第十五届“SPSSPRO杯”数学中国数学建模网络挑战赛(第二阶段)『特等奖』,@队友:东可在编程、好同志歪歪
今年B题是一个自然语言处理(NLP)的问题,在数学建模比赛中比较少见。题目主要关于唐宋诗歌和诗人的风格差异。第一阶段的问题主要基于字(词)频、字词关联和唐宋诗风格差异进行定量分析和评价,第二阶段问题主要针对唐宋诗人的风格差异及其进一步细分进行探索。
本篇总结主要就方案进行阐述,模型和算法原理的介绍有所省略。
目录
1. 问题重述
1.1 问题背景
1.2 问题提出
2. 模型假设
3. 数据探索与预处理
3.1 数据探索与预处理流程
3.2 数据概况
3.3 数据清洗
3.4 统计分析
3.5 基于“甲言”的古汉语分词
4. 问题一的模型建立与求解
4.1 问题分析与思路
4.2 特征提取
4.2.1 作者主题模型(Author-Topic Model)
4.2.2 文本情感分析
4.2.3 词库建立与匹配
4.2.4 篇幅统计
4.3 指标体系构建和指标值计算
4.4 机器学习分类算法测试与选择
4.5 模型效果评价
4.5.1 特征重要性排序
4.5.2 混淆矩阵分析
4.5.3 模型训练指标评价
5. 问题二的模型建立与求解
5.1 问题分析与思路
5.2 基于风格特征指标体系的K-Means聚类模型
5.2.1 K-Means聚类K值选取
5.2.2 K-Means聚类结果与分析
5.3 基于用词倾向度的Single-Pass聚类模型
5.3.1 用词倾向度与风格
5.3.2 Word2Vec词向量训练和词嵌入
5.3.3 Single-Pass聚类算法
5.3.4 Single-Pass聚类参数选择
5.3.5 Single-Pass聚类结果分析
5.4 模型总结与对比
6. 问题三的模型建立与求解
6.1 问题分析与思路
6.2 代表诗人选取结果
6.3 代表诗人选取结果分析
7. 模型评价与推广
7.1 模型的优点
7.2 模型的不足之处与未来展望
7.3 模型推广
8. 参考文献
9. 比赛总结与启示
1. 问题重述
1.1 问题背景
中国是一个诗的国度。唐诗在中国诗歌发展史上占据了最光彩的一页,是中国诗歌的高峰。而宋诗在继承唐诗传统的基础上,其思想内容、艺术表现等方面都形成了自己鲜明的特色,形成了中国诗歌的另一高峰。可见“诗分唐宋”,不仅是朝代之分,也是两种不同美学风格的区分。
1.2 问题提出
根据题意,本文需要解决的问题主要有三个:
- 假设一个诗人的主要风格一定归属于唐诗或宋诗中的一种,建立数学模型,仅通过诗人的若干首作品,来确定此人的风格归属,并说明模型的合理性和有效程度;
- 建立数学模型,研究唐诗和宋诗的风格是否可以进一步详细划分为子类,并说明每个子类的划分依据;
- 为每种风格子类选出若干最有代表性的诗作和诗人。
2. 模型假设
为简化模型,我们做了以下合理性假设:
- 《全唐诗》《全宋诗》不存在误收,诗歌内容无错别字等情况;
- 主题、情感、语言是诗人诗作的三大特征,诗人的风格可以由这些特征反映;
- 同一位诗人的不同诗作风格是相似的。
此外,针对问题一补充以下3点假设:
- 诗的风格可以分为两类,唐诗和宋诗;
- 一个诗人的主要风格归属于两者之一;
- 诗人所处时代对诗人诗作风格有较为显著的影响。
针对问题二补充以下假设:
- 诗人的用词偏好一定程度上决定了诗人诗作的风格。
3. 数据探索与预处理
3.1 数据探索与预处理流程
首先对数据进行探索和预处理。附件数据为JSON格式,共包含唐诗文件58个、宋诗文件255个和唐宋诗作者生平简介文件各1个。为方便进行查看处理和统计分析,使用Python将唐诗、宋诗文件分别合并转换为DataFrame数据表格式。数据探索和预处理的流程如下图所示。
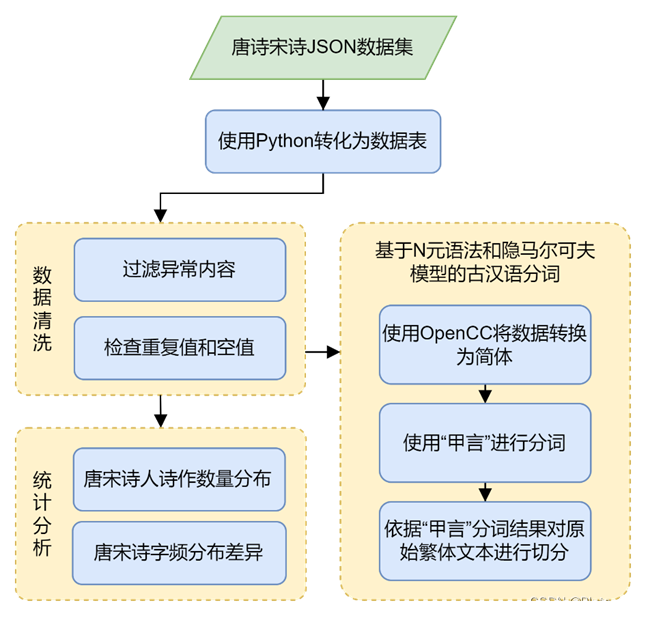
3.2 数据概况
唐宋诗数据表主要包括author、paragraphs、title等字段,唐宋诗作者数据表主要包括name、desc、id等字段,全部字段如下表所示。
| 数据表 | 字段 | 内容和类型 |
| 唐宋诗数据表 | author | 字符串类型,作者名 |
| paragraphs | 列表类型,列表每个元素为一句诗 | |
| title | 字符串类型,诗的标题 | |
| id | 字符串类型,诗的ID标识 | |
| tags | 列表类型,诗的标签 | |
| 唐宋诗作者数据表 | name | 字符串类型,作者名 |
| desc | 字符串类型,作者生平简介 | |
| id | 字符串类型,作者的ID唯一标识 |
唐宋诗数据为繁体字,由于简体和繁体字转换存在一对多的情况,可能丢失部分信息,为最大限度保持原文信息量,本文在分析时保留原始繁体字。
对全部数据进行统计,唐诗共收录57612首,宋诗共收录254248首。
3.3 数据清洗
数据中存在部分与诗歌本身无关的内容,包括注释、注解、整理者声明等(如下表所示),对后续分词词频统计和分析可能造成较大影响,因此首先进行数据清洗。
| 来源 | author | paragraphs | title |
| 《全唐诗》 | 王勃 | ['澗戶風前竹,山空月下琴。', '(項疑「山空」爲「山窗」之誤。', ')唯餘兩□□,應盡百年心。'] | 幽居(斯五五五。下同) |
| 魏奉古 | ['長安[二]桂殿倚空城,……[三]昔同今(八)屋,雲浮彫練此城[四]遊……] | 長門怨([一]伯三一九五二七四八) | |
| 《全宋诗》 | 扈蒙 | ['(以上劉瑛整理)。'] | 存目 其二 |
