今天,为了满足我女朋友作业的需求,我使用Python制作了一个图片转文字的小应用。
(当然,下面导入模块的问题我就不多说了,是非常简单的)

一. 申请百度通用文字识别接口。
1.先在百度AI开放平台注册账号(点击这里进入百度智能云)。一般使用百度账号即可。

2.注册成功后登录,在右侧菜单栏中寻找文字识别功能。
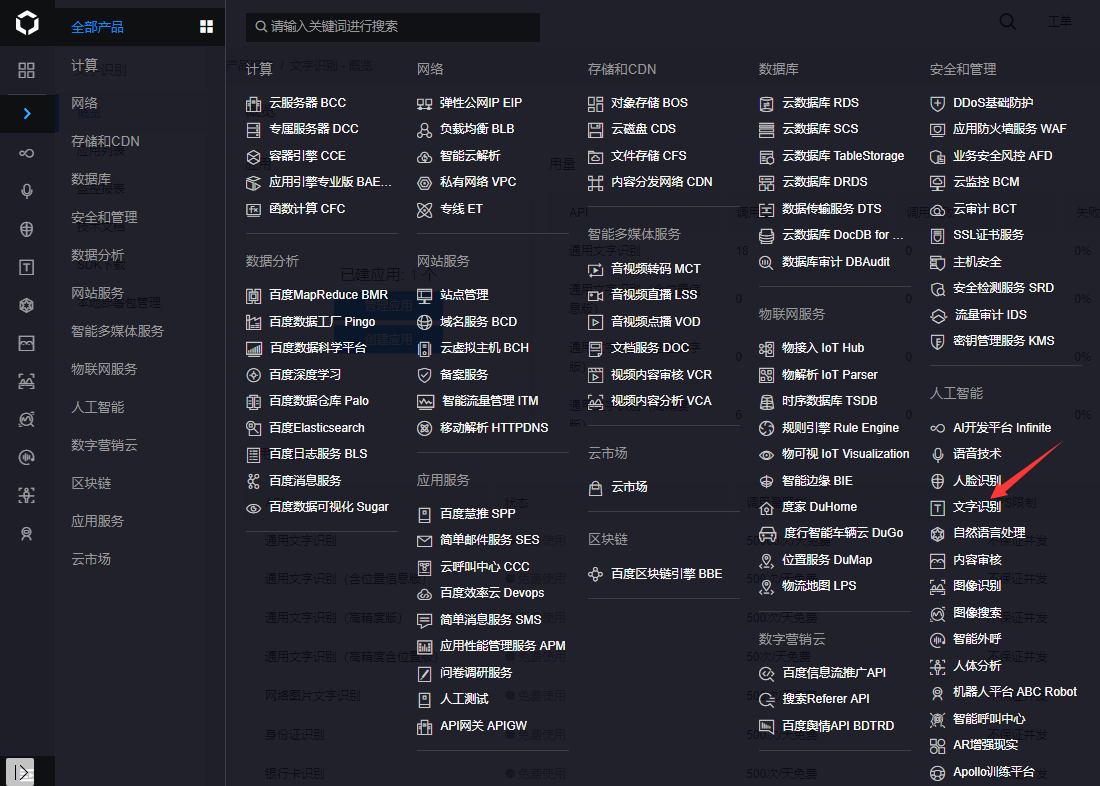
3.进入后创建一个新的应用,并按要求填写好应用名称等信息后,立即创建即可。
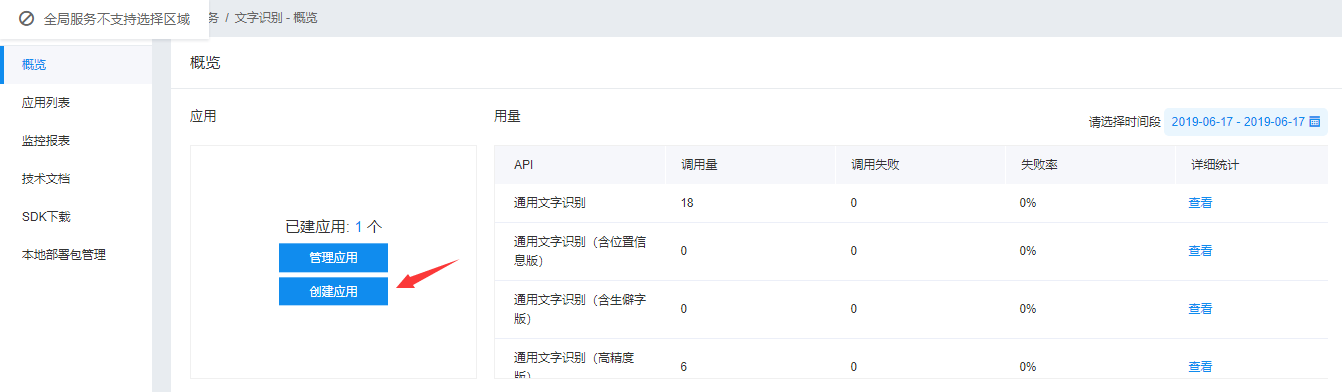
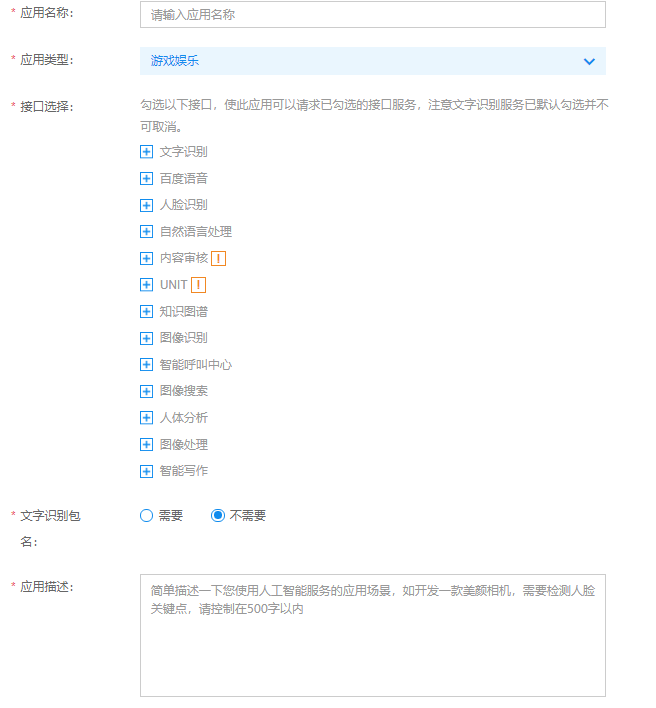

