注:本文只做简单科普,具体的内容后续会慢慢展开,本文提到的相关内容,各自的官网基本都有详细介绍。
大数据以及大数据技术发展历程
大数据
首先大数据平台是随着大数据的产生而产生的,那首先肯定要搞清楚什么是大数据,根据维基百科的描述,指的是传统数据处理应用软件不足以处理的大或复杂的数据集的术语。也就是数据量大到现有的技术已经处理不了,必须使用新的方法才能处理的数据。具体大到什么程度其实没有一个具体的,清晰的定义的,但是我们能想象的就是,这个数据量会一直增大,随着信息全球化发展以及通信技术的发展,例如5G的兴起和普及,工业以及日常生活数据量会一直膨胀。我们目前计算机描述数据量大小的一般是MB,GB,TB,PB等,后续随着硬件技术等发展可能会出现更大的存储,如何针对如此庞大的数据量进行计算,并且考虑效率和成本,就是我们要面对的大数据问题。
大数据技术
大数据面临的问题主要有三个,那就是存储,计算和服务,针对以上问题,Google推出了三篇划时代的数据论文,也就是我们常说的大数据三驾马车。2003年的Google File System、2004年的Google MapReduce、2006年的Google Bigtable。后面我们简称,GFS,MR,和BIGDATA。GFS通过上千个节点的分布式文件系统,解决了大数据的存储问题。MR通过map和reduce这两个函数,对海量数据做了一次抽象,通过分布式计算,让开发的人不需要再考虑底层分布式系统的开发了,这样也解决了大数据计算的问题。但是可以存储和计算了,用的时候如何去用,我们肯定要解决随机读和随机写的问题,随之诞生的就是bigtable,它是直接使用 GFS 作为底层存储,来做好集群的分片调度,以及利用 MemTable+SSTable 的底层存储格式,来解决大集群、机械硬盘下的高性能的随机读写问题。
