讲解目录
- 问题C 机场的出租车问题
- 一、通过题目我们得知:
- 二、通过论文摘要我们得知:
- 三、第一题解析
- 问题重述对第一题的描述
- 问题分析对第一题的描述
- 问题一的模型建立与求解
- 四、第二题解析:
- 问题重述对第二题的描述
- 问题分析对第二题的描述
- 问题二的模型建立与求解
- 五、第三题解析:
- 问题重述对第三题的描述
- 问题分析对第三题的描述
- 问题三的模型建立与求解
- 六、第四题解析:
- 问题重述对第四题的描述
- 问题分析对第四题的描述
- 问题四的模型建立与求解
- 七、模型检验:
- 八、模型评价:
问题C 机场的出租车问题
quad
大多数乘客下飞机后要去市区(或周边)的目的地,出租车是主要的交通工具之一。国内多数机场都是将送客(出发)与接客(到达)通道分开的。送客到机场的出租车司机都将会面临两个选择:
quad
(A) 前往到达区排队等待载客返回市区。出租车必须到指定的“蓄车池”排队等候,依“先来后到”排队进场载客,等待时间长短取决于排队出租车和乘客的数量多少,需要付出一定的时间成本。
quad
(B) 直接放空返回市区拉客。出租车司机会付出空载费用和可能损失潜在的载客收益。
quad
在某时间段抵达的航班数量和“蓄车池”里已有的车辆数是司机可观测到的确定信息。通常司机的决策与其个人的经验判断有关,比如在某个季节与某时间段抵达航班的多少和可能乘客数量的多寡等。如果乘客在下飞机后想“打车”,就要到指定的“乘车区”排队,按先后顺序乘车。机场出租车管理人员负责“分批定量”放行出租车进入“乘车区”,同时安排一定数量的乘客上车。在实际中,还有很多影响出租车司机决策的确定和不确定因素,其关联关系各异,影响效果也不尽相同。
quad
请你们团队结合实际情况,建立数学模型研究下列问题:
quad
(1) 分析研究与出租车司机决策相关因素的影响机理,综合考虑机场乘客数量的变化规律和出租车司机的收益,建立出租车司机选择决策模型,并给出司机的选择策略。
quad
(2) 收集国内某一机场及其所在城市出租车的相关数据,给出该机场出租车司机的选择方案,并分析模型的合理性和对相关因素的依赖性。
quad
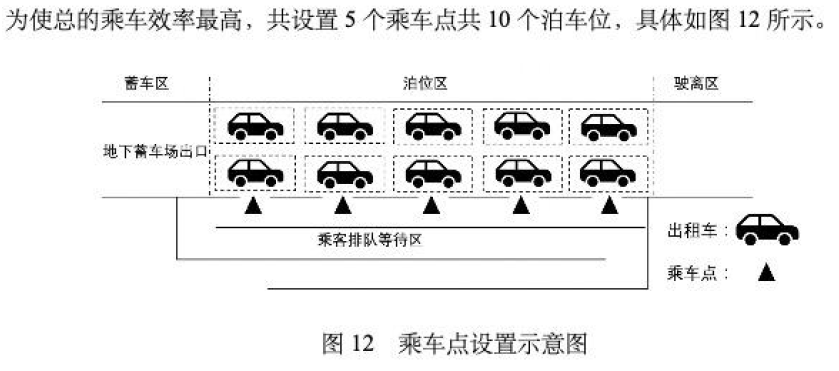
(3) 在某些时候,经常会出现出租车排队载客和乘客排队乘车的情况。某机场“乘车区”现有两条并行车道,管理部门应如何设置“上车点”,并合理安排出租车和乘客,在保证车辆和乘客安全的条件下,使得总的乘车效率最高。
quad
(4) 机场的出租车载客收益与载客的行驶里程有关,乘客的目的地有远有近,出租车司机不能选择乘客和拒载,但允许出租车多次往返载客。管理部门拟对某些短途载客再次返回的出租车给予一定的“优先权”,使得这些出租车的收益尽量均衡,试给出一个可行的“优先”安排方案。
quad
quad
一、通过题目我们得知:
① 此题无附录数据,我们要自己爬取数据
② A选择是直接回市区,消耗了回市的时间和找客的时间
③ B选择是在机场拉客,消耗了排队的时间
【本论文自定义隐藏条件】
