前言
- 论文题目《Double Graph Based Reasoning for Document-level Relation Extraction》
- 论文地址
- 文章来源:CSDN@LawsonAbs
- 推荐指数:★☆☆☆☆
首先声明一下,下面这篇文章写得不是很系统,如果需要高质量的博客进行介绍,请文末留言,我再更新。
mention_id 描述的是一篇doc 被tokenizer 之后,得到各个位置下的token对应哪个mention的下标?如果不对应mention,则置为0.
mention_id 的size 是[batch_size,max_length]

mentions
size = [mention_num,max_len]
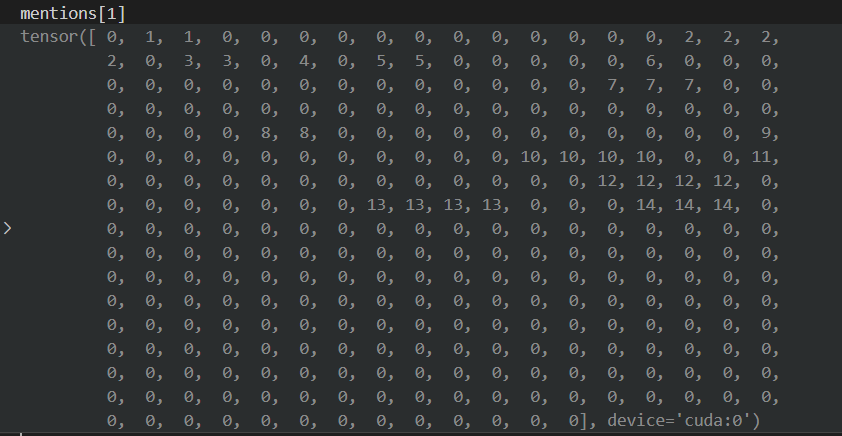
其实可以发现: mentions 中每行的值相同,都是 mention_id[i] 的值
mention_index
