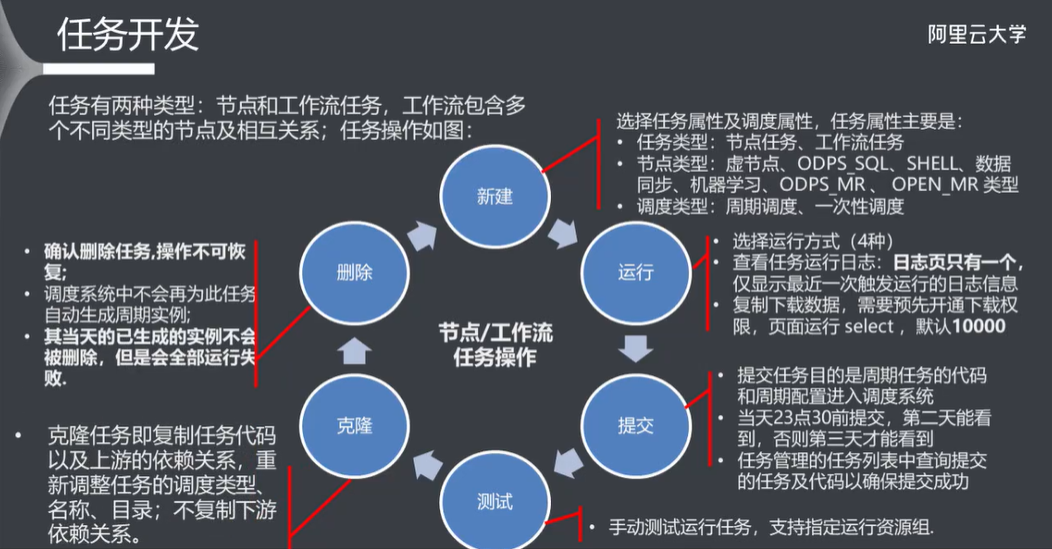
6.2 任务开发
6.3 任务类型

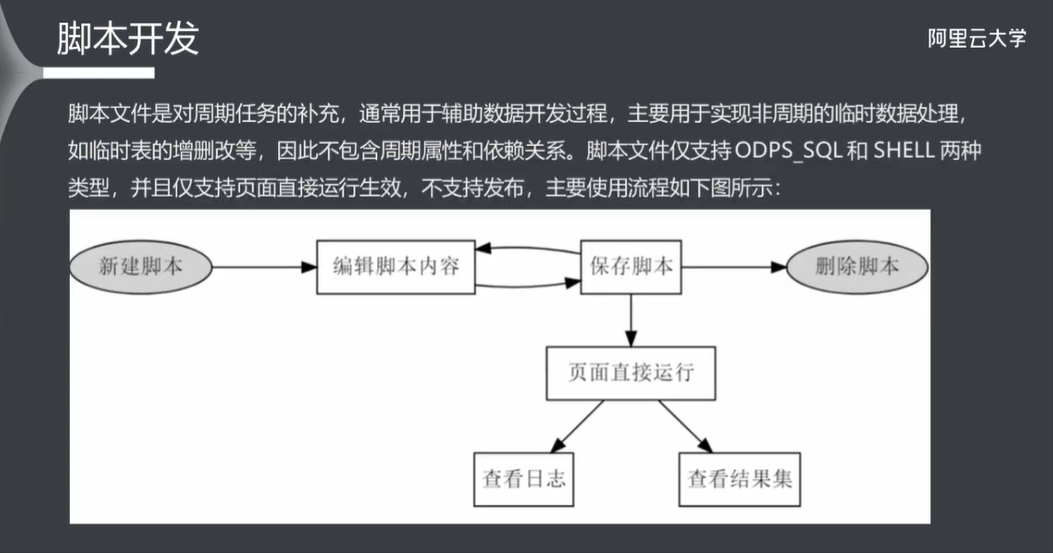
6.4 脚本开发
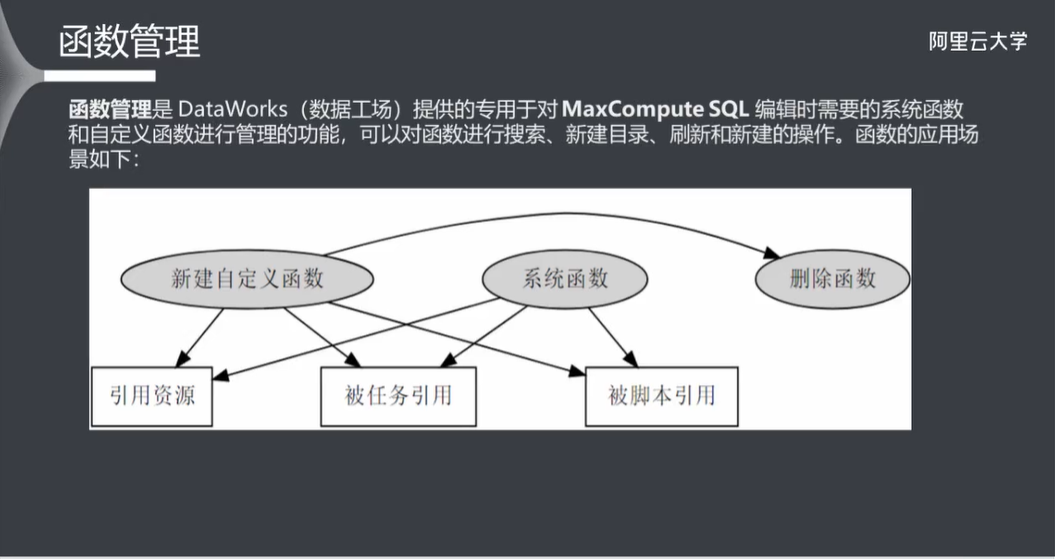
6.5 函数管理
6.6 发布管理

6.7 导入本地文件

