一、主从复制过程
master 服务器将数据的改变记录二进制 binlog 日志,当 master 上的数据发生改变时,则将其改变写入二进制日志中;
slave 服务器会在一定时间间隔内对 master 二进制日志进行探测其是否发生改变,如果发生改变,则开始一个 I/OThread 请求 master 二进制事件;
同时主节点为每个 I/O 线程启动一个 dump 线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动 SQL 线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后 I/OThread 和 SQLThread 将进入睡眠状态,等待下一次被唤醒。
1.1 binlog
主从复制是在binlog的基础上进行的
binlog格式可以设置为:statement、row、mixed三种
- Statement 基于语句,只记录对数据做了修改的SQL语句,能够有效的减少binlog的数据量,提高读取、基于binlog重放的性能
- Row 只记录被修改的行,所以Row记录的binlog日志量一般来说会比Statement格式要多。基于Row的binlog日志非常完整、清晰,记录了所有数据的变动,但是缺点是可能会非常多,例如一条update语句,有可能是所有的数据都有修改;再例如alter table之类的,修改了某个字段,同样的每条记录都有改动。
- Mixed Statement和Row的结合,怎么个结合法呢。例如像update或者alter table之类的语句修改,采用Statement格式。其余的对数据的修改例如update和delete采用Row格式进行记录。
# 临时关闭当前session的log-bin
mysql> set session sql_log_bin=0;
# 使用 purge 进行切割,这样之前的binlog就会都被清理掉
mysql> purge binary logs to 'log-bin.000003';
1.2 relaylog
二、异步复制、半同步复制
2.1 slave io_thread
1.根据master的ip和port,slave_io线程连接到master,如果连接不上,会发起重试
间隔时间:master_connect_retry(默认 60s)
2.发送sql命令 设置主库master_heartbeat_period(默认slave_net_timeout/2)以及计算主从时间差 clock_diff_with_master(主从机器的系统时间差+网络延迟)
3.io线程发送com_binlog_dump协议请求
4.waiting for master to send event
5.queueing master event to the relay log唤醒sql线程
6.修改master log pos的值 flush master_info(FLUSH频率为sync_master_info的值)将主库信息写入master_log_info表
7.继续步骤3 循环
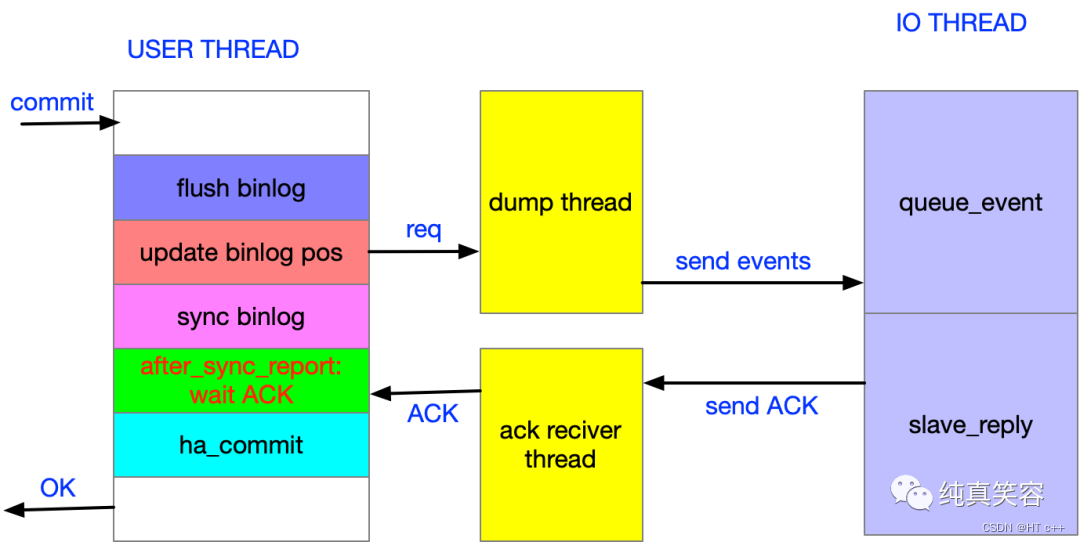
2.2 主库binlog_dump流程
1.DUMP线程收到COM BINLOG DUMP报文,解析上送filename和pos,并设置心跳包间隔时间master heartbeat period以及发送ROTATE EVENT更新从库的masterlog_name
2.进入"Sending binlog event to slave"状态,准备发送event到SlavelO线程
3.获取读取的binlog的尾指针位置,如果已达到hot binlog即最新的binlog文件)的尾部,则处于"Master has sent all binlog to slave; waiting for more updates"等待主库产生binlog
4.获取到尾指针,将相关的event发送到SlavelO一个文件结束
5.继续下个文件执行步骤3,如此循环 纯真笑容
2.3 slave_sql线程流程
1.对SlaveSQL线程进行参数初始化,并设置需要开始读取relaylog的name和 pos.