④ 司机当前的位置在机场
⑤ A选择回市区可以能拉多单客人
⑥ B选择一次只能拉一单客人(一单客人可能有多个乘客)
【详细说明】
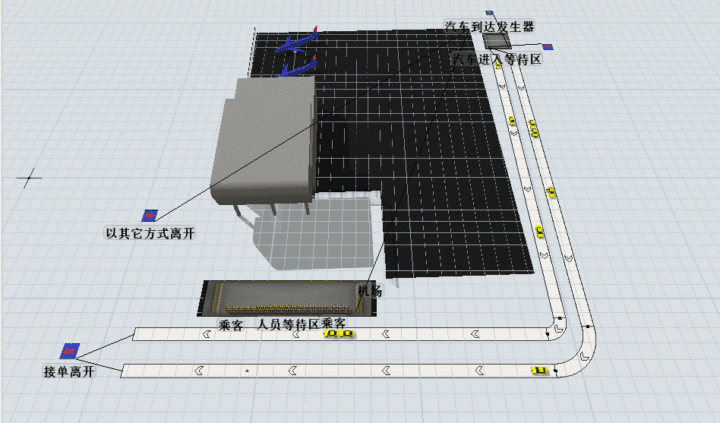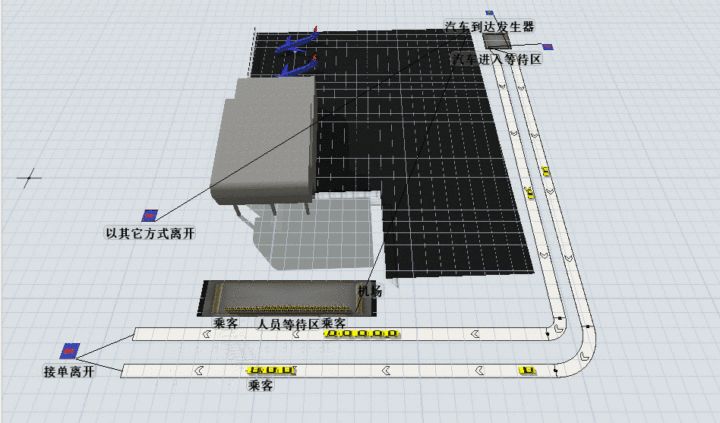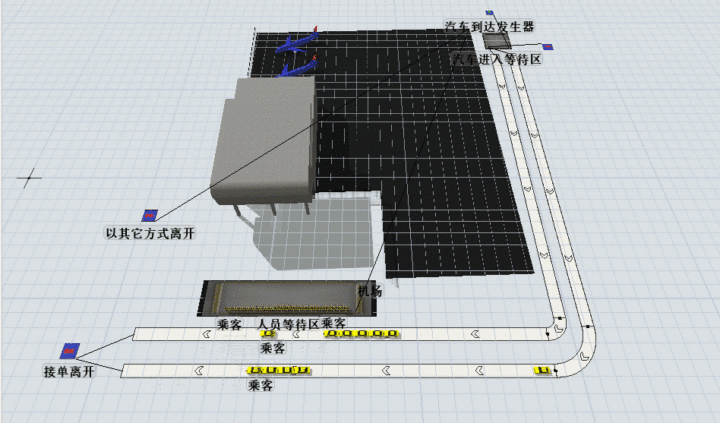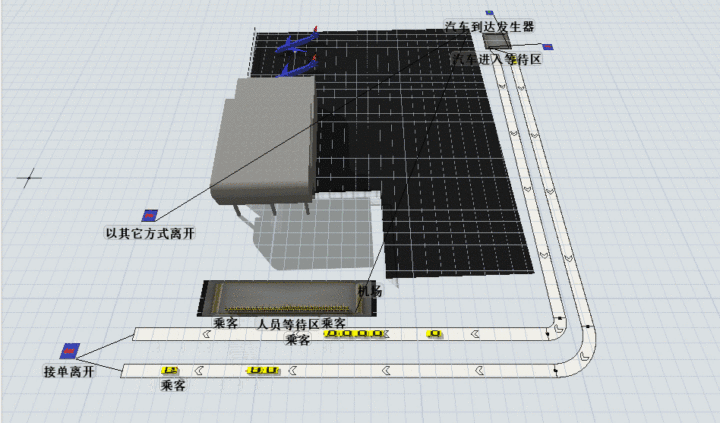
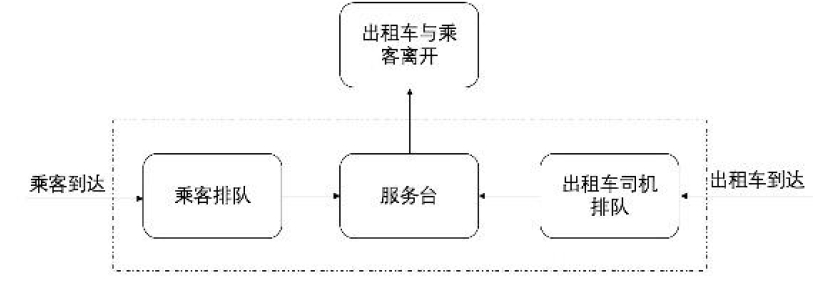
司机选择B的路线可以这个图演示(知乎偷的),大致意思即司机要先进入蓄车池,再排队等候乘客上车,最后送乘客到达目的地
司机选择A的路线可以直接用一句话表示:回市区拉客,且不止一单乘客
二、通过论文摘要我们得知:

① 本题选择的是上海浦东机场的数据
② 论文第一问只用了公式,并没有进行数值计算
③ 论文第二问是根据出租车司机的净收益对比而选择方案AB
④ 论文第三问用到了蒙特卡洛模拟
⑤ 论文第四问用的方法和第二问类似
三、第一题解析
问题重述对第一题的描述
分析与出租车司机决策相关因素的影响机理,建立出租车司机选择决策模型,给出司机的选择策略
问题分析对第一题的描述


问题一的分析可以看成由三个部分组成:重述+相关文献+做题思路
重述:题目内容和问题一重述内容的再放送
相关文献:分析了司机主观分析、司机空车时寻客行为、客流规律等一系列的论文,最后说了句:与问题一关系不大(我怀疑这些就是他们查找论文时遇到和题目没关系的论文,想着不能浪费,于是就搬上来了)
做题思路:问题一的解题流程
问题一的模型建立与求解
一般人看到决策模型就会想层次分析法,但这篇论文第一问却是列了一堆公式,选择最后收益最高的方案,这样做的目的是为了在做完第一问的同时也做了第二问,因为第二问就是分析某个机场并给出选择的方案
【模型】
① 综合考虑其时间成本以及收益,以单位时间的收益为依据为出租车司机做出选择策
② 对于排队载客返回市区,我们利用排队论的知识衡量出租车司机的等待时间
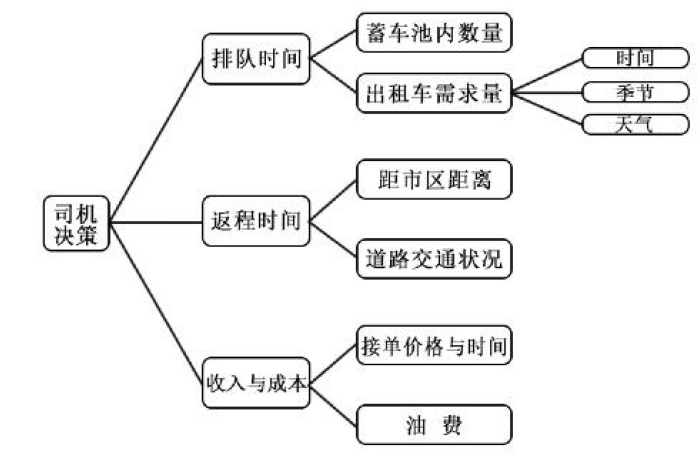
先给出一张类似于层次分析法的流程图,看似接下来要按照流程图给出相应公式,但是并非如此,他只是单纯的放了这张图罢了,接下来的公式用的却是另一套逻辑理论,我整理出来如下:


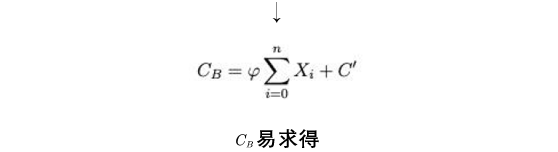
【论文公式解析】
选择A的时间消耗流程(
t
A
t_A
tA)
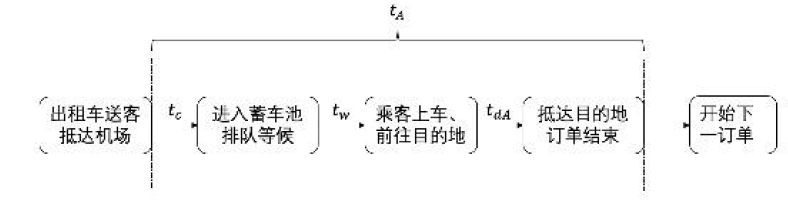
选择B的时间消耗流程(
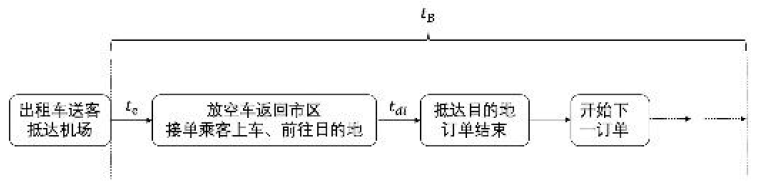
t
B
t_B
tB)
出租车
t
t
t 时刻的需求量(
P
r
(
t
)
P_r(t)
Pr(t))
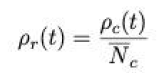
解析:所求的
P
r
(
t
)
P_r(t)
