0.概述
通过本篇文章将了解到以下内容:
- I/O复用的定义和产生背景
- Linux系统的I/O复用工具
- epoll设计的基本构成
- epoll高性能的底层实现
- epoll的ET模式和LT模式
1.复用技术和I/O复用
- 复用的概念
复用技术(multiplexing)并不是新技术而是一种设计思想,在通信和硬件设计中存在频分复用、时分复用、波分复用、码分复用等,在日常生活中复用的场景也非常多,因此不要被专业术语所迷惑。
从本质上来说,复用就是为了解决有限资源和过多使用者的不平衡问题,且此技术的理论基础是资源的可释放性。
- 资源的可释放性
举个实际生活的例子:
不可释放场景:ICU病房的呼吸机作为有限资源,病人一旦占用且在未脱离危险之前是无法放弃占用的,因此不可能几个情况一样的病人轮流使用。
可释放场景:对于一些其他资源比如医护人员就可以实现对多个病人的同时监护,理论上不存在一个病人占用医护人员资源不释放的场景。
- 理解IO复用
I/O的含义:在计算机领域常说的IO包括磁盘IO和网络IO,我们所说的IO复用主要是指网络IO,在Linux中一切皆文件,因此网络IO也经常用文件描述符FD来表示。
复用的含义:那么这些文件描述符FD要复用什么呢?在网络场景中复用的就是任务处理线程,所以简单理解就是多个IO共用1个线程。
IO复用的可行性:IO请求的基本操作包括read和write,由于网络交互的本质性,必然存在等待,换言之就是整个网络连接中FD的读写是交替出现的,时而可读可写,时而空闲,所以IO复用是可用实现的。
综上认为,IO复用技术就是协调多个可释放资源的FD交替共享任务处理线程完成通信任务,实现多个fd对应1个任务处理线程。
现实生活中IO复用就像一只边牧管理几百只绵羊一样:

- IO复用的设计原则和产生背景
高效IO复用机制要满足:协调者消耗最少的系统资源、最小化FD的等待时间、最大化FD的数量、任务处理线程最少的空闲、多快好省完成任务等。
在网络并发量非常小的原始时期,即使per req per process地处理网络请求也可以满足要求,但是随着网络并发量的提高,原始方式必将阻碍进步,所以就刺激了IO复用机制的实现和推广。
2.Linux中IO复用工具
在Linux中先后出现了select、poll、epoll等,FreeBSD的kqueue也是非常优秀的IO复用工具,kqueue的原理和epoll很类似,本文以Linux环境为例,并且不讨论过多select和poll的实现机制和细节。
- 开拓者select
select大约是2000年初出现的,其对外的接口定义:

作为第一个IO复用系统调用,select使用一个宏定义函数按照bitmap原理填充fd,默认大小是1024个,因此对于fd的数值大于1024都可能出现问题,看下官方预警:
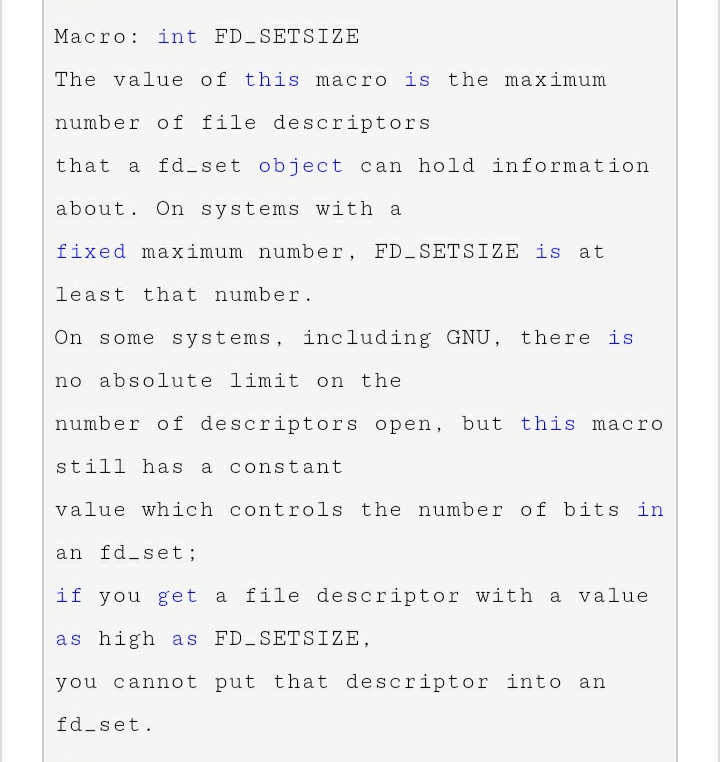
也就是说当fd的数值大于1024时在将不可控,官方不建议超过1024,但是我们也无法控制fd的绝对数值大小,之前针对这个问题做过一些调研,结论是系统对于fd的分配有自己的策略,会大概率分配到1024以内,对此我并没有充分理解,只是提及一下这个坑。