2.进入"Reading event from the relay log"状态,开始读取event
3.如果没有新event,进入"Slave has read all relay loq: waiting for more updates"状态,等待Slave_IO线程写入新event
4.读取到event设置lastmastertimestamp以及sql线程的starttime计算主从延时的重要依据)并判断是否需要跳过event的apply
5.根据event的数据在从库进行apply应用处理
6.对于非xid的event,更新读取relaylog的文件指针即event relaylog pos值当一个事务结束时候,会flushinfo(true)将rli信息强制写入relayloginfo表(默认 relay_log_info_repository=TABLE)
7.再次读取下个event进入步骤2如此循环 纯真笑容
2.4 半同步复制
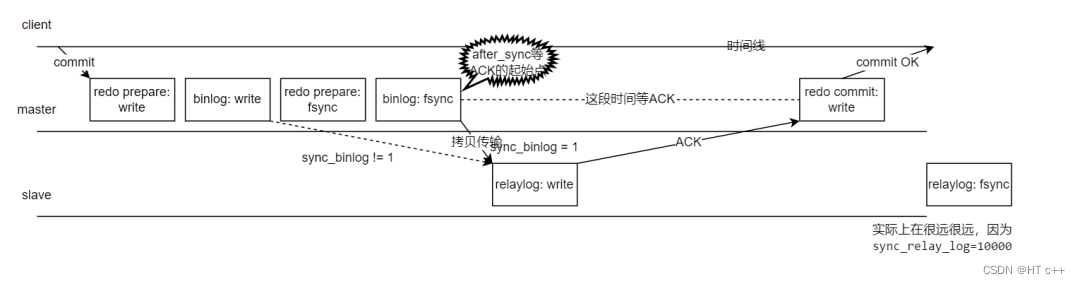
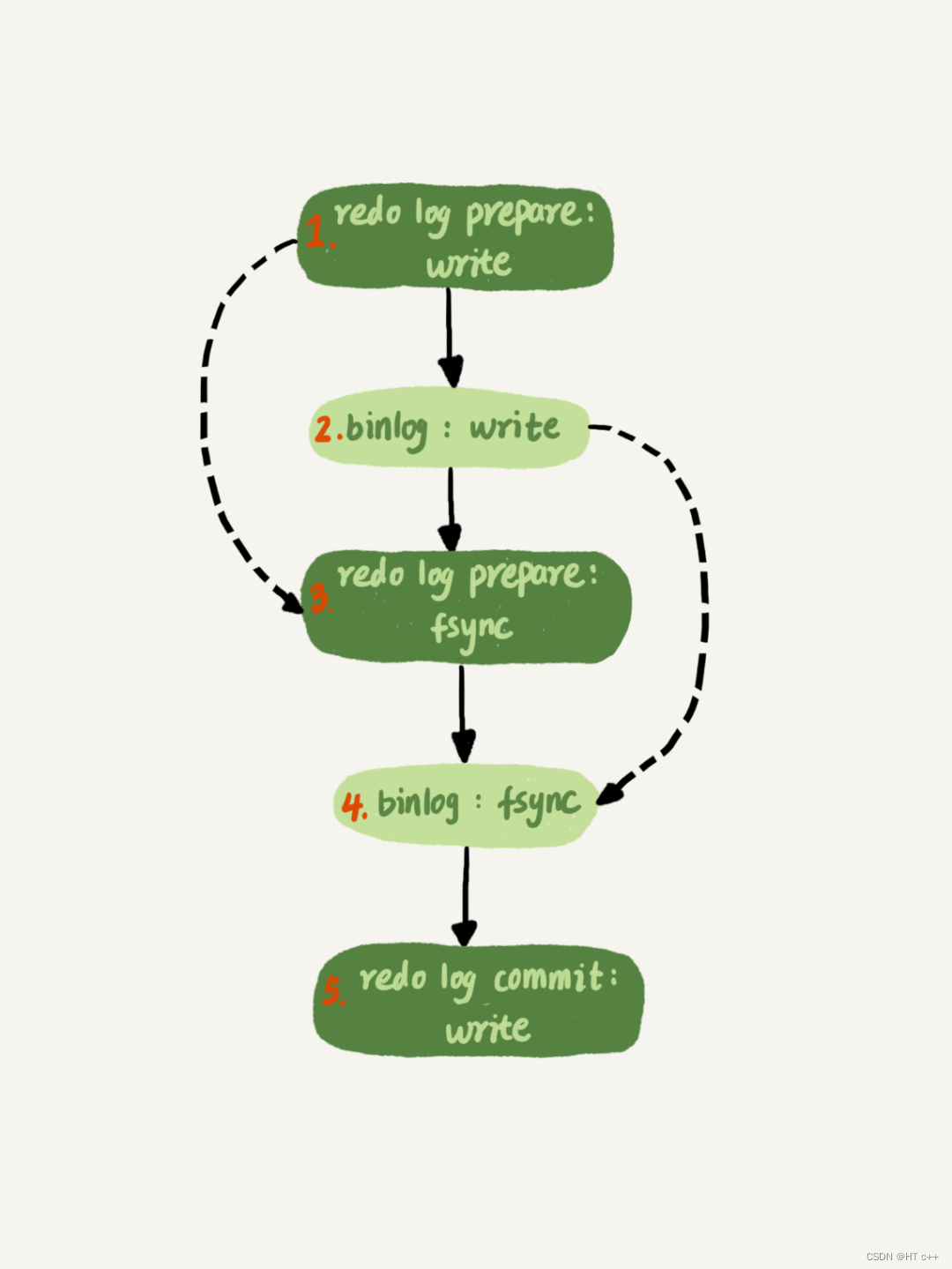
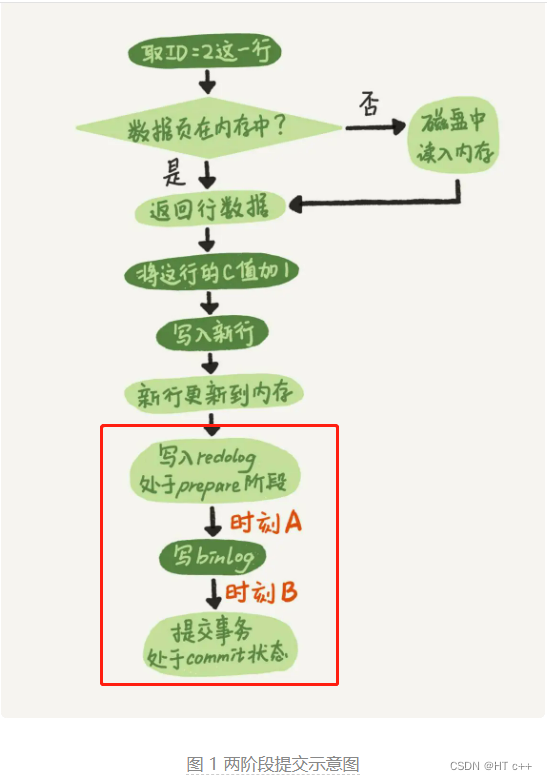
- 用户在 client 处执行 commit 提交了事务,主库写入了 redo 文件,对应"redo prepare: write"
- binlog: write—— master 节点写入 binlog 文件。 redo prepare: fsync——
- 传说中的两阶段提交的第一阶段 prepare 刷盘(从 OS 层 page cache 持久化刷新到硬盘)了。
- binlog:fsync—— binlog 刷盘。
- 拷贝 binlog 到 slave 写入到 relaylog 文件,写完则返回 ACK 给master 节点,表示收到这个 binlog 了,relaylog 