Pr(t) 实际上是选择A中的公式,或者说其实流程图中有关排队时间讲的全是选择A
基于生灭过程下选择A的时间损耗(
t
l
t_l
tl)
解析:生灭过程属于排队论中的知识,所求的
t
l
t_l
tl 相当于排队时长,生灭过程的具体思路如下图 (我没看懂) ,他应该是查资料得出的这些公式,实际运用过程中并没有起到太大作用(比如第二问),但可以放在论文第一问中语文建模,显得高端

单位时间选择A的收益(
△
E
A
triangle E_A
△EA)
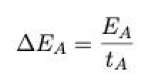
单位时间选择B的收益(
△
E
B
triangle E_B
△EB)
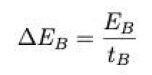
基于收益的决策模型
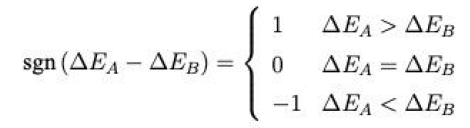
解析:这个很好理解,他这样可能是为了表达的更直观(高端)
【排版】
问题一的排版非常厉害,下图是问题一的目录,从中我们看出他采用了总分中的格式:先说明了影响决策的因素,再逐一给出相关因素的公式,最后将公式合并起来进行整体解释。厉害就厉害在:虽然选择AB的方案所用到的公式不完全相同,但他就是能将全部公式整齐有序的罗列出来,给人一种按照流程图写出来的感觉,而且每个公式间连接紧密、浅显易懂,排版的非常自然

四、第二题解析:
问题重述对第二题的描述
收集国内某一机场及其所在城市出租车的相关数据,给出该机场出租车司机的选择方案,并分析模型的合理性和对相关因素的依赖性
问题分析对第二题的描述

从第二题的问题重述和问题分析我们可以得知:
① 我们要选择一个机场。这意味着我们得从网上爬取这个机场的相关信息,也说明我们必须选择客流量很多的机场,这样才能便于分析和确保准确性
② 给出该机场出租车司机的选择方案。 与第一问不同的是,第二问要求我们计算,但没关系,因为第一问公式已经列出来了,我们直接套进去算就好了
③ 分析模型的合理性和对相关因素的依赖性。 要求我们最后还得验算模型;至于对相关因素的依赖性,我一开始想到的是回归的系数分析,但本论文用的不是回归,他用的是按百分比改变不同参数的值,看最终结果的百分比变化
问题二的模型建立与求解
论文选择的是上海浦东国际机场,他爬取的数据可能只有机场航班的到达量分布(后面会说为什么只有一组数据),从他问题二的代码中也能发现他并不是完全套用问题一的公式,他极大的简化了问题一的公式,也另加了一些变量(对比他列出的符合表可知)
【爬取数据】
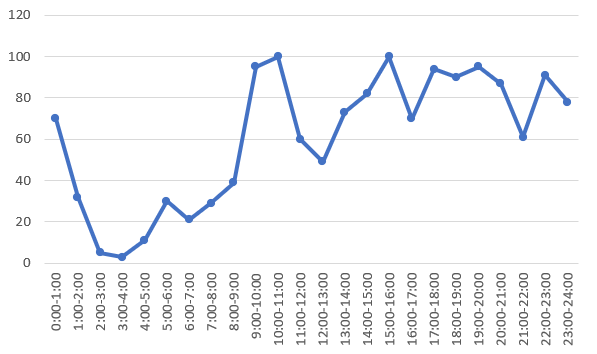
其实数据也不算爬取吧,毕竟数据量明显非常少,可以选择手抄的:下面是我从知乎偷来的机场航班的到达量分布数据,并做成了 Excel 图表,横坐标是24小时,纵坐标是各时间段航班到达量
【模型一】
也许你会好奇论文中的图(如下图)是从哪里来的,是不是另外爬取来的?
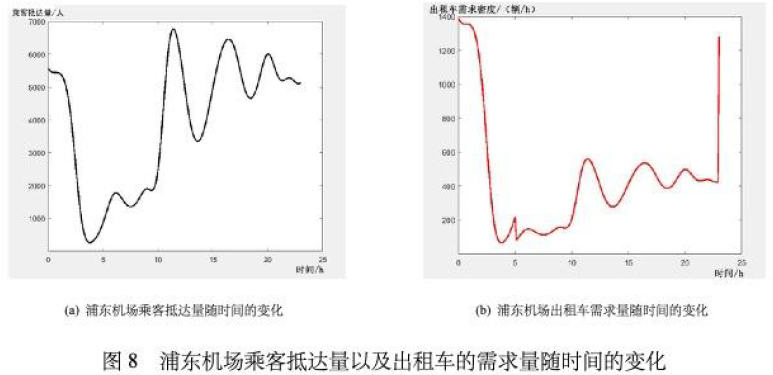