二. 到了这一步,我们真正的进入到程序中来。
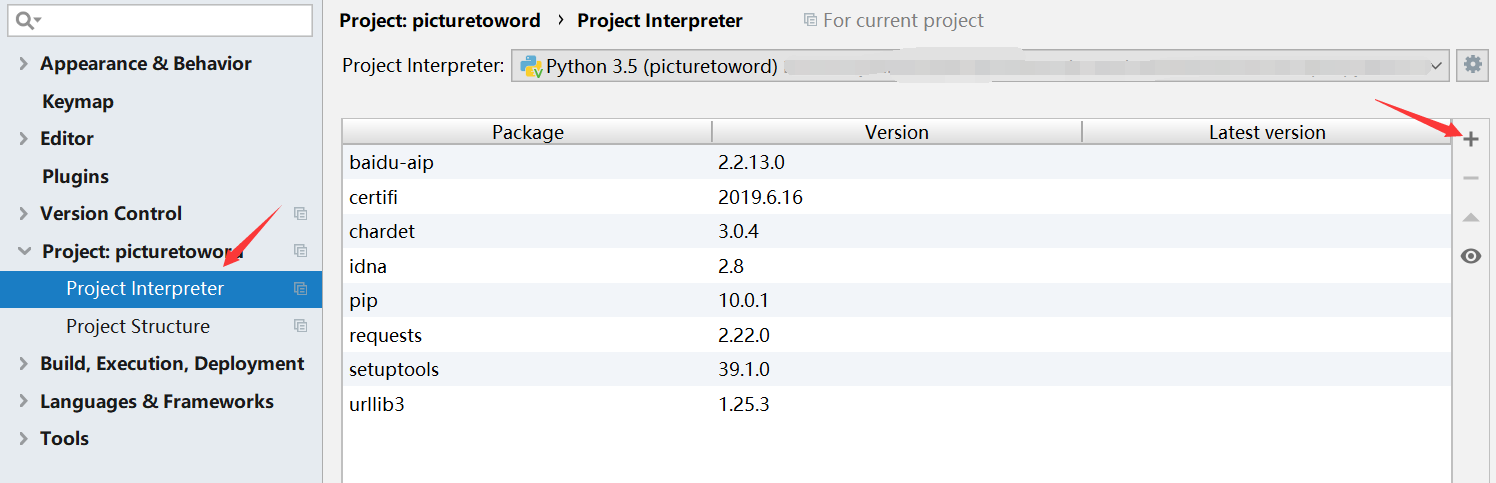
1.baidu-aip模块安装
在Pycharm中新建Project,在工程文件夹中新建一个py文件,命名随意。点击File->Setting,进入Setting。刚开始没有baidu-aip模块,点击右侧加号搜索baidu-aip进行安装。
2.因为我们这次只测试两张图片,所以我们在与py文件同级下新建一个目录images,里存放我们需要识别的所有图片(这些图片最好按1,2……命名,在读入时会按数字顺序一张一张扫描)。
------1.jpg

