innodhecksum[1]是MySQL自带的offline工具bin,可检查innodb数据文件是否损坏。使用方式如下。
shell> bin/innochecksum [options] file_nameMySQL的系统表空间(ibdata)、用户表空间(*.ibd)、redo log(ib_logfile)等文件,结构类似,都由page构成,UNIV_PAGE_SIZE默认16KB,定义如下。了解更多可参考文章[2]或者innodb-java-reader工具[3]。
#define UNIV_PAGE_SIZE (2 * 8192)如下图所示,page前后是38字节的header和8字节的trailer。checksum校验算法会利用index4-26以及index38-16376这两部分计算。详细实现参考ut0crc32.cc[4]。

page的checksum算法有三种,参考官方文档[6]。
innodb
crc32
none从MySQL 5.7.7版本之后crc32是默认的checksum算法。
crc32的校验算法有两种实现,如果CPU支持SIMD SSE4_2指令集,则硬件加速,直接inline汇编代码;如果不支持,fallback到软件算法实现。
innochecksum执行的逻辑很简单。
while (!feof(fil_in)) {
bytes = read_file //read 16KB
is_page_corrupted //using crc32/innodb/none algorithm
}优化innochecksum前,先看看基准性能如何。环境如下。
- CPU: Intel Xeon CPU E5-2682 v4 @ 2.50GHz(开启超线程,逻辑核数64)
- 内存: 256G
- NVMe SSD硬盘:PCIe 3.0 x4, NVMe, Intel® SSD DC P3600 Series, 1.6TB
Intel官方上查企业级DC P3600 1.6TB这块盘[7]。正面如下。

背面图如下,可以看到排列整齐的MLC NAND闪存颗粒[8]。

规格如下。官方资料,顺序写1600 MB/s,顺序读2600 MB/s。

测试数据文件是TPC-H的LINEITEM,大小有72G左右。(dbgen -s 70生成后导入MySQL,文件较大,为了更好的观测)。
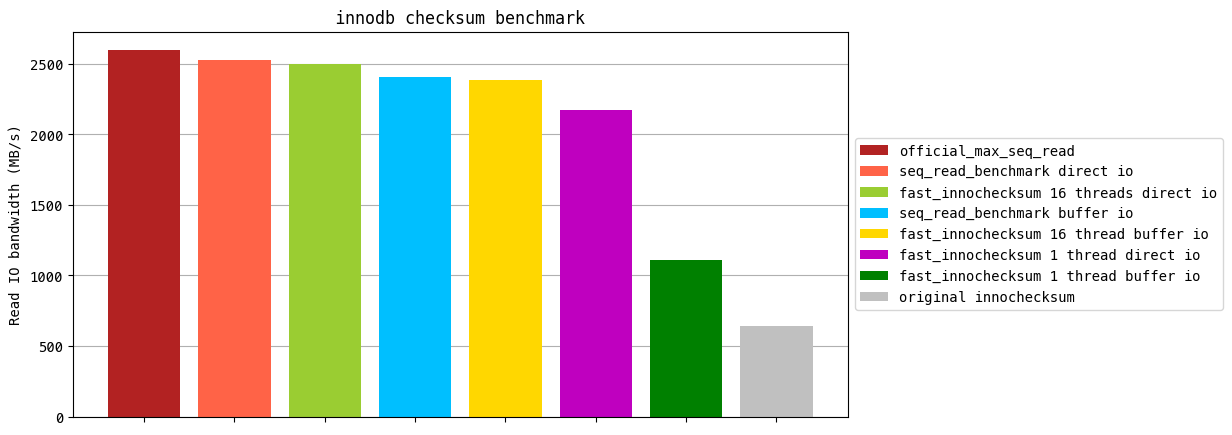
直接上图,MySQL自带的bin执行innochecksum -C crc32 file_name,带宽只有642 MB/s,远低于这块盘的顺序读吞吐限。
优化后的最优版本可以达到2503 MB/s,非常接近官方最高吞吐。
下面第一部分 测试NVMe SSD读写极限吞吐,第二部分 阐述优化实现方案。
1. 测试NVMe SSD读写极限吞吐
fio[9]测试读写吞吐,ioengine选择libaio。
fio写:
./fio --filename=test -iodepth=16 -ioengine=libaio -direct=1 -rw=write -bs=1m -size=512g -numjobs=8 -runtime=50 -group_reporting -name=test-write
write: bw=1543.2MB/s, iops=1543fio读:
./fio --filename=test -iodepth=16 -ioengine=libaio -direct=1 -rw=read -bs=2m -size=512g -numjobs=8 -runtime=50 -group_reporting -name=test-read
read : bw=2382.8MB/s, iops=2382测试结果基本符合官方的数据,但都差一些,所以手写代码再压测下,部分代码参考文章[10]。源码链接如下。
https://github.com/neoremind/io_benchmarkgithub.com测试buffer io write-back写,代码如下。
#include <iostream>
#include <unistd.h>
#include <cstring>
#include <sys/time.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <vector>
#include <thread>
#include <fcntl.h>
#define WRITE_ONCE_BYTE_SIZE 4096
static char data[WRITE_ONCE_BYTE_SIZE] __attribute__((aligned(WRITE_ONCE_BYTE_SIZE))) = {'a'};