答案是否定的,论文原话:利用浦东机场每架航班平均载客量计算得到了浦东机场乘客抵达量以及出租车的需求量随时间的变化,证明他是用公式推导得出的两幅图
我们来试着推导一下公式:
N
p
=
N
a
×
N
a
‾
N_p=N_atimes overline{N_a}
Np=Na×Na
机场乘客抵达量
N
p
N_p
Np 由航班平均载客量
N
a
‾
overline{N_a}
Na 乘以航班抵达数量
N
a
N_a
Na 得出,
N
a
‾
overline{N_a}
Na 是已知的,而
N
a
N_a
Na 就是我们爬取的数据,也是已知的
P r ( t ) = P a ( t ) × N a ‾ × k ( t ) N c ‾ P_rleft( t right) =frac{P_aleft( t right) times overline{N_a}times kleft( t right)}{overline{N_c}} Pr(t)=NcPa(t)×Na×k(t)
出租车的需求量 P r ( t ) P_rleft( t right) Pr(t) 由航班到达量 P a ( t ) P_aleft( t right) Pa(t) 乘以航班抵达数量 N a ‾ overline{N_a} Na 乘以回市区乘客比例 ( t ) left( t right) (t) 除以出租车平均载客 N c ‾ overline{N_c} Nc 得出, P a ( t ) P_aleft( t right) Pa(t) 不知道,但是可以用已知量航班抵达数量 N a N_a Na 代替(原因后面会说), N a ‾ overline{N_a} Na 是已知的, N c ‾ overline{N_c} Nc 也是已知的,而 K ( t ) Kleft( t right) K(t) 就是本题的重点(不是已知的)
由此画出机场乘客抵达量和出租车的需求量的函数图像(如下)
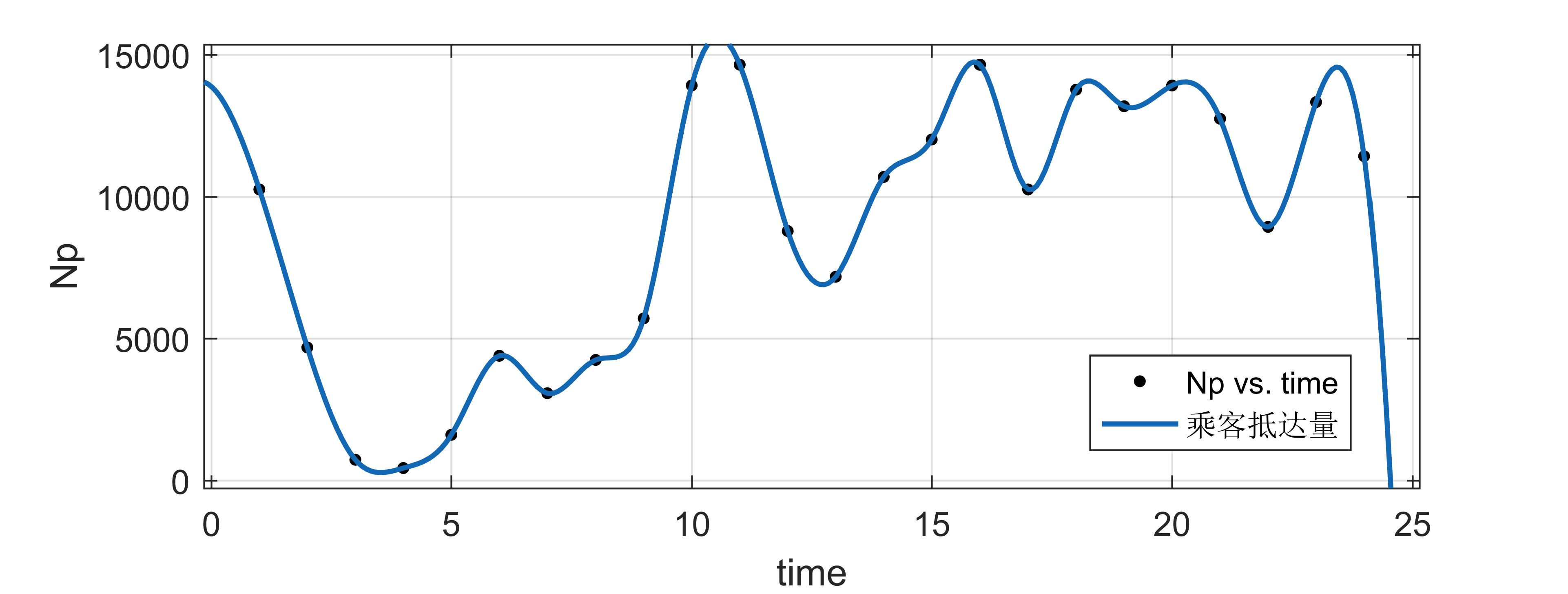
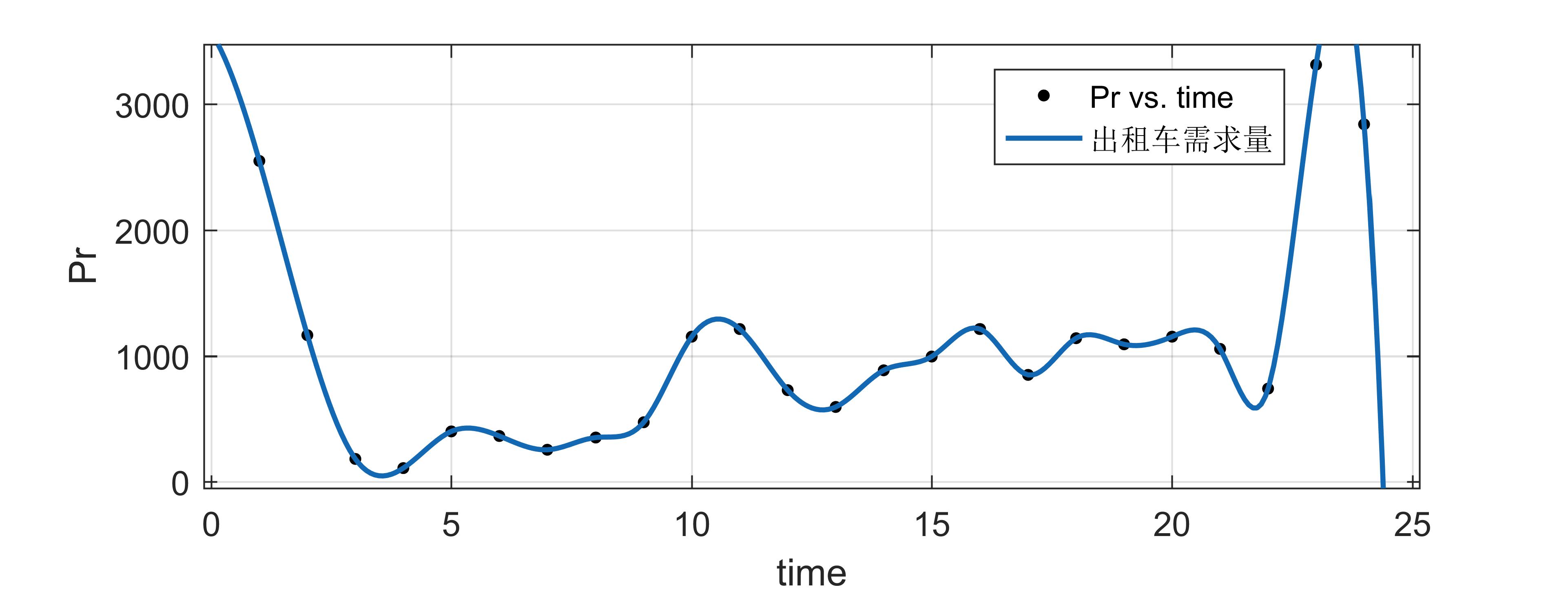
是不是感觉和论文的图很类似,证明我的推导是对的,这里解释一下前面的疑问:
① 为什么航班到达量 P a ( t ) P_aleft( t right) Pa(t) 可以用航班抵达数量 N a N_a Na 代替 ?
答:首先,航班到达量是从飞机下来的乘客数量,航班抵达数量是飞机到达的数量。我们可以看出我的图片和论文的图片非常类似,说明他也有可能并没有单独爬取 P a ( t ) P_aleft( t right) Pa(t) 的数据,而是用 N a N_a Na 代替的。还有一种可能,航班抵达数量和航班到达量的比例非常接近 1 : 1 1:1 1:1,毕竟单位时间内总飞机到达数量和下飞机的总客人量成正相关,那么这样的话,即使我们用 N a N_a Na 代替 P a ( t ) P_aleft( t right) Pa(t)也是合情合理的
② K ( t ) Kleft( t right) K(t) 为什么是本题的重点 ?