| 鄭將 | ['仲夏竹迷日,長竿带筍移。',…… '子猷清洒(鐸案:當爲酒)意,應與渭川期。'] | 和李侍郎移竹 |
上表所示为部分异常数据,对于各类括号采用正则表达式进行匹配过滤,正则表达式和清洗前后对比如下表所示。
| 清洗前(原文) | 清洗后 |
| ['澗戶風前竹,山空月下琴。', '(項疑「山空」爲「山窗」之誤。', ')唯餘兩□□,應盡百年心。'] | ['澗戶風前竹,山空月下琴。', '唯餘兩□□,應盡百年心。'] |
| ['長安[二]桂殿倚空城,……[三]昔同今(八)屋,雲浮彫練此城[四]遊……] | ['長安桂殿倚空城,……昔同今屋,雲浮彫練此城遊……] |
| ['(以上劉瑛整理)。'] | [] |
| ['仲夏竹迷日,長竿带筍移。',…… '子猷清洒(鐸案:當爲酒)意,應與渭川期。'] | ['仲夏竹迷日,長竿带筍移。',…… '子猷清洒意,應與渭川期。'] |
使用pandas.DataFrame的drop_duplicates()函数检查,不存在整行重复的数据。
3.4 统计分析
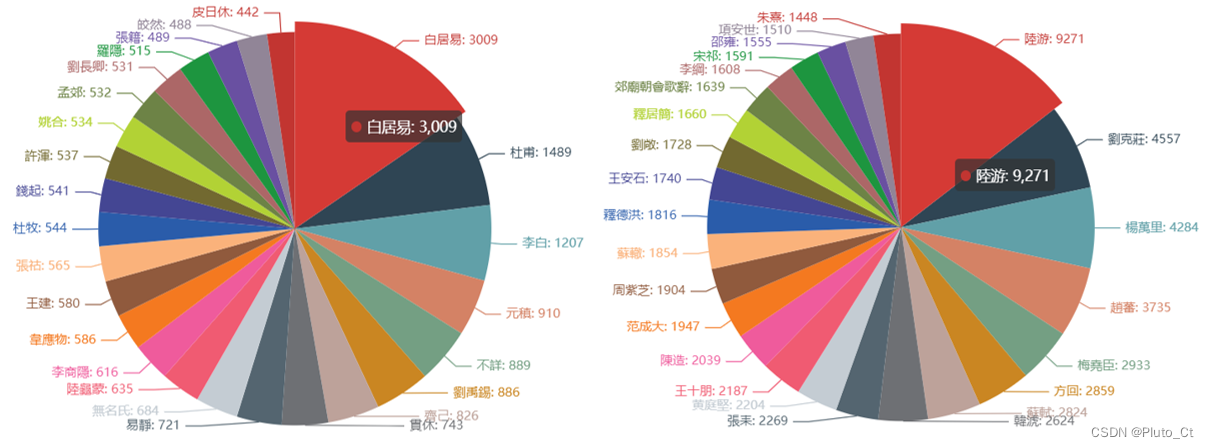
唐宋主要诗人诗作数如下图所示,《全唐诗》和《全宋诗》中收录作品最多的诗人分别为白居易和陆游。
分别统计唐诗和宋诗中的字频,唐宋诗字频最多的前6字相同,为“不、人、一、無、山、風”,唐诗“日”“云”“花”“水”“月”等自然意象出现较多,而宋诗“何”“如”“自”“生”“我”等说理常用字出现更为频繁。
| 诗的类别 | 高频字 |
| 唐诗 | 不、人、一、無、山、風、日、有、雲、來、天、中、何、時、上、花、水、爲、月、春 |
| 宋诗 | 不、人、一、無、山、風、有、來、天、何、日、如、自、生、中、時、年、雲、爲、我 |

3.5 基于“甲言”的古汉语分词
中文文本不存在单词的概念,但最小的语义单元可能是一个字,也可能是由多个字组成的词语,因此首先需要进行分词处理。在自然语言处理任务中,通常采用jieba、HanLP、SnowNLP等知名的第三方库进行分词处理,相关技术也已较为成熟;但古汉语在语法、语义等方面均与现代白话文有较大差别,因此采用这些基于现代汉语语料训练模型的分词工具无法得到较为满意的结果。
古诗中大多为单字词,但同时也存在不少连绵词、意象、典故等多字词语,仍然需要进行一定的分词处理再进行分析。因此,我们采用了开源的“甲言”项目[2]提供的古汉语分词方法,该项目基于N元语法和隐马尔可夫模型进行古汉语自动分词,并结合文言词典基于有向无环词图、句子最大概率路径和动态规划算法进行分词,经测试能够针对古汉语达到较好的分词效果。
由于甲言对简体语料的分词效果更好,我们使用OpenCC将数据中的繁体数据转为简体后再利用甲言进行分词;同时由于简繁字存在一对多的情况,为最大程度保留原文原貌,甲言分词结果不转换回繁体,而是基于甲言分词的分割位置对原文进行切分,达到对原文分词的效果;在提高分词准确度的同时完全保留了繁体原文的用字和含义。
在停用词处理上,我们删除了未被计算机识别的占位字符;“兮”“哉”等虽为无实意的虚词,但感叹词的数量很大程度上影响了诗的情感表达强度,因此我们对其予以保留。
4. 问题一的模型建立与求解
4.1 问题分析与思路
基于文论观点,唐诗和宋诗可以视作两种主要出现在唐代和宋代的风格,一个诗人的主要风格归属于唐诗或宋诗中的一种。我们认为,诗人所处的时代对诗人的风格具有显著影响,因此可以通过唐代、宋代诗人整体的诗作风格来定义“唐诗”“宋诗”的风格特征。
我们将建立一个指标体系对唐宋诗人的风格差异进行特征构造和量化,然后使用机器学习算法进行训练,选择最优模型用于评判诗人的风格归属,最后对模型进行效果评价。模型建立与求解流程如下图所示。
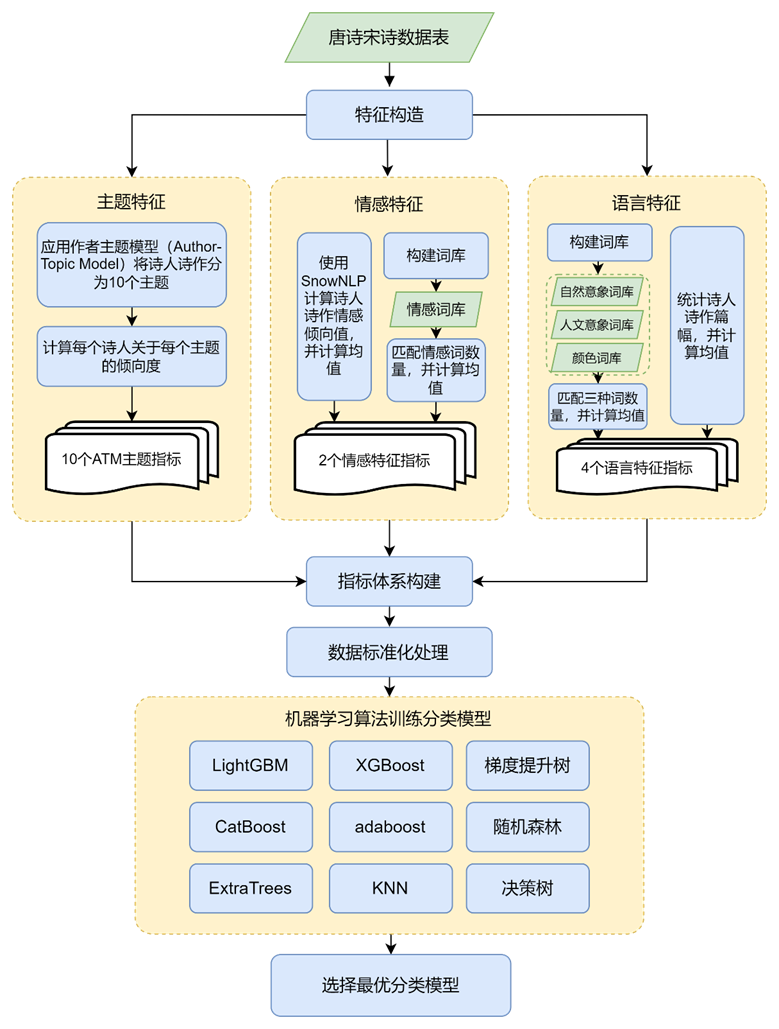
4.2 特征提取
4.2.1 作者主题模型(Author-Topic Model)
作者主题模型(Author-Topic Model, ATM)是一种概率主题模型,也是一项基于LDA主题模型(Latent Dirichlet Allocation)的拓展,能够对某个语料库中作者的写作主题进行分析,得出作者的写作主题倾向,并找到具有同样写作倾向的作者。
基于甲言分词结果,本文应用作者主题模型对诗人诗作进行主题分析,将诗人诗作分为10个主题,并依据每位诗人的诗作主题分布得到每位诗人对于每个ATM主题的主题倾向度,形成10个主题特征指标。
作者主题模型(Author-Topic Model)的Python Gensim实现 https://blog.csdn.net/u014111377/article/details/124883067运用Gensim中的AuthorTopicModel()类,基于唐宋诗作及其与诗人的对应关系语料,构建作者主题模型,并进行训练计算,模型结果如下表所示。
https://blog.csdn.net/u014111377/article/details/124883067运用Gensim中的AuthorTopicModel()类,基于唐宋诗作及其与诗人的对应关系语料,构建作者主题模型,并进行训练计算,模型结果如下表所示。
| ATM主题 | 主题相关字词TOP10及其权重 |
| 主题1 | 0.016*"兮" + 0.010*"死" + 0.005*"手" + 0.005*"要" + 0.005*"兒" + 0.004*"眼" + 0.004*"然" + 0.004*"口" + 0.004*"而" + 0.004*"汝" |
