一级分区
准备数据
order_created.txt
10703007267488 2014-05-01 06:01:12.334+01
10101043505096 2014-05-01 07:28:12.342+01
10103043509747 2014-05-01 07:50:12.33+01
10103043501575 2014-05-01 09:27:12.33+01
10104043514061 2014-05-01 09:03:12.324+01
创建表
PARTITIONED BY 就是声明分区,并指定分区字段和字段类型
terminated by 是指定 tab分割(t就是tab)
create table order_partition
(
order_no string,
order_time string
)
PARTITIONED BY (event_time string)
row format delimited fields terminated by 't';
导入数据
现在order_created.txt所在的目录在/root/soft
[root@zjj101 soft]# ls
data docker hadoop-2.7.2 hive-1.2.1 myconf order_created.txt tmp
[root@zjj101 soft]# pwd
/root/soft
使用load方式导入
sql
load data local inpath '/root/soft/order_created.txt' into table order_partition
partition (event_time = '2014-05-01');
参数说明:
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
如果导入的文件在本地文件系统,需要加上local,使用put将本地上传到hdfs
不加local默认导入的文件是在hdfs,使用mv将源文件移动到目标目录
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
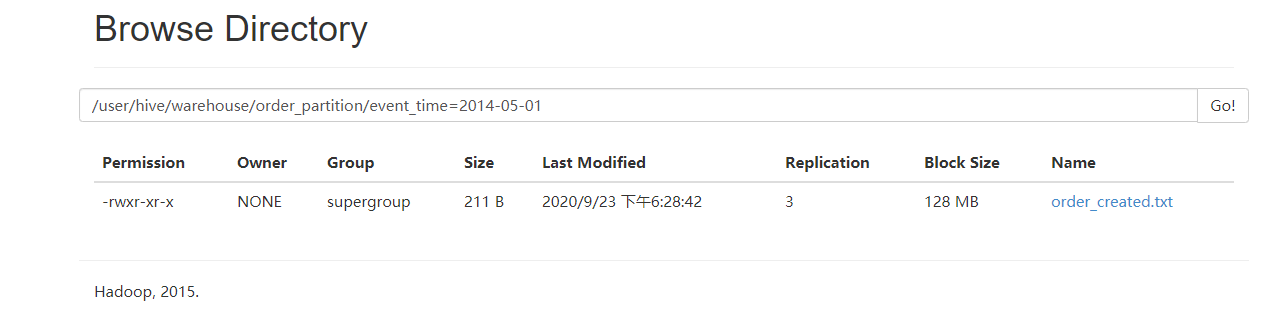
查询数据
sql
select *
from order_partition
where event_time = '2014-05-01';
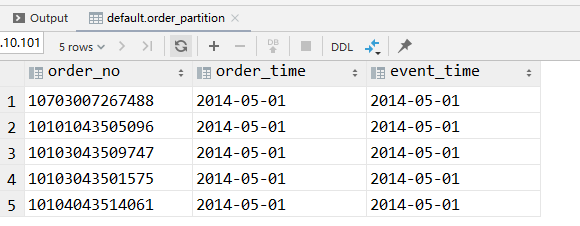
hdfs控制面板
刚刚的数据就在里面了
查看表的描述
查看表的描述
最后
以上就是爱撒娇小白菜最近收集整理的关于hive分区表一级分区的基本使用 *一级分区hdfs控制面板查看表的描述的全部内容,更多相关hive分区表一级分区的基本使用内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复