答:因为它不是已知量 !那出租车的需求量
P
r
(
t
)
P_rleft( t right)
Pr(t) 是如何算出来的呢 ?我们看一下原论文是怎么说的(图8是那两幅图)

我严重怀疑他是先想出这些话,然后反推出
P
r
(
t
)
P_rleft( t right)
Pr(t) 的,因为论文中完全没有交代回市区乘客比例
K
(
t
)
Kleft( t right)
K(t) 的出处,代码部分也是直接代了几个数值上去,所以他有完全可能是特意这么做的,我的理解是他查论文找到相关资料背景并且觉得有道理,就把
K
(
t
)
Kleft( t right)
K(t) 的值按照结论给反推了回去
③ 为什么我的函数图片这么顺滑 ?
答:按理来说,已知的函数点只有24个,应该是点和点之间用直线相连,所以很明显我是用了拟合的方法。但奇怪的是论文原话:我们对原始数据进行了差值处理,就离谱,因为我试过了,每个点之间至少要差10个以上的值才勉强连接起来的,而差值主要是针对于两个点之间的,也就是要重复差值10次以上,并且由于每次差值不能确保点之间的连贯性,很容易出现函数不平滑的现象,所以我有理由怀疑他用的是拟合而不是差值 (毕竟代码部分我看不懂)
【代码一】
clear;clc;
load('data.mat'); % 机场航班的到达量分布数据
figure( 'Name', '乘客抵达量' );
for i=1:24
Np(i)=sum(i)*146.5;
end
plot(time,Np,'b-')
xlabel('时间/h')
ylabel('乘客抵达量/人')
grid on
figure( 'Name', '出租车需求量' );
for i=1:24
if (1>=0)&&(i<=5)
k=0.45;
elseif (i>=23)
k=0.45;
else
k=0.15;
end
Pr(i)=sum(i)*146.5*k/1.81;
end
plot(time,Pr,'b-')
xlabel('时间/h')
ylabel('出租车需求量/人')
grid on
【模型二】
他的论文还有一个特别厉害的求解思路,问题二的目标是选择一个方案,他的思路是假设两个方案的总用时间和获得收益相同,根据两个方案的公式恒等,算出A选择下的排队时长
t
l
t_l
tl,进而获得每个时刻出租车乘车点的出租车队列长度
N
b
(
t
)
N_b(t)
Nb(t)
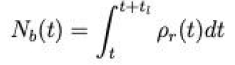
然后,设
t
t
t 时刻将乘客送往浦东机场到达出发通道的出租车的数量为
p
m
(
t
)
p_m(t)
pm(t)(该数据可由某时刻从浦东机场出发的航班数以及航班的平均载客量得到),则实际状况下浦东机场出租车乘车点的出租车队列长度为
N
p
(
t
)
N_p(t)
Np(t)
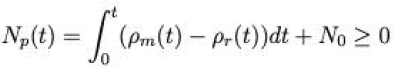

小提示:
p
m
(
t
)
p_m(t)
pm(t) 其实可以用
p
p
(
t
)
p_p(t)
pp(t) 代替,从论文原话:该数据可由某时刻从浦东机场出发的航班数以及航班的平均载客量得到可以得出
实际运算的过程中并不用求解积分,积分只是来解释函数图像的
由此画出每个时刻下的和实际状况下出租车队列长度的函数图像(如下)
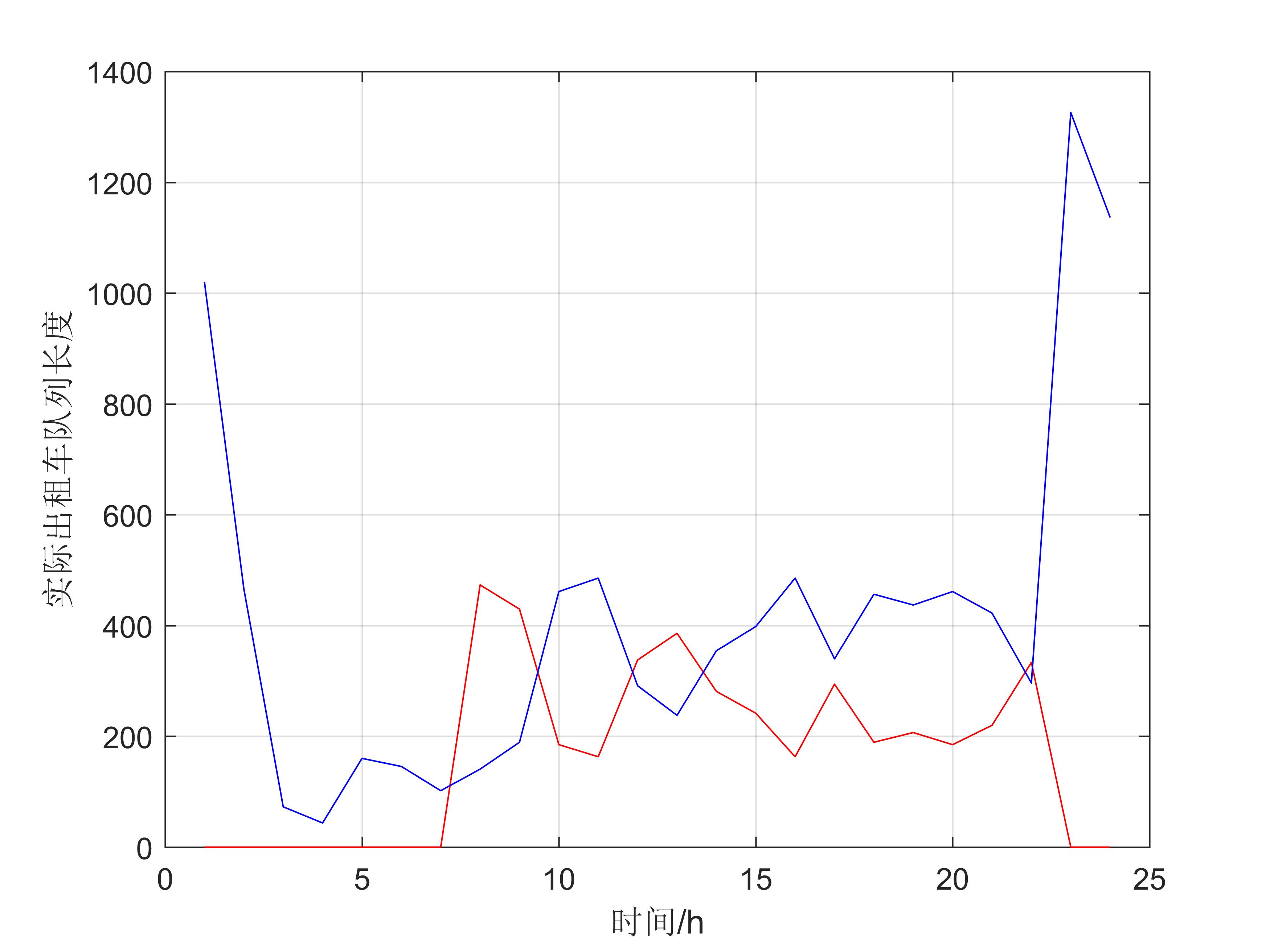