| 主题2 | 0.009*"說" + 0.007*"病" + 0.005*"付" + 0.004*"佛" + 0.004*"覺" + 0.004*"風流" + 0.004*"飽" + 0.004*"緣" + 0.004*"堪" + 0.004*"元" |
| 主题3 | 0.005*"疏" + 0.005*"懷" + 0.004*"民" + 0.004*"隠" + 0.004*"期" + 0.003*"幸" + 0.003*"况" + 0.003*"居" + 0.003*"謝" + 0.003*"俗" |
| 主题4 | 0.013*"先生" + 0.005*"山色" + 0.004*"總" + 0.004*"中原" + 0.004*"嗔" + 0.003*"借" + 0.003*"筆" + 0.003*"收" + 0.003*"茗" + 0.003*"打" |
| 主题5 | 0.005*"吟" + 0.004*"西風" + 0.003*"青山" + 0.003*"春風" + 0.003*"樹" + 0.003*"肯" + 0.003*"萬里" + 0.002*"歌" + 0.002*"一笑" + 0.002*"翁" |
| 主题6 | 0.013*"閒" + 0.005*"回" + 0.004*"歲月" + 0.004*"熟" + 0.003*"曉" + 0.003*"佳" + 0.003*"溪" + 0.003*"邊" + 0.003*"宮" + 0.003*"半" |
| 主题7 | 0.008*"僧" + 0.005*"竹" + 0.005*"靜" + 0.004*"句" + 0.004*"亭" + 0.004*"梅" + 0.004*"仙" + 0.004*"景" + 0.003*"味" + 0.003*"供" |
| 主题8 | 0.007*"神" + 0.005*"而" + 0.004*"于" + 0.004*"乃" + 0.004*"靈" + 0.004*"至" + 0.004*"哉" + 0.004*"或" + 0.003*"德" + 0.003*"既" |
| 主题9 | 0.007*"裏" + 0.005*"也" + 0.005*"一片" + 0.004*"底" + 0.004*"一聲" + 0.004*"紅" + 0.004*"無人" + 0.004*"脚" + 0.004*"邊" + 0.003*"黄金" |
| 主题10 | 0.004*"竹" + 0.004*"人間" + 0.004*"晚" + 0.004*"樹" + 0.004*"晴" + 0.004*"隠" + 0.003*"冷" + 0.003*"夕陽" + 0.003*"白雲" + 0.003*"眠" |
如上表,ATM模型将诗人诗作分为10个主题,每个主题分别包含了一些含义,例如主题10中“竹”“人间”“树”“晴”“夕阳”“白云”等多自然意象,且包含了“隐”等词语,可能为田园风光和隐居的描写,而主题5则包含“西风”“万里”等波澜壮阔的景象,可见不同主题间能够较好地反映诗人诗作风格的差异。
4.2.2 文本情感分析
文本情感分析,是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息,其主要任务就是对文本中的主观信息(如观点、情感、态度、评价、情绪等)进行提取、分析、处理、归纳和推理。
唐宋诗情感倾向存在一定的差异,因此本文采用SnowNLP中的sentiments进行文本情感值计算,用于评估诗人诗作的情感倾向,作为“情感特征”的一项指标。
4.2.3 词库建立与匹配
(1)情感词库
我们认为,诗作中情感词的多少决定了情感表达的强度,唐宋诗情感表达的强度存在一定的差异性。因此,建立情感词库用于匹配唐宋诗作中的情感词。结合礼记和中医理论,选择与诗最为贴切的情感,最终将诗的情感表达分为“喜、怒、哀、惧、爱、憎、思 ”七类;基于Word2Vec词向量查找与之相近的字词,并进一步通过人工筛选形成情感词库,用于判别诗作中是否存在较为强烈的情感表达。
使用情感词库对每首诗作进行匹配,计算每位诗人在每首诗中的情感词数量均值,作为该诗人的一项“情感特征”指标,部分情感词及其在唐宋诗中的字词频如下所示。
| 唐诗情感词TOP10 | 宋诗情感词TOP10 | ||
| 思 | 3028 | 樂 | 17996 |
| 樂 | 3006 | 好 | 11670 |
| 悲 | 2908 | 思 | 10243 |
| 愁 | 2562 | 喜 | 9765 |
| 好 | 2296 | 憂 | 9226 |
| 情 | 2195 | 嗟 | 8210 |
| 憂 | 1760 | 悲 | 8142 |
| 愛 | 1458 | 愁 | 7705 |
| 辭 | 1376 | 懷 | 6636 |
| 恨 | 1248 | 情 | 6494 |

(2)意象词库
古典诗歌的意象,主要包括自然意象和人文意象两类,自然意象是指日月星辰、山川风物等来源于自然界的意象,而人文意象是历史文化的意象,更多地体现在典故的引用上,唐宋诗在这两者的运用上有所差异。
唐诗以自然意象取胜,把自然意象与诗人强烈的现实感怀结合起来,表现清新刚健的时代精神,兴象玲珑,境界浑成;宋诗以人文意象取胜,以富有人文积淀色彩的典故、语码和充满才情智慧的议论表现渊雅不俗的人文情趣与修养,具有人文风采[6]。
因此,我们基于文献调研和资料整理,建立了自然意象和人文意象两个意象词库,用于对每首诗作进行匹配,分别计算每位诗人在每首诗中的自然意象和人文意象数量均值,作为该诗人的两项“语言特征”指标,部分意象词及其在唐宋诗中的字词频如下图所示。
| 自然意象 | 唐 | 宋 | 人文意象 | 唐 | 宋 |