根据参数sync_relay_log=10000每 10000个事务刷一次刷盘(因为我们只讨论主库 crash 的情况,这个从库 relay 刷盘行为我们不用管)
- 根据参数设置rpl_semi_sync_master_wait_point=AFTER_SYNC,所以在这个位置点开始等待 slave 节点完成"relaylog: write",然后返回个 ACK 给 master。
- master 节点收到 ACK 后,知道从库收到这个binlog 后就可以提交事务了,发起"redo commit:write",传说中的两阶段提交的第二阶段 commit阶段,commit 到文件。
- master 回复客户端 ACK: commit OK。
2.4.1 sync binlog
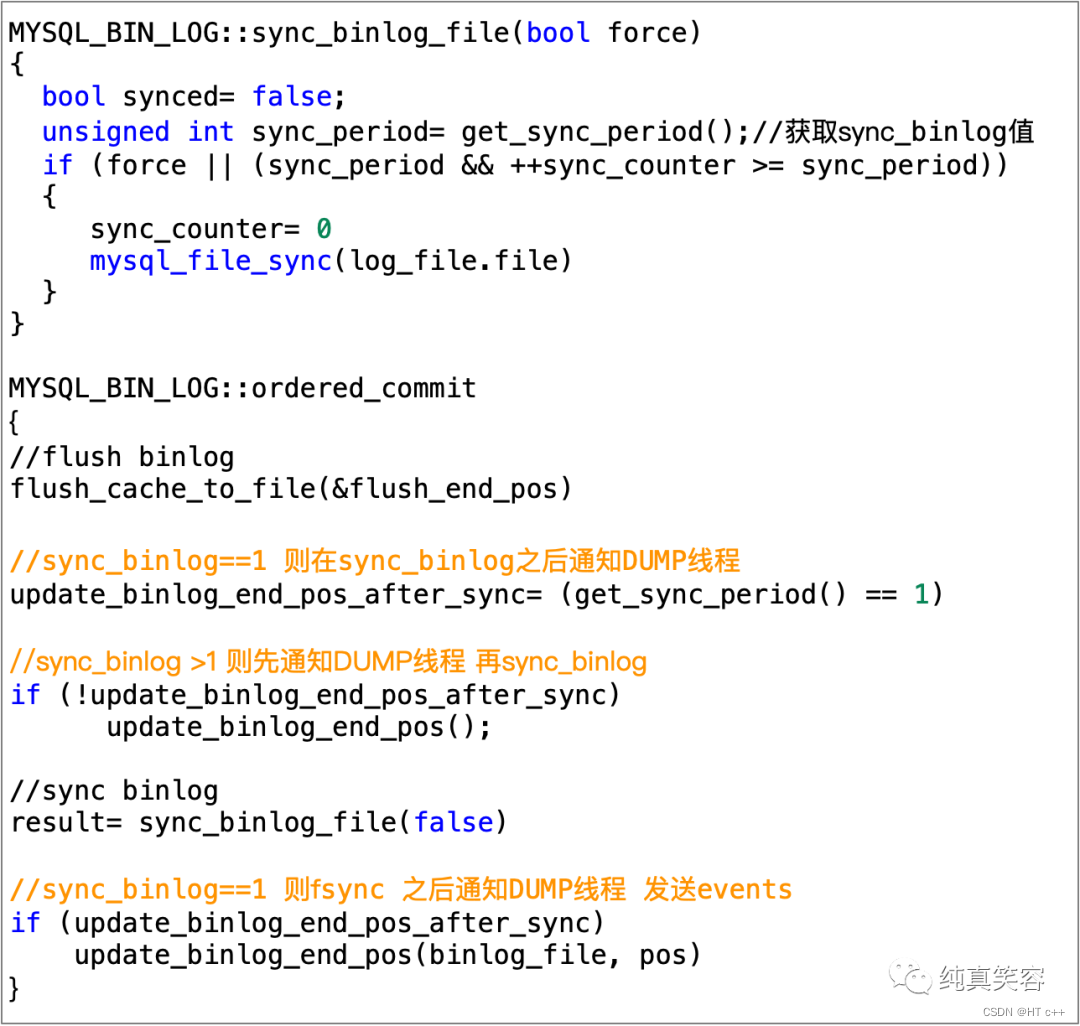
-
当sync_binlog为0的时候,binlog sync磁盘由OS负责.