static const uint64_t kWriteCountPerThread = 1000 * 1000;
static const uint64_t kConcurrency = 64;
static const uint64_t kWriteBytesPerThread = sizeof(data) * kWriteCountPerThread;
static const uint64_t kTotalWriteBytes = kWriteBytesPerThread * kConcurrency;
uint64_t NowMicros() {
struct timeval tv;
gettimeofday(&tv, NULL);
return static_cast<uint64_t>(tv.tv_sec) * 1000000 + tv.tv_usec;
}
void writer(int index) {
std::string fname = "data" + std::to_string(index);
int fd = ::open(fname.c_str(), O_NOATIME | O_RDWR | O_CREAT, 0644);
int ret = posix_fallocate(fd, 0, kWriteBytesPerThread);
if (ret != 0) {
printf("fallocate err %dn", ret);
}
lseek(fd, 0, SEEK_SET);
for (int32_t i = 0; i < kWriteCountPerThread; i++) {
::write(fd, data, WRITE_ONCE_BYTE_SIZE);
}
close(fd);
}
int main() {
uint64_t st, ed;
st = NowMicros();
std::vector<std::thread> threads;
for(int i = 0; i < kConcurrency; i++) {
std::thread worker(writer, i);
threads.push_back(std::move(worker));
}
for (int i = 0; i < kConcurrency; i++) {
threads[i].join();
}
ed = NowMicros();
printf("time elapsed microsecond(us) %lld, %lld MB/sn", ed - st, kTotalWriteBytes / (ed - st));
return 0;
}64并发顺序写4k数据,1510 MB/s,CPU利用率非常高,vmstat显示bo存在抖动。个人分析原因,虽然使用fallocate预分配空间,减少了刷文件总metadata的overhead,但测试OS的内核不支持FALLOC_FL_ZERO_RANGE,还是会存在EXT4 extents filling zero的overhead(参考文章[11]);另外高并发的小IO写page cache,频繁刷脏页也加重了系统的负载。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
65 0 0 3618176 330256 247338112 0 0 0 1457344 152720 6513 0 96 4 0 0
65 0 0 3492712 330256 247428272 0 0 0 1315880 169502 4963 0 96 4 0 0
66 0 0 3545536 330256 247339136 0 0 0 1183212 180769 4215 0 96 4 0 0
65 0 0 3525324 330256 247325776 0 0 0 1309008 183833 4679 0 97 3 0 0
66 0 0 3590052 330256 247226944 0 0 0 1496924 176723 5951 0 97 3 0 0
57 0 0 3543704 330256 247167072 0 0 0 2441148 197181 7717 0 95 5 0 0
64 0 0 3565740 330256 247107824 0 0 0 1472412 170361 8038 0 94 6 0 0
55 0 0 3520116 330256 247132928 0 0 0 1457048 154563 9472 0 95 5 0 0
65 1 0 3549728 330256 247052544 0 0 0 1555564 133119 8827 0 92 8 0 0
63 0 0 3567856 330256 247002144 0 0 0 1343976 144924 7134 0 97 3 0 0改成48并发反而带宽接近官方资料。