| 竹 | 3356 | 14811 | 笛 | 376 | 1795 |
| 柳 | 2990 | 9484 | 蓬萊 | 256 | 1303 |
| 白雲 | 2510 | 6588 | 清明 | 144 | 868 |
| 魚 | 2165 | 10012 | 三尺 | 119 | 801 |
| 蘭 | 1698 | 5196 | 南浦 | 214 | 732 |
| 燕 | 1587 | 6295 | 寒食 | 222 | 730 |
| 蓮 | 1150 | 3112 | 重陽 | 138 | 714 |
| 芳草 | 982 | 2202 | 中秋 | 72 | 639 |
| 蟬 | 952 | 2034 | 長亭 | 118 | 484 |
| 明月 | 949 | 3170 | 方寸 | 113 | 424 |
(3)颜色词库
沈宗骞在《芥舟学画编》中曾说:“天下之物,不外形色。”色彩本身是没有情感的,由于诗人在运用的过程中赋予了自己的感情,色彩便有了生命的象征,正如王国维所说:“有我之境,以我观物,股物皆著我之色彩。”唐宋诗人十分注意现实生活中的各种色彩,并在作品中把这些色彩生动地表现出来。
本文选取白、黄、红、绿、黑五大色系建立颜色词库,分别计算每位诗人在每首诗中的颜色词数量均值,作为该诗人的一项“语言特征”指标。
4.2.4 篇幅统计
唐宋诗篇的格式和篇幅偏好有所差异,如“五言绝句”“五言律诗”“七言绝句”“七言律诗”等,《全唐诗》和《全宋诗》中也包含一些非常规篇幅的诗作,因此篇幅可能是唐宋诗存在差异的一项指标。
本文统计了每位诗人诗篇字数的均值,作为一项“语言特征”指标。
4.3 指标体系构建和指标值计算
在数据探索和文献调研的基础上,本文将唐宋诗人风格差异的特征表现概括为主题、情感、语言三大维度。其中,“主题特征”指诗人诗作的题材和表达的内容,“情感特征”指诗人诗作的情感倾向和表达情感的强度,“语言特征”指诗人诗作的诗篇长度和结构,以及使用意象、颜色等修辞描写手法的倾向。
基于上述“主题特征”“情感特征”“语言特征”三个维度构建诗人诗作风格特征指标体系如下表所示。
| 一级指标 | 二级指标 | 计算方法 |
| 主题特征 | ATM主题1 | 该诗人对于ATM主题1的倾向度 |
| ATM主题2 | 该诗人对于ATM主题2的倾向度 | |
| …… | …… | |
| ATM主题10 | 该诗人对于ATM主题10的倾向度 | |
| 情感特征 | 诗歌情感倾向 | 该诗人每首诗的情感倾向均值 |
| 情感词 | 该诗人每首诗中提到的情感词数量均值 | |
| 语言特征 | 人文意象 | 该诗人每首诗中提到的人文意象数量均值 |
| 自然意象 | 该诗人每首诗中提到的自然意象数量均值 | |
| 颜色词 | 该诗人每首诗中提到的颜色词数量均值 | |
| 篇幅 | 该诗人每首诗的字数均值 |
其中“主题特征”通过作者主题模型(Author-Topic Model, ATM)将所有诗作分为10个主题,并得出每位诗人对于每个主题的倾向度;“情感特征”中的“诗歌情感倾向”通过对每位诗人的诗作进行文本情感分析计算并求均值得到;情感词和“语言特征”中的人文意象、自然意象、颜色词通过词库匹配计算词频均值得到;篇幅为诗人每首诗的字数均值。
采用MinMax方法进行数据标准化。
4.4 机器学习分类算法测试与选择
基于模型假设,我们认为诗人诗作的风格与其所处时代有显著联系,因此可以使用机器学习算法训练分类模型,其自变量为每位诗人的风格特征指标值计算结果,因变量为诗人诗作风格(诗人所处朝代)。
使用SPSSPRO进行机器学习算法的应用与测试,选择较符合本研究目标的九种机器学习算法,按7:3划分训练集和测试集,并测试训练效果,九种机器学习算法在训练集和测试集上的表现如下表所示。
| 机器学习算法 | 训练集准确率 | 测试集准确率 |
| LightGBM | 0.906 | 0.837 |
| XGBoost | 0.992 | 0.825 |
| 梯度提升树 | 0.957 | 0.81 |
| CatBoost | 0.899 | 0.807 |
| adaboost | 0.816 | 0.804 |
| 随机森林 | 0.82 | 0.8 |
| ExtraTrees | 0.803 | 0.786 |
| KNN | 0.804 | 0.765 |
| 决策树 | 0.798 | 0.763 |
由上表可以发现,XGBoost和梯度提升树在训练集上的表现最好,分别达到了99.2%和95.7%,但测试集上的准确率与训练集差距较大,存在过拟合的情况。而LightGBM相比之下在训练集和测试集上都取得了较好的效果,在测试集上的表现为所有测试算法中最高,因此,选用LightGBM算法训练本文的诗作风格分类模型。
4.5 模型效果评价
本文基于三大维度16个指标构建了诗人诗作风格评价指标体系,采用LightGBM机器学习算法训练分类模型,训练得到的模型取得了较好的效果,具体模型特性与评价如下。
4.5.1 特征重要性排序
对16个特征进行重要性排序,结果如下图所示。
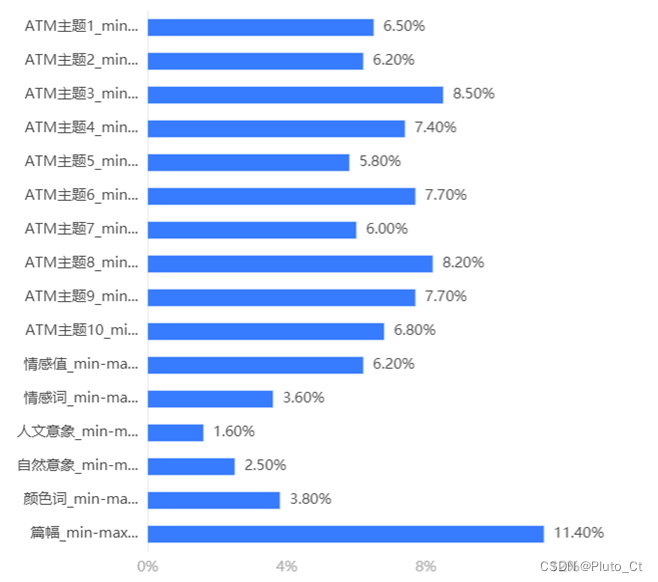
特征重要性排在前5位的分别为“篇幅”“ATM主题3”“ATM主题8”“ATM主题6”“ATM主题9”,说明诗人诗作的篇幅和ATM主题倾向对其风格影响较大;相较之下,人文意象、自然意象的数量对分类模型的影响较小,这可能是由于该列数据稀疏,即许多诗人没有诗作提到意象导致的。
4.5.2 混淆矩阵分析
