-
Edge-Informed Single Image Super-Resolution
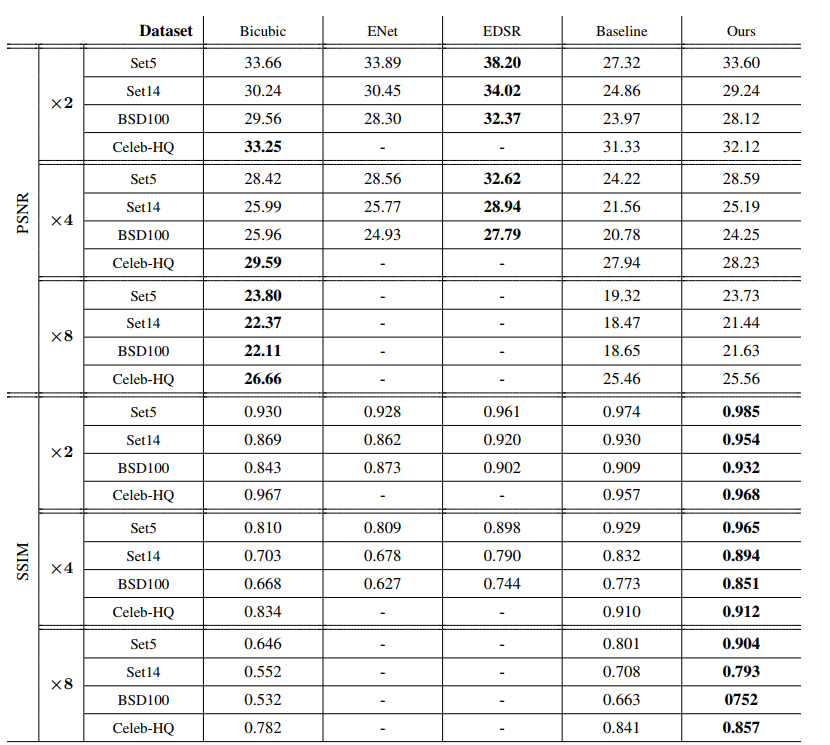
- 性能:
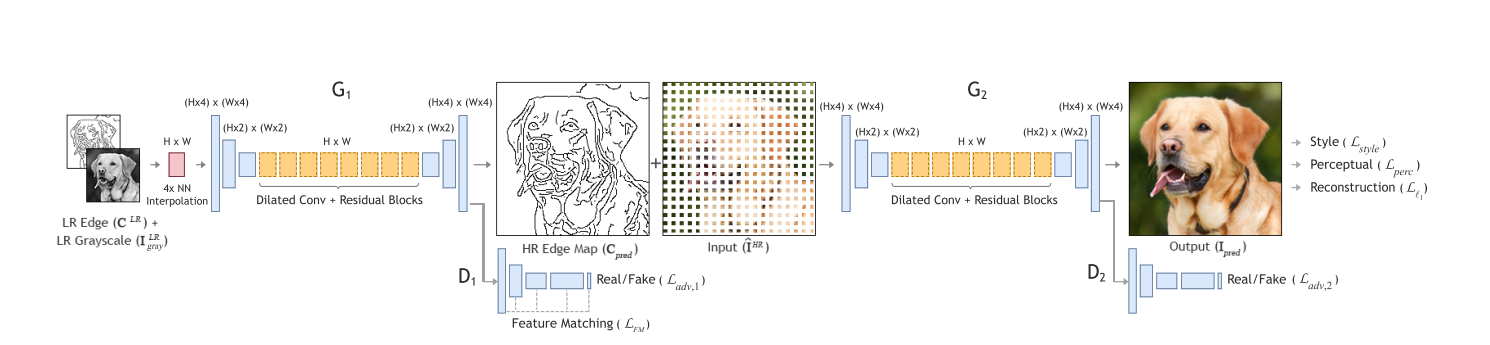
- 把sr任务描述为一个 in-between pixels inpainting task,并分为两个阶段,一个是edge enhancement,一个是image completion,两个阶段用两个GAN来完成,两个G都是encoder-decoder,先downsample两次再upsample,其它一些细节如下
We use dilated convolutions in our residual layers. Our generators follow similar architectures to the method proposed by Johnson et al. [21] shown to achieve superior results for super-resolution [35, 14], image-to-image translation [45], and style transfer. Our discriminator follows the architecture of a 70 × 70 PatchGAN [20, 45] that classifies overlapping 70×70 image patches as real or fake. We use instance normalization [40] across all layers of the network, which normalizes across the spatial dimension to generate qualitatively superior images during training and at test time.
- G1的输入是LR的灰度图的邻近插值和LR的灰度图的canny 边缘图的邻近插值,输出是对HR的灰度图的canny 边缘图的预测
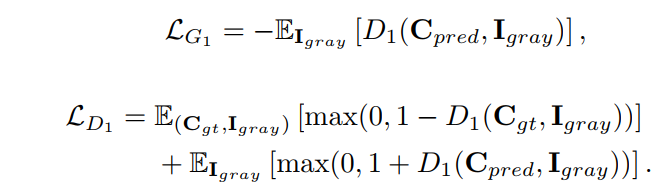
- G1比常规G加一个
L
F
M
mathcal{L}_{FM}
LFM无法用perceptual loss因为VGG不是训练在边缘图上的,没有作用
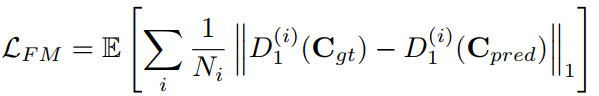
- 还使用了GAN的SN技术
- G2的输入是LR的fixed fraction conv和G1的输出,就是针尖的upsample,卷积核长这样:
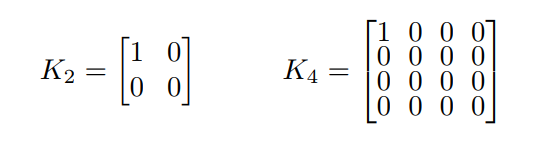
- 性能:
最后
以上就是大意机器猫最近收集整理的关于Edge-Informed Single Image Super-ResolutionEdge-Informed Single Image Super-Resolution的全部内容,更多相关Edge-Informed内容请搜索靠谱客的其他文章。







![[sicily]部分题目分类](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)
发表评论 取消回复