**
大数据平台开发搭建**
Hadoop安装过程:
(1)在VMware中安装了CentOS,修改网络连接为仅主机模式:与主机共享的专用网络。
(2)启动Linux系统,进行Linux系统中的IP地址、网关、子网掩码。
(3)修改主机名,将主机名和IP地址进行绑定
(4)关闭防火墙
(5)配置SSH免密码登陆
(6)安装jdk
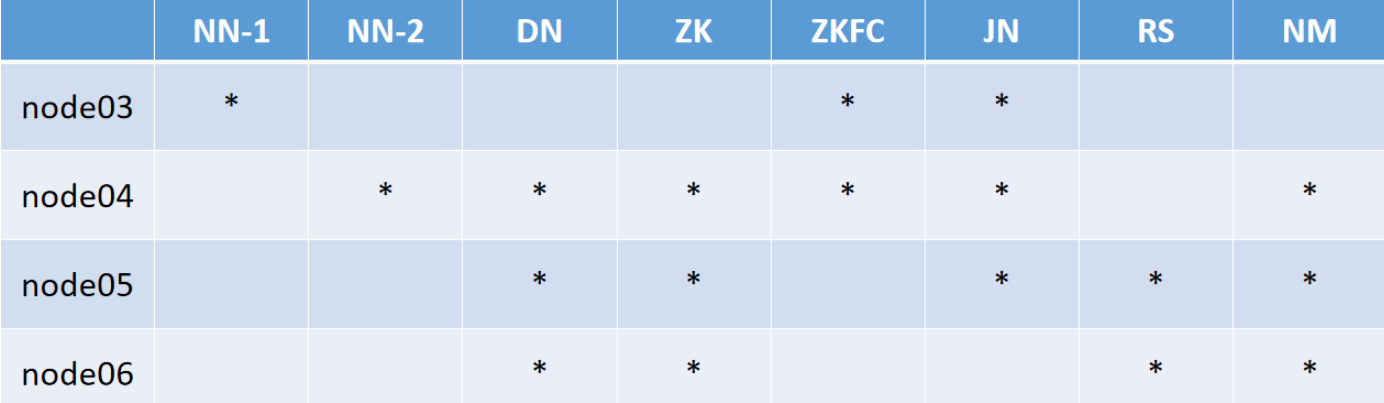
2.在xshell里面分发jdk
-scp jdk-7u67-linux-x64.rpm node02:pwd
-scp jdk-7u67-linux-x64.rpm node03:pwd
-scp jdk-7u67-linux-x64.rpm node04:pwd
并在Xshell的全部会话栏里一起ll,看jdk是否发送成功。
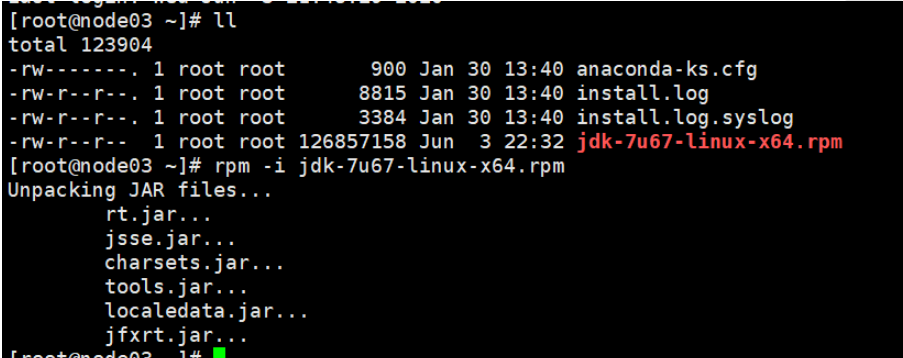
03、04上执行rpm安装命令
-rpm -i jdk-7u67-linux-x64.rpm
在node01上cd /etc,在此目录下把profile文件分发到node02、03、04上。
scp profile node02:pwd
利用Xshell全部会话栏,source /etc/profile
利用Xshell全部会话栏,jps,看02、03、04这三台机子的jdk是否装好。
2.同步时间
1.yum进行时间同步器的安装
-yum -y install ntp
2.执行同步命令
-ntpdate time1.aliyun.com 和阿里云服务器时间同步

3。-cat /etc/sysconfig/network
查看HOSTNAME是否正确
-cat /etc/hosts
查看IP映射是否正确
若不正确,可以改文件,也可以把node03上的用scp分发过去
-cat /etc/sysconfig/selinux里是否
SELINUX=disabled
service iptables status查看防火墙是否关闭

