IVFuseNet: Fusion of infrared and visible light images for depth prediction
IVFuseNet: 融合红外和可见光图像以进行深度预测
核心点:
预测深度、进行融合
IVFuseNet------>为了融合互补信息并预测各种条件下的深度
Specifically, we construct common-feature-fusion subnetwork, full-feature-fusion subnetwork, and high-resolution reconstruction subnetwork, aiming to leverage the complementarity of these two kinds of images.
The common-feature-fusion subnetwork :公共特征融合子网络采用两流多层卷积结构,其每层的滤波器部分耦合,以分别融合从红外图像和可见光图像中提取的公共特征。
The full-feature-fusion subnetwork :全特征融合子网络通过自适应融合权重而不是前缀融合权重来融合从公共特征融合子网络生成的两流特征。
The high-resolution reconstruction subnetwork:高分辨率重构子网为了增强深度预测的细节重构采用了残余密集卷积(可以准确的将低分辨率特征映射到相应的高分辨率特征)
介绍
深度预测是无人驾驶研究领域的主要内容之一,研究从二维图像中恢复the depth information of scenery的方法。
The depth information can help understand the geometric relationship in the scene(场景) and judge the distance between the current vehicle and other objects, and further enhance the safety of unmanned driving.
红外图像和可见光图像传达有关深度预测的不同信息。预测弱光场景的深度,红外图像比可见光图像贡献更多。当我们预测充满纹理并在足够光照下的物体的深度时,结果是相反的。The above-mentioned fusion methods generally fuse infrared images and visible light images with an equal-weight or prefixed hand-crafted weights, 忽略了两种图像对预测不同场景中不同物体深度的不同贡献。
我们提出的方法联合了公共特征融合子网络、全特征融合子网络、高分辨率重构子网络。以及为了保持重要的特征,我们在公共特征融合子网络中提出了部分耦合滤波器,以在自适应加权融合之前进一步增强特征。在卷积中发现融合后的图像分辨率低,可以采用residual dense convolution(RDC)进行分辨率恢复。
• The partially coupled filters are designed in common-feature fusion subnetwork to extract features from infrared and visible light images and learn the transferable features between infrared images and visible light images. That is equivalent to retain the individual features of two types of input images while fusing common features in the process of subnetwork learning.
