自古以来,我们就希望预知未来,现如今,随着大数据人工智能技术的发展,我们早已经不满足传统的同比、环比等数据分析方法,但是时间序列趋势预测的传统算法又很专业,很难用于日常生产经营中。
深度学习神经网络为我们提供较为通用的解决方案,我们将在这里实践基于Python Keras LSTM多维输入输出时序预测模型。
1. 关于时间序列分析
1.1. 时间序列分析
时间序列就是按时间顺序排列的一组数据序列,以揭示随着时间的推移发展规律这一现象。时间序列有如下四个特点:
- 趋势性:某个变量随着时间进展或自变量变化,呈现一种比较缓慢而长期的持续上升、下降、停留的同性质变动趋向,但变动幅度可能不相等。
- 周期性:某因素由于外部影响随着自然季节的交替出现高峰与低谷的规律。
- 随机性:个别为随机变动,整体呈统计规律。
- 综合性:实际变化情况是几种变动的叠加或组合。预测时设法过滤除去不规则变动,突出反映趋势性和周期性变动。
时间序列分析就是发现这组数据的变动规律并用于预测的统计技术,也就是根据过去的变化趋势预测未来的发展,它的前提是假定事物的过去延续到未来。
时间序列分析有三个基本特点:
- 假设事物发展趋势会延伸到未来
- 预测所依据的数据具有不规则性
- 不考虑事物发展之间的因果关系
我们日常工作生活中,时间序列分析应用和需求非常多,例如加油站经营者想知道我们下一次加油时间、加多少油,或者,被竞争者抢走。
再例如我们投资股票,十分想知道未来股票价格走势、成交量,和量化交易AI机器人博弈。
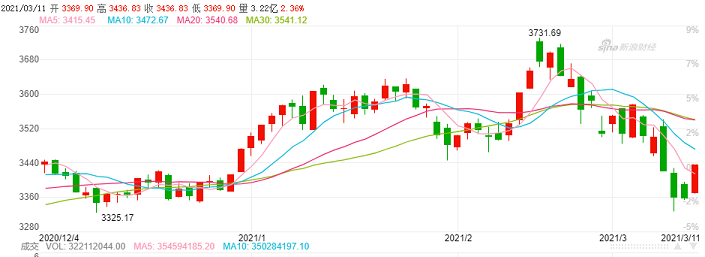
针对时间序列的预测,传统常用方法包括灰色预测,指数平滑或ARIMA模型。现如今我们已经从机器学习特征工程着手,时间滑窗改变数据的组织方式,使用xgboost/LSTM模型/时间卷积网络等算法进行时序预测分析。
1.2. 时间序列分析与回归分析区别
回归分析对数据的假设:独立性
在回归分析中,我们假设数据是相互独立的。这种独立性体现在两个方面:一方面,自变量(X)是固定的,已被观测到的值,另一方面,每个因变量(y)的误差项是独立同分布,对于线性回归模型来说,误差项是独立同分布的正态分布,并且满足均值为0,方差恒定。
这种数据的独立性的具体表现就是:在回归分析中,数据顺序可以任意交换。在建模的时候,你可以随机选取数据循序进行模型训练,也可以随机选取一部分数据进行训练集和验证集的拆分。也正因为如此,在验证集中,每个预测值的误差都是相对恒定的:不会存在误差的积累,导致预测准确度越来越低。
时间序列对数据的假设:相关性
对于时间序列分析而言,我们必须假设而且利用数据的相关性。核心的原因是我们没有其他任何的外部数据,只能利用现有的数据走向来预测未来。因此,我们需要假设每个时间序列数据点之间有相关性,并且通过建模找到对应的相关性,去预测未来的数据走向。这也是为什么经典的时间序列分析(ARIMA)会用ACF(自相关系数)和PACF(偏自相关系数)来观察数据之间的相关性。
时间序列对相关性的假设直接违背了回归分析的独立性假设。在多段时间序列预测中,一方面,对于未来预测的自变量可能无法真实的观察到,另一方面,随着预测时序越来越远,误差会逐渐积累,未来的预测会比近期预测更不确定。
2. LSTM模型