-
当sync_binlog值大于1的时候,sync binlog操作可能并没有使binlog落盘(需要达到sync_binlog值之后才会进行fsync).如果没有实际落盘,事务在提交前,Master crash了,Master再次启动后原事务就会被回滚。但可能Dump线程已将events同步到Slave,并且Slave已经应用了这些events,这也会导致Slave数据比Master多,主备同步失败。
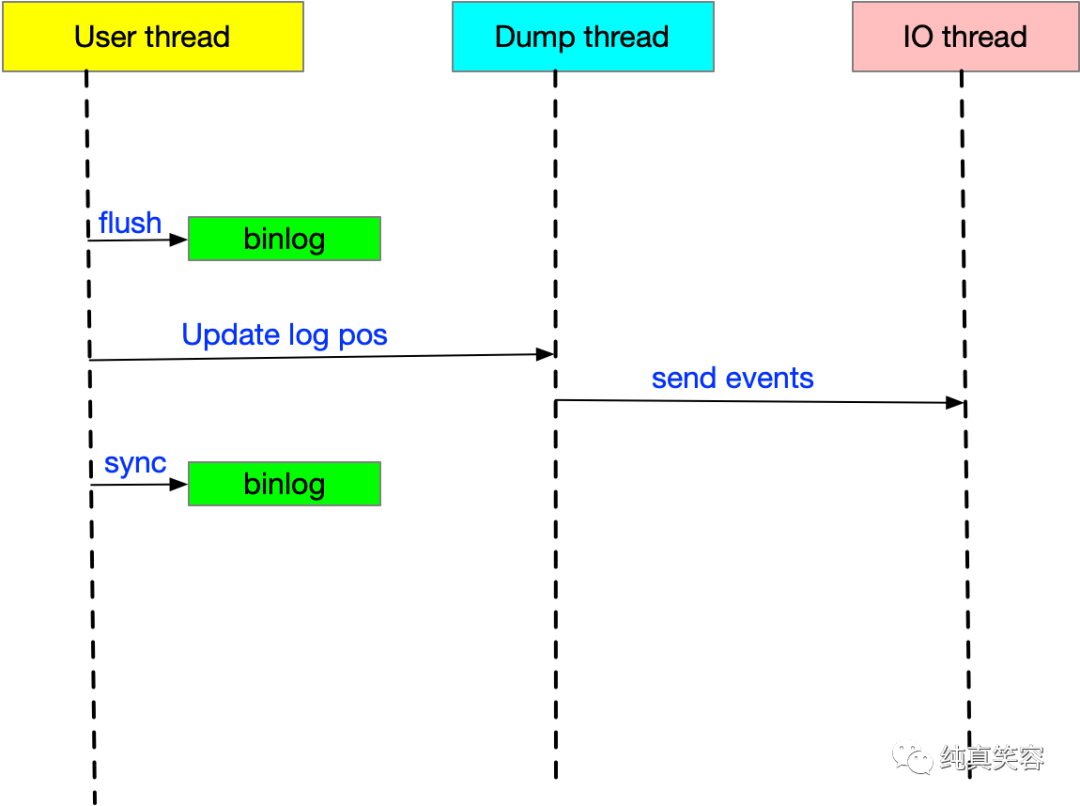
2.4.2 sync relay log
- 参数解释
当sync_relay_log为0的时候,relaylog sync磁盘由OS负责.
当sync_relay_log>1的时候,semisync返回给Master的position可能没有fsync到磁盘.
sync_relay_log=1的时候,会保证semisync返回给Master的positiony已经fsync到磁盘.
- 异常举例:
在gtid_mode下,在sync_binlog=1的情况下,sync_relay_log不是1的时候,仅发生Master或Slave的一次Crash并不会发生数据丢失或者主备同步失败情况。
如果发生Slave没有sync relay log,Master端事务提交,然后Slave端Crash。这样Slave端就会丢失掉已经回复Master ACK的事务events。
但当Slave再次启动,如果没有来得及从Master端同步丢失的事务Events,Master就Crash。这个时候,用户访问Slave就会发现数据丢失.