七、DataWorks 调度配置
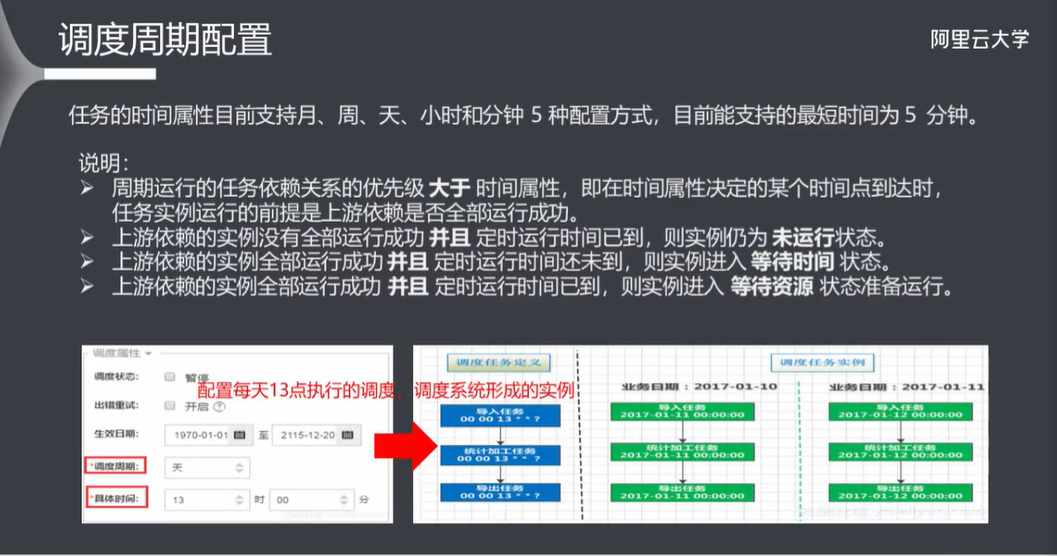
7.1 调度周期配置
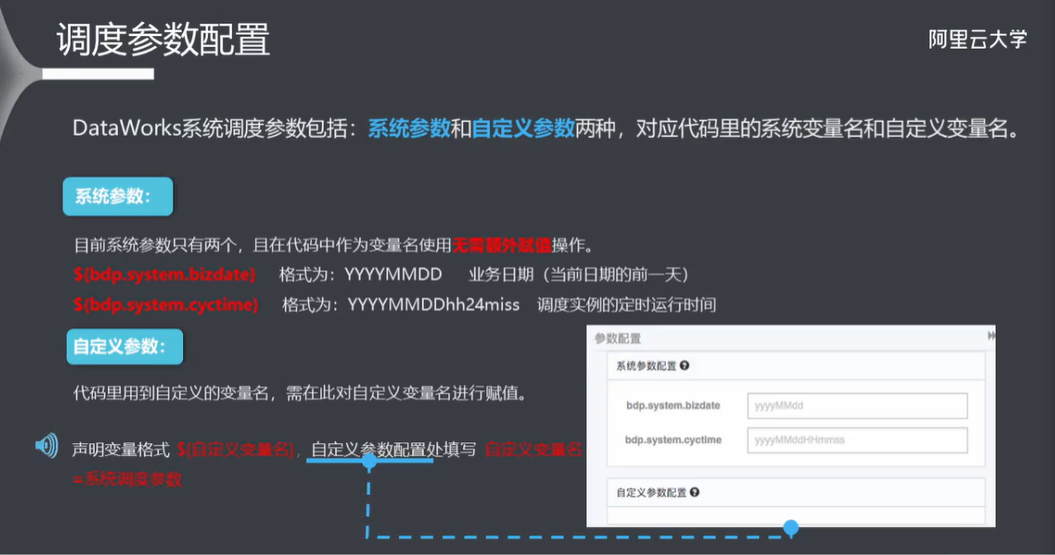
7.2 调度参数配置
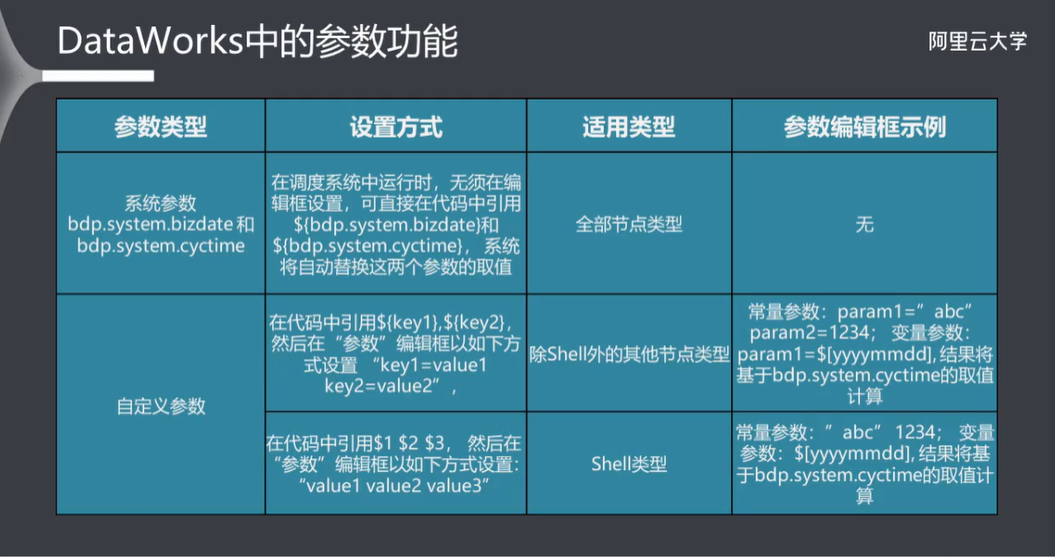
7.3 DataWorks 中的参数功能