部分耦合滤波器是在common-feature-fusion子网中设计的,用于从红外和可见光图像中提取特征,并学习红外图像和可见光图像之间的可转移特征。这相当于保留了两种类型的输入图像的个体特征,同时融合了子网学习过程中的公共特征。
• The adaptive weighted fusion method considers the different contributions of infrared and visible light images in different scenes and the adaptive fusion coefficient matrix is trained by the full-feature-fusion subnetwork without the prefixed hand-crafted weights.
自适应加权融合方法考虑了红外和可见光图像在不同场景下的不同贡献,自适应融合 coefficient矩阵由全特征融合子网训练,不带前缀的手工权重。
• The residual dense convolution blocks which help recover finer details and improve the effect of feature fusion are applied in the high-resolution subnetwork for the task of depth prediction. The high-resolution subnetwork maps the low-resolution features to the corresponding high resolution features accurately for supervised learning.
在高分辨率子网中应用了有助于恢复更精细细节并提高特征融合效果的残余密集卷积块,用于深度预测任务。高分辨率子网将低分辨率特征精确地映射到相应的高分辨率特征,以进行监督学习。
相关工作
DenseFusion、FusionGAN
采用的也是手工的权重,但是,对于深度预测,在不同的光照条件下,两种图像的权重应该是可变的。
技术方法
宏观框架:Fig1
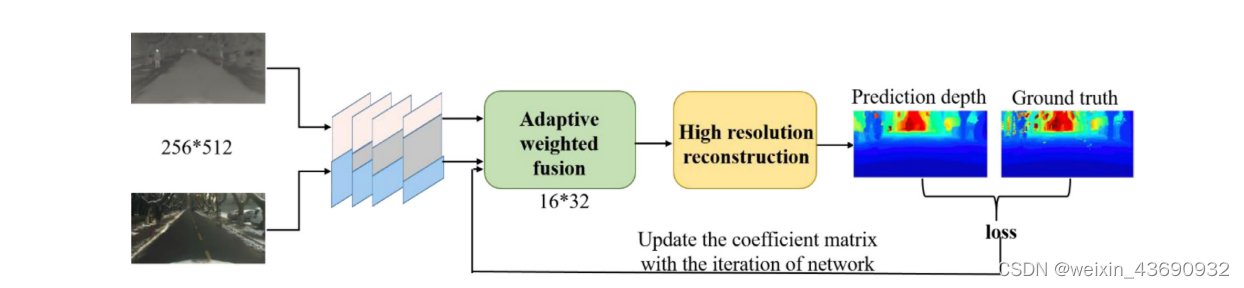
IVFuseNet图:粉色块代表红外图像流,蓝色块代表可见图像流,灰色块旨在从红外和可见光图像中提取融合的特征。
细节描述:Fig2
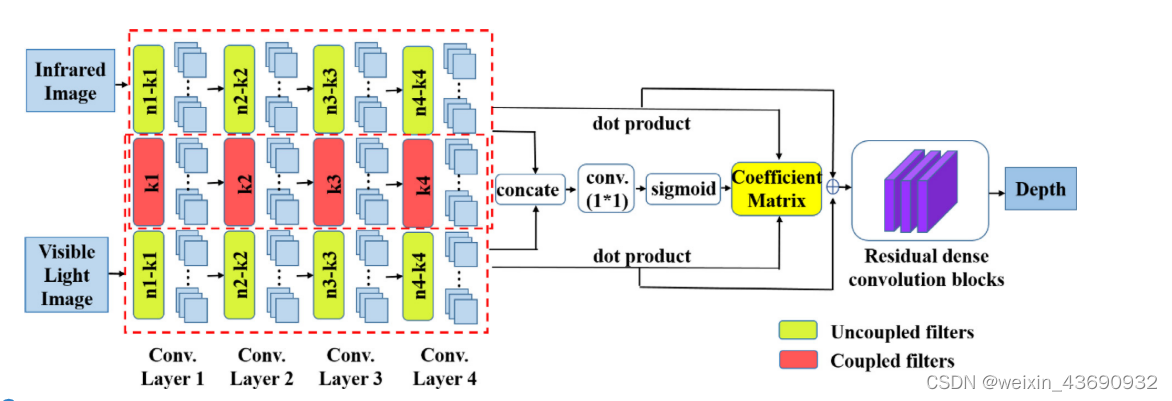
IVFuseNet图:顶部红色虚线帧呈现红外图像流,底部红色虚线帧呈现可见光图像流,重叠是两种图像的耦合滤波器。然后通过自适应加权融合方法融合红外和可见光图像的特征。最后,应用残余密集卷积来增强特征并重建高分辨率特征。(dot product是点积)
在整个IVFuseNet中:
在公共特征融合子网络中设计了部分耦合滤波器,以提取浅层特征并融合两种不同图像的公共特征。
在全特征融合子网络中,我们提出了一种自适应加权融合策略,以融合公共特征融合子网络提取的全特征。
我们设计了高分辨率重建子网,利用residual dense convolution以增强特征细节并预测高分辨率深度图。