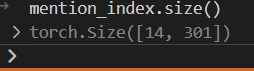
当前这篇doc有多少个mention,那么mention_index 的size(0) 就是多大。mention.size(1) = max_length
其中的值如下:
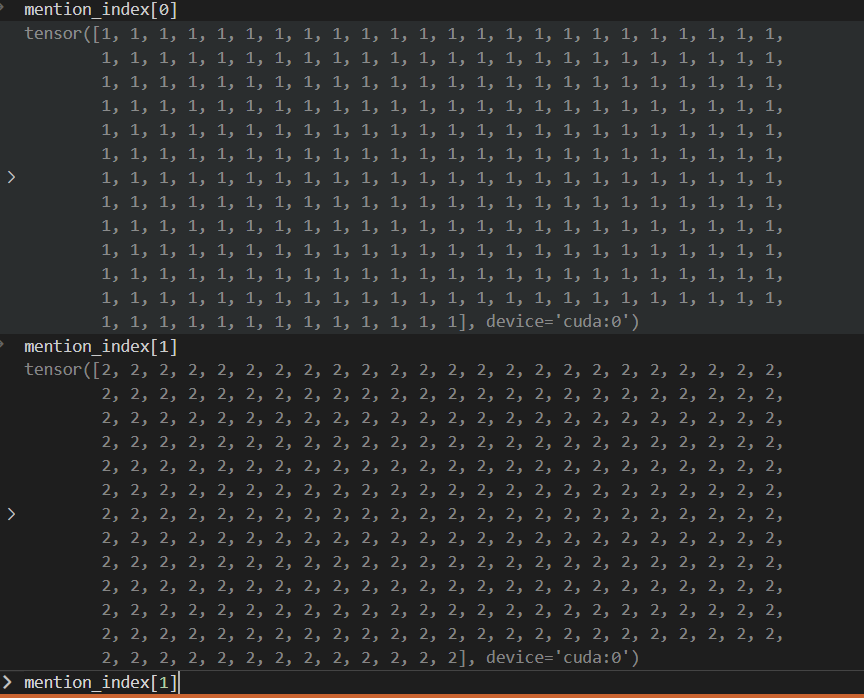
这个mention_index 后面会用到(与mentions做比较操作),第i行负责提取出第i+1(因为mention从1开始计数,但是下标从0开始计数)个mention的表示。
再看 select_metrix
这个select_metrix 就是由 mention_index 和 mentions 比较得到,其计算过程如下:
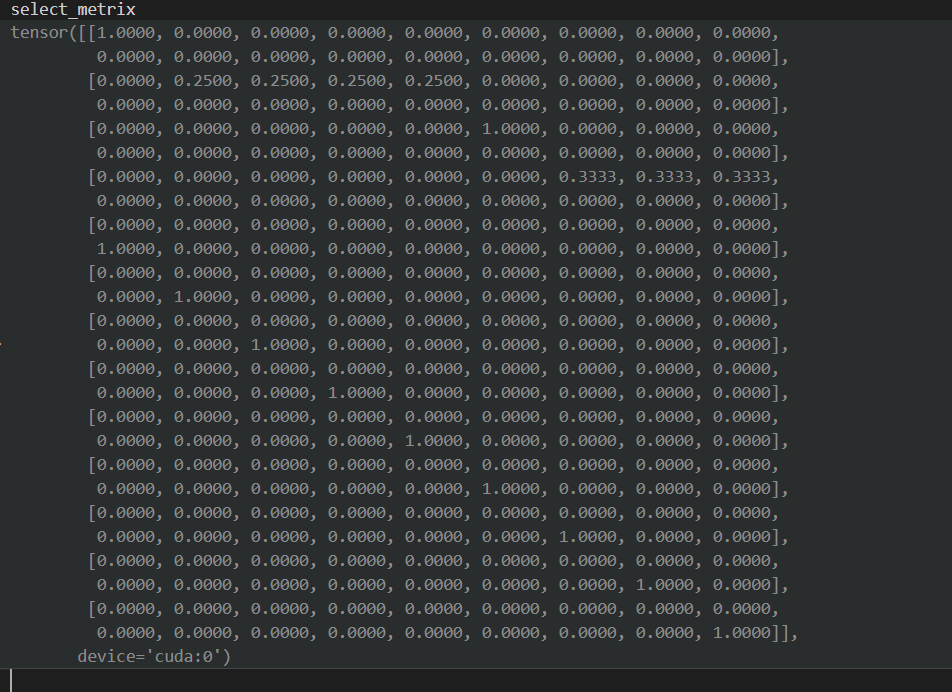
select_metrix = (mention_index == mentions).float()
