相机视觉
人类在驾驶过程中所接收的信息大多来自视觉,例如交通标志、道路标志、交通信号等,这些视觉信息成为人类驾驶员控制车辆的主要决策依据。在智能驾驶中,相机取代人类视觉系统作为交通环境感知的传感器之一。相较于其他传感器,视觉传感器安装使用的方法简单、获取的图像信息量大、投入成本低、作用范围广,并且近些年更是得益于数字图像处理技术的快速发展和计算机硬件性能的提高。但是在复杂交通环境下,视觉传感器依然存在目标检测困难、图像计算量大、算法难以实现的问题,视觉感知技术在应对道路结构复杂、人车混杂的交通环境时也还存在很多不足。
视觉传感器
智能驾驶中配置的视觉传感器主要是工业相机,与民用相机相比具有更大优势,例如较高的图像稳定性、传输能力和抗干扰能力。
按照输出的数据信号,工业相机可分为模拟式和数字式两种。模拟相机的输出为模拟电信号,需要借助视频采集卡等组件完成数字信号转换,该类相机连线简单、成本较低,但是转换速率慢;数字相机所采集的图像直接通过内部感光组件及控制组件转换为数字信号,该类相机采集速率快、数据存储方便,但是价格相对昂贵。
按照芯片类型,可分为CCD(Charge-Coupled Device,电荷耦合元件)相机和 CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体)相机。CCD 相机由光学镜头、时序及同步信号 发生器、垂直驱动器及模拟/数字信号处理电路组成,具有无灼伤、无滞后、低电压、低功耗等优势;CMOS 相机集光敏元阵列、图像信号放大器、信号读取电路、模数转换电路、图像信号处理器及控制器于 一体,传输速率高、动态范围宽、局部像素可编程随机访问。
除了以上两种常见的分类方法,工业相机还可以按照传感器的结构特性分为线阵相机和面阵相机;按照输出图像的色彩分为黑白相机和彩色相机;按照响应频率范围分为普通相机、红外相机和紫外相机; 按照扫描方式分为逐行扫描相机和隔行扫描相机等;按照接口类型分为网络相机、1394 相机和 USB 相机。

视觉感知技术
- 相机
图像传感器—相机能够获取环境彩色景象信息,是无人车获取环境信息的第二大来源。相机可选择的型号和种类非常多样,可简单分为单目相机、双目立体相机和全景相机三种。
1.单目视觉技术
- 即通过单个相机完成环境感知任务,具有结构简单、算法成熟并且计算量较小的优 点,但是感知范围有限、无法获取场景目标的深度信息。
无人车的环境成像是机器视觉在车辆上的应用,需要满足车辆行驶环境及自身行驶状况的要求。天气变化、车辆运动速度、车辆运动轨迹、随机扰动、相机安装位置等都会影响车载视觉。无人车任务中对图像质量要求高,不仅在图像输出速度上需要较高帧频,且在图像质量上也具有较高要求。单目相机是只使用一套光学系统及固体成像器件的连续输出图像的相机。通常对无人车任务的单目相机要求能够对其实现实时调节光积分时间、自动白平衡,甚至能够完成开窗口输出图像功能。另外,对相机光学系统的视场大小、景深尺度、像差抑制都有一定要求。
值得一提的是以色列 Mobileye 公司的单目智能相机产品 ,它将图像处理及运算部件也集成在同一相机产品之内,完成诸如前向碰撞、行人探测、车道线偏离等检测功能,其性能在同类产品中具有一定优势。
2.立体视觉技术
- 基本原理是采用 2 个(或多个)相机从不同视点观察同一目 标,并通过计算图像像素间位置偏差恢复三维场景,难点在于寻找多 个相机图像中匹配的对应点。
双目相机能够对视场范围内目标进行立体成像,其设计是建立在对人类视觉系统研究的基础上,通过双目立体图像处理,而获取场景的三维信息 。其结果表现为深度图,再经过一步处理就可以得到三维空间中的景物,实现二维图像到三维图像的重构。但是在无人车任务应用中,双目相机的两套成像系统未必能够完美对目标进行成像和特征提取,也就是说,所需目标三维信息往往不能十分可靠地获取。
3.全景视觉技术
- 成像视野较宽,但图像畸变较大、分辨率较低。