对于代码部分其实我动了点手脚,毕竟和论文使用的数据不一样,但是我最不理解的是为什么有些时时候出租车队列长度为0(在代码值为0部分其实算出来是负数,我特意改成0的),我能想出来的理由只有:他根据查资料出来的结论强行更改数值 (老套路了)
【代码二】
clear;clc;
syms tl n % 损耗时间 选择B的平均订单量
fai=6.8*7.4/100; % 油耗系数
tdA=50/60; % A订单路程
tA=tl+tdA; % 选择A总时间
PA=155; % A订单平均价格
XA=45.8; % A订单平均距离
CA=fai*XA; % A成本
deltaEA=PA-CA; % A净获利
te=30/60; % 回市区时间
tdi=20/60; % B找客平均时间
tB=te+n*tdi; % 选择B总时间
PB=n*29.3; % B订单平均价格
XB=26+n*9.12; % B订单平均距离
CB=fai*XB; % B成本
deltaEB=PB-CB; % B净获利
[a,b]=vpasolve([tA-tB,deltaEA-deltaEB],[tl,n])
% 1.62 5.87
clear;clc;
load('data.mat');
figure( 'Name', '实际出租车队列长度' );
for i=1:24
if (1>=0)&&(i<=5)
k=0.45;
elseif (i>=23)
k=0.45;
else
k=0.15;
end
Pr(i)=sum(i)*146.5*k/1.81;
end
for i=1:24
Np(i)=sum(i)*146.5-Pr(i)+600;
en
plot(time,Np,'r-')
xlabel('时间/h')
ylabel('实际出租车队列长度')
hold on
plot(time,Pr,'b-')
grid on
【分析模型对相关因素的依赖性】
论文中的方法是:改变自变量的百分比来探究因变量的百分比变化(示例如下图)
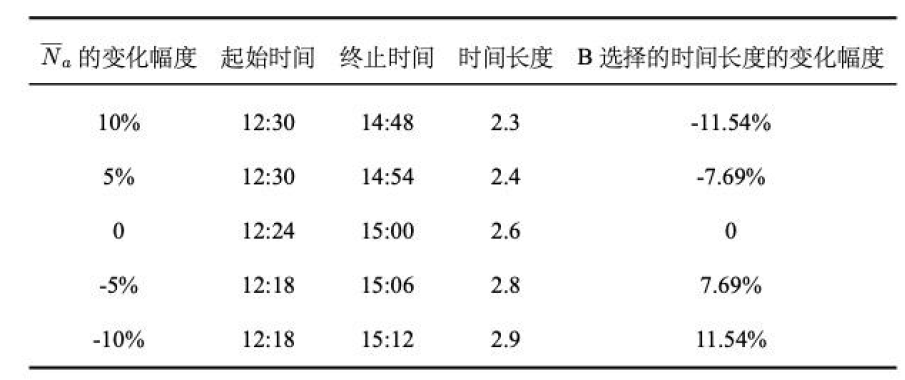
我认为:B选择的时间长度的变化幅度应该指的是A选择的时间损耗
t
l
t_l
tl 的变化幅度
因为根据公式恒等式推导的只有
t
l
t_l
tl 和选择B的平均订单量
n
n
n,排除
n
n
n 后只剩
t
l
t_l
tl 了
至于起始时间、终止时间、时间长度我真没想出来,可能与前面的积分解释有关( 终 止 时 间 − 起 始 时 间 = 时 间 长 度 , 单 位 : 小 时 终止时间-起始时间=时间长度,单位:小时 终止时间−起始时间=时间长度,单位:小时)
【分析模型的合理性】
论文用的方法是:加高斯噪声处理
一般来说高斯噪声处理常用于图像处理,但论文中运用的是数据(航班到达量)加高斯噪声处理,这就使得我在网上很难找类似的方法,好不容易找到了,求解出来的值又看不懂
load('Z.mat') % 二维的航班到达量(时间和数量)
% 给数据加指定SNR的高斯噪声
signal_noise = awgn(Z,10,'measured');
An=(Z-mean(mean(Z))).^2;
% Ps=sum(sum(An)); % signal power
Ps=0;
for i=1:24
Ps=Ps+An(1,i);
end
for i=1:24
Ps=Ps+An(2,i);
end
Bn=(Z-signal_noise).^2;
% Pn=sum(sum(Bn)); % noise power
Pn=0;
for i=1:24
Pn=Pn+Bn(1,i);
end