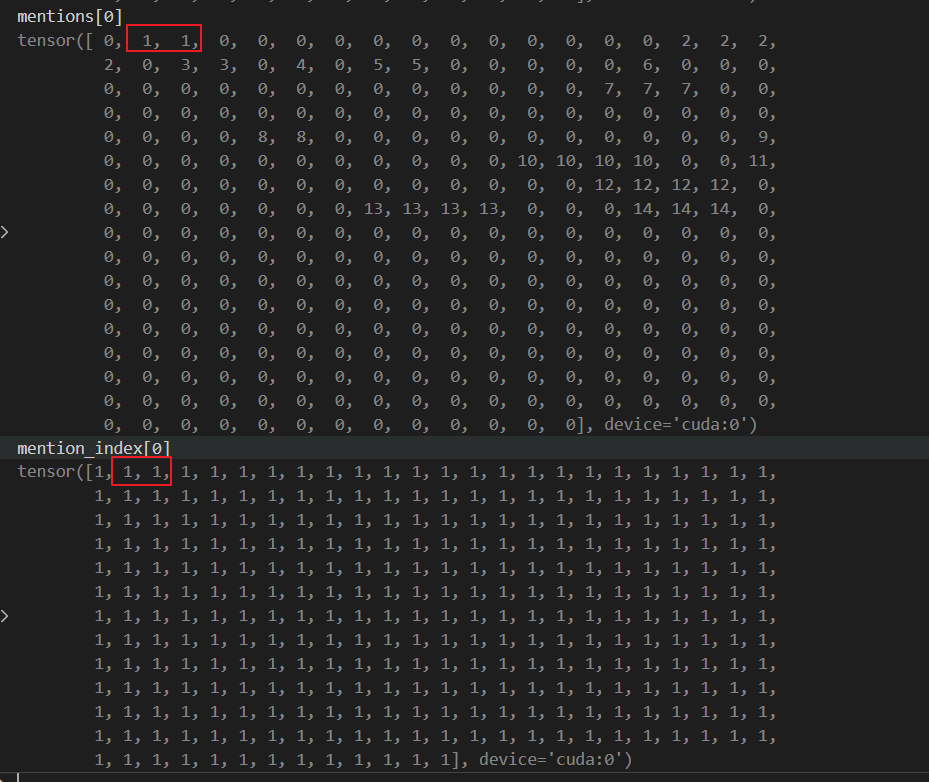
得到的计算结果就是 select_metrix[0]
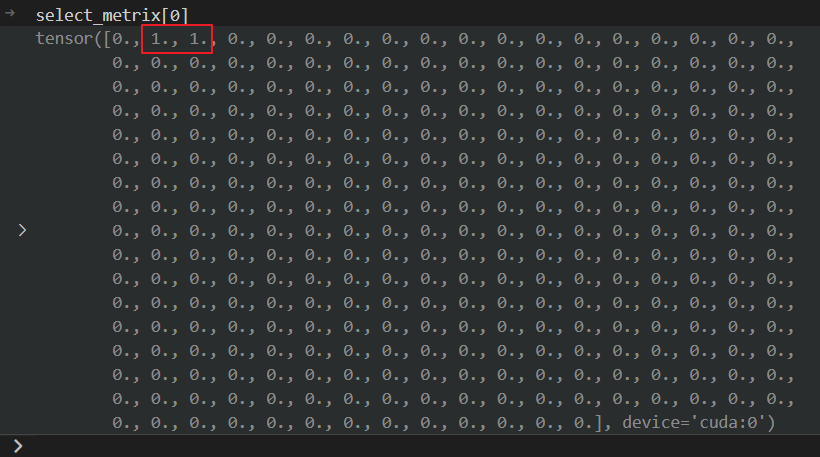
上面这个红框的含义就是:这两个位置的表示就是第0+1个mention 的位置。
torch.sum(select_metrix, dim = -1)
表示的就是对 select_metrix 这个矩阵每行求和,得到的值如下:

这个值的含义就是:找出这篇doc中有几个token表示这个mention。
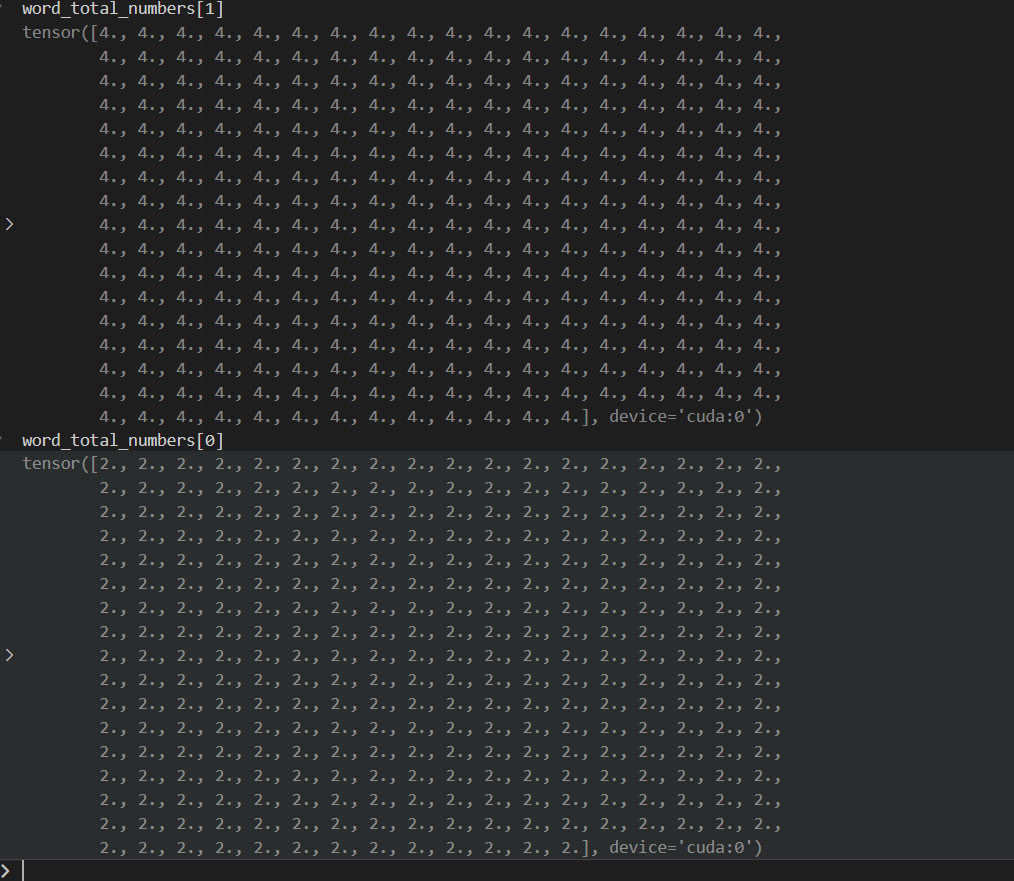
torch.sum(select_metrix, dim=-1).unsqueeze(-1).expand(-1, slen)
再做一个unsqueeze(-1) 以及 .expand(-1,slen) 操作,就是将每行的值复制一份,扩展到每列上。值如下:
接着对 select_metrix 做一个赋值