以加拿大 Point Grey 公司的 Lady bug 相机为代表的多相机拼接成像的全景相机被用于地图街景成像的图像传感器,它是由完全相同 6 个相机对上方和 360 度全周进行同时成像,然后再进行 6 幅图像矫正和拼接,以获得同时成像的全景图像。使用该全景相机的无人车可以同时获得车辆周围环境的全景图像,并进行处理和目标识别。
另外,使用鱼眼镜头的单目相机也能呈现全景图像 ,虽然原始图像的畸变较大,但其计算任务量相对多相机拼接方式较小,且价格低廉,也开始受到无人车领域的重视。
•应用
单目视觉技术多用于智能车辆的车道级定位、识别道路几何结构、 检测周边的车辆或行人等障碍物、识别交通灯和交通标志等,主要包括车道检测与跟踪技术、障碍物检测与跟踪技术、交通灯及交通标志 识别技术、基于视觉的 SLAM 技术和视觉里程计技术等。
立体视觉技术常用于相机标定、图像匹配和障碍物检测。相机标定的方法包括传统标定法、主动视觉标定法和自标定法,三种标定方法在鲁棒性、计算精度和算法复杂程度上各有优劣;图像匹配有区域匹配法、特征匹配法和相位匹配法,在对图像的量化程度上有所差异; 障碍物检测的方法有逆投影变换法和 V 视差图法,前者对相机参数 较为敏感,后者对视差图要求较高。
相机的标定
相机与车体也为刚性连接,两者相对姿态和位置固定不变,相机的标定是为了找到相机所生成的图像像素坐标系中的点坐标与相机环境坐标系中的物点坐标之间的转换关系。从而实现把相机采集到的环境数据与车辆行驶环境中的真实物体对应。
单目相机的标定主要包括对相机模型的建立和对物点坐标的转换 。通过下式可以得到相机环境坐标系中的物点 P(x_yc,y_vc,z_vc) 到图像像素坐标系中的像点 P_i(u,v) 的转化关系。
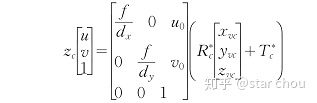
式中,f 为透镜的焦距,dx 与 dy 分别为相机传感器 x 与 y 方向的像素单元距离由厂家提供,R_c* 为 3*3 的坐标旋转矩阵,T_c* 为 1*3 的坐标平移矩阵,u_0 与 v_0 为图像像素中心坐标,z_c 为相机坐标系下 P 点的 z_c 轴上的值。忽略实际情况中畸变的误差。双目立体相机标定主要包括双目立体视觉模型建立、双目图像去畸变处理、双目图像校正、双目图像裁切等四个步骤。
全景视觉技术一般分为四类:单相机 360°旋转式成像、鱼眼镜 头相机成像、多相机拼接成像和折反射全景成像。其中,单相机 360° 旋转式成像对系统可靠性要求较高,鱼眼镜头相机成像需要标定和畸 变校正,这两种技术获取的图像视角较宽;多相机拼接成像可实现全 景实时拼接,但标定复杂、成本较高;折反射全景成像具有自动化、 小型化和集成化的特点,成像特性取决于反射镜面的形状。
近年来,深度学习在计算机视觉和图像处理领 域的应用取得了巨大成功,基于深度学习的图像处理成为智能驾驶视觉感知的重要支撑。深度学习的输入可以为原始的图像像素,通过构建含有多隐层的机器学习模型模拟人脑的多层结构。经逐层抽取得到的信息特征,相比传统图像处理算法构造的特征更具表征力和推广性, 大大地提高了目标检测和识别的准确性。在智能驾驶视觉感知中,深度学习多用于对车辆、行人、交通标志等交通要素的检测和识别。由于深度学习需要大数量、多样性的数据集,而且对计算平台的性能要求高,目前大多仅应用于离线数据的处理。
- 测试评价
在智能驾驶中,相机视觉必须具备准确性、实时性和鲁棒性三方面的技术特点。准确性是指图像处理过程中应该能够有效提取与驾驶活动相关的交通要素;实时性是指视觉感知系统的数据处理必须与智能车辆的高速行驶同步;鲁棒性是指视觉感知算法对于经常变化的天气条件和道路环境需要具有良好的适应性。视觉传感器的配置参数和视觉感知技术的算法优劣共同决定了视觉感知系统的性能。
最后
以上就是坦率河马最近收集整理的关于单目相机 svd 从图像恢复3维位置_无人驾驶环境感知之相机的全部内容,更多相关单目相机内容请搜索靠谱客的其他文章。








发表评论 取消回复