如果完全要保证半同步的主从数据的一致性需要设置sync_binlog和sync_relay_log都为1,但是这会带来性能的瓶颈(尤其是sync_relay_log为1 每同步一个event就需要fsync).所以实际的应用中,会根据数据一致性和性能的综合考虑设置合理的值.
三、常见主从报错与解决方式
3.1 Last error主从数据不一致
查看导致last error产生的信息
#方法1——通过binlog查询
show binlog events in 'mysql-bin.032102' from 730019106 limit 10; #找到对应行,该行中Info信息就是1973位置所做操作
#方法2——通过ps表查询
select * from performance_schema.replication_applier_status_by_worker where LAST_ERROR_NUMBER=1396
如果确认可以跳过或者短时间无法解决
# 跳过指定数量的事务,通常为1跳过当前出错事务
mysql > stop slave ;
mysql > set global sql_slave_skip_counter=1
mysql > start slave ;
# 跳过指定类型的错误或者所有错误
vi /etc/my.cnf
[mysqld]
slave-skip-errors=1062,1146,2341 #跳过指定错误类型
slave-skip-errors=all #跳过所有错误,不建议使用
# GTID模式下跳过事务
stop slave;
set gtid_next='fb6d07d2-a253-1212-b2fh-29255eg3f3g:23' #show slave status信息中retrieved_gtid_set里的gtid为
fb6d07d2-a253-1212-b2fh-29255eg3f3g:18-23
begin;commit; #手动指定gtid_next,如果gtid已经存在于实例的GTID集合中,该事务会被忽略;如果没有存在于GTID集合中就将这个gtid分配给接下来要执行的事务,系统不需要给这个事务生成新的GTID
set gtid_next='AUTOMATIC'; #修改回自动获取GTID
start slave;
# 使用gtid_purged跳过事务
show slave status G; #先查看executed_gtid_set的值,该值有两行,看下面那行
show variables like '%gtid_purged%' #查看主库purged值,假设末尾是1-33
reset master #清空从库binlog和gtid_executed状态
set global gtid_purged='xxxxxxxxxxxxxxxxxxxxxxxxx:1-33'; 跳过1-33的事务
start slave; #主从状态恢复后需手动补跳过的事务所产生的数据
3.2 连接主库报错
Last_IO_Errno: 1040
Last_IO_Error: error reconnecting to master 'repl@10.0.0.51:3307' - retry-time: 10 retries: 7
通过复制用户 手动连接
判断是否是主库连接数过多还是防火墙不同
3.3 relay log损坏
Last_SQL_Error: Error initializing relay log position: I/O error reading the header from the binary log
Last_SQL_Error: Error initializing relay log position: Binlog has bad magic number;
It's not a binary log file that can be used by this version of MySQL
找到同步的binlog和POS点,然后重新做同步,这样就可以有新的relaylog
Relay_Master_Log_File: mysql-bin.000010
Exec_Master_Log_Pos: 821
mysql> stop slave;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000010',MASTER_LOG_POS=821;
Query OK, 0 rows affected (0.01 sec)
mysql> start slave;
3.4 主库crash 从库重复回放
在开启 GTID 模式下,如果指定 master_auto_position=1,start slave 时,从库会把 Retrieved_Gtid_Set 和 Executed_Gtid_Set 的并集发送给主库,主库将收到的并集和自己的 gtid_executed 比较,把从库 GTID 集合里缺失的事务全都发送给从库。
主机重启后,事务重复回放,表明 Retrieved_Gtid_Set 和 Executed_Gtid_Set 的并集中有 GTID 事务丢失,导致重复获取事务执行引发主键冲突错误。
Retrieved_Gtid_Set 和 Executed_Gtid_Set 均为内存变量,MySQL 重启后,Retrieved_Gtid_Set 初始化为空值,从而推断出 Executed_Gtid_Set 有 GTID 事务丢失。
Executed_Gtid_Set 来源于 gtid_executed 变量,gtid_executed 变量持久化介质有 mysql.gtid_executed 表和 binlog 日志