select_metrix = torch.where(word_total_numbers > 0, select_metrix / word_total_numbers, select_metrix)
这个代码的含义就是想 计算每个token在整体doc中的权重:
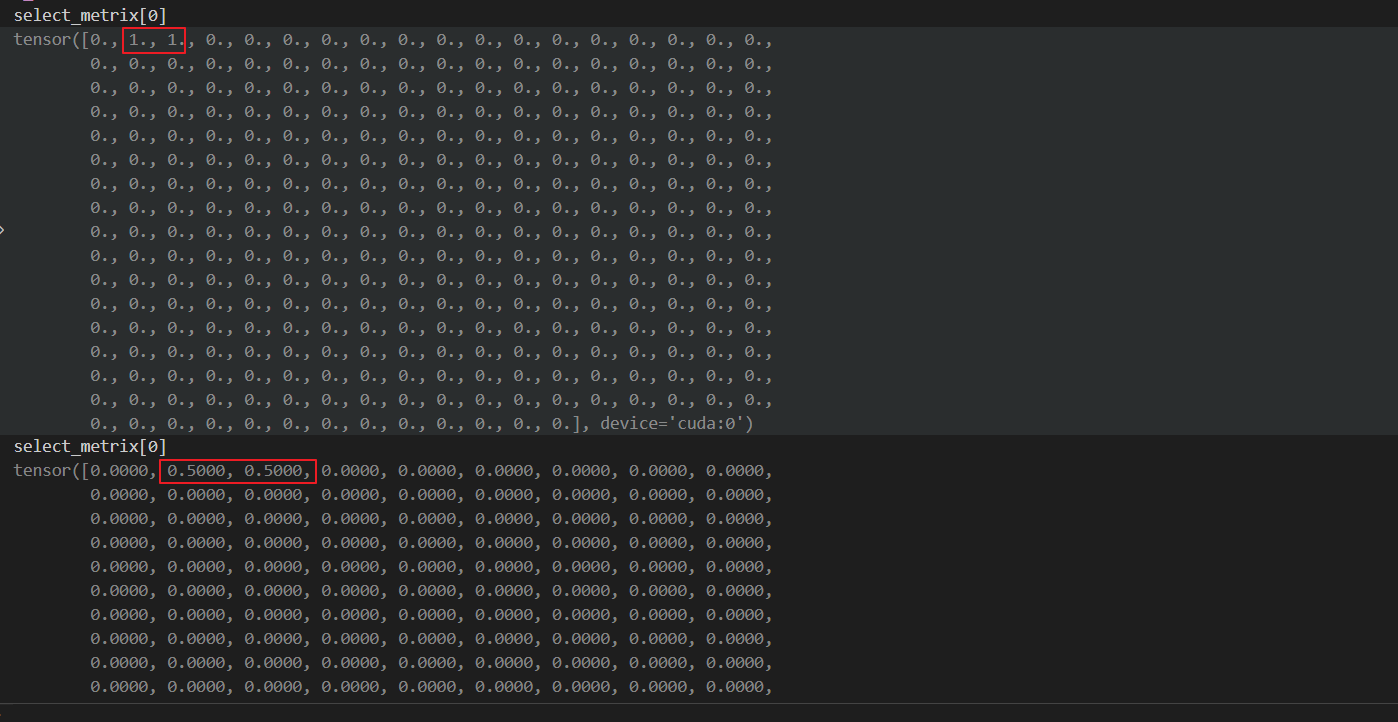
最后便得到mention的表示。
x = torch.mm(select_metrix, encoder_output) # [mention_num, bert_hid]
接着来看根据mention 取 entity 表示的过程

这个值是怎么获取的?
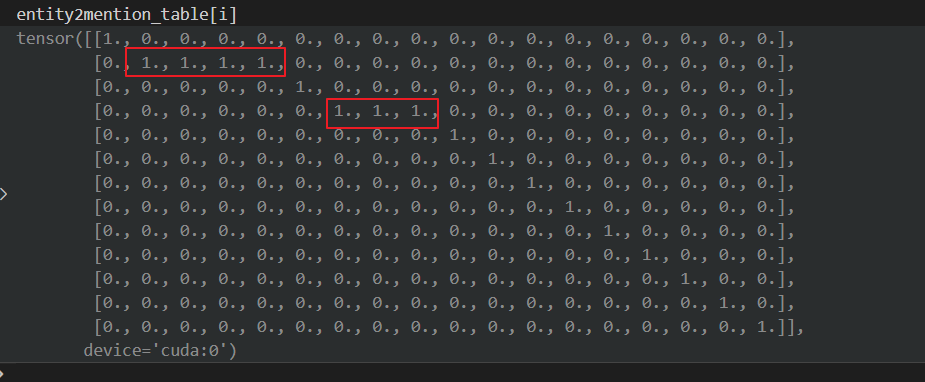
这个变量有什么特征?
可以观察到: entity2mention_table[i].size(0) <= entity2mention_table[i].size(1) , 这个是恒成立的。因为第一维代表的是entity num,第二维代表的是mention num。 实体数是要大于mention 数的。