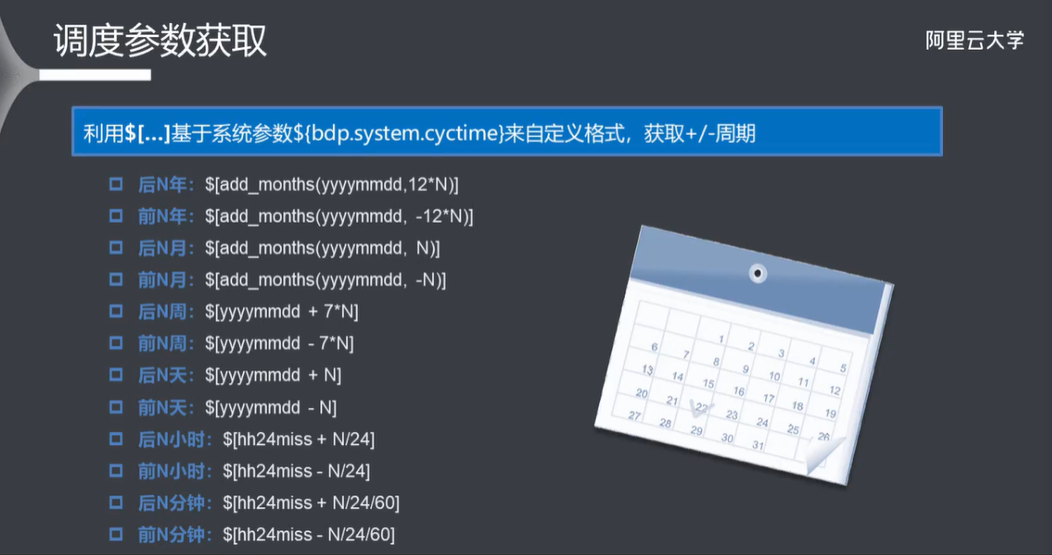
调度参数获取
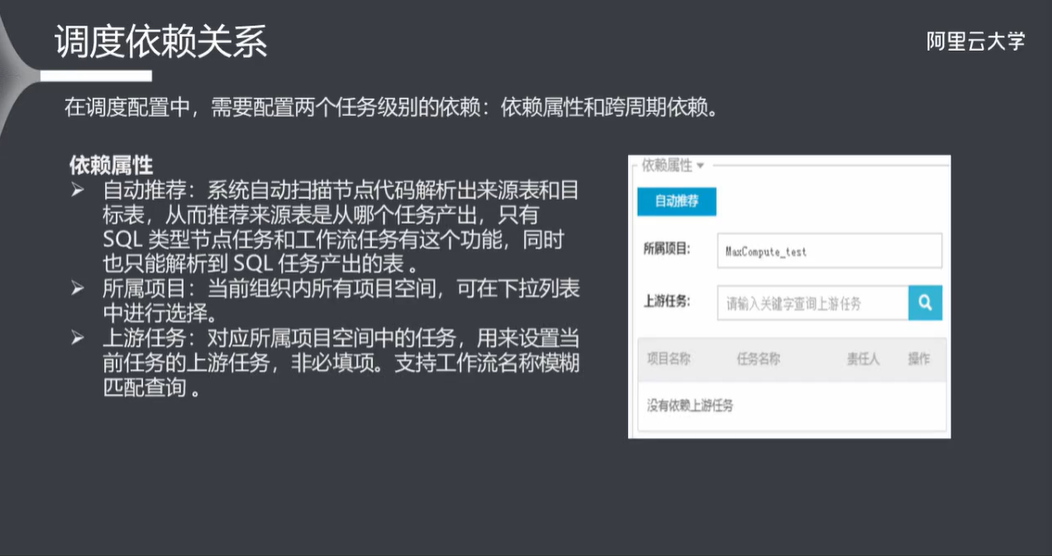
7.4 调度依赖关系
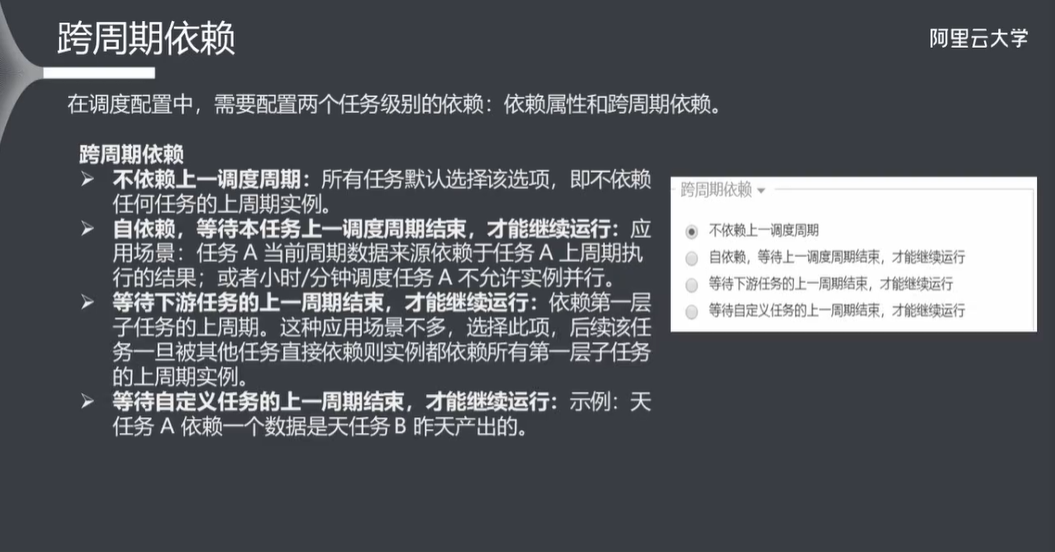
7.5 跨周期依赖
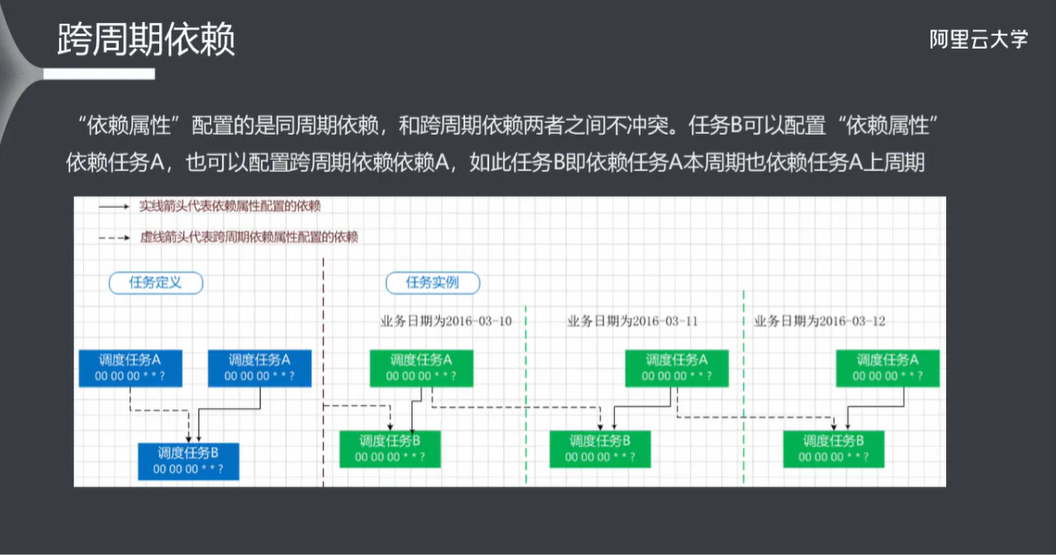
八、数据管理