当 log_bin=on ,log_slave_updates=on 时,只有在 binlog 切换时侯才会更新 mysql.gtid_executed 表,保存直到上一个 binlog 执行过的 GTID 集合。MySQL 重启后,在默认参数 binlog_gtid_simple_recovery=1 时,gtid_executed 变量值从最后一个 binlog 文件计算获得
Worker 线程报 1062 主键冲突错误–> gtid_executed 信息陈旧–> binlog 未实时持久化
3.5 级联复制报错
针对双主级联复制,需要检查从库的read_only选项,双主模式下的自增步长,以及log_slave_updates参数,否则双主模式下,可能会有问题
3.6 主从切换后gtid不一致
从库之前执行过命令导致产生了新的gtid,并且该gtid所在的binlog已经被清理
导致发生主从切换之后,新从库同步复制新主库时,由于master_auto_position=1模式下,从库会将当前已经执行过的gtid集合发送给主库,主库接收到从库发送的gtid集合后,会与当前已经执行的gtid set求差值,并将没有执行过的gtid发送给备库,由于binlog被清理导致无法将gtid发送给从库(gtid_purged没有包含)
解决:在新从库手动跳过缺失的gtid(注:跳过缺失的gtid,意味着不在从库执行缺失的事务,可能导致数据的丢失)
数据恢复:利用主库备份重做或者利用binlog备份 恢复到原来的日志目录(需要的binlog要从第一个包含缺失的gtid日志到当前的全部日志)
3.7 多线程复制报错
对于多线程复制,slave_pending_jobs_size_max变量设置用于保存尚未应用的event的工作队列可用的最大内存量(以字节为单位)。设置此变量对未启用多线程处理的复制没有影响。设置此变量不会立即生效。必须要停掉复制之后,重新start slave。
此变量的最小值为1024;默认值为16MB。最大可能值为18446744073709551615(16 EB)。
此变量的值是软限制,可以设置为与正常工作负载匹配。如果异常大的事件超过此大小,事务将被保留,直到所有工作线程都有空队列,然后进行处理。如果内存富余,或者延迟较大时,可以适当调大;注意这个值要比主库的max_allowed_packet大!
当worker线程正在处理的event的总大小超过slave_pending_jobs_size_max变量的大小时,将发生此等待操作。此时可有在主库看到线程的状态为:Waiting for Slave Workers to free pending events
Last_SQL_Error: Cannot schedule event Rows_query, relay-log name /data/mysql_4306/log/slave-relay-bin.004764, position 912733141 to Worker thread because its size 21520792 exceeds 18777088 of slave_pending_jobs_size_max.
#从库
set global slave_pending_jobs_size_max=
四、主从延迟解决方式
4.0 mysql8 查看主从延迟的方式
SELECT LAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMP - LAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP
FROM performance_schema.replication_applier_status_by_worker
4.1 无主键、无索引或索引区分度不高
特点:
a. show slave status 显示position一直没有变
b. show open tables 显示某个表一直是 in_use 为 1
c. show create table 查看表结构可以看到无主键,或者无任何索引,或者索引区分度很差。
备库
set global slave_rows_search_algorithms='TABLE_SCAN,INDEX_SCAN,HASH_SCAN';
或者
set sql_log_bin=0;
alter table xx add key xx(xx);
4.2 主库上有大事务,导致从库延时
#binlog 中最大的 10 个事务的大小
mysqlbinlog -vv mysql_bin.000164>/tmp/0164.log
cat /tmp/0164.log|grep "GTID$(printf 't')last_committed" -B 1|grep -E '^# at'|awk '{print $3}'|awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp);tmp=$1}'|sort -n -r|head -n 10
4.3 主库写入频繁,从库压力跟不上导致延时
4.4 大量myisam表,在备份的时候导致slave延迟
首先查看从库是否有负载,根据是否有负载进行区别对待,注意这里的负载一定要使用 top -H 查看 io/sql/worker 线程的负载
最后
以上就是精明果汁最近收集整理的关于MySQL主从复制原理学习一、主从复制过程二、异步复制、半同步复制三、常见主从报错与解决方式的全部内容,更多相关MySQL主从复制原理学习一、主从复制过程二、异步复制、半同步复制三、常见主从报错与解决方式内容请搜索靠谱客的其他文章。








发表评论 取消回复