-----2.jpg

3.首先我们先找到这些图片所在文件夹的路径
PROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))#获取项目根目录
path = os.path.join(PROJECT_ROOT,"images") #文件路径
4.将百度AppID, API Key, Secret Key这些关键信息写入调用百度ORC接口。这里要导入我们安装好的baidu-aip模块了。
"""你的百度AppID, API Key, Secret Key"""
APP_ID = '16545975'
API_KEY = 'qbK2kKKtrXTo0rE1rg4M6Tl6'
SECRET_KEY = 'xxxxxxxxxxxx'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
5.定义打开图片的函数
"""打开文件,读取图片"""
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
6.循环读入目录中的每一张图片
for r, ds, fs in os.walk(path):
for fn in fs:
fname = os.path.join(r, fn)
image = get_file_content(fname)
ret = client.basicGeneral(image)
#print(ret)
#print(ret['words_result'])
for item in ret['words_result']:
print(item['words'])
5.接下来我们一步一步的分析结果,首先我们调用通用文字识别,打印结果看看是什么吧!(我们只截前面一部分)
# 调用通用文字识别,图片参数为本地图片
ret = client.basicGeneral(image)
print(ret)

可以看到,结果是一个字典,我们需要的图片内容都在关键字为words_result中,又可以发现,这个关键字的值是一个列表。我们先把这个字典中的words_result关键字的值取出来并打印。
print(ret['words_result'])

这样我们就取出了这个列表,图片中文字的内容是分段显示的,每一段又是一个字典(在图片中每一次换行都会形成一个字典),这就很简单了,我们只需要把每个字典中的关键字word的值取出来拼接上不就是我们图片中想要的内容了吗?这就要借助我们的循环。
for item in ret['words_result']:
print(item['words'])

可以看到,输出的格式和图片中的格式是完全一样的。两张图片的内容已经被我们全部扫描出来了。
到这里这个小应用就全部结束了,大家可以根据需要继续完善,例如将输出结果保存到文本文件中等等。表情包中的文字也是可以识别的哦!
今天拿着QQ文字扫描发现QQ识别率还是很高的,但是一张一张太麻烦了,我想还是让他们自己来识别更方便。
完整代码:
from aip import AipOcr
import os
"""你的百度AppID, API Key, Secret Key"""
APP_ID = '16545975'
API_KEY = 'qbK2kKKtrXTo0rE1rg4M6Tl6'
SECRET_KEY = 'xxxxxxxxxxx'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
"""打开文件,读取图片"""
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
PROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))#获取项目根目录
path = os.path.join(PROJECT_ROOT,"images") #文件路径
for r, ds, fs in os.walk(path):
for fn in fs:
fname = os.path.join(r, fn)
image = get_file_content(fname)
ret = client.basicGeneral(image)
for item in ret['words_result']:
print(item['words'])
最后
以上就是直率黑猫最近收集整理的关于使用百度文字识别API进行图片中文字的识别的全部内容,更多相关使用百度文字识别API进行图片中文字内容请搜索靠谱客的其他文章。








发表评论 取消回复