存在的问题:
- 可协调fd数量和数值都不超过1024 无法实现高并发
- 使用O(n)复杂度遍历fd数组查看fd的可读写性 效率低
- 涉及大量kernel和用户态拷贝 消耗大
- 每次完成监控需要再次重新传入并且分事件传入 操作冗余
综上可知,select以朴素的方式实现了IO复用,将并发量提高的最大K级,但是对于完成这个任务的代价和灵活性都有待提高。无论怎么样select作为先驱对IO复用有巨大的推动,并且指明了后续的优化方向,不要无知地指责select。
- 继承者epoll
epoll最初在2.5.44内核版本出现,后续在2.6.x版本中对代码进行了优化使其更加简洁,先后面对外界的质疑在后续增加了一些设置来解决隐藏的问题,所以epoll也已经有十几年的历史了。
在《Unix网络编程》第三版(2003年)还没有介绍epoll,因为那个时代epoll还没有出现,书中只介绍了select和poll,epoll对select中存在的问题都逐一解决,简单来说epoll的优势包括:
- 对fd数量没有限制(当然这个在poll也被解决了)
- 抛弃了bitmap数组实现了新的结构来存储多种事件类型
- 无需重复拷贝fd 随用随加 随弃随删
- 采用事件驱动避免轮询查看可读写事件
综上可知,epoll出现之后大大提高了并发量对于C10K问题轻松应对,即使后续出现了真正的异步IO,也并没有(暂时没有)撼动epoll的江湖地位,主要是因为epoll可以解决数万数十万的并发量,已经可以解决现在大部分的场景了,异步IO固然优异,但是编程难度比epoll更大,权衡之下epoll仍然富有生命力。
3.epoll的基本实现
- epoll的api定义:
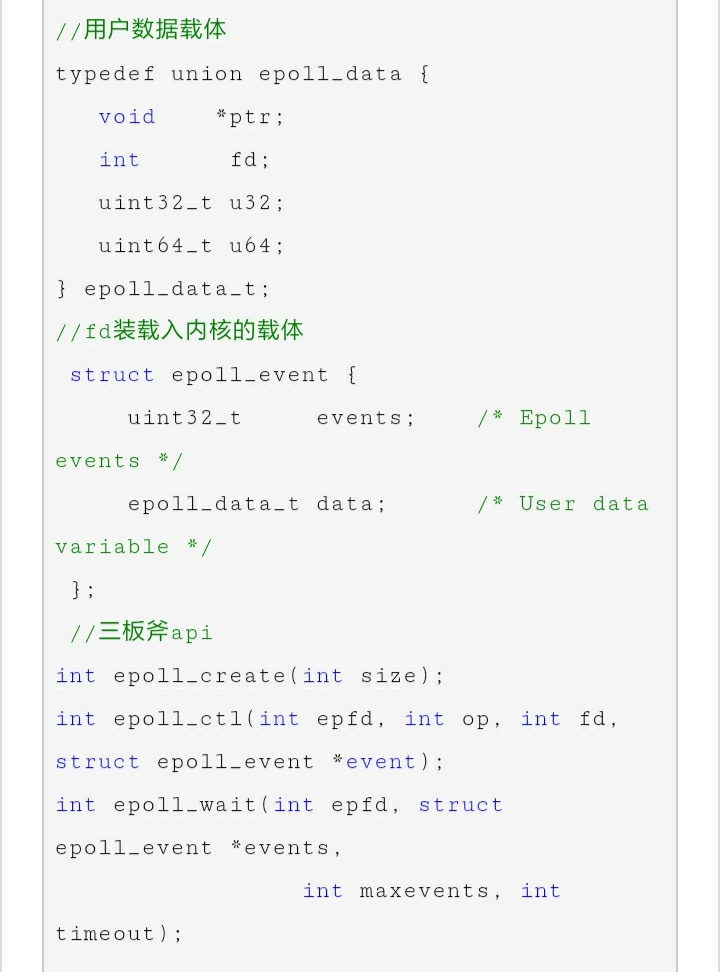
- epoll_create是在内核区创建一个epoll相关的一些列结构,并且将一个句柄fd返回给用户态,后续的操作都是基于此fd的,参数size是告诉内核这个结构的元素的大小,类似于stl的vector动态数组,如果size不合适会涉及复制扩容,不过貌似4.1.2内核之后size已经没有太大用途了;
- epoll_ctl是将fd添加/删除于epoll_create返回的epfd中,其中epoll_event是用户态和内核态交互的结构,定义了用户态关心的事件类型和触发时数据的载体epoll_data;
- epoll_wait是阻塞等待内核返回的可读写事件,epfd还是epoll_create的返回值,events是个结构体数组指针存储epoll_event,也就是将内核返回的待处理epoll_event结构都存储下来,maxevents告诉内核本次返回的最大fd数量,这个和events指向的数组是相关的;
- epoll_event是用户态需监控fd的代言人,后续用户程序对fd的操作都是基于此结构的;
- 通俗描述:
可能上面的描述有些抽象,不过其实很好理解,举个现实中的例子:
- epoll_create场景:
- 大学开学第一周,你作为班长需要帮全班同学领取相关物品,你在学生处告诉工作人员,我是xx学院xx专业xx班的班长,这时工作人员确定你的身份并且给了你凭证,后面办的事情都需要用到(也就是调用epoll_create向内核申请了epfd结构,内核返回了epfd句柄给你使用);
- epoll_ctl场景:
- 你拿着凭证在办事大厅开始办事,分拣办公室工作人员说班长你把所有需要办理事情的同学的学生册和需要办理的事情都记录下来吧,于是班长开始在每个学生手册单独写对应需要办的事情:
- 李明需要开实验室权限、孙大熊需要办游泳卡......就这样班长一股脑写完并交给了工作人员(也就是告诉内核哪些fd需要做哪些操作);
- epoll_wait场景:
- 你拿着凭证在领取办公室门前等着,这时候广播喊xx班长你们班孙大熊的游泳卡办好了速来领取、李明实验室权限卡办好了速来取....还有同学的事情没办好,所以班长只能继续(也就是调用epoll_wait等待内核反馈的可读写事件发生并处理);
- 官方DEMO
通过man epoll可以看到官方的demo:



在epoll_wait时需要区分是主监听线程fd的新连接事件还是已连接事件的读写请求,进而单独处理。
4.epoll的底层实现
epoll底层实现最重要的两个数据结构:epitem和eventpoll。
可以简单的认为epitem是和每个用户态监控IO的fd对应的,eventpoll是用户态创建的管理所有被监控fd的结构,详细的定义如下:


- 底层调用过程
epoll_create会创建一个类型为struct eventpoll的对象,并返回一个与之对应文件描述符,之后应用程序在用户态使用epoll的时候都将依靠这个文件描述符,而在epoll内部也是通过该文件描述符进一步获取到eventpoll类型对象,再进行对应的操作,完成了用户态和内核态的贯穿。
epoll_ctl底层主要调用epoll_insert实现操作:
- 创建并初始化一个strut epitem类型的对象,完成该对象和被监控事件以及epoll对象eventpoll的关联;
- 将struct epitem类型的对象加入到epoll对象eventpoll的红黑树中管理起来;
- 将struct epitem类型的对象加入到被监控事件对应的目标文件的等待列表中,并注册事件就绪时会调用的回调函数,在epoll中该回调函数就是ep_poll_callback();
- ovflist主要是暂态处理,比如调用ep_poll_callback()回调函数的时候发现eventpoll的ovflist成员不等于EP_UNACTIVE_PTR,说明正在扫描rdllist链表,这时将就绪事件对应的epitem加入到ovflist链表暂存起来,等rdllist链表扫描完再将ovflist链表中的元素移动到rdllist链表中;
- 如图展示了红黑树、双链表、epitem之间的关系:
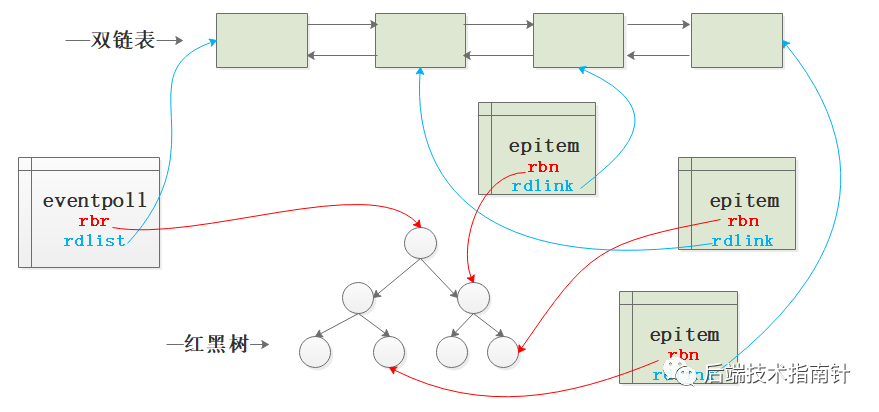
注:rbr表示rb_root,rbn表示rb_node 上文给出了其在内核中的定义
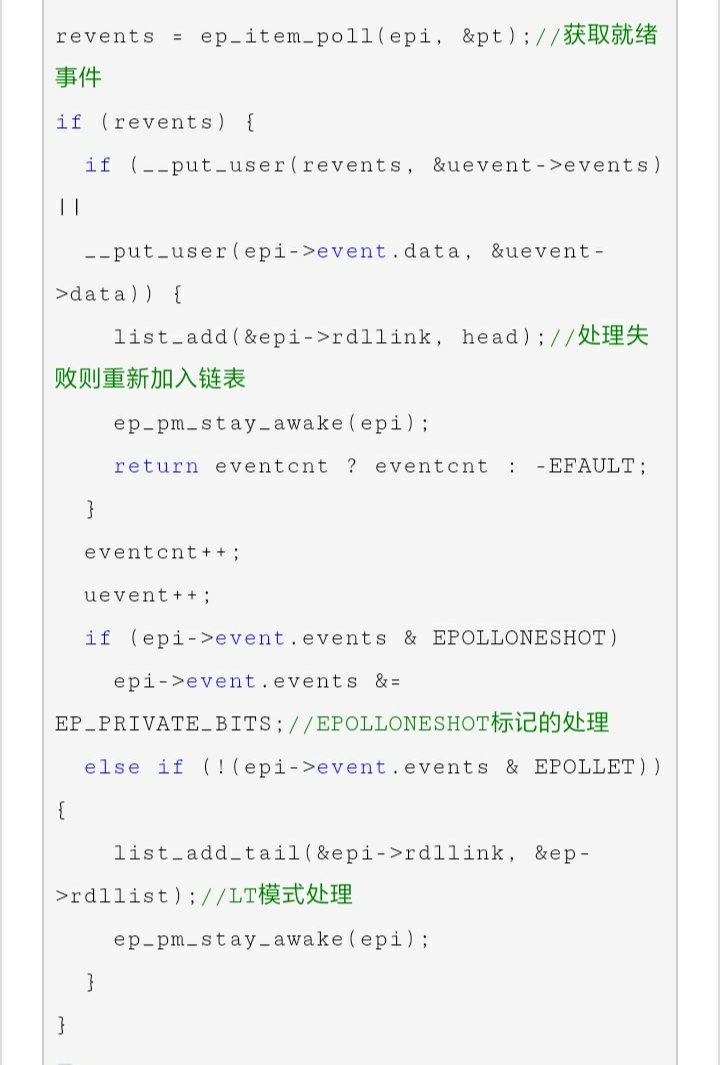
- epoll_wait的数据拷贝
常见错误观点:epoll_wait返回时,对于就绪的事件,epoll使用的是共享内存的方式,即用户态和内核态都指向了就绪链表,所以就避免了内存拷贝消耗网上抄来抄去的观点
关于epoll_wait使用共享内存的方式来加速用户态和内核态的数据交互,避免内存拷贝的观点,并没有得到2.6内核版本代码的证实,并且关于这次拷贝的实现是这样的:
5.ET模式和LT模式
- 简单理解
默认采用LT模式,LT支持阻塞和非阻塞套,ET模式只支持非阻塞套接字,其效率要高于LT模式,并且LT模式更加安全。
LT和ET模式下都可以通过epoll_wait方法来获取事件,LT模式下将事件拷贝给用户程序之后,如果没有被处理或者未处理完,那么在下次调用时还会反馈给用户程序,可以认为数据不会丢失会反复提醒;
ET模式下如果没有被处理或者未处理完,那么下次将不再通知到用户程序,因此避免了反复被提醒,却加强了对用户程序读写的要求;
- 深入理解
上面的简单理解在网上随便找一篇都会讲到,但是LT和ET真正使用起来,还是存在一定难度的。
- LT的读写操作
LT对于read操作比较简单,有read事件就读,读多读少都没有问题,但是write就不那么容易了,一般来说socket在空闲状态时发送缓冲区一定是不满的,假如fd一直在监控中,那么会一直通知写事件,不胜其烦。
所以必须保证没有数据要发送的时候,要把fd的写事件监控从epoll列表中删除,需要的时候再加入回去,如此反复。
天下没有免费的午餐,总是无代价地提醒是不可能的,对应write的过度提醒,需要使用者随用随加,否则将一直被提醒可写事件。
- ET的读写操作
fd可读则返回可读事件,若开发者没有把所有数据读取完毕,epoll不会再次通知read事件,也就是说如果没有全部读取所有数据,那么导致epoll不会再通知该socket的read事件,事实上一直读完很容易做到。
若发送缓冲区未满,epoll通知write事件,直到开发者填满发送缓冲区,epoll才会在下次发送缓冲区由满变成未满时通知write事件。
ET模式下只有socket的状态发生变化时才会通知,也就是读取缓冲区由无数据到有数据时通知read事件,发送缓冲区由满变成未满通知write事件。
- 一道面试题
使用Linux epoll模型的LT水平触发模式,当socket可写时,会不停的触发socket可写的事件,如何处理?网络流传的腾讯面试题
这道题目对LT和ET考察比较深入,验证了前文说的LT模式write问题。
普通做法:
当需要向socket写数据时,将该socket加入到epoll等待可写事件。接收到socket可写事件后,调用write()或send()发送数据,当数据全部写完后, 将socket描述符移出epoll列表,这种做法需要反复添加和删除。