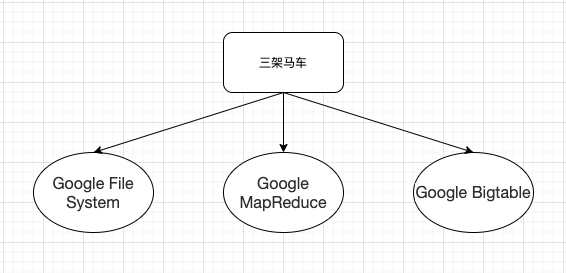
有了以上基础之后,后面演化基本都是随着使用过程中遇到的问题来进行的。
例如有了MR,但是要写代码才能实现,那使用门槛就会变高,随之就要解决易用性的问题,尤其是我们已经有了很多OLTP的数据库的情况下,SQL就是一个发展方向,Google 发表了 Sawzall,Yahoo 实现了 Pig,但是这两者都有不同程度的伪编程的模式,而且没有统一的标准,随着facebook在2009年发表的Hive的出现,慢慢Hive替代了以上,变成了行业标准。但是hive本质上还是一个或多个MR任务,延迟很高,无法给数据分析师使用,后面又诞生了Dremel,Spark等,从执行引擎和数据传输对MR做了升级。
再例如有了Bigtable,但是事务问题和schema的问题远没有解决,Google在2011年发布了Megastore的论文,就慢慢补充了schema和简单事务的问题,更接近于关系型数据库。为了解决异地多活和跨数据中心的问题,Google又发表了Spanner,能做到全局一致性。
上述已经基本解决了大数据量的问题,但是与此同时,随着业务的发展,数据的实时性要求更高。随之诞生了Storm,Kafka Streams等流式处理组件,完成了流批协同处理,2014 年,Kafka 的作者 Jay Krepson 提出了 Kappa 架构,这个可以被称之为第一代“流批一体”的大数据处理架构。