8.1 数据管理
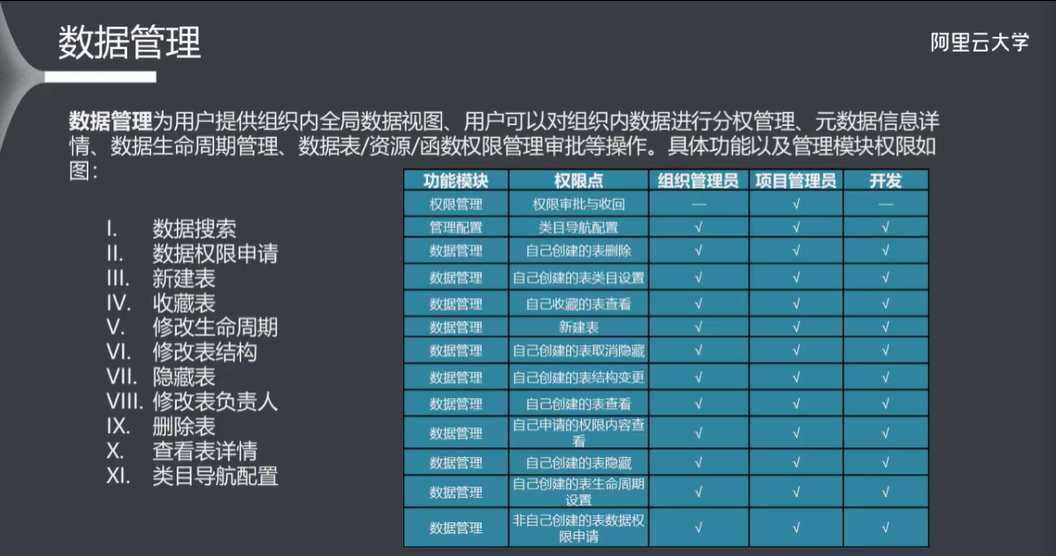
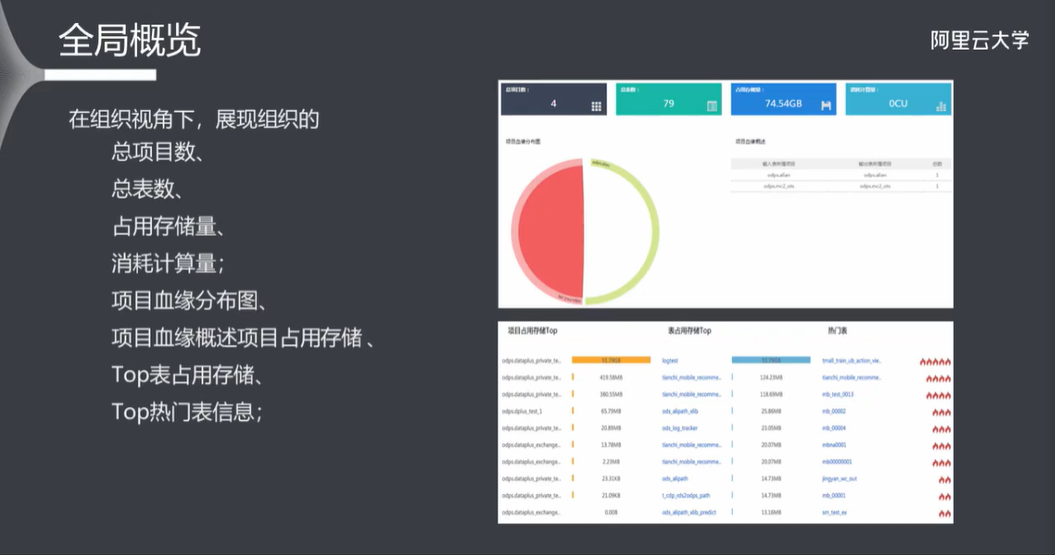
8.2 全局概览
8.3 数据表的管理操作
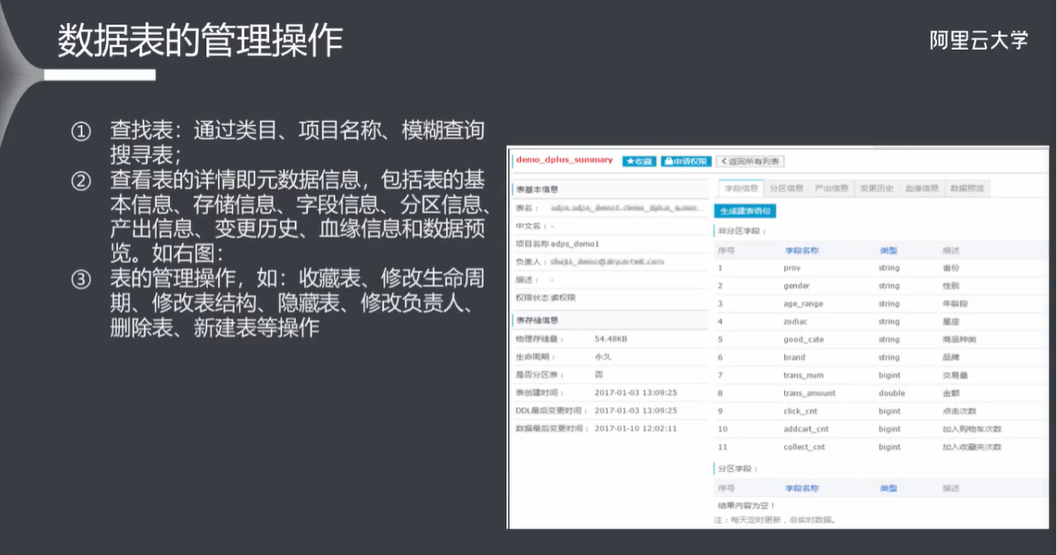
注意:数据管理模块中的表存储信息是离线计算得出的,默认是一天同步一次这个信息,是非实时同步,所以与真实信息不一致。
