成果展示:
一个项目单独拎出来:
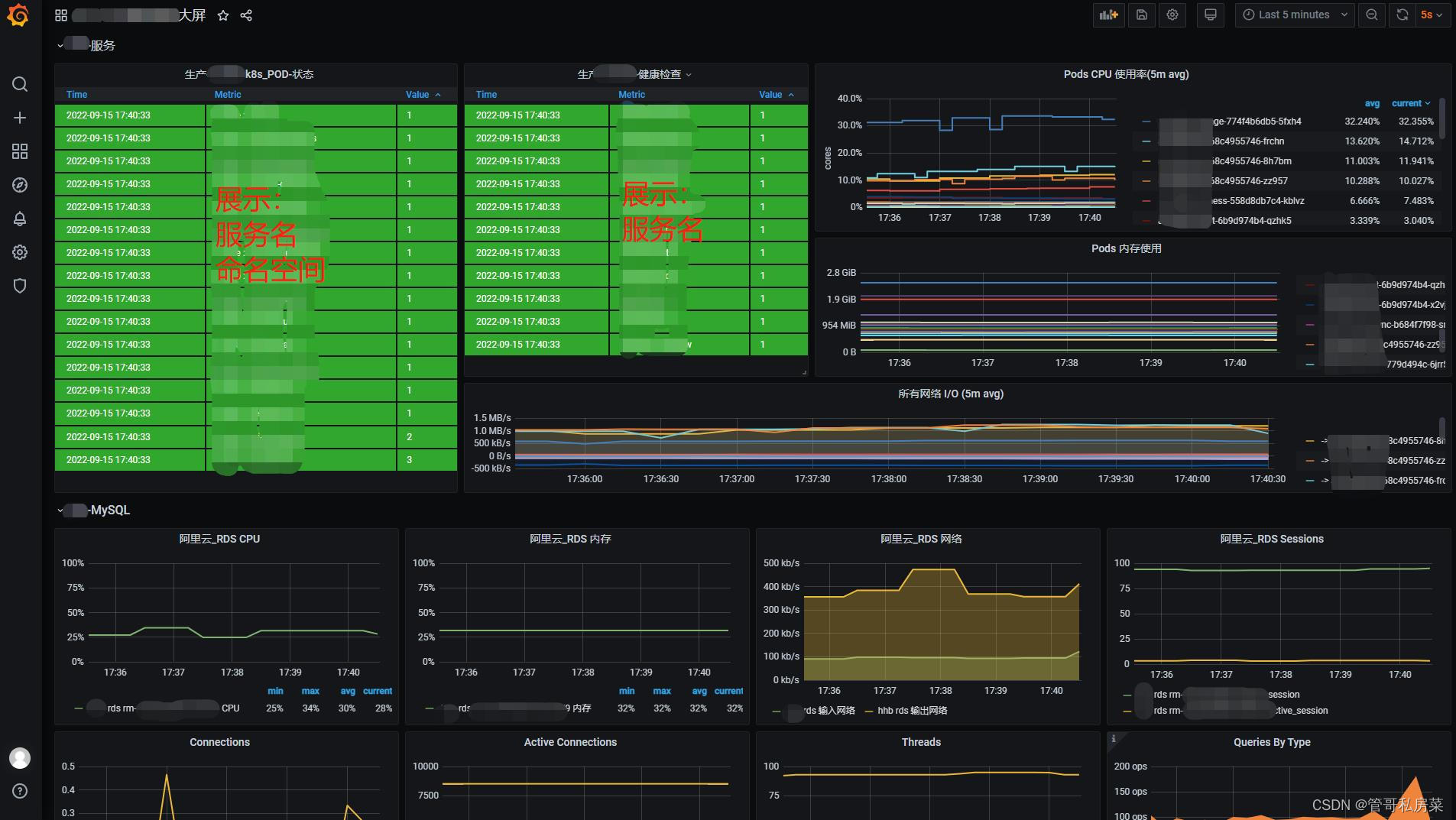
总体大屏: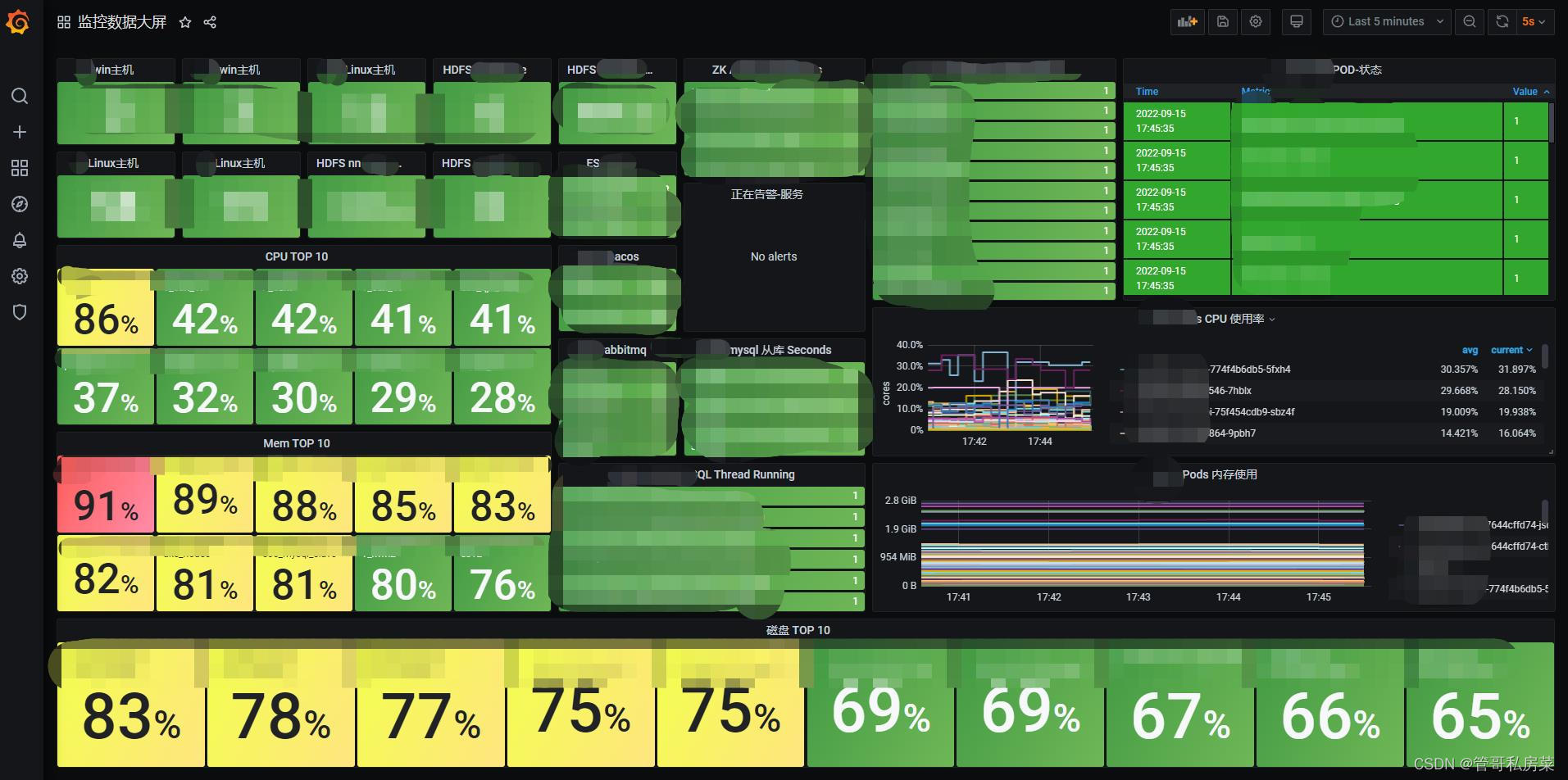
K8S大屏: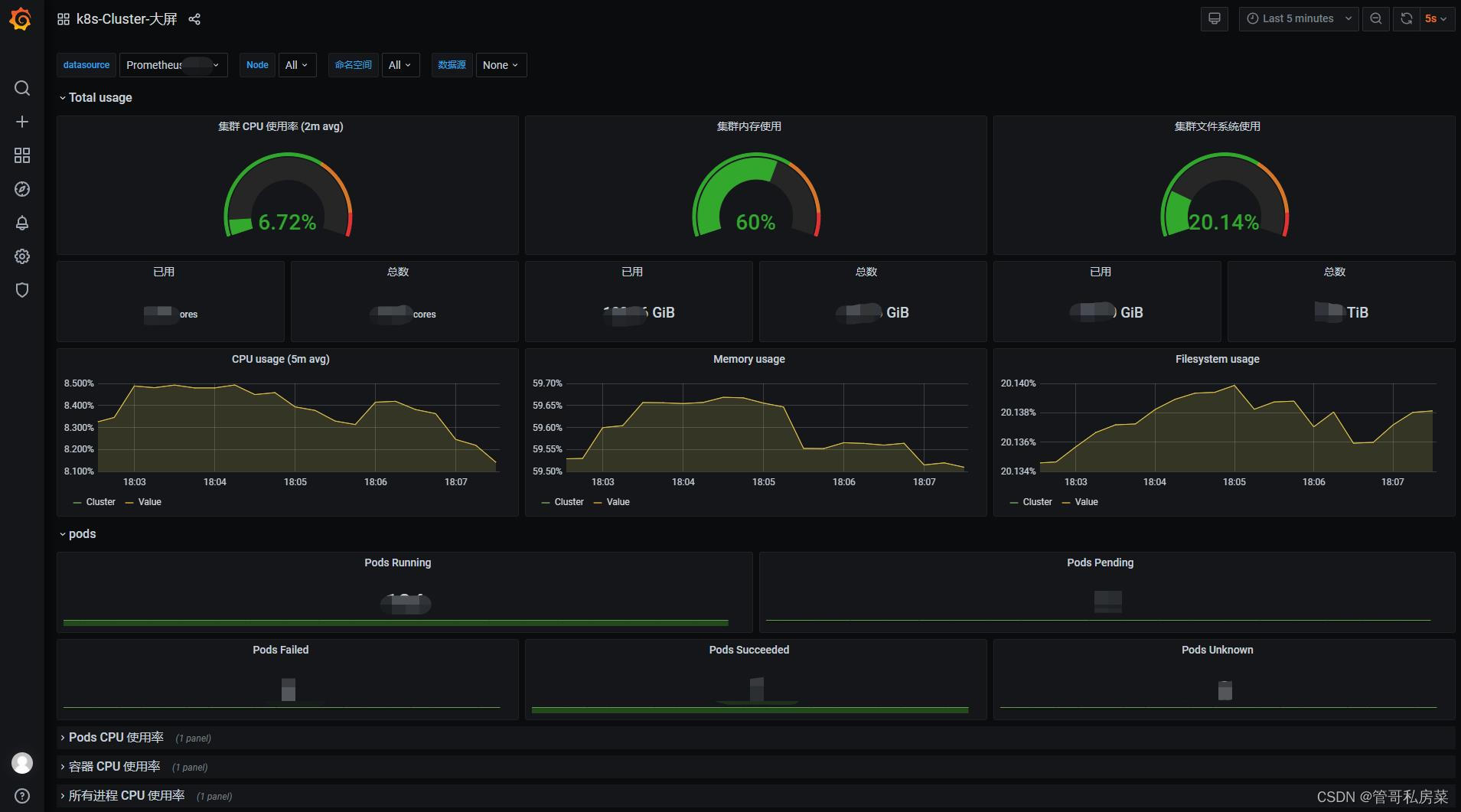
Linux 主机大屏: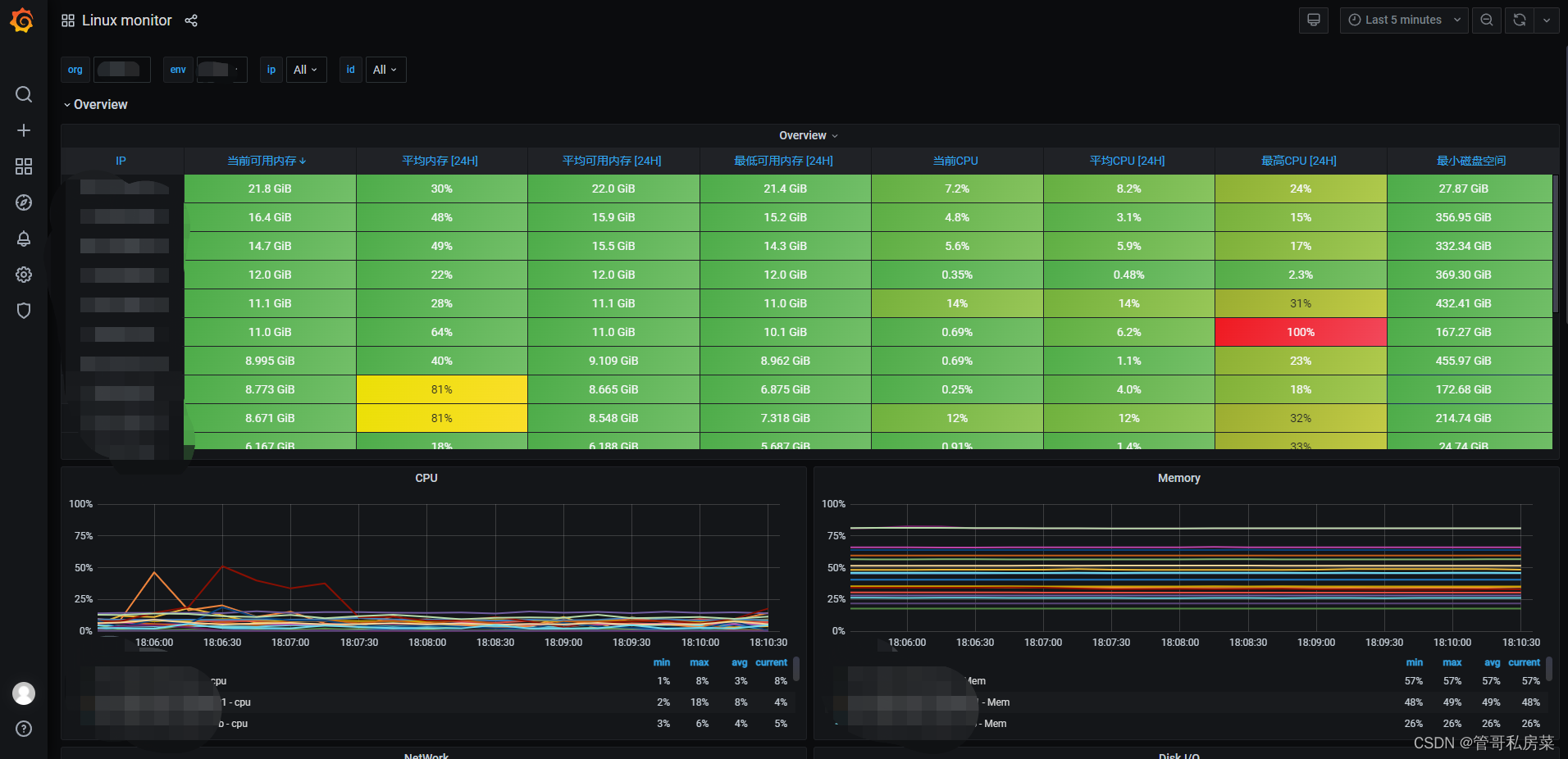
说明:
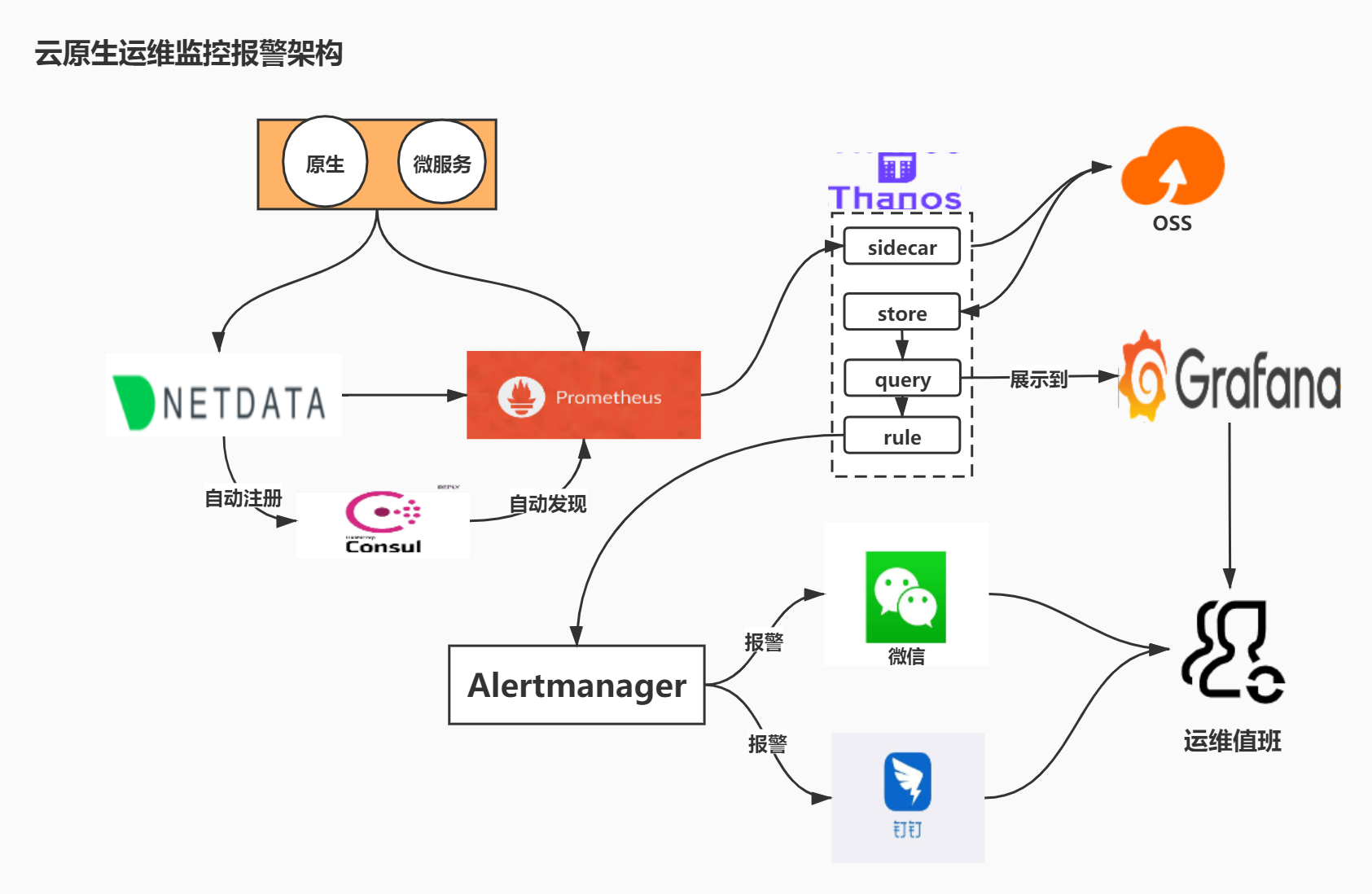