改进做法:
向socket写数据时直接调用send()发送,当send()返回错误码EAGAIN,才将socket加入到epoll,等待可写事件后再发送数据,全部数据发送完毕,再移出epoll模型,改进的做法相当于认为socket在大部分时候是可写的,不能写了再让epoll帮忙监控。
上面两种做法是对LT模式下write事件频繁通知的修复,本质上ET模式就可以直接搞定,并不需要用户层程序的补丁操作。
- ET模式的线程饥饿问题
如果某个socket源源不断地收到非常多的数据,在试图读取完所有数据的过程中,有可能会造成其他的socket得不到处理,从而造成饥饿问题。
解决办法:为每个已经准备好的描述符维护一个队列,这样程序就可以知道哪些描述符已经准备好了但是并没有被读取完,然后程序定时或定量的读取,如果读完则移除,直到队列为空,这样就保证了每个fd都被读到并且不会丢失数据,流程如图:
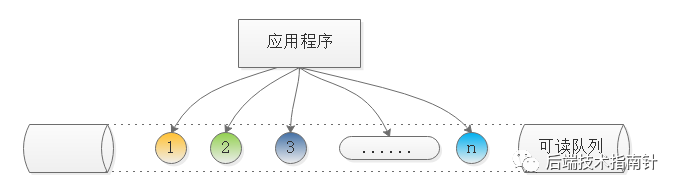
- EPOLLONESHOT设置
A线程读完某socket上数据后开始处理这些数据,此时该socket上又有新数据可读,B线程被唤醒读新的数据,造成2个线程同时操作一个socket的局面 ,EPOLLONESHOT保证一个socket连接在任一时刻只被一个线程处理。
- 两种模式的选择
通过前面的对比可以看到LT模式比较安全并且代码编写也更清晰,但是ET模式属于高速模式,在处理大高并发场景使用得当效果更好,具体选择什么根据自己实际需要和团队代码能力来选择,如果并发很高且团队水平较高可以选择ET模式,否则建议LT模式。
6.epoll的惊群问题
在2.6.18内核中accept的惊群问题已经被解决了,但是在epoll中仍然存在惊群问题,表现起来就是当多个进程/线程调用epoll_wait时会阻塞等待,当内核触发可读写事件,所有进程/线程都会进行响应,但是实际上只有一个进程/线程真实处理这些事件。
在epoll官方没有正式修复这个问题之前,Nginx作为知名使用者采用全局锁来限制每次可监听fd的进程数量,每次只有1个可监听的进程,后来在Linux 3.9内核中增加了SO_REUSEPORT选项实现了内核级的负载均衡,Nginx1.9.1版本支持了reuseport这个新特性,从而解决惊群问题。
EPOLLEXCLUSIVE是在2016年Linux 4.5内核新添加的一个 epoll 的标识,Ngnix 在 1.11.3 之后添加了NGX_EXCLUSIVE_EVENT选项对该特性进行支持。EPOLLEXCLUSIVE标识会保证一个事件发生时候只有一个线程会被唤醒,以避免多侦听下的惊群问题。
最后
以上就是迷你滑板最近收集整理的关于深入理解Linux IO复用之epoll0.概述1.复用技术和I/O复用2.Linux中IO复用工具3.epoll的基本实现4.epoll的底层实现5.ET模式和LT模式6.epoll的惊群问题的全部内容,更多相关深入理解Linux内容请搜索靠谱客的其他文章。








发表评论 取消回复