4.在xshell的全部对话框ssh localhot 一下
cd .ssh
将node01公钥发给其他三台机子
scp id_dsa.pub node02:pwd/node01.pub
scp id_dsa.pub node03:pwd/node01.pub
scp id_dsa.pub node04:pwd/node01.pub
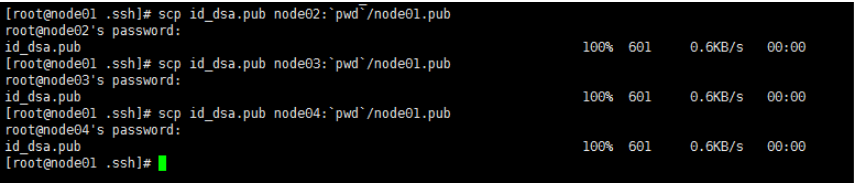
然后全部对话框内
cat node01.pub >> authorized_keys

5.免密钥
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys

ssh localhost验证一下
分发到node01上:scp id_dsa.pub node03:pwd/node04.pub
在node01的.ssh目录下,cat node04.pub >> authorized_keys,
在node02上ssh node01验证一下可否免密钥登录
hadoop文件配置
1.cd /opt/****/hadoop-2.6.5/etc/hadoop/
vi hdfs-site.xml
将内的内容改为
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1 node01:8020 dfs.namenode.rpc-address.mycluster.nn2 node02:8020 dfs.namenode.http-address.mycluster.nn1 node01:50070 dfs.namenode.http-address.mycluster.nn2 node02:50070 dfs.namenode.shared.edits.dir qjournal://node01:8485;node02:8485;node03:8485/mycluster dfs.journalnode.edits.dir /var/fyf /hadoop/ha/jn dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_dsa dfs.ha.automatic-failover.enabled true dfs.replication 3 删除线部分需自己改。
2.vi core-site.xml
同理改为
fs.defaultFS hdfs://node01:9000 hadoop.tmp.dir /var/fyf/hadoop/pseudo fs.defaultFS hdfs://mycluster ha.zookeeper.quorum node02:2181,node03:2181,node04:2181 ipc.client.connect.max.retries 100 Indicates the number of retries a client will make to establisha server connection. ipc.client.connect.retry.interval 10000 Indicates the number of milliseconds a client will wait for before retrying to establish a server connection.
3.vi slaves
删除里面的内容 加上
node02
node03
node04
4.安装hadoop
cd /opt/…
将文件夹分发给node02,3,4
scp –r …/ node02:pwd
scp –r …/ node03:pwd
scp –r …/ node04:pwd
也将hdfs-site.xml和core-site.xml分发到node02,3,4
-scp hdfs-site.xml core-site.xml node02:pwd
-scp hdfs-site.xml core-site.xml node03:pwd
-scp hdfs-site.xml core-site.xml node04:pwd
用xftp传zookeeper,安装zookeeper
(1.解压安装zookeeper
tar xf zookeeper-3.4.6.tar.gz -C /opt/…

(2.修改zookeeper的配置文件
cd /opt/…/zookeeper-3.4.6/conf
给zoo_sample.cfg改名
cp zoo_sample.cfg zoo.cfg

3.vi zoo.cfg
改dataDir=/var/…/zk
加
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
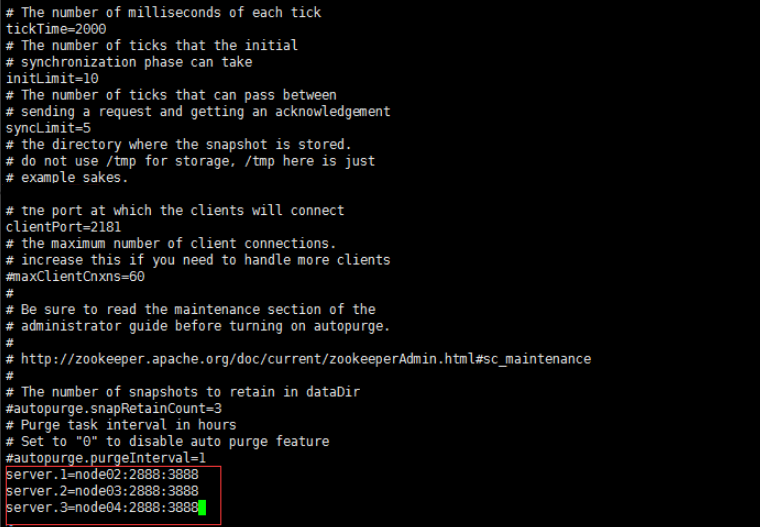
4.把zookeeper分发给node03,node04
scp -r zookeeper-3.4.6/ node03:pwd
scp -r zookeeper-3.4.6/ node04:pwd
5.给每台机子创建刚配置文件里的路径
mkdir -p /var/…/zk
对node02来说:
echo 1 > /var/…/zk/myid
cat /var/…/zk/myid
对node03来说:
echo 2 > /var/…/zk/myid
cat /var/…/zk/myid
对node04来说:
echo 3 > /var/…/zk/myid
6.在/etc/profile进行配置然后分发到node03,,04