for i=1:24
Pn=Pn+Bn(2,i);
end
snr=10*log10(Ps/Pn); % 验证所加的噪声
点击运行算出来 s u r sur sur 等于 6.131,再点击运行算出来等于 6.467,下一次等于 5.658,所以这表示了什么…我没看懂,对于这类分析模型的合理性我可能会采用相关性分析之类的
五、第三题解析:
问题重述对第三题的描述
经常会出现出租车排队载客和乘客排队乘车的情况。某机场“乘车区”现有两条并行车道,管理部门应如何设置“上车点”,并合理安排出租车和乘客,在保证车辆和乘客安全的条件下,使得总的乘车效率最高
问题分析对第三题的描述


由:文献 + 个人观点 + 解体思路 组成
文献:简单复述题目,并引用查找的文献
个人观点 :分析引用文献的不足之处
解体思路:给出解决方案与过程
泊松流:可以约看成单位时间内客人量的正态分布
问题三的模型建立与求解
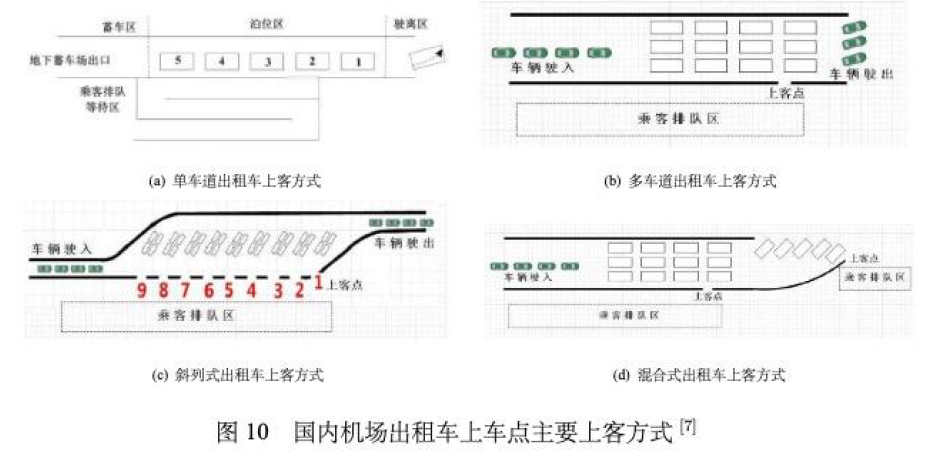
【文献引用】
问题三引用的三张图片(如下)是选自论文:基于排队论的航空枢纽陆侧旅客服务资源建模与仿真_孙健
【模型】
模型建立的目的是:乘车效率最大
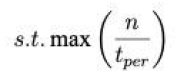
其中
n
n
n 代表泊位,
t
p
e
r
t_{per}
tper 代表第一辆出租车进上客区到最后一辆出租车离开的总时间,二者相除即乘车效率
要理解他推导的公式和蒙特卡洛,还得从代码看起,所以我们从代码来理解(代码二是函数封装)
【代码一】
clear;clc;
f=zeros(size(2:2:100)); % 所假设的泊位数的个数
j=0;
for i=2:2:100 % 循环泊位数的个数
j=j+1; % 第j个泊位数
f(j)=myfun(i); % 第j个泊位数对应的出租车供给能力(辆/s)
end
x=2:2:100; % 偶数泊位数
f=3600.*f; % 3600 * 出租车供给能力(辆/s)= 出租车供给能力(辆/h)
plot(x,f,'r.'); % 出租车供给能力和泊位数的散点图
xlswrite('C:Users14805Desktop2019Cdata.xlsx',f); % 将结果储存到指定位置中
【代码二】
function f=myfun(x) % 求出租车供给能力(辆/s)的函数【乘车效率】
k=2; % 上客区的车道数量
for m=1:1500 % 蒙特卡洛次数
for i=1:x % 泊位不一定全满车,取不同的车数量计算
mu=(30+x.*2.5); % 参数为lamda的指数分布
ar(i)=exprnd(mu); % 所有出租车从到上客区熄火到发车离开的时间
end
r=max(ar); % 取ar的最大值表示最差的情况(时间最多)
t(m)=r+2.*(x.*5/(5/3.6)+1.*(x-1))./k; % 从第一辆出租车进入泊位到最后一辆出租车离开泊位的总时间
end
f=1500*x/sum(t); % 泊位数除以总时间表示乘车效率,并重复1500次取平均值
end
代码一主要是储存泊位数和对应的出租车供给能力,为画散点图做准备;
代码二求的是求出租车供给能力,即乘车效率,exprnd 函数的作用是给出服从参数 mu 的正态分布数值 ar,那么 r 储存的就是最大的 ar,从 t 的等式中看出 r 就是公式中的
E
E
E
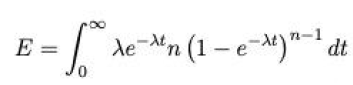