LSTM算法的全称是长短期记忆网络(long short-term memory),由于LSTM算法基于RNN算法改进而来的,一种特殊的RNN网络,规避了标准RNN中梯度爆炸和梯度消失的问题,而且该网络设计出来是为了解决长依赖问题。该网络由 Hochreiter & Schmidhuber (1997)引入,并有许多人对其进行了改进和普及。他们的工作被用来解决了各种各样的问题,直到目前还被广泛应用。
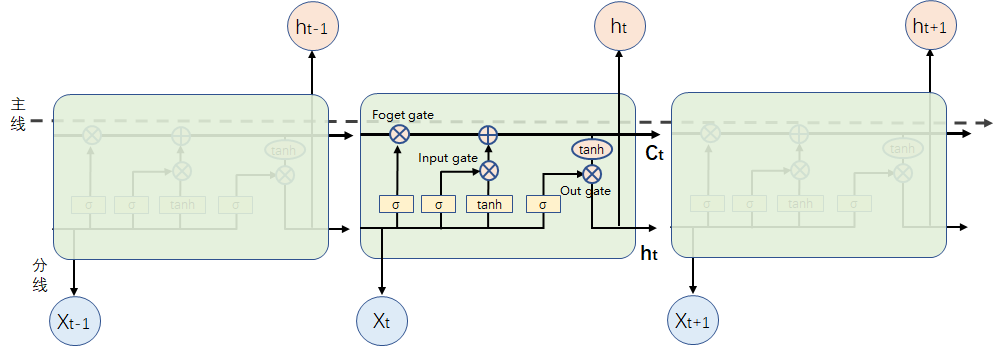
LSTM由四部分组成:输入门、输出门、忘记门、记忆单元
- 输入门(Input gate):决定外界能不能把数据写入记忆单元,只有输入门打开的时候,才能写入数据;
- 输出门(Output gate):决定外界能不能从记忆单元里读取数据,只有输出门打开的时候打,才能读取数据;
- 忘记门(Forget gate):决定什么时候把记忆单元里的数据清除,打开的时候是不清除的,关闭的时候就会清除;
- 记忆单元(Memory cell):LSTM的基本单元,核心所在是 cell 的状态(cell state),也就是上图这条向右的线。
LSTM最大的特点就是:可以有很长时间或距离的记忆能力,而普通的RNN不能记住间距大的信息。
3. Keras LSTM实现多维输入输出时序预测
3.1. 多层LSTM
使用LSTM搭建多层LSTM网络还是比较方便的,我们只需要使用Sequential()进行堆叠即可,一般来说LSTM模块的层数越多(一般不超过3层,再多训练的时候就比较难收敛),对高级别的时间表示的学习能力越强;同时,最后会加一层普通的神经网路层用于输出结果的降维。本案例LSTM堆叠三层。
-
Sequential 用于初始化神经网络
-
Dense 用于添加全连接的神经网络层
-
LSTM 用于添加长短期隐藏层
-
Dropout 用于添加防止过拟合的dropout层

LSTM参数: -
units:定义隐藏层神经元个数(units = self.cell_size)128个
-
input_shape:输入维度,首层时,应指定该值(或batch_input_shape,配合使用stateful=True参数),不限定batche
-
return_sequences:布尔值,默认False,控制返回类型。若为True则返回整个序列,否则仅返回输出序列的最后一个输出
-
activation:激活函数使用relu(activation=‘relu’)
If a RNN is stateful, it needs to know its batch size. Specify the batch size of your input tensors:
- If using a Sequential model, specify the batch size by passing a
batch_input_shapeargument to your first layer.- If using the functional API, specify the batch size by passing a
batch_shapeargument to your Input layer.
batch_input_shape needs the size of the batch: (numberofSequence,timesteps,data_dim)
input_shape needs only the shape of a sample: (timesteps,data_dim).