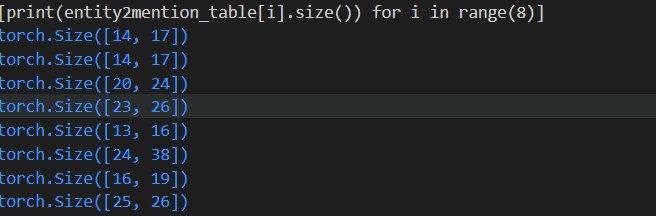
这里的 entity num 和 mention num 都是从0开始计数,单纯的表示doc中的第几个实体。
mention_nums 表示的是将每列的值扩充到多列
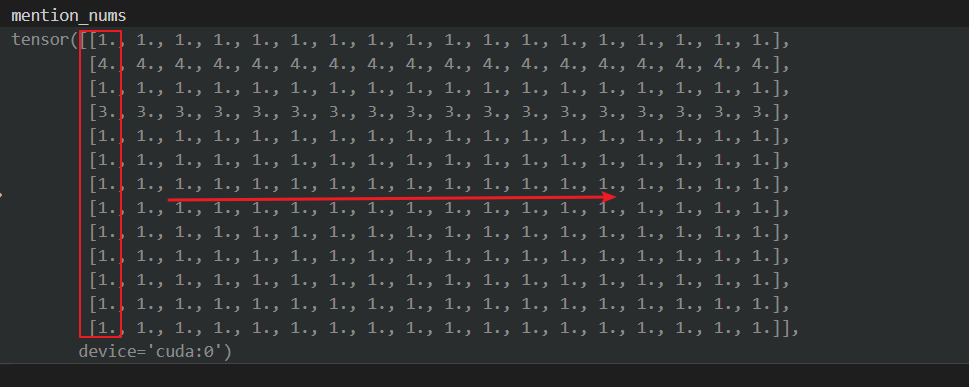
select_metrix = torch.where(mention_nums > 0, select_metrix / mention_nums, select_metrix)
这行代码的作用同上面的做法相同,(之前的是在token上找出mention的,这就是在 mention 上找出 entity 的)
得到的值如下:
查看模型生成正负样本的逻辑
首先了解一下这各个变量
relation_multi_label
这个是什么意思?