混淆矩阵(Confusion Matrix)也称误差矩阵,是一种表示精度评价的标准格式,用n行n列矩阵表示。混淆矩阵的每一列代表了预测类别,总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,总数表示该类别的数据实例的数目。
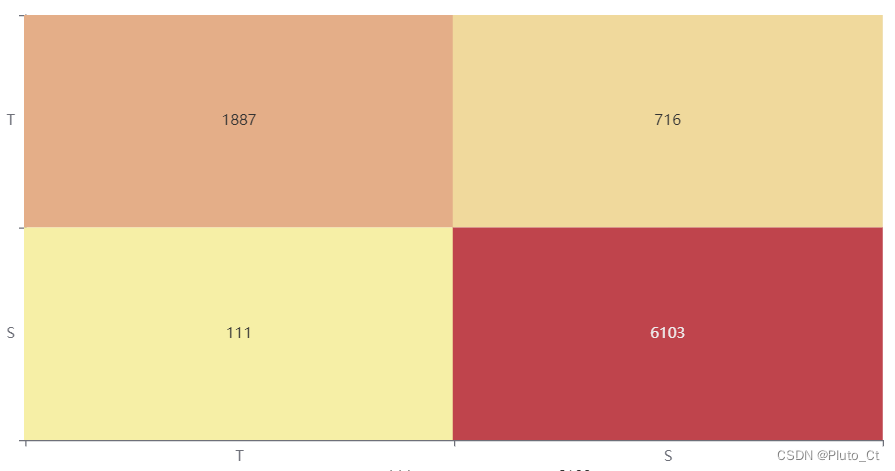
观察混淆矩阵热力图,模型对宋诗风格诗人的分类效果很好,对唐诗的分类效果较好。这可能是由于训练样本宋诗风格诗人的比例较大造成的,未来可通过调节样本比例进一步优化改进。
4.5.3 模型训练指标评价
模型在训练集和测试集上的表现如下表所示,在训练集和测试集上的准确率分别达到90.6%和83.7%,F1值分别达到0.902和0.826,能够较好地区分诗人的风格倾向。
| 准确率 | 召回率 | 精确率 | F1 | |
| 训练集 | 0.906 | 0.906 | 0.91 | 0.902 |
| 测试集 | 0.837 | 0.837 | 0.833 | 0.826 |
上表中展示了训练集和测试集的预测评价指标,通过量化指标来衡量LightGBM的预测效果。
由于诗人的风格倾向并不完全由时代决定,存在唐代诗人诗作风格倾向宋诗、宋代诗人诗作风格倾向于唐诗的情况,因此本模型在测试集上准确率达到83.7%,与训练集接近,已经较为充分地提取了唐宋诗人诗作的特征信息。
5. 问题二的模型建立与求解
5.1 问题分析与思路
为探究唐宋诗人诗作风格进一步细分的方法,我们通过两种不同的方式建立了两个不同粒度的诗人诗作风格细分模型。
其一,基于风格特征指标体系的K-Means聚类模型。基于问题一构建的诗人诗作风格特征指标体系,计算每位诗人的16个指标值,并将其进行标准化后作为聚类特征,运用K-Means聚类算法分别对唐宋诗人进行聚类。采用肘部法则和轮廓系数的方法,综合考虑数据集大小,将唐代诗人和宋代诗人分别聚为3类和8类,并根据聚类中心点对比分析每类诗人的特点,达到了较好的细分效果。
其二,基于用词倾向度的Single-Pass聚类模型。特征指标构造的过程中损失了一些文本信息量,对于更进一步地细分有所局限,我们基于诗人用词倾向度和文本相似度进行了更进一步细分的探索。首先计算反映诗人用词偏好的用词倾向度并筛选每位诗人的高倾向词。由于文本为非结构化数据,难以直接进行比较和计算,我们使用Word2Vec训练了针对古诗词的200维词向量,并运用基于余弦相似度的Single-Pass文本聚类算法对代表诗人的用词倾向度进行聚类,得到若干用词风格相似的诗人组,并将聚类结果与学者研究结论进行对比分析,达到了较好的进一步细分效果。
模型建立与求解流程如下图所示。
5.2 基于风格特征指标体系的K-Means聚类模型
5.2.1 K-Means聚类K值选取
根据肘部法则,随着聚类数K值的增大,SSE逐渐减小并趋于平稳。根据平均轮廓法,平均轮廓系数越大,说明聚类效果最好。由唐诗簇内误差平方和与轮廓系数图所示,SSE转折点较为隐蔽,但K值等于3时平均轮廓系数取得最大值,因此唐诗的最佳聚类数为3。
由宋诗簇内误差平方和与轮廓系数图所示,当K小于8时,随着K增大,SSE曲线斜率变化较大,当K大于8时,随着K增大,SSE曲线斜率变化减小并趋于平稳,且K=8时轮廓系数取得次大值,同时由于宋诗数据量大,相比唐诗包含的风格种类更多,因此宋诗的最佳聚类数为8。
5.2.2 K-Means聚类结果与分析
指标值经过Z-Score标准化处理,每一类别的数量和聚类中心点如下图所示。
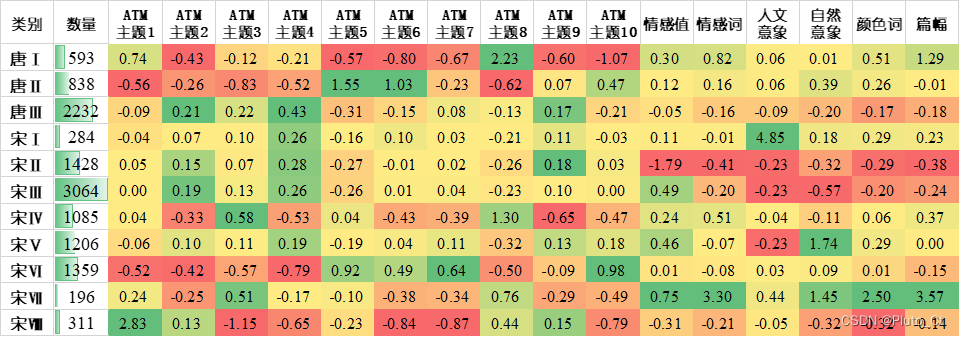
由图分析得知,聚类之后不同类别的唐、宋诗的差异较为显著。整体而言,唐诗中唐Ⅲ占比居多,宋诗中宋Ⅲ占比也为最大。其中,唐Ⅰ类别的诗以ATM主题8为主,情绪情感较为充沛,且篇幅为唐诗3类之最;唐Ⅱ以主题5和6为主,稍偏主题10;唐Ⅲ以主题4为主,其次为主题2和9。宋Ⅰ以主题4、9为主但风格以人文意象见长;宋Ⅱ以主题9为主,其次为主题2和4,情感特征和语言特征较少;宋Ⅲ以主题2和4居多,且情感较为充沛;宋Ⅳ以主题3和主题8为主,情绪情感;宋Ⅴ以主题4为主,情感值居高,且以自然意象见长;宋Ⅵ以主题7和10为主;宋Ⅶ以主题3为主,情感最为充沛,情绪饱满,且自然意象、颜色词使用较多,篇幅为唐宋诗之最;宋Ⅷ则以主题1为主。
5.3 基于用词倾向度的Single-Pass聚类模型
5.3.1 用词倾向度与风格
唐宋诗辅助研究的重要手段之一即为统计分析,可以通过词频反映作者对字词的使用偏好,进而分析词频与诗人风格之间的关系。但仅仅通过词频对诗人用词偏好的反映并不直观,因此本文参照胡俊峰[10]等人的研究,引入了“用词倾向度”的定义,其公式如下。
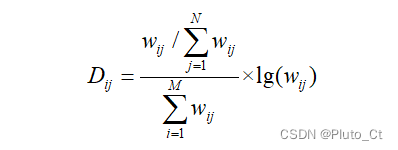
其中,wij表示第i个诗人使用第j个词的次数,N表示《全唐诗》《全宋诗》中总词数(包括单字词和多字词),M表示《全唐诗》《全宋诗》中诗人总数。
部分代表诗人用词倾向度排序结果如下表所示。
| 朝代 | 诗人 | 用词倾向度排序结果 |
| 唐代 | 杜甫 | 白帝 飜 巫峽 戎馬 顏色 飢 劒 江漢 黃 風塵 干戈 峽…… |
| 李白 | 黃鶴 黃金 秋浦 劒 黃河 猨 顏 金陵 妾 樓船 猛虎 青…… | |
| 元稹 | 春早 廻 耶 撩亂 邨 顏色 燄 潛 鬬 晝夜 劒 黃 漸 …… | |
| 陸龜蒙 | 魚戲 秖 蓮葉 祗 煙 檝 詞 強 煙霞 櫂 劒 弦 鬬 帶…… | |
| 李商隱 | 宓妃 鸎 黃昏 迢遰 佳期 帶 妬 宋玉 黃 玉樓 翡翠 鴛…… | |