最后为全连接层(Dense),全连接输出为4个量(Dense(self.output_size)),并使用 TimeDistributed 来将 Dense 层输出转化为时间序列做为最后的输出。
损失函数使用loss=‘mean_squared_error’,优化函数使用optimizer=‘adam’。
超参数:
- TIME_STEPS = 15
- BATCH_SIZE = 30
- INPUT_SIZE = 25
- OUTPUT_SIZE = 4
- PRED_SIZE = 15 #预测输出1天序列数据
- CELL_SIZE = 128
- LR = 0.0001
3.2. Python实践代码
import pandas as pd
import numpy as np
import datetime
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.layers import LSTM,TimeDistributed,Dense,Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
BATCH_START = 0
TIME_STEPS = 15
BATCH_SIZE = 30
INPUT_SIZE = 25
OUTPUT_SIZE = 4
PRED_SIZE = 15 #预测输出1天序列数据
CELL_SIZE = 128
LR = 0.0001
EPOSE = 100
class KerasMultiLSTM(object):
def __init__(self,n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size # LSTM神经单元数
self.batch_size = batch_size # 输入batch_size大小
def model(self):
self.model = Sequential()
#LSTM的输入为 [batch_size, timesteps, features],这里的timesteps为步数,features为维度
# return_sequences = True: output at all steps. False: output as last step.
# stateful=True: the final state of batch1 is feed into the initial state of batch2
'''
self.model.add(LSTM(units = self.cell_size, activation='relu', return_sequences = True , stateful=True,
batch_input_shape = (self.batch_size, self.n_steps, self.input_size))
)
self.model.add(Dropout(0.2))
self.model.add(LSTM(units = self.cell_size, activation='relu', return_sequences = True, stateful=True))
self.model.add(Dropout(0.2))
self.model.add(LSTM(units = self.cell_size, activation='relu', return_sequences = True, stateful=True))
self.model.add(Dropout(0.2))
'''
# 不固定batch_size,预测时可以以1条记录进行分析
self.model.add(LSTM(units = self.cell_size, activation='relu', return_sequences = True ,
input_shape = (self.n_steps, self.input_size))
)
self.model.add(Dropout(0.2))
self.model.add(LSTM(units = self.cell_size, activation='relu', return_sequences = True))
self.model.add(Dropout(0.2))
self.model.add(LSTM(units = self.cell_size, activation='relu', return_sequences = True))
self.model.add(Dropout(0.2))
#全连接,输出, add output layer
self.model.add(TimeDistributed(Dense(self.output_size)))
self.model.compile(metrics=['accuracy'], loss='mean_squared_error', optimizer='adam')
self.model.summary()
def train(self,x_train,y_train, epochs ,filename):
history = self.model.fit(x_train, y_train, epochs = epochs, batch_size = self.batch_size).history
self.model.save(filename)
return history
if __name__ == '__main__':
df = get_train_data()
train_x,train_y,z,sc,col_name,df = set_datas(df,True)
# 训练集需要是batch_size的倍数
k = len(train_x)%BATCH_SIZE
train_x,train_y = train_x[k:], train_y[k:]