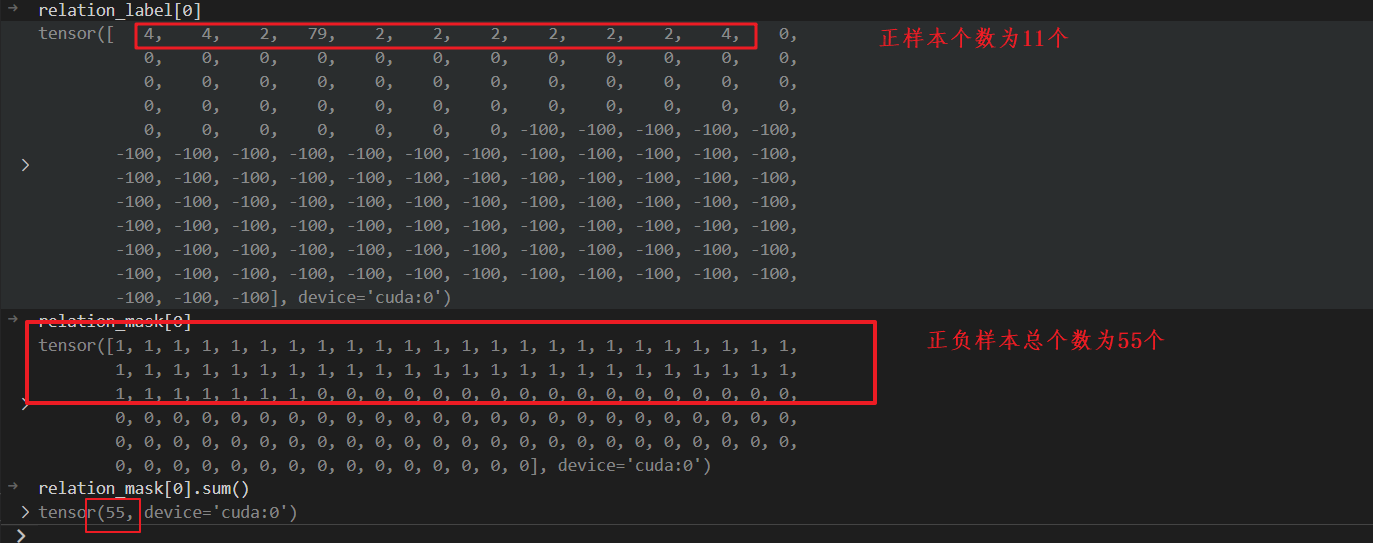
realtion_label

代表的含义就是:当前batch中各个doc拥有的标签数。[batch_size,label_num]
relation_mask
因为有的doc没有那么多label,所以需要一个mask操作。
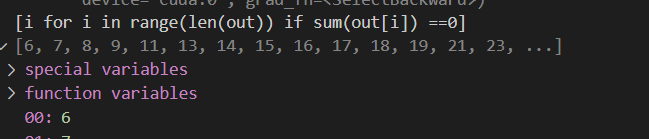
Bug 排查
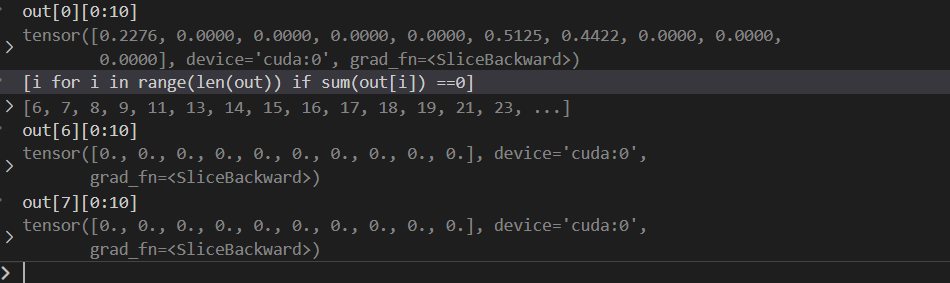
发现图卷积之后的结果很多都是0?这是怎么回事儿?