| 杜牧 | 窓 戌 羽林 褭褭 斾 罇 故國 紅粉 微雨 髪 秪 強 隣…… | |
| 孟郊 | 魯山 視聽 常恐 賢人 顏 君子 結交 贈君 太行 始知 劒…… | |
| 皮日休 | 徵君 共君 太湖 秖 魯山 歘 華陽 移時 相向 白蓮 盡日…… | |
| 宋代 | 梅堯臣 | 大梁 嘗聞 太守 曷 慙 畏 翦 贈 美 洛陽 吳 儻 邀 …… |
| 蘇軾 | 巌 詩題 東坡 使君 嗟我 遥知 俯仰 逝 閱 首 作詩 我…… | |
| 歐陽修 | 眾 罇 嘉客 潁水 醉翁 京師 可愛 彊 鳥語 年少 嗟我 …… | |
| 陳師道 | 衝風 縮手 衰疾 潦倒 鳥雀 稍稍 稍 西方 向來 相忘 獨…… | |
| 楊萬里 | 半點 朶 儂 南溪 荆溪 它 水精 老夫 江西 忽然 渠 暄…… | |
| 王安石 | 低徊 鍾山 咏 投老 柴荆 塵沙 洲渚 溝 陳迹 邂逅 岡 …… | |
| 文天祥 | 楚囚 牢愁 睢陽 銅駝 燕山 魂魄 烈士 孤臣 囚 忠臣 柰…… | |
| 陳與義 | 鄧州 麯 繩床 歲暮 衡山 綸巾 倚杖 竹籬 湖南 光景 莽…… |
5.3.2 Word2Vec词向量训练和词嵌入
文本作为非结构化数据,难以直接进行比较和计算。Word2Vec可以将文本转换为向量的形式,方便衡量不同文本之间的相似程度。Word2Vec模型的字词与向量对应关系需要通过训练得到。
我们基于《全唐诗》《全宋诗》全部诗句的语料,在甲言分词的基础上使用Gensim进行词向量训练,得到一个200维的词向量,可以将诗句中的字词映射到向量,从而进行进一步的分析计算。
5.3.3 Single-Pass聚类算法
Single-Pass聚类算法是一种基于余弦相似度的短文本聚类算法,采用增量聚类的方式将文本向量与已有话题内的内容进行比对,计算文本相似度进行匹配。若与某个话题类别匹配,则把该文本归入该话题,若该文本域所有话题类别的相似度均小于某一阈值,则将该文本表示成新的种子话题。Single-Pass聚类算法步骤如下[12]:1) 输入新文档d;2) 计算d与已有话题分类中每篇文档的相似度,获取与d相似度最大的话题并得到相似度值T;3) 若T大于阈值θ,则文档d被分类到已知的话题类别,否则作为一个新的话题类别;4) 聚类过程结束。
本文采用Single-Pass算法用于对诗人高倾向词的聚类。
5.3.4 Single-Pass聚类参数选择
经过文献调研,本文选取唐朝代表诗人37位,宋诗33位,具体名单及选取依据详见附录。我们采用Single-Pass算法对诗人的用词偏好特征进行聚类,得到若干用词风格相似的诗人组。分别选用不同的参数和阈值进行选词和聚类,得到不同的结果对比分析如下图所示。
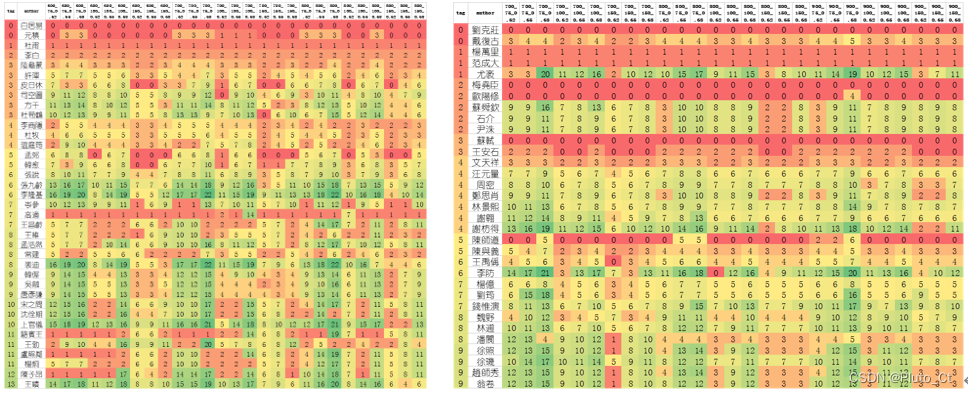
通过与学者研究的诗人派别进行比较,参考唐宋诗语料库大小的影响,选择结果较好的参数作为模型的最终参数,其中:针对唐代诗人,选用频数前600的字词参与用词倾向度进行计算,选择其中用词倾向度前150的词语进行词嵌入和相似度聚类;针对宋代诗人,选用频数前800的字词参与用词倾向度进行计算,选择其中用词倾向度前100的词语进行词嵌入和相似度聚类;聚类阈值均选用0.65。
5.3.5 Single-Pass聚类结果分析
由最佳阈值得出的Single-Pass聚类结果如下。
| 类别 | 诗人 |
| 1 | 白居易、元稹、皮日休、孟郊、韓愈 |
| 2 | 杜甫、高適 |
| 3 | 李白、陸龜蒙、常建、 |
| 4 | 許渾、李商隱、杜牧、溫庭筠、韓偓、吳融、唐彥謙、 |
| 5 | 張說、沈佺期、陳子昂 |
| 6 | 司空圖、方干、杜荀鶴、李隆基、裴迪 |
| 7 | 岑參、王昌齡、王維、孟浩然、宋之問、駱賓王、盧照鄰、楊炯 |
| 8 | 張九齡 |
| 9 | 王績 |
| 10 | 上官儀、王勃 |
唐代部分代表诗人“用词倾向度-Single-Pass聚类”结果如上表所示,第一类中,白居易与元稹同属“元白诗派”,孟郊、韩愈属于“韩孟诗派”,这两个诗派的用词倾向具有一定的相似性;第五类中司空图、方干、杜荀鹤同属隐逸冲淡诗派,与学者研究结论一致。
第七类中,岑参、王昌龄同属边塞军旅诗派,王维、孟浩然同属山水田园诗派,骆宾王、卢照邻、杨炯则同属于士人诗派,这三者都被聚了出来,但尤其山水田园诗和另两种存在较大的差异性,说明基于用词倾向的聚类对于同类诗人效果良好,但可能将不同类聚到一起,需要结合其他因素共同考虑和评判。
| 类别 | 诗人 |
| 1 | 劉克莊、梅堯臣、歐陽修、蘇軾、陳師道 |
| 2 | 楊萬里、范成大 |
| 3 | 王安石、文天祥 |
| 4 | 戴復古、陳與義、潘閬 |
| 5 | 王禹偁、魏野 |
| 6 | 楊億、劉筠 |
| 7 | 汪元量、謝翱 |
| 8 | 周密、林景熙、徐璣 |
| 9 | 蘇舜欽、石介、尹洙、鄭思肖 |
| 10 | 林逋、徐照、趙師秀、翁卷 |
| 11 | 錢惟演 |
| 12 | 尤袤、謝枋得 |
| 13 | 李防 |
宋代部分代表诗人“用词倾向度-Single-Pass聚类”结果如上表所示,第二类中,杨万里、范成大同属中兴四大诗人诗派,第七类中的汪元量、谢翱同属遗民诗派,第九类中苏舜钦、石介、尹洙同属复古诗派。
与唐代相同,基于用词倾向的聚类对于同类诗人效果良好,但可能将不同类聚到一起,需要结合其他因素共同考虑和评判。
5.4 模型总结与对比
本研究分别基于风格特征指标体系和用词倾向度提出了两种不同粒度的诗人诗作风格细分模型。