model = KerasMultiLSTM(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
model.model()
history = model.train(train_x,train_y,EPOSE,"lstm-model2.h5")
plt.plot(history['loss'], linewidth=2, label='Train')
plt.legend(loc='upper right')
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()
训练结果过程如下图所示:
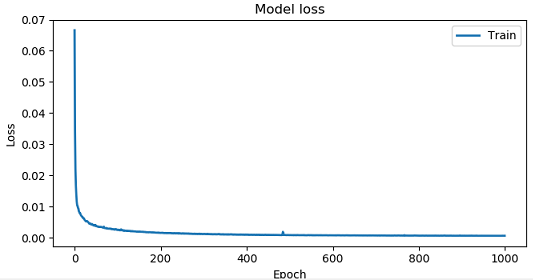
训练结果模型,通过model.save(filename)保存持久化。训练所涉及到的函数、数据集使用《Tensorflow LSTM实现多维输入输出预测实践详解》中的代码和股票数据集。
代码与数据可详见:xiaoyw71/Time-series-behavior-analysis-eg.-stock-
3.3. 预测代码
加载持久化模型,所涉及到的函数、数据集使用《Tensorflow LSTM实现多维输入输出预测实践详解》中的代码和股票数据集。
if __name__ == '__main__':
# 获取原归一化处理的Scaler
#df = get_train_data()
#train_x,train_y,z,sc,col_name,df = set_datas(df,True)
df = get_test_data()
seq,res,z,sc,col_name,df = set_datas(df,False,sc)
seq = seq.reshape(-1,TIME_STEPS,INPUT_SIZE)
#c0 = seq
#for i in range(BATCH_SIZE-1):
# seq = np.row_stack((seq,c0))
share_close = df['close0'].values
share_vol = df['vol0'].values/10000
share_sh = df['close1'].values
share_sz = df['close2'].values
model = load_model('lstm-model2.h5')
pred = model.predict(seq)
#p1 = pred[0]
y=get_pred_data(pred[0].reshape(TIME_STEPS,OUTPUT_SIZE),z,sc)
#y=get_pred_data(p1,z,sc)
df= pd.DataFrame(y,columns=col_name)
df.to_csv('yk2.csv')
share_close1 = df['close0'].values
share_vol1 = df['vol0'].values/10000
share_sh1 = df['close1'].values
share_sz1 = df['close2'].values
#合并预测移动移位PRED_SIZE
share_close1 = np.concatenate((share_close[:PRED_SIZE],share_close1),axis=0)
share_vol1 = np.concatenate((share_vol[:PRED_SIZE],share_vol1),axis=0)
share_sh1 = np.concatenate((share_sh[:PRED_SIZE],share_sh1),axis=0)
share_sz1 = np.concatenate((share_sz[:PRED_SIZE],share_sz1),axis=0)
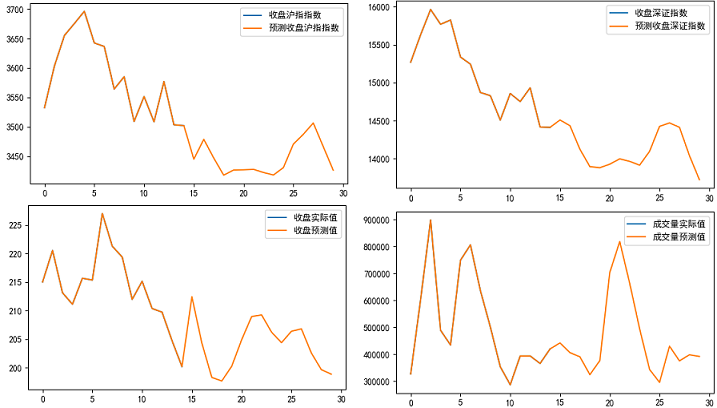
plt.plot(share_sh, label='收盘沪指指数')
plt.plot(share_sh1, label='预测收盘沪指指数')
plt.plot(share_sz, label='收盘深证指数')
plt.plot(share_sz1, label='预测收盘深证指数')
plt.plot(share_close, label='收盘实际值')
plt.plot(share_vol, label='成交量实际值')
plt.plot(share_vol1, label='成交量预测值')
plt.plot(share_close1, label='收盘预测值')
plt.title('Test Loss')
plt.legend()
plt.show()
预测输出结果图形化为30天的数据,其中从横坐标第14个点为预测数据(从0开始),直到29点,共计15交易日预测数据(3月8日~27日)。
注意Tensorflow版本兼容性问题:
model_config = json.loads(model_config.decode(‘utf-8’))
AttributeError: ‘str’ object has no attribute ‘decode’
只要运行如下命令即可:
是由于tensorflow2.1.0支持h5py<3.0.0,而在安装tensorflow会自动安装h5py 3.1.0 。
只要运行如下命令即可:
pip install tensorflow h5py==2.10.0
参考:
《Tensorflow LSTM实现多维输入输出预测实践详解》知乎 ,肖永威 ,2021年3月
《基于Keras的LSTM多变量时间序列股票预测》肖永威的专栏-CSDN博客,2020年4月
《时间序列和回归分析有什么本质区别?》知乎,姚岑卓,2019年8月
最后
以上就是整齐哑铃最近收集整理的关于Keras LSTM实现多维输入输出时序预测实践详解1. 关于时间序列分析2. LSTM模型3. Keras LSTM实现多维输入输出时序预测的全部内容,更多相关Keras内容请搜索靠谱客的其他文章。








发表评论 取消回复