查看有边的节点:

其中a表示的是有边的节点。可以发现:上面结果为0的那些节点都是没有边的。所以导致出现了问题。
最后参与分类的特征多,loss 下降的确实更加明显,比较的是下面两个部分:
predictions = self.predict(torch.cat(
(h_entity, t_entity,global_info),dim=-1)
)
predictions = self.predict(torch.cat(
(h_entity, t_entity,torch.abs(h_entity - t_entity), torch.mul(h_entity, t_entity),global_info),dim=-1)
)
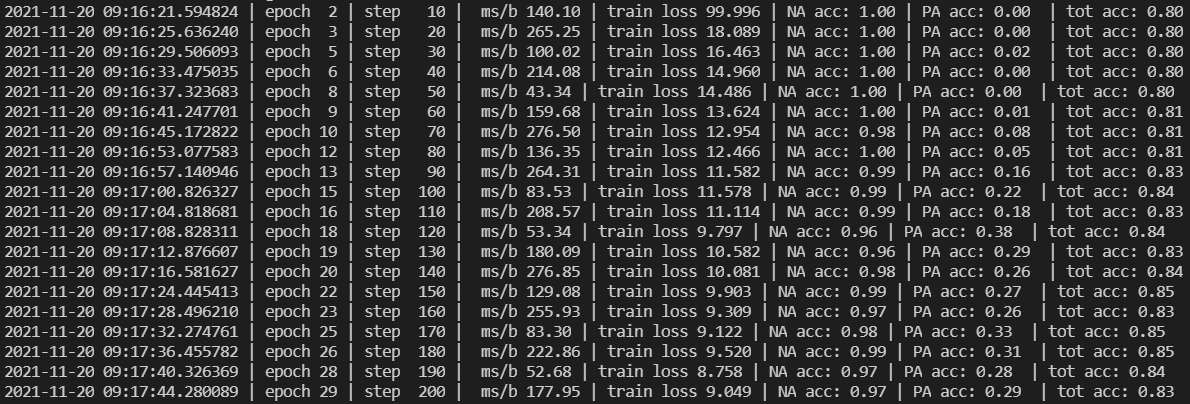
我当前的这种思想:
使用train.json建立一个全局的graph,这可能导致数据泄漏,因为在训练前我们就把标签数据写到图中了,这样就导致模型可以直接读取了。所以存在一定的问题。
当我仅仅以 train.json 创建graph_big 时,训练10 epoch 之后,在dev.json 上验证,效果就仅有

这性能是远远不够的!
最后
以上就是飘逸金毛最近收集整理的关于源码解读系列之GAIN模型前言接着来看根据mention 取 entity 表示的过程查看模型生成正负样本的逻辑Bug 排查的全部内容,更多相关源码解读系列之GAIN模型前言接着来看根据mention内容请搜索靠谱客的其他文章。








发表评论 取消回复