Common-Feature-Fusion subnetwork
我们认为每一对V-I上的点都对应相同的位置,wang等人提出可以使用耦合滤波器将某些类似的功能从源域转移到目标域。但是,即使经过高度复杂的操作,也并非红外和可见光图像的所有特征都可以表示并相互传输。在本文中,可以相互转移的特征称为 “共同特征”,而不能相互转移的特征称为 “单独特征”。基于以上分析,我们设计了公共特征融合子网,以融合公共特征。
图2中的红色虚线帧说明了我们共同特征融合子网的详细机制。我们采用双流结构。对于每个流,我们使用AlexNet [444] 作为我们的基线,因为AlexNet的参数数量相对较少。
与传统的两流CNN不同,我们在每个卷积层中设计了部分耦合滤波器,以学习红外和可见光图像之间的可转移特征。
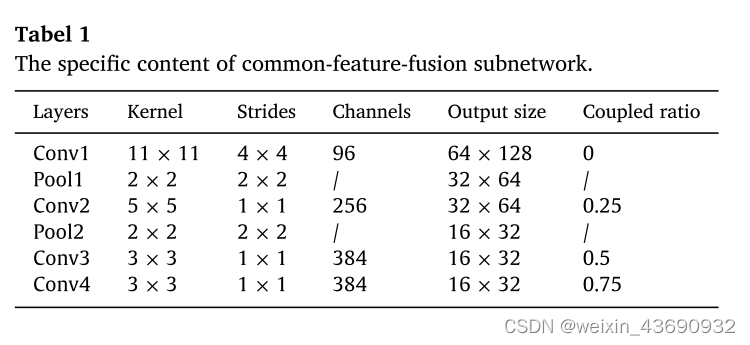
Fig3:用于VI的内核和用于IR的内核是解耦滤波器,用于提取单个特征; 内核耦合是部分耦合滤波器,用于提取用于特征融合的公共特征。
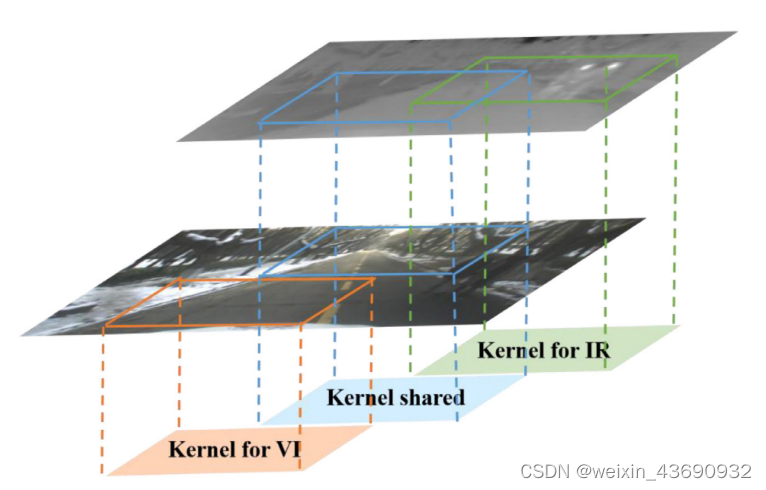
公共特征融合子网络的滤波器可以分为三类: 红外图像的滤波器,可见光图像的滤波器以及红外和可见光图像的部分耦合滤波器。部分耦合滤波器旨在提取红外和可见光图像的特征。作为可见光图像的 “辅助变量”,红外图像可以帮助发现在弱光条件下未从可见光图像中捕获的更多判别特征。同样,作为红外图像的 “辅助变量”,可见光图像可以通过部分耦合滤波器帮助从红外图像中提取更多细节信息 (纹理和边缘等)。未耦合的滤波器学习红外图像和可见光图像的各个特征,部分耦合滤波器的数量与总滤波器的数量之比称为耦合比。
???? ???? = ???? ???? ∕ ???? ???? ( ???? = 1 , 2 , 3,4)
R i是第i层的耦合比,k i是第i卷积层的部分耦合滤波器的数量,n i是第i卷积层的全滤波器的数量。。在本文中,我们使用以下耦合比: 0、0.25、0.5、0.75。可以注意到,随着卷积层的增加,耦合比变大。分析表明,浅层卷积层提取的纹理和细节特征在红外图像和可见光图像之间存在很大差异。而较深的卷积层则提取结构和形状特征,这些特征共享红外图像和可见光图像的公共信息。在公共特征融合网络中,我们通过反向传播 (BP) 方法更新滤波器权重。可以发现,对于红外图像流和可见光图像流,在每次训练迭代中,耦合滤波器的权重被更新两次,并且在每次迭代中,未耦合滤波器的权重被更新一次。(Fig2)
综上所述,在公共特征融合子网络中设计了部分耦合滤波器,用于学习红外和可见光图像的公共特征的非线性变换,相当于增强了两种图像的特征并融合了公共特征。从红外图像和可见光图像中提取的特征分为共同特征和个体特征。为了利用公共特征和单个特征进行进一步的深度预测,我们提出了全特征融合子网络来融合两流结构的所有特征。
Full-Feature-Fusion subnetwork(Fig2)
(全特征融合子网络决定了我们可以分别依靠红外特征和可见光特征来预测深度的程度)
在部分耦合滤波器提取公共特征之后,我们需要融合公共特征和单个特征以进行深度预测。由于提取的特征具有不同的特征,因此设计一种自适应的特征融合策略至关重要。