其中,基于风格特征指标体系的K-Means聚类模型是面向全数据集的细分探索,依据指标体系的数值进行聚类和分析,将唐诗和宋诗分别细分为3类和8类,是一个较为宏观的风格细分方法,聚类中心点坐标在指标体系上的位置可以在一定程度上反映该细分类别的核心风格特点。
而基于用词倾向度的Single-Pass聚类模型,直接引入了信息量更为全面的文本信息,并提出“用词倾向度”作为文本的增强优化方法,实现了对于唐宋诗人诗作风格的更进一步细分,同时经过与部分代表诗人的学者研究结论进行对比分析,模型较为有效,但也存在一些改进空间。
两个模型各有优势,在不同的粒度上对唐宋诗的风格进行了细分。
6. 问题三的模型建立与求解
6.1 问题分析与思路
问题三基于问题二中构建的K-Means聚类模型进行代表诗人选取。本文问题二已经构建出两个聚类模型,一是基于风格特征指标体系的K-Means聚类模型,另一个是基于用词倾向度的Single-Pass聚类模型。前者的聚类特征包含主题、情感、语言三大维度,较为全面,而后者的聚类特征为文本相似度,是用词特征的深入研究。考虑到风格聚类的全面性,本文依据K-Means聚类模型的结果作为风格子类进行代表诗人和诗作的选取。
本题解决与评价流程如下图所示。
6.2 代表诗人选取结果
选取唐、宋诗三种风格代表诗人20位如下表所示,诗人代表诗作和选择依据(与聚类中心的距离)略。
| 唐Ⅰ | 唐Ⅱ | 唐Ⅲ |
| 白元鑒 | 盧綸 | 衛準 |
| 劉禹錫 | 捧劒僕 | 鄧廷聞 |
| 張祜 | 楊凝 | 張敬之 |
| 崔詞 | 周繇 | 朱勰 |
| 楊真人 | 章孝標 | 法滿 |
| 朱評之 | 李益 | 曾扈 |
| 高宗皇帝李治 | 丁位 | 香兒 |
| 貞素 | 劉威 | 次休 |
| 延壽 | 牛希濟 | 周顓 |
| 陳元光 | 戴叔倫 | 崔懷寶 |
| 周朴 | 曹松 | 章碣 |
| 柳宗元 | 李羣玉 | 畢誠 |
| 金地藏 | 張喬 | 金可紀 |
| 陶彝之 | 虛中 | 蔣氏 |
| 殷潛之 | 李商隱 | 景龍文館學士 |
| 李翔 | 譚用之 | 胥偃 |
| 王孝廉 | 修睦 | 利涉 |
| 豆盧回 | 許渾 | 肅宗 |
| 林暈 | 于興宗 | 李善寧之子 |
| 王周 | 李涉 | 梁陟 |
| 宋Ⅰ | 宋Ⅱ | 宋Ⅲ | 宋Ⅳ | 宋Ⅴ | 宋Ⅵ | 宋Ⅶ | 宋Ⅷ |
| 何新之 | 潘鄭臺 | 趙士宇 | 葉夢得 | 王嚮 | 毛珝 | 曾原郕 | 釋法薰 |
| 王漁壑 | 徐忻 | 釋洪海 | 程公許 | 鮮于至 | 張伯玉 | 李師聖 | 釋慧方 |
| 衡泌 | 張一齋 | 余亢 | 洪炎 | 劉彥朝 | 鄧深 | 范良龔 | 釋懷深 |
| 程壯 | 釋法顯 | 杜師旦 | 葛勝仲 | 沈安義 | 王志道 | 陳允升 | 釋嗣宗 |
| 余力齋 | 皇甫韶 | 釋圓照 | 晁補之 | 楊元量 | 史彌寧 | 林夔孫 | 釋文禮 |
| 王伯淮 | 何甫 | 周光嶽 | 劉子寰 | 吳球 | 楊冠卿 | 趙彥假 | 釋智愚 |
| 劉師忠 | 吳弘鈺 | 馮開元 | 孔平仲 | 謝逵 | 余靖 | 頓起 | 釋清了 |
| 蔣夢炎 | 杜範兄 | 張仲武 | 張方平 | 胡宗哲 | 潘檉 | 孫漸 | 釋自齡 |
| 翁甫 | 崖州女子 | 何權 | 吳潛 | 姚愈 | 王安國 | 龔復 | 釋宗演 |
| 桂聞詩 | 徐遜綿 | 劉文毅 | 王信 | 黄希武 | 趙汝鐩 | 徐大忠 | 釋文準 |
| 袁思永 | 趙子泰 | 高衡 | 馬之純 | 楊本然 | 楊公遠 | 趙宗德 | 釋咸靜 |
| 丘岳 | 趙逵 | 趙師固 | 曹彥約 | 閻彥昭 | 王安中 | 周晞稷 | 釋智朋 |
| 醉道人 | 蕭克翁 | 蔡崑 | 洪皓 | 富嚴 | 戴復古 | 倪德元 | 釋道川 |
| 陳仲諤 | 周吟軒 | 布衣某 | 李曾伯 | 蓋嶼 | 袁說友 | 蜀翁 | 釋法一 |
| 釋寶玄 | 忘懷老人 | 林應隆 | 趙燁 | 陳逢辰 | 張榘 | 郭波 | 釋鼎需 |
| 袁立儒 | 竺大本 | 劉三戒 | 方鳳 | 朱承祖 | 戴昺 | 唐耜 | 釋了朴 |
| 王毖 | 陳熊 | 吳白 | 張琮 | 趙汝旗 | 張藴 | 朱震 | 釋守珣 |
| 開先長老 | 洪天錫 | 貢宗舒 | 陳棣 | 趙善宣 | 曹勛 | 潘景良 | 李昴英 |
| 趙師聖 | 釋雲林 | 陳貴誠 | 王邁 | 徐文瀾 | 初惟深 | 謝璡 | 釋智深 |
| 釋正韶 | 黄岳年 | 虞薦發 | 曾班 | 王希旦 | 黄彥平 | 汪泌 | 釋紹隆 |
6.3 代表诗人选取结果分析
| 类别 | 代表诗人 | 主要特征指标 | 风格特点 |
| 唐Ⅰ | 刘禹锡,张祜,柳宗元,周朴 | 主题8,情感词,篇幅 | 风情俊爽,意象功力很深,苦涩,清冷峭拔 |
| 唐Ⅱ | 卢纶,章孝标,李益 | 主题5、6 | 雄浑慷慨,意境开阔 |
| 唐Ⅲ | 章碣 | 主题4 | 风雅著称 |
| 类别 | 代表诗人 | 主要特征指标 | 风格特点 |
| 宋Ⅰ | 蒋梦炎,袁思永,袁立儒,陈仲谔,释宝玄 | 主题4、9,人文意象 | 以人文意象见长 |
| 宋Ⅱ | 赵逵,周吟轩,吴弘钰,皇甫韶,徐忻 | 主题9,情感值、情感词较少 | 自然、豁达,以说理为主 |
| 宋Ⅲ | 余亢,周光岳,冯开元刘三戒 | 主题2、4,情感值 | 诗歌情感较为感伤低沉 |
| 宋Ⅳ | 叶梦得,葛胜仲,晁补之,孔平仲,吴潜 | 主题3、8 | 诗歌格调豪爽, |
| 宋Ⅴ | 吴球,谢逵,胡宗哲,阎彦昭,陈逢辰 | 主题4,情感值,自然意象 | 描写景物较多,以自然意象见长 |
