交叉验证(Cross Validation)是常用的一种用来评估模型效果的方法。
当样本分布发生变化时,交叉验证无法准确评估模型在测试集上的效果,这导致模型在测试集上的效果远低于训练集。
通过本文,你将通过一个kaggle的比赛实例了解到,样本分布变化如何影响建模,如何通过对抗验证辨别样本的分布变化,以及有哪些应对方法。
本篇文章完整代码: https://github.com/Qiuyan918/Adversarial_Validation_Case_Study/blob/master/Adversarial_Validation.ipynb
1 什么是「样本分布变化」?
在真实的业务场景中,我们经常会遇到「样本分布变化」的问题。
主要体现在训练集和测试集的分布存在的差异。比如,在化妆品或者医美市场,男性的比例越来越多。基于过去的数据构建的模型,渐渐不适用于现在。
2 为什么「样本分布变化」的时候,交叉验证不适用?
当我们要做一个模型,来预测人们在超市的消费习惯。
我们的训练样本主要是18岁至25岁的年轻人构成,而测试样本主要是70岁以上的老人组成。这时样本分布就发生了变化。

这种情况下,使用交叉验证,无法准确评估模型的效果。原因是,交叉验证的验证集和测试集不够相似。
交叉验证中,每一折的验证集都是从训练集随机抽取的。随机抽取的验证集的分布和整体的训练集是相同的,也就意味着每一折的验证集都和测试集的分布存在较大的差异。
所以在样本分布变化时,通过交叉验证的方式构建的模型,在测试集上的表现,相较于训练集,通常会打折扣。稍后我们会通过一个实例来确认这一点。
3 什么是对抗验证(Adversarial Validation)?
对抗验证(Adversarial Validation),并不是一种评估模型效果的方法,而是一种用来确认训练集和测试集的分布是否变化的方法。
它的本质是构造一个分类模型,来预测样本是训练集或测试集的概率。
如果这个模型的效果不错(通常来说AUC在0.7以上),那么可以说明我们的训练集和测试集存在较大的差异。
仍然以「预测人们在超市的消费习惯」为例。因为训练集主要是18岁-25岁的年轻人,测试集主要是70岁以上的老人,那么通过「年龄」,我们就能够很好的区分出训练集和测试集。
图2 分类器通过「年龄」可以轻松区分训练集和测试集
具体步骤:
- 定义y:样本是train还是test。
- 将 Train 和 Test 合成一个数据集
- 构造一个模型,拟合新定义的y
- 观察模型效果:如果模型的AUC超过0.7,说明了 Train 和 Test 的分布存在较大的差异
# 定义新的Y
df_train['Is_Test'] = 0
df_test['Is_Test'] = 1
# 将 Train 和 Test 合成一个数据集。
df_adv = pd.concat([df_train, df_test])4 分布变化时,有哪些优于交叉验证的方法?
4.1 人工划分验证集
人工划分验证集,需要我们对数据有充分的了解。
因为这次比赛的数据是根据时间划分的,所以我的验证集同样可以根据时间划分。
如果我们不清楚训练集和测试集如何划分,可以采用后面两种方法。
# 将样本根据时间排序
df_train = df_train.sort_values('Date').reset_index(drop=True)
df_train.drop(['Date'], axis=1, inplace=True)
# 前80%的样本作为训练集,后20%的样本作为验证集
df_validation_1 = df_train.iloc[int(0.8 * len(df_train)):, ]
df_train_1 = df_train.iloc[:int(0.8 * len(df_train)), ]4.2 和测试集最相似的样本作为验证集
如果对数据没有充分了解,如何找到训练集中,和测试集分布最相似的样本呢?
这就会用到我们做对抗验证时,模型预测样本是测试集的概率。概率越高,则说明和测试集越相似。
# 通过抗验证中的模型,得到各个样本属于测试集的概率
model_adv.fit(df_adv.drop('Is_Test', axis=1), df_adv.loc[:, 'Is_Test'])
preds_adv = model_adv.predict_proba(df_adv.drop('Is_Test', axis=1))[:, 1]
# 只需要训练样本的概率
df_train_copy = df_train.copy()
df_train_copy['is_test_prob'] = preds_adv[:len(df_train)]
# 根据概率排序
df_train_copy = df_train_copy.sort_values('is_test_prob').reset_index(drop=True)
# 将概率最大的20%作为验证集
df_validation_2 = df_train_copy.iloc[int(0.8 * len(df_train)):, ]
df_train_2 = df_train_copy.iloc[:int(0.8 * len(df_train)), ]4.3 有权重的交叉验证
不仅可以用对抗验证中,样本是测试集的概率来划分验证集,也可以将这个概率作为样本的权重。
概率越高,和测试集就越相似,权重就越高。这样,我们就可以做有权重的交叉验证。
# 生成lightgbm的数据格式,赋予各个样本权重
train_set = lgb.Dataset(
df_train.drop('HasDetections', axis=1),
label=df_train.loc[:, 'HasDetections'], weight=preds_adv[:len(df_train)])5 实例
5.1 用到的数据