令f ir ∈ R b × w × h × c和f vi ∈ R b × w × h × c表示由公共特征融合子网络提取的红外图像和可见光图像的特征。首先,我们在第三维处连接f ir和f vi,这等效于红外图像和可见光图像的融合特征f融合 ∈ R b × w × h × 2 c。其次,我们将融合特征与内核k ∈ R 2c × c× 1 × 1进行卷积,其中2c是输入通道数,c是输出通道数,内核大小为1 × 1。由于融合特征f融合同时考虑了红外和可见光图像的特征,这种卷积操作的输出与两种特征都有关,因此,此过程学习两种特征的相关性。得到f ir或f vi维数相同的初始系数(coefficient)矩阵M后,我们计算它们的点积,表示它们对不同场景深度预测的不同贡献。最后,我们设计一个sigmod层,将M的每个元素转换为0到1之间的概率形式,然后就得到到了最终的系数矩阵。
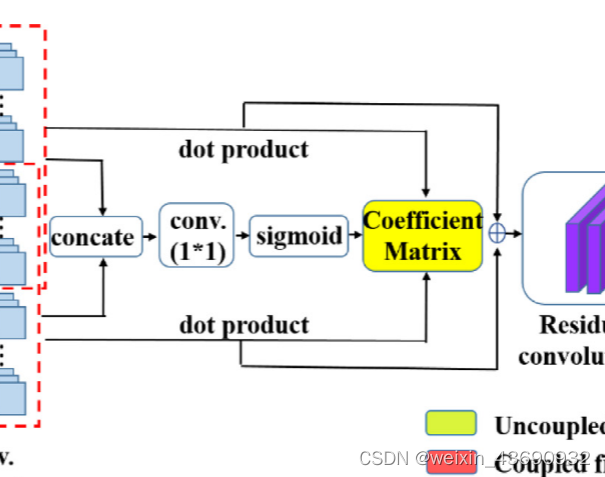
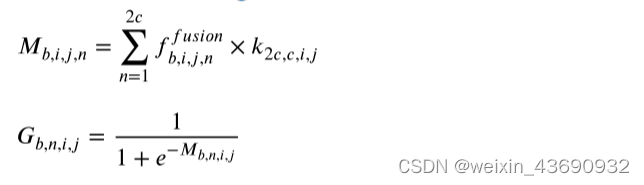
其中b表示批量大小,n表示输出通道的数量。我们让红外图像的系数有效矩阵 ???? ????= ????,可见光图像的系数有效矩阵 ???? ????= 1 − ????,其中G ir和G vi分别表示红外图像和可见光图像对预测深度的贡献水平。系数矩阵在不同条件下是不同的(eg:光线不好的情况下红外贡献水平变大)
High-resolution reconstruction subnetwork
通过利用公共特征融合子网络和全特征融合子网络,我们获得了具有地面真相深度图16分之1分辨率的融合特征。为了预测深度图,我们需要将低分辨率深度图映射到与地面真相深度图具有相同分辨率的相应高分辨率深度图。如果使用传统的反卷积进行深度预测,则会出现Checkboard artifacts,并且详细信息可能会丢失。受 启发,我们设计了基于残余密集卷积块的高分辨率重构子网。
Fig4:
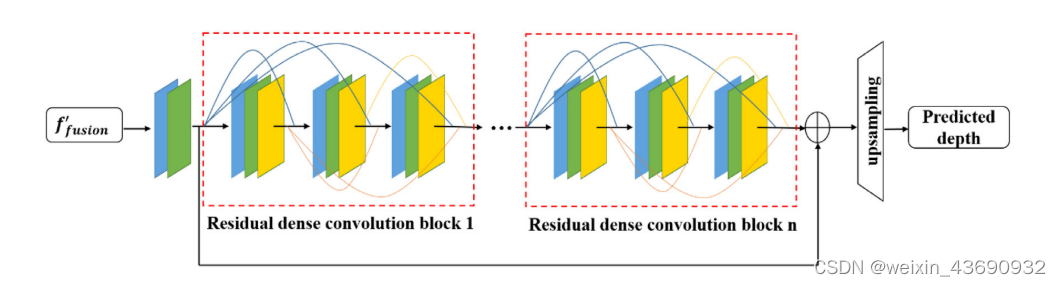
每个红色虚线框表示一个residual密集卷积块。蓝色正方形表示卷积,绿色正方形表示批量归一化,黄色正方形表示激活函数。
让 ???? ′ ????????????????????n作为低分辨率融合特征获得全特征融合子网。首先,我们使用卷积层从红外和可见光图像的低分辨率融合特征中学习信息。
???? 0 = ???? ( ???? ???????????? )
其中g( ·) 表示3 × 3卷积和批归一化 (BN) 的复合函数。然后将F 0用作剩余密集卷积块的输入。在剩余密集卷积块中,每一层的输出直接连接到当前剩余密集卷积块的所有后续层。它还允许从前面的残余密集卷积块的输出到当前残余密集卷积块的每一层的连接。

其中,n表示第n个剩余密集卷积块,i表示当前剩余密集卷积块的第i层。如果每个剩余密集卷积块的输出具有N个特征,并且每个块的每一层都具有N个特征,则我们将当前块的前一层和前一层产生的特征串联起来,导致 ???? 0 ( ???? − 1) 个特征映射作为第i层的输入。在本文中,我们设置 ???? 0 = ???? = 32,每个块具有卷积,批归一化和校正线性单元的三个复合运算。
与传统的cnn相比,剩余密集卷积块可以利用原始低分辨率特征的层次特征来增强细节特征。获得串联特征图后,我们采用1 × 1卷积运算自适应地学习所有层的特征,并使通道数与F 0相同以进行残差学习。通过三个剩余密集卷积块,我们可以使层之间的信息最大化,并获得具有更详细信息的特征图。然后使用残差学习,我们将F 0和最后一个块的输出相加,以进一步增强我们网络的预测能力。最后,我们设计了一个上采样层而不是反卷积,该层的输出大小为256 × 512是我们预测的深度图。
最后
以上就是烂漫日记本最近收集整理的关于深度预测:VIIF:无人驾驶数据集的全部内容,更多相关深度预测内容请搜索靠谱客的其他文章。








发表评论 取消回复