2015年Google发表了Dataflow模型,对流式数据做了很好的总结和抽象,于是后面的Flink和Apache Beam,都沿用了Dataflow的模型理论,诞生了。
总结
此处引用了极客时间 徐文浩老师的一张图,比较完善清晰
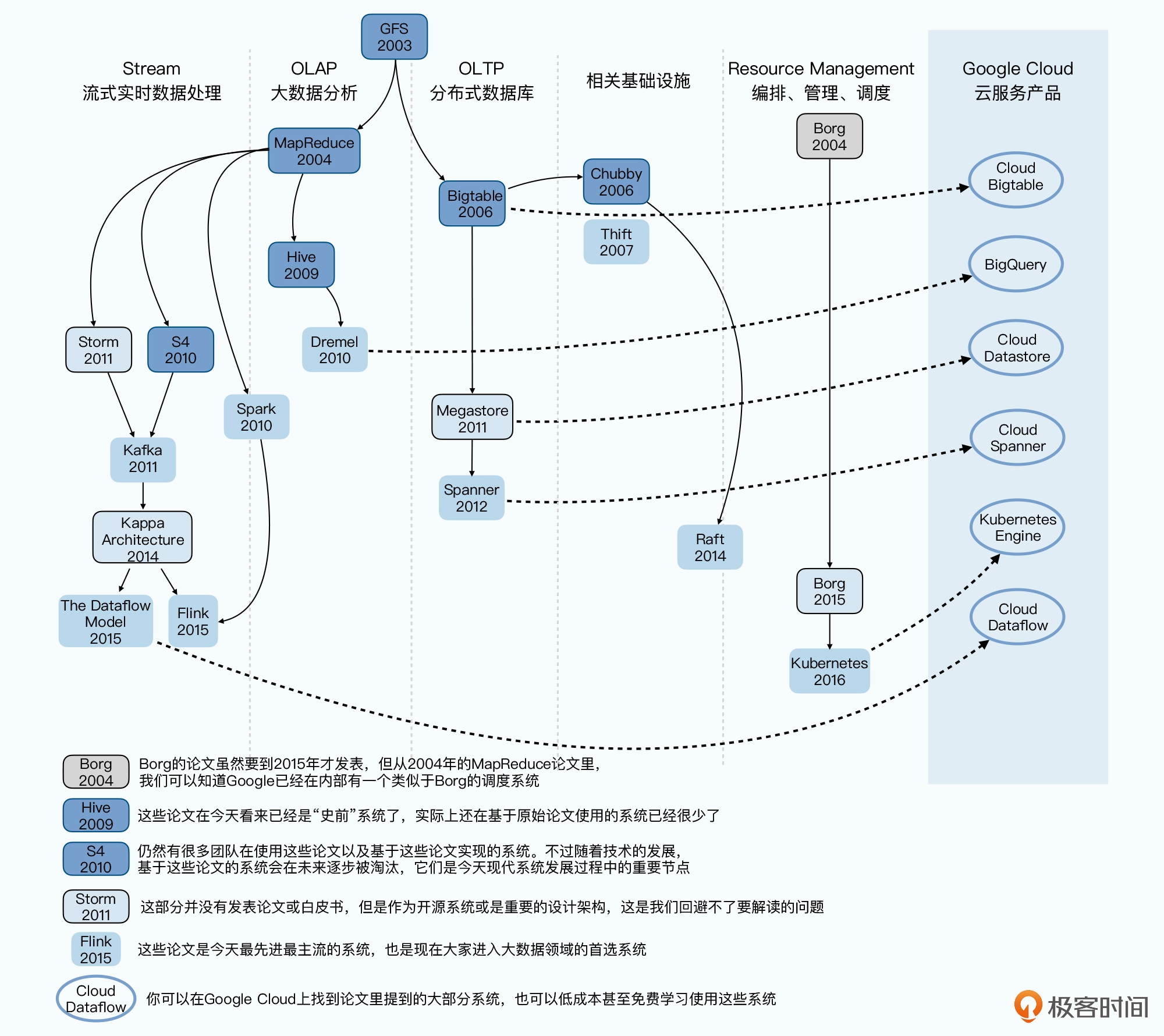
徐文浩老师极客时间大数据经典论文解读 https://time.geekbang.org/column/article/418480
https://time.geekbang.org/column/article/418480
目前存在的数据平台的产品
由于大数据技术的逐渐更新和完善,要做数据开发,分析等方面的工作,就需要自己去搭建相关组件去使用。为了降低门槛和资源统一,数据平台应运而生,几乎所有的公司都会搭建或者购买一套自己的数据平台。
基础设施
阿里云,目前规模最大的集群应该还是阿里云,可以管控上万台服务器,基本自己完全对标实现了hadoop的相关功能,拥有自己的sdk,客户端以及可视化界面。
腾讯云,腾讯云起步较晚,但是还是有很多使用方,和传统hadoop相比使用并无太大差别,认证拥有自己的tdbs,类似于更加完善的kerberus。
华为云, 阿里云之前,工信部备案的最大集群其实是5000台的华为云,基于hadoop的源码,自己修改了很动,做了定制化的内容,例如存算分离,机架感知自定义等。整体类似于传统的hadoop集群,但是基本都有专门的运维人员来操作,无法自己来做运维管理