time elapsed microsecond(us) 123703672, 1589 MB/s测试direct io write-through写,核心代码如下。64并发顺序写4k打不满,为保证数据不丢,通常会通过mmap拼接4k的数据到16k,尽量大块IO写,接近打满带宽,和fio结果相近。
char* base = nullptr;
char* cursor = nullptr;
uint64_t staging_offset = 0, file_offset = 0;
int staging_fd = ::open(staging_fname.c_str(), O_NOATIME | O_RDWR | O_CREAT, 0644);
int ret = posix_fallocate(staging_fd, 0, kStagingFileSize);
void* staging_ptr = mmap(NULL, kStagingFileSize, PROT_READ | PROT_WRITE,
MAP_SHARED, staging_fd, 0);
int fd = ::open(fname.c_str(), O_DIRECT | O_NOATIME | O_RDWR | O_CREAT, 0644);
ret = posix_fallocate(fd, 0, kWriteBytesPerThread);
lseek(fd, 0, SEEK_SET);
base = static_cast<char*>(staging_ptr);
cursor = static_cast<char*>(staging_ptr);
for (int32_t i = 0; i < kWriteCountPerThread; i++) {
if (unlikely(staging_offset >= kStagingFileSize)) {
pwrite64(fd, staging_ptr, kStagingFileSize, file_offset);
cursor = base;
file_offset += kStagingFileSize;
staging_offset = 0;
}
memcpy(cursor, data, 4096);
cursor += 4096;
staging_offset += 4096;
}
close(staging_fd);
close(fd);
munmap(staging_ptr, kStagingFileSize);
staging_ptr = nullptr;结果如下。
time elapsed microsecond(us) 170181550, 1540 MB/s测试buffer io读。核心代码如下。
int fd = ::open(fname.c_str(), O_NOATIME | O_RDWR, 0644);
void* buffer = NULL;
posix_memalign(&buffer, getpagesize(), kReadOnceByteSize);
uint64_t offset = 0;
for (int32_t i = 0; i < kReaderCountPerThread; i++) {
pread64(fd, buffer, kReadOnceByteSize, offset);
offset += kReadOnceByteSize;
}
close(fd);64并发顺序读4k结果如下。
time elapsed microsecond(us) 109012309, 2404 MB/s这里每次测试都需要清理page cache:echo 3 > /proc/sys/vm/drop_caches。
测试direct io读。代码和上面类似,只需要打开文件的时候指定O_DIRECT。由于没有read ahead,所以带宽都在2000 MB/s以下,同样的解决思路读大块IO,56并发顺序读16k。
time elapsed microsecond(us) 90598873, 2531 MB/s2. 优化innochecksum
首先分析`innochecksum -C crc32 file_name`,使用perf查看热点代码。
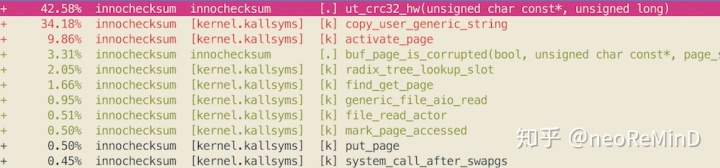
42.58%在使用SIMD SSE4_2硬件加速计算checksum,34.18%是拷贝page cache数据到用户态,由于使用buffer io,同步阻塞式的从kernel space page cache拷贝小块IO 16k到user space,所以这部分开销不小。另外由于innochecksum是串行执行,CPU利用率很低。