scp /etc/profile node03:/etc
scp /etc/profile node04:/etc
7.启动zookeeper
全部会话内输zkServer.sh start(node01内没有zookeeper)
然后用zkServer.sh status查看zookeeper节点的状态
开启后有一个leader


1.启动journal使两台namenode同步数据
在node01,02,03上启动journalnode
hadoop-daemon.sh start journalnode
2.格式化任一namenode
随意挑一台namenode上执行hdfs namenode –format
另一台namenode不用执行,否则clusterID变了,找不到集群了。
然后,启动刚刚格式化的那台namenode。
hadoop-daemon.sh start namenode
3.然后,我们要同步另一台namenode
hdfs namenode -bootstrapStandby
4格式化zkfc
hdfs zkfc -formatZK
查看hadoop-ha是否打开,输入命令
zkChli.sh
ls /
在node02上执行zkCli.sh打开zookeeper客户端看hadoop-ha是否打开

启动hdfs集群
1.在node01上启动hdfs集群:start-dfs.sh
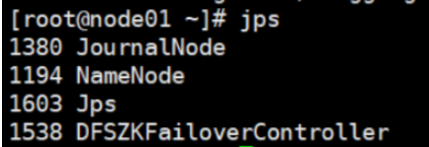
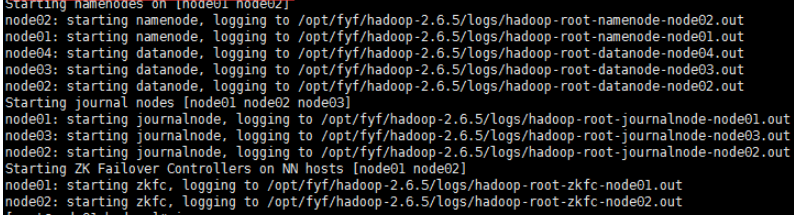 关闭集群命令:stop-dfs.sh
关闭集群命令:stop-dfs.sh
关闭zookeeper命令:zkServer.sh stop
配置文件
1.复制mapred-site.xml.template
cp mapred-site.xml.template mapred-site.xml
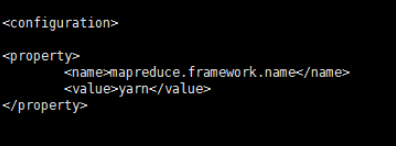
在mapred-site.xml里添加如下property
mapreduce.framework.name
yarn
2.在yarn-site.xml里添加如下property,里面有内容的不能删

5.hadoop高可用安装以及配置完成,退出时需关闭集群和虚拟机
启动集群
1.启动zookeeper,全部会话zkServer.sh start
2.在node01上启动hdfs,start-dfs.sh
3.在node01上启动yarn,start-yarn.sh
4.在node03、04上分别启动resourcemanager
yarn-daemon.sh start resourcemanager
5.全部会话jps,看进程全不全
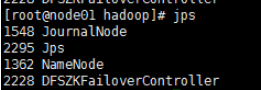
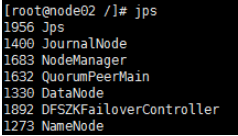
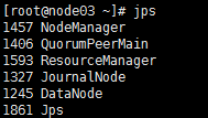
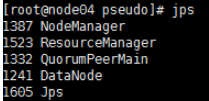
以上是启动后各个node 的jps
关闭集群
1.node01: stop-dfs.sh
2.node01: stop-yarn.sh (停止nodemanager)
3.node03,node04: yarn-daemon.sh stop resourcemanager
4.node02、03、04:zkServer.sh stop
最后
以上就是风中煎饼最近收集整理的关于大数据开发平台搭建的全部内容,更多相关大数据开发平台搭建内容请搜索靠谱客的其他文章。








发表评论 取消回复