浪潮云,浪潮云起步很早,主攻政务领域,整体技术深度和广度都很好,使用方面类似于hadoop,近几年也开始拥抱云原生技术
私有云,几乎中大型的公司都会搭建自己的云管平台,自己部署hadoop相关集群,保证数据的安全性和稳定性。
云原生,近几年兴起的最火的技术之一,通过虚拟技术可以完全替代传统集群,不专门区分机器,通过k8s完成对容器的编排和管理,使得资源管理更加精细。
数据平台
数据平台主要指的是数据的加工和管理平台,基于基础设施来构建。目前市面上最好的还是阿里云的dataworks,通过自定义的sql标准的方式,让开发变的更加高效,同时提供了的开发的sdk,利用客户端或者sdk直接提交的方式,完成对数据的处理和转换。类似的还有星环的产品,也是拥有自己的sql标准,基于底层的hadoop组件相关源码改造,从上层的入口到底层的计算引擎全部由自己管控。其他做的好的还有袋鼠云,神策,数澜,apache kylin,SAP等等。
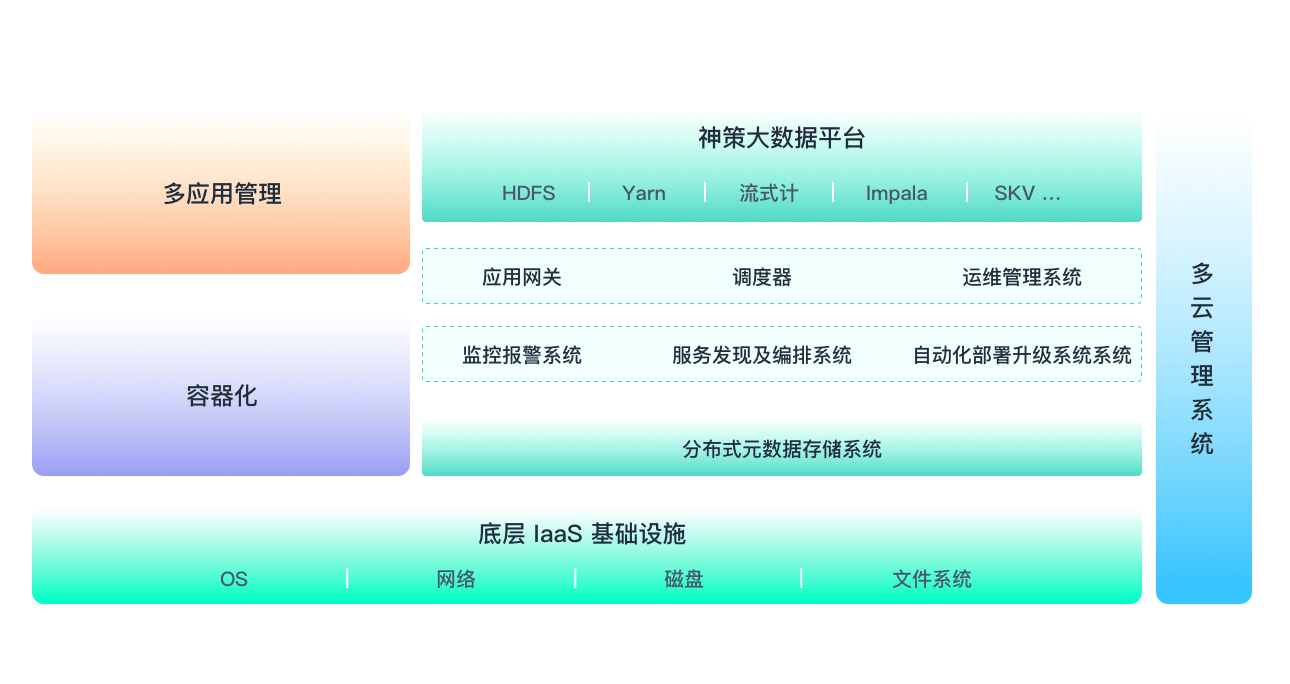
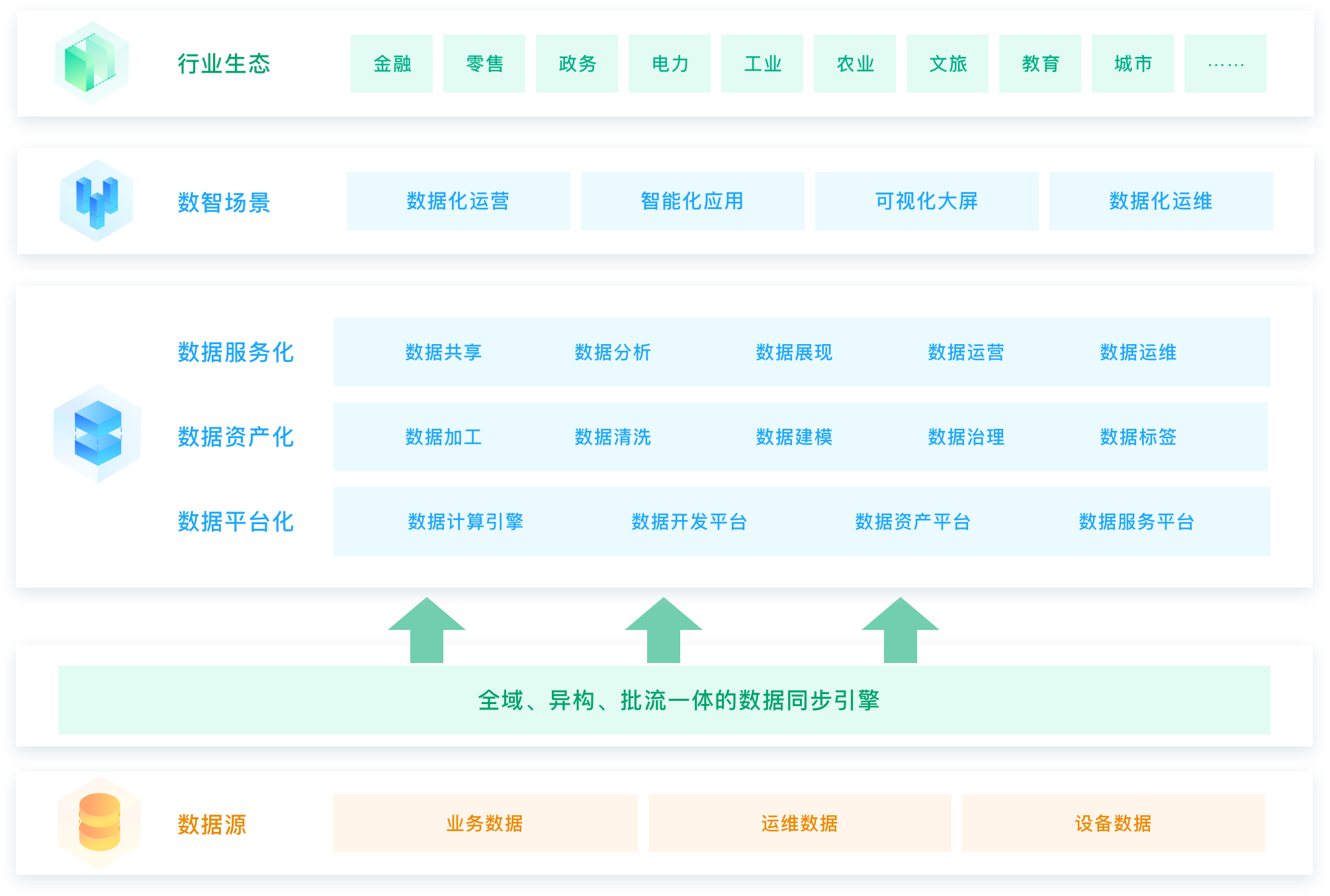
下面几张架构图基本来源于各自的官网,可以做相关对比。
神策
袋鼠云
kylin
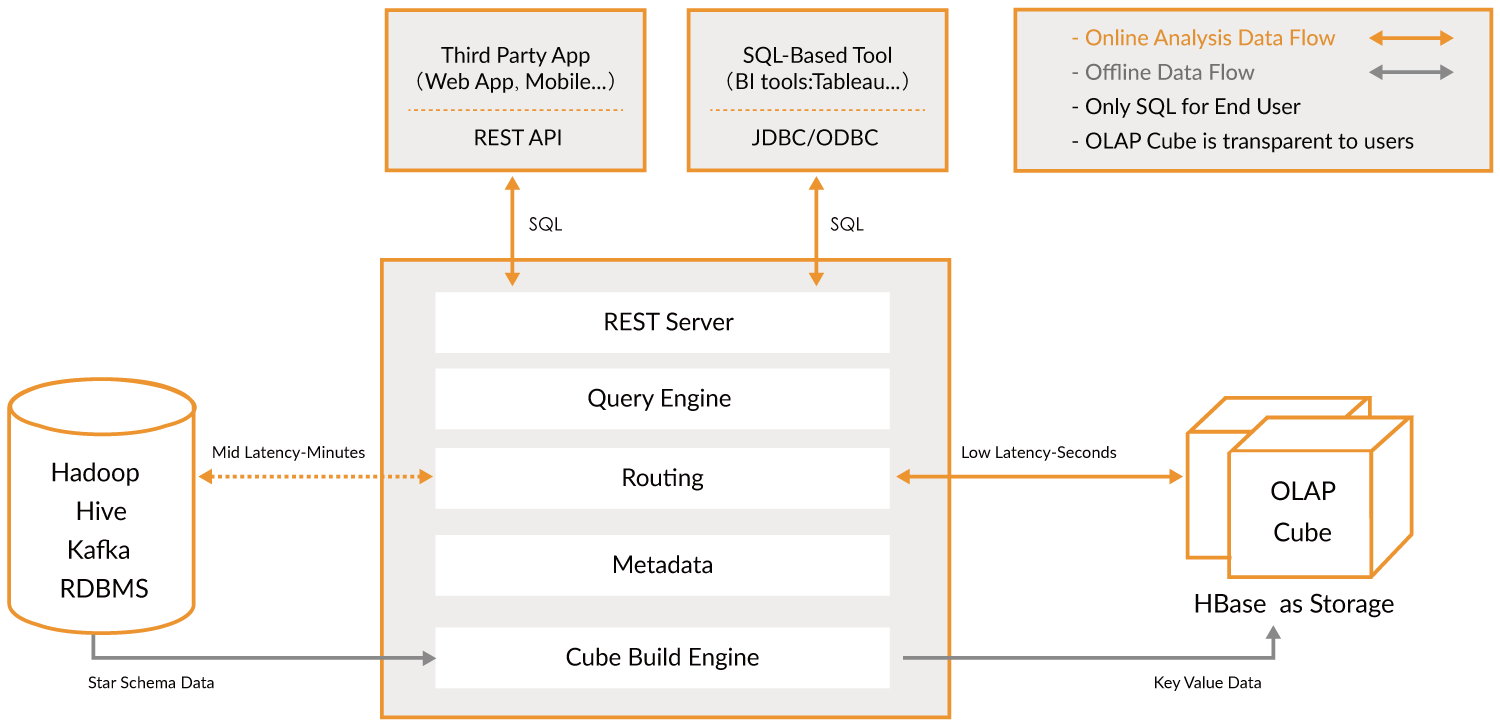
数据平台的技术架构
其实由上面的的数据平台的产品大体也可以看出所使用的技术,这里还是简单罗列一下。数据平台的基础功能大体抽象如下:
存储:目前大数据的存储有很多,国产的和国外的其实都很完善。例如常见的HDFS,HBASE,上层的mpp,例如GreenPlum,GuassDB,MPPDB,Vertica,DM等,S3协议的OSS,新兴的存储组件ALLUXIO,MINIO,flink中间结果缓存加速,icebug等。每个公司都可以根据自己的需求来进行技术选型。
计算:目前计算引擎方面,主流的还是spark和flink,都可以做离线计算和流计算,kafka也可以做流计算。
资源管理和任务调度:公司为了满足自己的定制化需求,基本都会开发自己的一套调度系统,但目前通用的大数据调度还是XXL-JOB,Azkaban,Elastic-Job,Apache Oozie,opencron,Uncode-Schedule,Antares等。资源管理对于cdh来说当然还是yarn,云原生k8s即可。
可视化:界面主要是为了提供可视化操作,更加直观的展现,帮助非专业人士更加快速上手使用。目前大部分采用的是微服务架构,后台基本采用springcloud一整套解决方案,或者自己构建springboot服务,采用dubbo或者nacos做注册中心。前段采用独立部署,采用的主流框架例如react,vue等等
拓展知识
什么是数仓
数据仓库介绍
推荐阅读阿里出品的《数据仓库》和《大数据之路》两本书
什么是数据湖
数据湖与数据中台有什么区别
什么是流批一体
如何搭建批流一体大数据分析架构
最后
以上就是兴奋战斗机最近收集整理的关于大数据平台的开发与思考一:的全部内容,更多相关大数据平台内容请搜索靠谱客的其他文章。








发表评论 取消回复