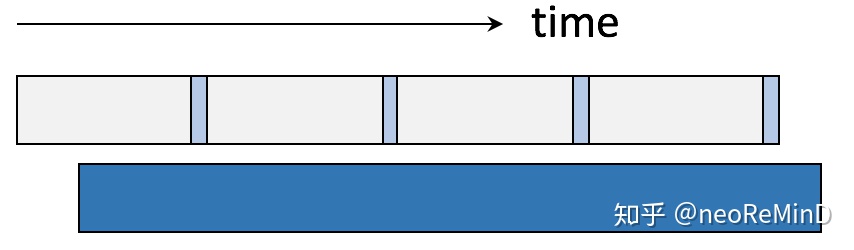
时间消耗示意图如下。
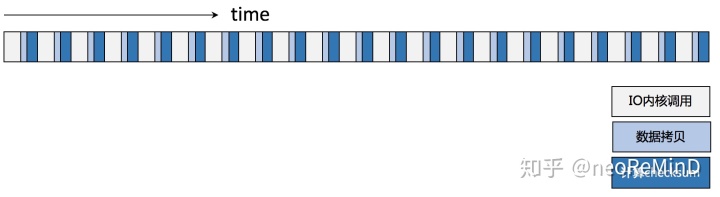
优化思路总结有两点。1)大块IO批量读,减少内核调用次数
打破page-at-a-time的读取模式,采用大块IO少量内核调用,缓存到用户态,由于内核IO path较长,尽量避免频繁陷入内核和数据拷贝,例如一次读16MB,与MonetDB/X100[12]提供的向量化(vectorized)执行有异曲同工之妙。同时整块的数据对于CPU的多级缓存架构也更友好。
时间消耗呈现如下图。

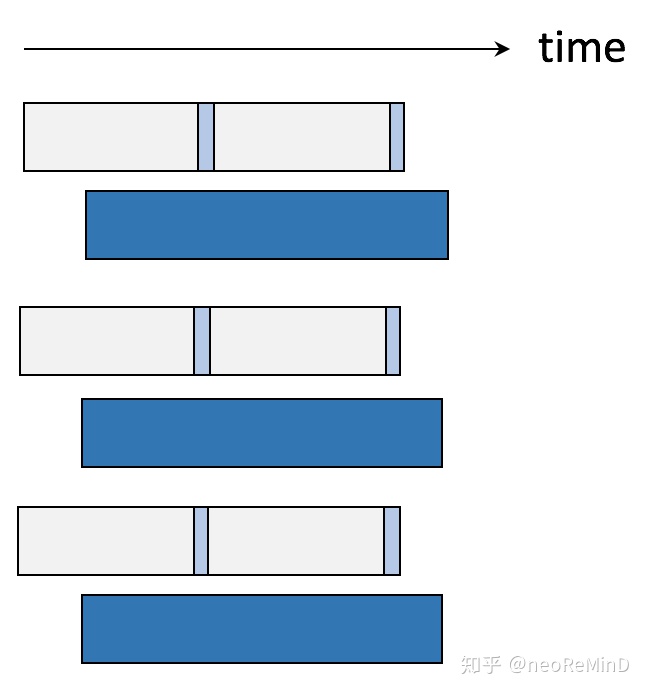
2)IO计算分离
打破单线程串行执行的模式,最大化CPU利用率,避免low IPC(instructions-per-cycle)efficiency,也就是计算和IO不互相等待,模拟两级流水线,一个负责IO读,一个负责计算checksum。
在大块IO批量读的基础上,加上IO计算分离,时间消耗如下图。
最终实现源码链接。
neoremind/fast_innochecksumgithub.com
文件结构如下。fast_innochecksum.cpp是执行main入口,ut0crc32.*是从MySQL源码中拷贝出来计算checksum的工具类。
$ls
Makefile
fast_innochecksum.cpp
partition.cpp
partition.h
partition_scan_cache_pool.cpp
partition_scan_cache_pool.h
scanner.cpp
scanner.h
shard.cpp
shard.h
thread_pool.h
ut0crc32.cpp
ut0crc32.h
util.cpp
util.h核心的流水线执行实现,在partition.cpp、partition_scan_cache_pool.cpp、shard.cpp三个文件中。
假设文件不再细分shard,整个文件就是一个shard,分多个shard是为了多线程执行,后面再介绍。shard再细分成partition,每个partition的大小是一次buffer io或者direct io读取的量,大块IO读取到内存中,缓存起来,由于内存有限,采用滑动窗口(sliding window)的思想,一个窗口内只含有限个partition。流水线执行(pipelining)需要两个线程,一个是IO线程,做prefetching,预读多个partition的数据到内存中缓存起来,供计算线程使用;另一个是计算线程,扫partition内存缓存的pages,计算checksum。
如下图所示,假设partition大小(代码中的kPartitionByteSize)64MB,则一次IO单元读取4000个page;滑动窗口大小(代码中的kNumOfScanCachePartition)3个,最多prefetching3个partition。窗口不断向文件后面移动,实现了IO计算分离的执行过程。
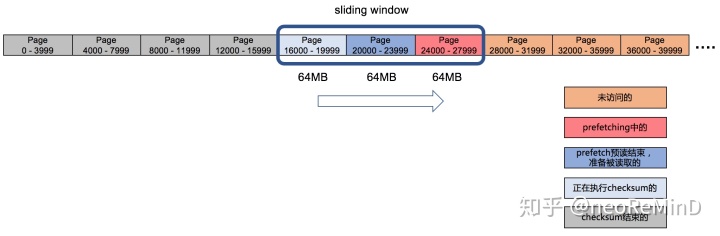
实际production环境,考虑到单个innodb文件都不会太大,可以配置更小的kPartitionByteSize,16MB也是可行的。
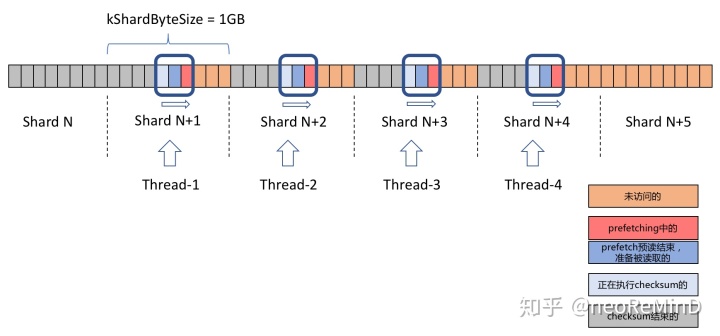
由于NVMe SSD出色的并发读特性,要想压榨磁盘到极限,就必须并行化。把一个文件分成若干个shard,大小配置是kShardByteSize,提交每个shard到线程池中,每个shard就可以独立的进行上面的过程。代码在scanner.cpp中。如下图所示,kShardByteSize=1G,线程池4个thread。
最终版本的时间消耗如下图。
最终评测结果如下。MySQL innochecksum 642 MB/s,buffer io单线程IO计算分离的结果1109 MB/s,比例是57%,稍高于perf图中的实际纯计算开销42%,也比较合理。
采用不同的IO模型,direct io普遍优于buffer io,只要读取的内存是对齐的,就可以by pass pagecache,并且省了一次内存拷贝。
在采用direct io,16线程并发,shard 1G,partition 64MB的情况下可以达到2503 MB/s的读带宽,非常接近官方资料2600MB/s。
+-------------------------------------------+
|IO |thread|Shard |Partition|Throughput|
|mode |count |ByteSize|ByteSize | |