那么显然,蒙特卡洛的目的就是求最大的出租车从到上客区熄火到发车离开的时间,也称为等客时间,那为什么让等客时间最长呢 ?是为了避免偶然性,以防正态分布的数值过于极端,换句人话说就是做出最坏的打算,最后,根据代码可算出当前泊位数的乘车效率
运行代码,由此得到不同泊位对应的乘车效率散点图(如下)
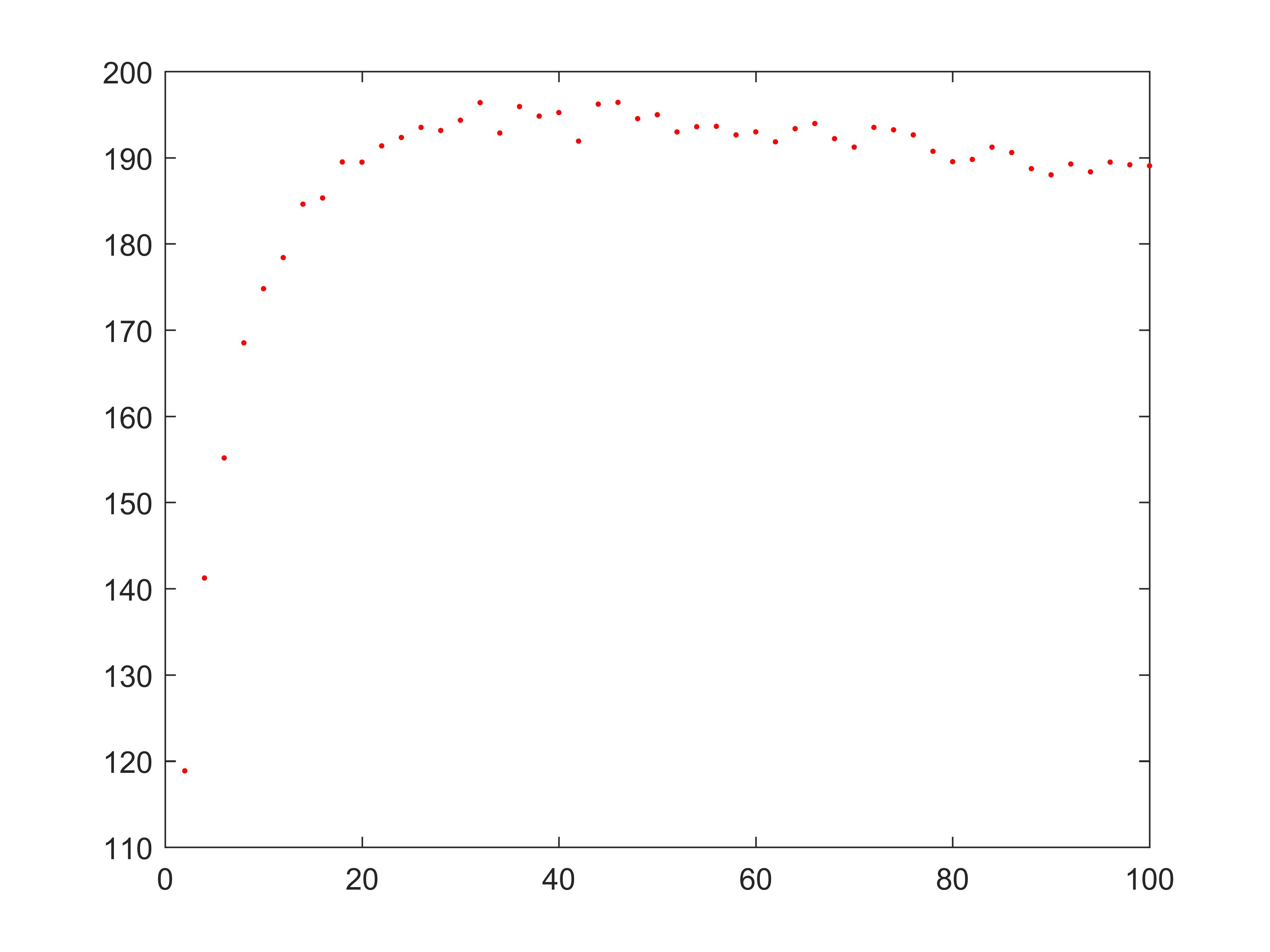
从图中很显然看出最大乘车效率是195左右,但泊位数集中在20至100间,这显然是不现实的,现实生活中还要考虑泊位占地面积以及空间费用等因素,论文原话:因此我们以每小时驶离上客区的出租车数量最大值的0.9倍进行搜寻得到此时的乘车点,
195
∗
0.9
=
175.5
195*0.9=175.5
195∗0.9=175.5,我们选择乘车效率为175.5对应的泊位数10作为最终结果,又由于两条并行车道,乘车点为:
10
/
2
=
5
10/2=5
10/2=5
六、第四题解析:
论文第四问和第二问的解题思路非常类似,以至于我非常怀疑作者是做完第四问后又有了灵感,然后重写了第二问,为什么我会这么说 ?看下面解析就知道了
问题重述对第四题的描述
机场的出租车载客收益与载客的行驶里程有关,试给出一个可行的“优先"安排方案,使得这些出租车的收益尽量均衡
问题分析对第四题的描述

这篇分析就是活生生的高大上专业术语,原理很简单:根据短长途收益和时间相同得出短途车应该插入的队列长度,但他就很厉害了,“GPS短途智能识别系统”、“分流”、“缓冲区” 都来了,还有副流程图把问题一二三的模型都结合起来了,在下佩服
问题四的模型建立与求解
要是能看懂问题二的模型,这一题应该也能很容易看懂了,只是多引入了一个概念 λ lambda λ 用于表示短途对于长途的倍数,然后依靠恒等式列公式运行代码即可得到结果(这里就不重复写了)
【函数图像解析】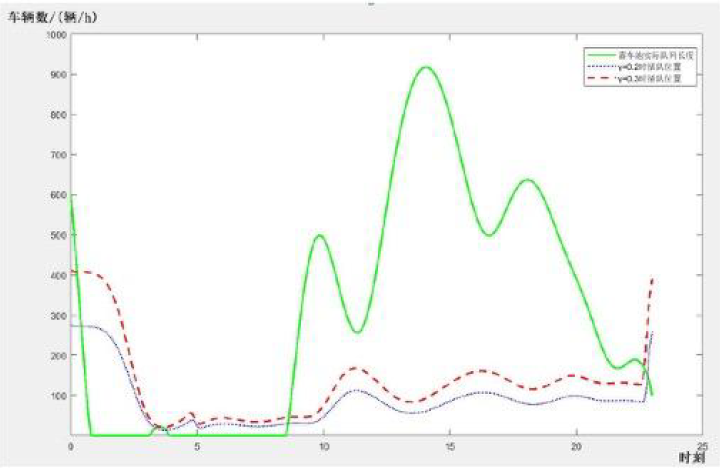
原文:绿线代表蓄车场内的实际出租车排队的队列长度,蓝色虚线表示取0.2时短途单下出租车插队后其前面的车辆数量,红色虚线为取0.4时的情况
根据函数图像判断短途车应该插队的位置,也就是绿线横坐标与红或蓝线横坐标的比值
原文:红色虚线一直在蓝色虚线之上,这代表随着短途订单距离的增加,收益增加,出租车司机返回机场享受优先权插队后,其前面的出租车数量也在增加。这可以间接验证我们模型的准确性
意思是相同时间下(纵坐标), λ lambda λ 越高,插队的位置就越长(红线的横坐标高于蓝线的横坐标)
原文:在0:30—3:00时,红色虚线与蓝色虚线均高于绿色虚线,这代表蓄车场内的出租车无法满足乘客的需求,短途司机一返回机场即可接单开始下一订单。表11给出了一些具体时刻短途载客的出租车返回机场的插队情况
这个解释非常巧妙,既能把前面的锅摘掉(值为负数改成0),又能对当前现象进行合理解释
七、模型检验:
这个检验方法和问题二的分析模型对相关因素的依赖性大同小异,都是改变自变量的百分比来探究因变量的百分比变化,只不过因变量这次变成了乘车效率
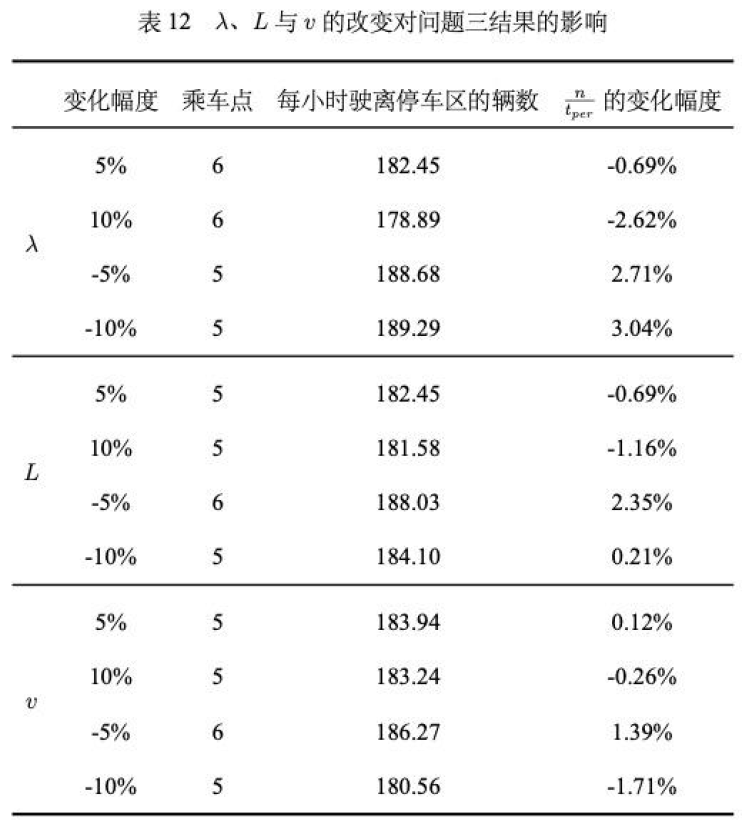
每小时驶离停车区的辆数取的应该是平均值
八、模型评价:
略 (王婆卖瓜,自卖自夸哈哈)
最后
以上就是俭朴高跟鞋最近收集整理的关于数学建模国奖论文2019-C-C308分析问题C 机场的出租车问题的全部内容,更多相关数学建模国奖论文2019-C-C308分析问题C内容请搜索靠谱客的其他文章。








发表评论 取消回复