| 宋Ⅵ | 邓深,余靖,潘柽,王安国 | 主题7、10 | 诗人多为在朝官员,为人清廉,气节甚伟,多用白描,重说理 |
| 宋Ⅶ | 赵彦假,孙渐,周晞稷,唐耜,唐耜,潘景良 | 主题3,情感值、情感词、自然意象、颜色词、篇幅 | 诗作多为歌行体,用词或淡婉工雅,或豪放雄奇 |
| 宋Ⅷ | 釋法薰,釋慧方,釋懷深,釋嗣宗,釋文禮 | 主题1 | 诗作内容多为僧侣记录日常生活,语言富有禅意,且不局限于格式,多为四六字 |
7. 模型评价与推广
7.1 模型的优点
本文对于唐宋诗人诗作风格的差异进行了定量分析与比较研究,本文建立的模型具有以下优点:
数据预处理阶段:
1)对于古诗而言,面向古汉语的“甲言”分词,能够达到相较于面向现代汉语的Jieba等常用分词工具更好的分词效果;
2)本文在分词过程中没有直接应用简繁转换,最大程度地保留了繁体原文的用字和信息量。
以上两点为后续分析的准确性提供了较好的基础。
针对问题一的模型:
1)本文应用作者主题模型、文本情感分析等方法,对非结构化的文本数据进行较深的挖掘,提取了较多文本中包含的信息;
2)结合主题、情感、语言3个维度进行量化和模型训练,对风格的概括较为全面。
针对问题二和三的模型:
1)本文分别基于唐宋诗人诗作风格特征指标体系和用词倾向度进行了聚类挖掘,在不同粒度上达到了对唐宋诗人诗作风格进一步细分的目标;
2)聚类中心点坐标值与ATM主题等指标的对应关系具有可解释性,能够对每个细分类别的风格进行总结和对比分析。
7.2 模型的不足之处与未来展望
同时,本文模型也存在一些不足之处:
1)问题一对风格的特征提取仍有改进空间,例如部分特征与篇幅相关性较大,取其与篇幅的商可能得到更为有效的特征指标;
2)问题三在代表诗人诗作的选取中仅考虑了其与聚类中心的距离,结合诗人诗作数量等因素可能得到更有代表性的结果。
7.3 模型推广
本文模型主要针对唐宋诗的风格差异展开研究和分类,模型可进一步推广到其他分类面,例如诗人地域、身份等;也可向其他文体进行推广,例如对不同时代、不同地域的文言文进行分析和分类等。
8. 参考文献
[1] 王培友.唐宋诗之争、宋贤精神及宋诗文化生态研究的理论思考[J].中国文化研究,2014(01):71-85.DOI:10.15990/j.cnki.cn11-3306/g2.2014.01.005.
[2] Jiaeyan. 甲言Jiayan[EB/OL]. https://github.com/jiaeyan/Jiayan, 2022-4-10.
[3] 流浪集. 隐马尔可夫模型(HMM)中文分词[EB/OL]. https://www.cnblogs.com/leeshine/p/5804679.html, 2016-09-24.
[4] Rosen-Zvi M, Griffiths T, Steyvers M, et al. The Author-Topic Model for Authors and Documents[J]. AUAI Press, 2012.
[5] Corina. Python SnowNLP 基于情感词典的情感分析[EB/OL]. 2020-05-20.
[6] 杨筱燕. 浅析唐宋诗之分[J].新西部(下半月),2008(12):120-121.
[7] Microstrong. 深入理解LightGBM[EB/OL]. https://zhuanlan.zhihu.com/p/99069186, 2020-01-06.
[8] 刘建平Pinard. K-Means聚类算法原理[EB/OL]. https://www.cnblogs.com/pinard/p/6164214.html, 2016-12-12.
[9] 刘金超DT. K-Means中K值的选取[EB/OL]. https://blog.csdn.net/weixin_45399233/article/details/101942911, 2019-10-02.
[10] 胡俊峰,俞士汶.唐宋诗之计算机辅助深层研究[J].北京大学学报(自然科学版),2001(05):727-733.DOI:10.13209/j.0479-8023.2001.126.
[11] 好好先生. 小白看Word2Vec的正确打开姿势|全部理解和应用[EB/OL]. https://zhuanlan.zhihu.com/p/120148300, 2020-03-29.
[12] 格桑多吉,乔少杰,韩楠,等. 基于Single-Pass的网络舆情热点发现算法[J]. 电子科技大学学报, 2015, 44(04): 599-604.
9. 比赛总结与启示
第一阶段由于时间把控的问题未能取得很好的结果,在方案思考时过于发散以至于来不及完成论文;第二阶段改变了策略,在第一阶段研究积累和经验的基础上快速明确问题,参考了优秀论文的篇章结构和图表绘制,将更多时间花在解决问题和结果呈现上,更完整地呈现了方案的内容和包括第一阶段在内的工作,也算是弥补了遗憾。
最后
以上就是失眠电灯胆最近收集整理的关于2022SPSSPRO认证杯数学建模B题第二阶段方案及赛后总结:唐宋诗的定量分析与比较研究1. 问题重述2. 模型假设3. 数据探索与预处理4. 问题一的模型建立与求解5. 问题二的模型建立与求解6. 问题三的模型建立与求解7. 模型评价与推广8. 参考文献9. 比赛总结与启示的全部内容,更多相关2022SPSSPRO认证杯数学建模B题第二阶段方案及赛后总结:唐宋诗的定量分析与比较研究1.内容请搜索靠谱客的其他文章。








发表评论 取消回复