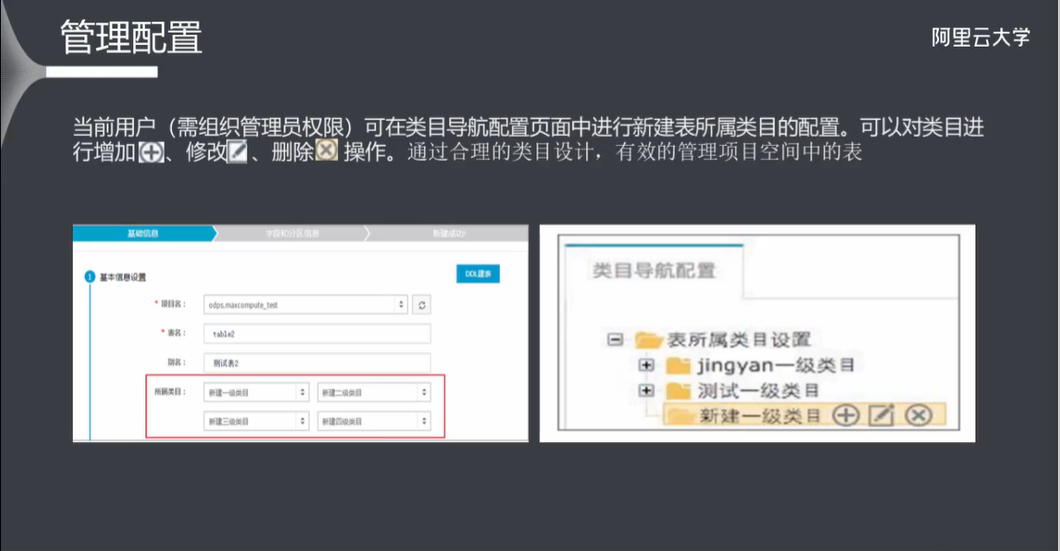
8.4 数据权限


九、DataWorks 运维管理
9.1 运维管理
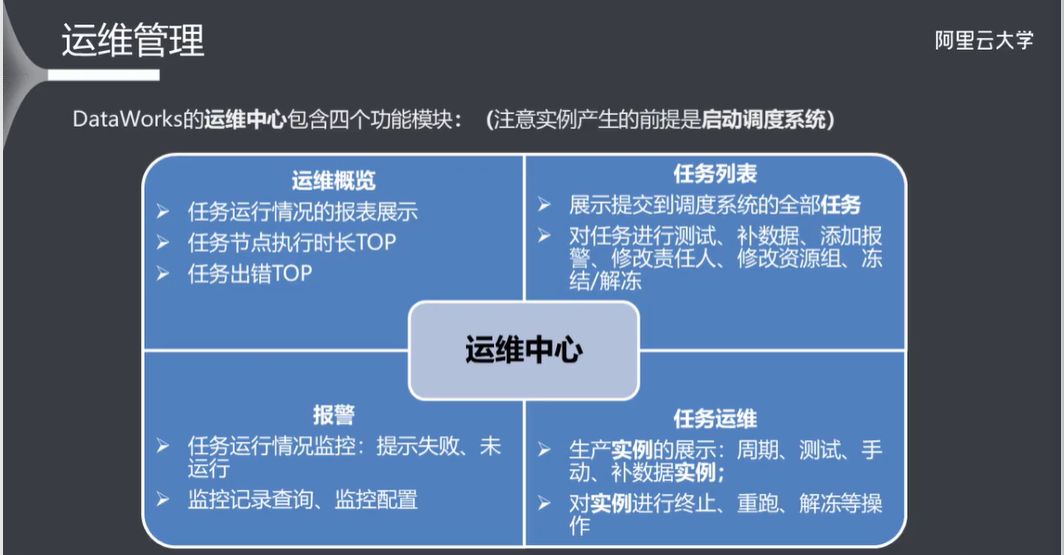
9.2 运维有关的权限

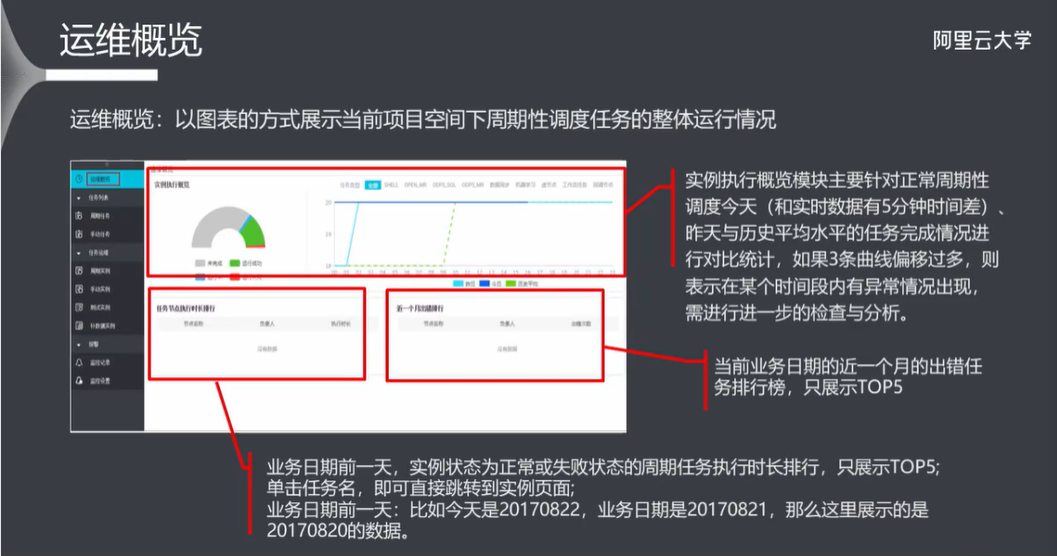