+-------------------------------------------+
|direct| 1 | 256MB | 16MB | 2081 MB/s|
|direct| 1 | 1G | 64MB | 2173 MB/s|
|direct| 16 | 256MB | 16MB | 2468 MB/s|
|direct| 16 | 1G | 64MB | 2503 MB/s|
|buffer| 1 | 256MB | 16MB | 1086 MB/s|
|buffer| 1 | 1G | 64MB | 1109 MB/s|
|buffer| 16 | 256MB | 16MB | 2342 MB/s|
|buffer| 16 | 1G | 64MB | 2386 MB/s|
+-------------------------------------------+
Note: kNumOfScanCachePartition=33. 思考
本次评测采用了PCIe 3.0 x4, NVMe, Intel® SSD DC P3600 Series, 1.6TB磁盘,这块盘读写测试,以及最终的benchmark都没有严格达到官方资料,差一点点,相比Intel Optane傲腾[13]系列要逊色不少。后续如果有条件,可以在傲腾上跑一跑。
本次评测主要集中在最大化吞吐,因此在IO模型上没有使用libaio,没有使用新内核版本提供的io_uring[14],这些技术可以进一步降低延迟,加大IOPS,不过本次重点还是在带宽上。
随着新硬件的不断发展,比如,RDMA、DPDK这些摒弃传统内核重IO path的kernel by pass网络传输技术,SPDK、3D XPoint NVMe SSD、NVMe on DIMM这些磁盘IO新驱动和新硬件,多核心CPU的普及,hardware-conscious design(NUMA-aware,cache-conscious等)越来越重要,很多传统的设计和数据结构并不是针对高性能硬件优化的,面向新硬件新技术重新设计,提高资源利用率,榨干硬件资源,才能进一步释放软件的性能和吞吐。本文就是在这样背景下的一次实践。
参考资料
[1] https://dev.mysql.com/doc/refman/5.7/en/innochecksum.html
[2] https://zhuanlan.zhihu.com/p/103582178
[3] https://github.com/alibaba/innodb-java-reader
[4] https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/ut/crc32.cc
[5] https://blog.jcole.us/2013/01/03/the-basics-of-innodb-space-file-layout/
[6] https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_checksum_algorithm
[7] https://ark.intel.com/content/www/us/en/ark/products/80993/intel-ssd-dc-p3600-series-1-6tb-2-5in-pcie-3-0-20nm-mlc.html
[8] https://mp.weixin.qq.com/s/LeXFcQ6aLd-Cvm5o5BtEsw
[9] https://fio.readthedocs.io/en/latest/
[10] https://www.cnkirito.moe/linux-io-benchmark/
[11] https://zhuanlan.zhihu.com/p/61212603
[12] [MonetDB/X100: Hyper-Pipelining Query Execution](https://w6113.github.io/files/papers/monetdb-cidr05.pdf)
[13] https://www.intel.com/content/www/us/en/products/memory-storage/solid-state-drives/data-center-ssds/optane-dc-ssd-series.html
[14] https://zhuanlan.zhihu.com/p/62682475
最后
以上就是鲤鱼歌曲最近收集整理的关于iar最高优化模式选择size对代码的影响_优化innochecksum实战,四倍加速榨干NVMe SSD磁盘带宽...的全部内容,更多相关iar最高优化模式选择size对代码的影响_优化innochecksum实战,四倍加速榨干NVMe内容请搜索靠谱客的其他文章。








发表评论 取消回复