图3 微软恶意软件比赛
这里用到的数据来自Kaggle上的微软恶意软件比赛。
因为这次比赛的 Train 和 Test 是根据时间划分的,所以Train 和 Test 的分布非常不同,很具有代表性。
通过对该数据做对抗验证,我们发现模型的AUC达到了0.99。说明本次比赛的训练集和测试集的样本分布存在较大的差异。
5.2 对比各种方法的效果
分别使用上述提到的总共4种方法,我们来对比一下四种方法的效果,如下表:
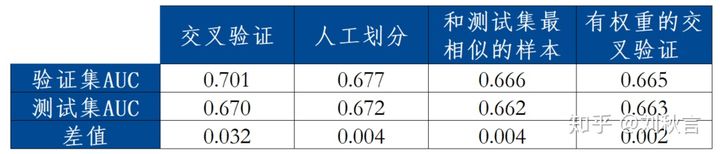
使用交叉验证时,验证集AUC和测试集AUC的差值是最大的,远高于其他方式。说明在样本分布发生变化时,交叉验证不能够准确评估模型在测试集上的效果。
5.3 为什么评价方式是差值,而不是测试集AUC?
有人可能会提到,哪种方法在测试集上的AUC最高,哪种方法就更好,不是吗?
需要注意的是,本文讨论的不是“提升”模型效果的方法,而是“评估”模型效果的方法。
具体来说,虽然目前看来,比如交叉验证在测试集上的AUC,略高于有权重的交叉验证。
但是,当前的模型只是一个很基础的模型(Baseline Model),没有做任何的变量筛选,特征工程,以及模型调参。
由于所有的优化模型的决定,都将基于验证集,而交叉验证无法准确评估模型在测试集上的效果,这将导致很多优化模型的决定是错误的。
只有在有一个可靠的验证集的情况下,提升模型在验证集上效果的方法,我们才有信心认为,它也可以提升在测试集上的表现。
另外,从本次比赛的结果,我们也可以发现,最终排名很好的参赛者,都没有使用交叉验证。
6 结论
在样本分布发生变化时,交叉验证不能够准确评估模型在测试集上的效果。
这里建议采用其他方式:
- 人工划分验证集
- 和测试集最相似的样本作为验证集
- 有权重的交叉验证
最后
以上就是悦耳人生最近收集整理的关于[机器学习]试试Kaggle大牛们常用的方法——对抗验证的全部内容,更多相关[机器学习]试试Kaggle大牛们常用内容请搜索靠谱客的其他文章。




![[机器学习]试试Kaggle大牛们常用的方法——对抗验证](https://www.shuijiaxian.com/files_image/reation/bcimg24.png)



发表评论 取消回复