9.3 运维概览
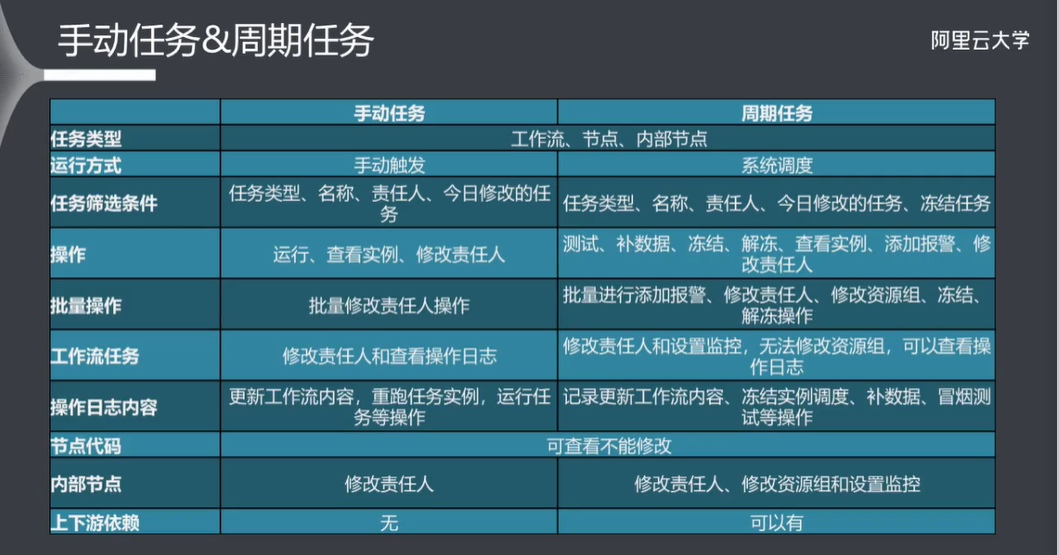
9.4 手动任务 & 周期任务

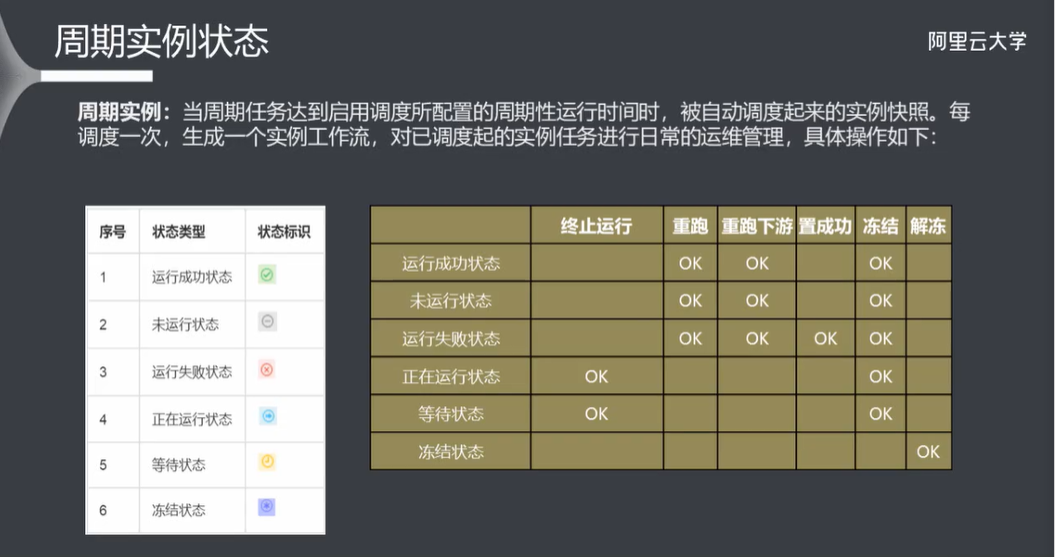
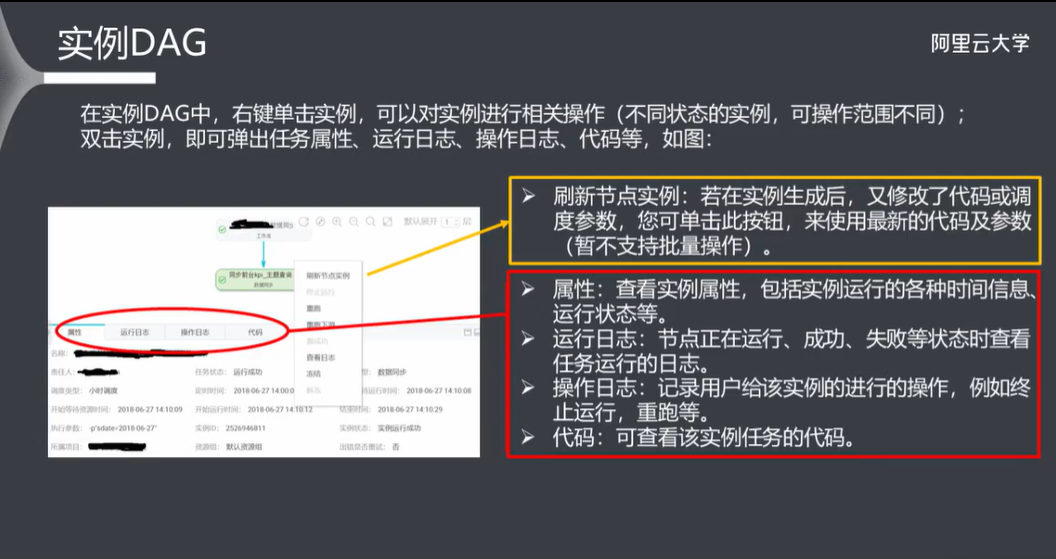
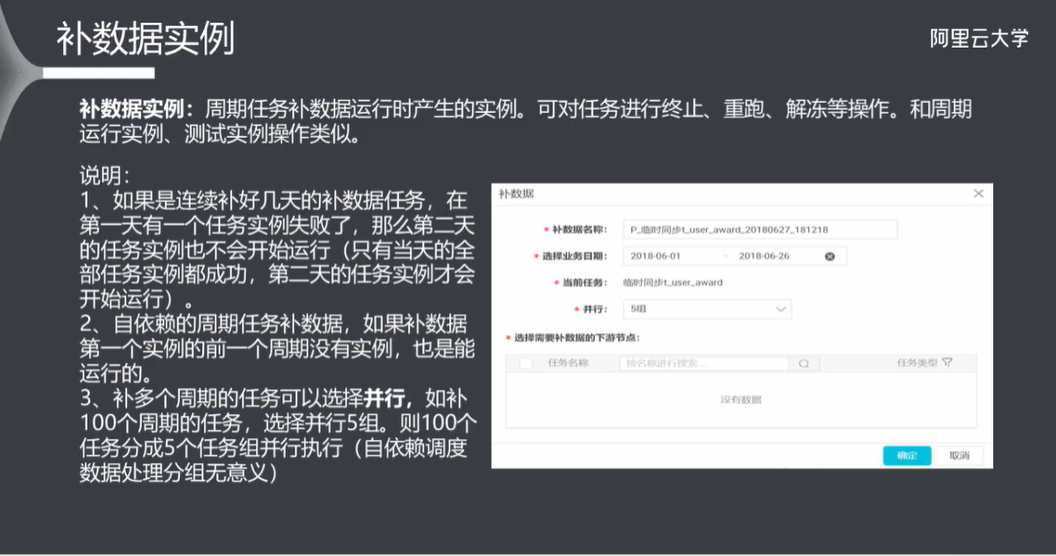