- 使用Prometheus(https://github.com/prometheus)原生的k8s服务发现驱动,采集容器化信息;通过微服务参数配置,暴露运行状态信息提供给prometheus,实现微服务信息采集;
- 通过新引入的netdata(https://github.com/netdata/netdata)做为采集器,采集除了微服务、k8s以外的所有资源信息;
- 通过consul解决新节点自动注册和发现问题;
- 使用prometheus时序数据库,解决存储效率问题;
- 通过thanos实现多个Prometheus实例构建集群模式;
- 使用alertmanager实现基础报警统一规则和触发。
后续可以考虑扩展:
- netdata+kafka,将采集数据写入其他引擎
2.2新架构技术特点
netdata特性:
1、效率高,资源开销低
2、可扩展性强,社区活跃,github 50k start
3、自带web界面,信息全,可替代dstat等linux工具
4、支持到秒级甚至实时监控
5、自带120+常用组件采集脚本,减轻工作负担
Prometheus特性:
1、基于时序数据库,存储效率高
2、支持集群模式,组合thanos扩展性强
3、云原生,容器化场景最热门方案
netdata+Prometheus对比zabbix架构
优点:
1、时效性从分钟级提高到秒级
2、存储、查询效率高
3、每个客户端提供一个漂亮的web界面、信息全,可大量减少登录服务器查询的次数
4、支持集群模式,扩展性强
5、直接支持一部分暴露jmx、metric信息的服务,减少监控脚本配置工作量
6、云计算、容器化场景更适合
7、数据持久化,原则支持无限长时间数据
8、支持降采样,极大提高长时间跨度查询效率
9、云原生项目,可容器化
缺点:
1、指标众多,需进行适当裁剪
2、自定义数据类型,有误差(最大误差0.0001%)
3、自定义采集脚本需要脚本开发能力(go、python),相比zabbix(shell)学习成本高
总结:
通过对比、了解业务各种报警监控采集方案,采用netdata + Prometheus + consul + thanos方案,效率更高、功能更强大、可扩展性强,较为符合云原生业务发展和需求。
最后
以上就是危机蜡烛最近收集整理的关于运维监控之——云原生运维监控报警架构(prometheus+grafana+netdata+Thanos+Alertmanager+Consul)的全部内容,更多相关运维监控之——云原生运维监控报警架构(prometheus+grafana+netdata+Thanos+Alertmanager+Consul)内容请搜索靠谱客的其他文章。








发表评论 取消回复