9.5 监控报警
十、DataWorks 项目管理
10.1 项目管理综述
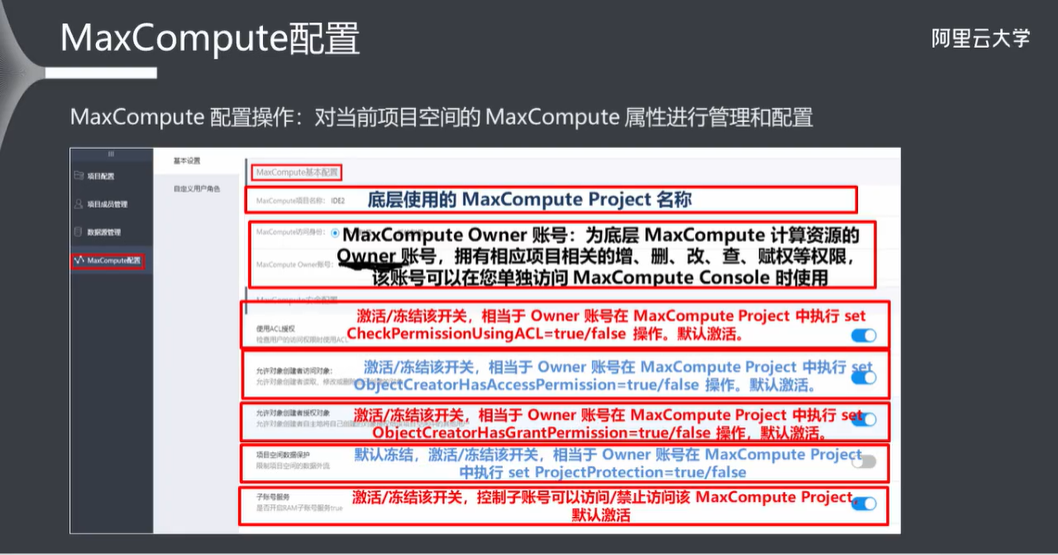
10.2 项目配置
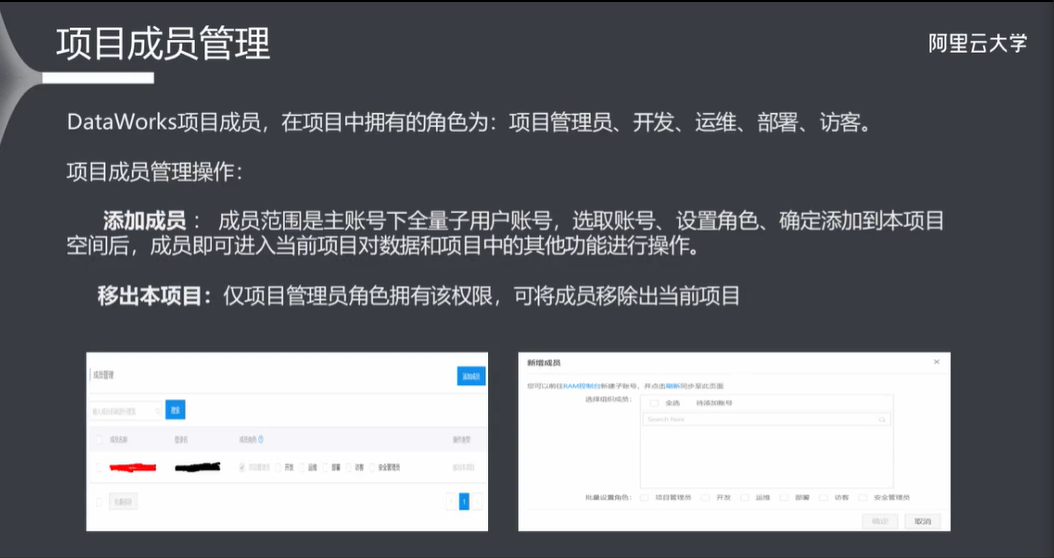
10.3 项目成员管理
10.4 调度资源管理
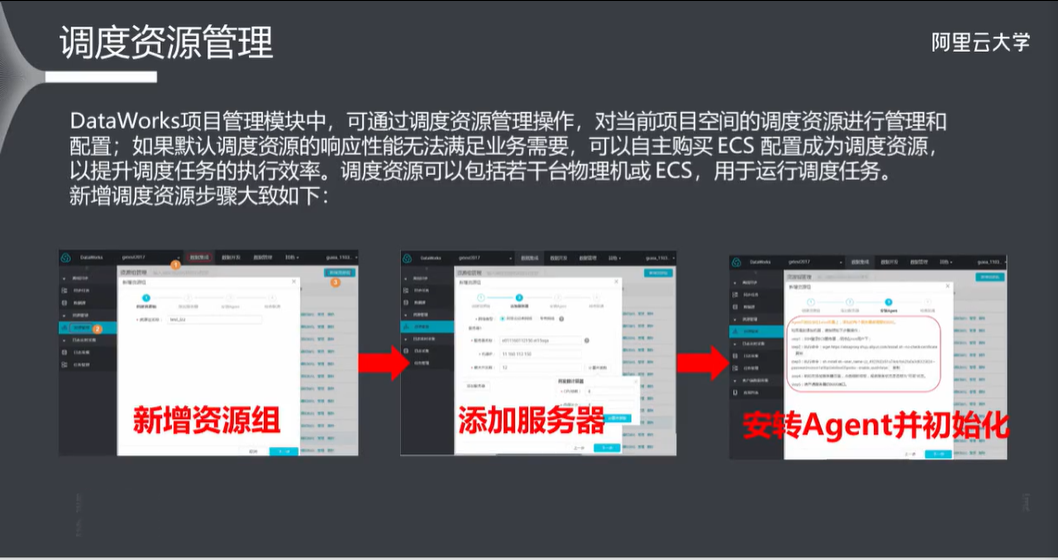
默认调度资源:默认调度资源为标志位,标记当前调度资源是否为默认调度资源。调度任务默认向该资源组提交惹任务,一个项目内有且只有一个默认调度资源。
最后
以上就是苗条招牌最近收集整理的关于阿里云大数据ACP(一)大数据开发平台 DataWorks的全部内容,更多相关阿里云大数据ACP(一)大数据开发平台内容请搜索靠谱客的其他文章。








发表评论 取消回复