论文名称:Dynamic Routing Between Capsules
论文下载:https://arxiv.org/abs/1710.09829
论文年份:NeurIPS 2017
论文被引:3597(2022/04/23)
论文代码:
Keras:https://github.com/XifengGuo/CapsNet-Keras
Torch:https://github.com/jindongwang/Pytorch-CapsuleNet/blob/master/capsnet.py
Slides:Dynamic Routing Between Capsules
胶囊网络(CapsNets)是一种热门的新型神经网络架构,很可能对深度学习产生深远的影响,尤其是对计算机视觉而言。那么,与传统的卷积神经网络 (CNN) 在各种计算机视觉任务(例如分类、定位、对象检测、语义分割或实例分割)相比,二者有何区别?
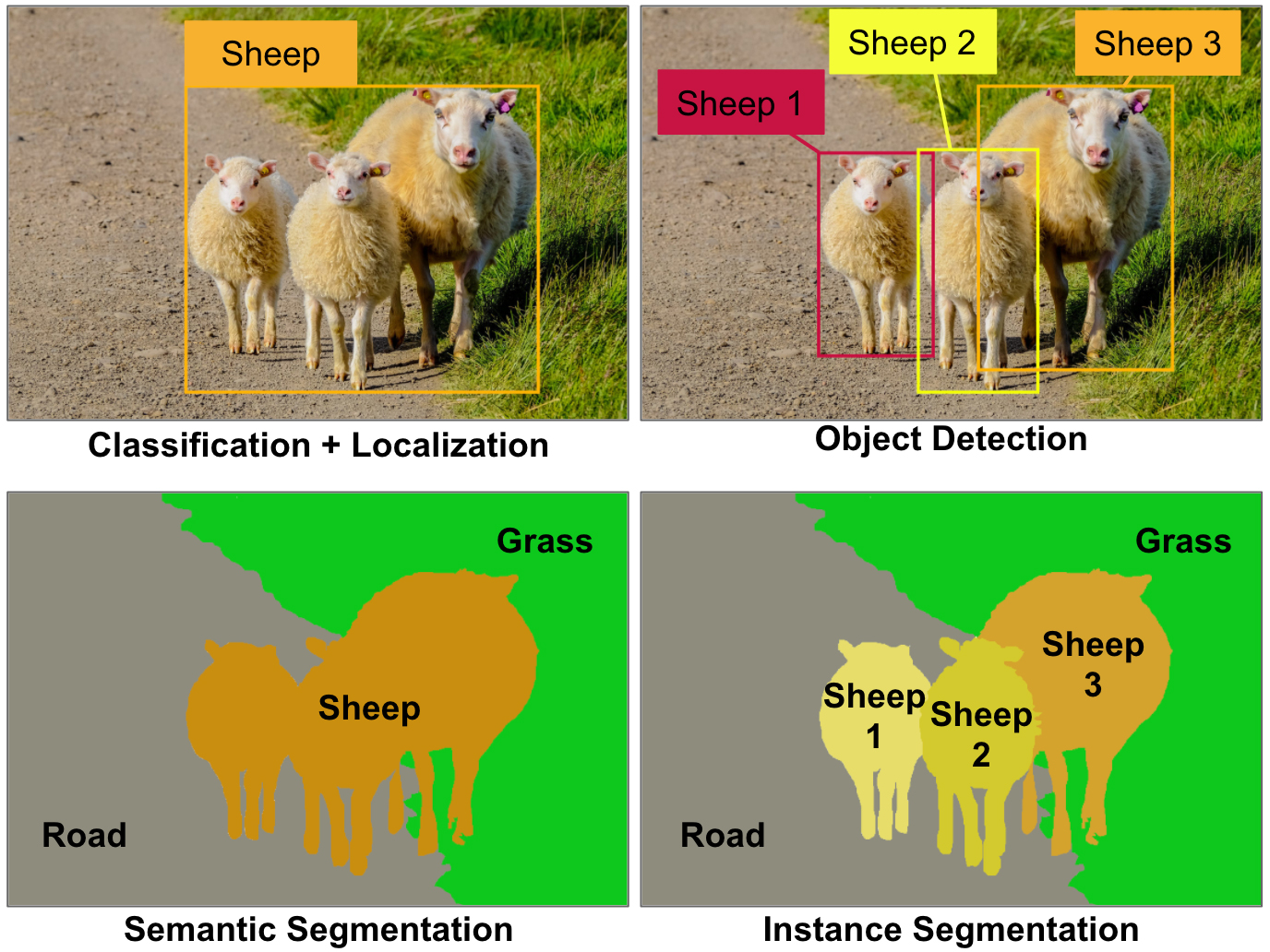
Figure 1. Some of the main computer vision tasks. Today, each of these tasks requires a very different CNN architecture, for example ResNet for classification, YOLO for object detection, Mask R-CNN for instance segmentation, and so on. Image by Aurélien Géron.
- CNNs 使用大量图像的训练(或者重用了部分神经网络)。 CapsNets 可以使用更少的训练数据很好地泛化。
- CNNs 不能很好地处理歧义(ambiguity)。 CapsNet 可以,因此即使在拥挤的场景(crowded scenes)中也能表现出色(尽管它们现在仍然在与背景作斗争)。
- CNN 在池化层中丢失了大量信息。这些层降低了空间分辨率(参见图 2),因此它们的输出对于输入的微小变化是不变的。当必须在整个网络中保留详细信息时,例如在语义分割中,这是一个问题。今天,这个问题通过围绕 CNN 构建复杂的架构来恢复一些丢失的信息来解决。使用 CapsNets,详细的姿势信息(例如精确的对象位置、旋转、厚度、倾斜、大小等)被保留在整个网络中,而不是丢失并随后恢复。输入的微小变化会导致输出的微小变化——信息被保留。这称为等变性(equivariance)。因此,CapsNets 可以在不同的视觉任务中使用相同的简单且一致的架构。
- 最后,CNN 需要额外的组件来自动识别某个部分属于哪个对象(例如,这条腿属于这只羊)。 CapsNets 默认提供零件的层次结构。
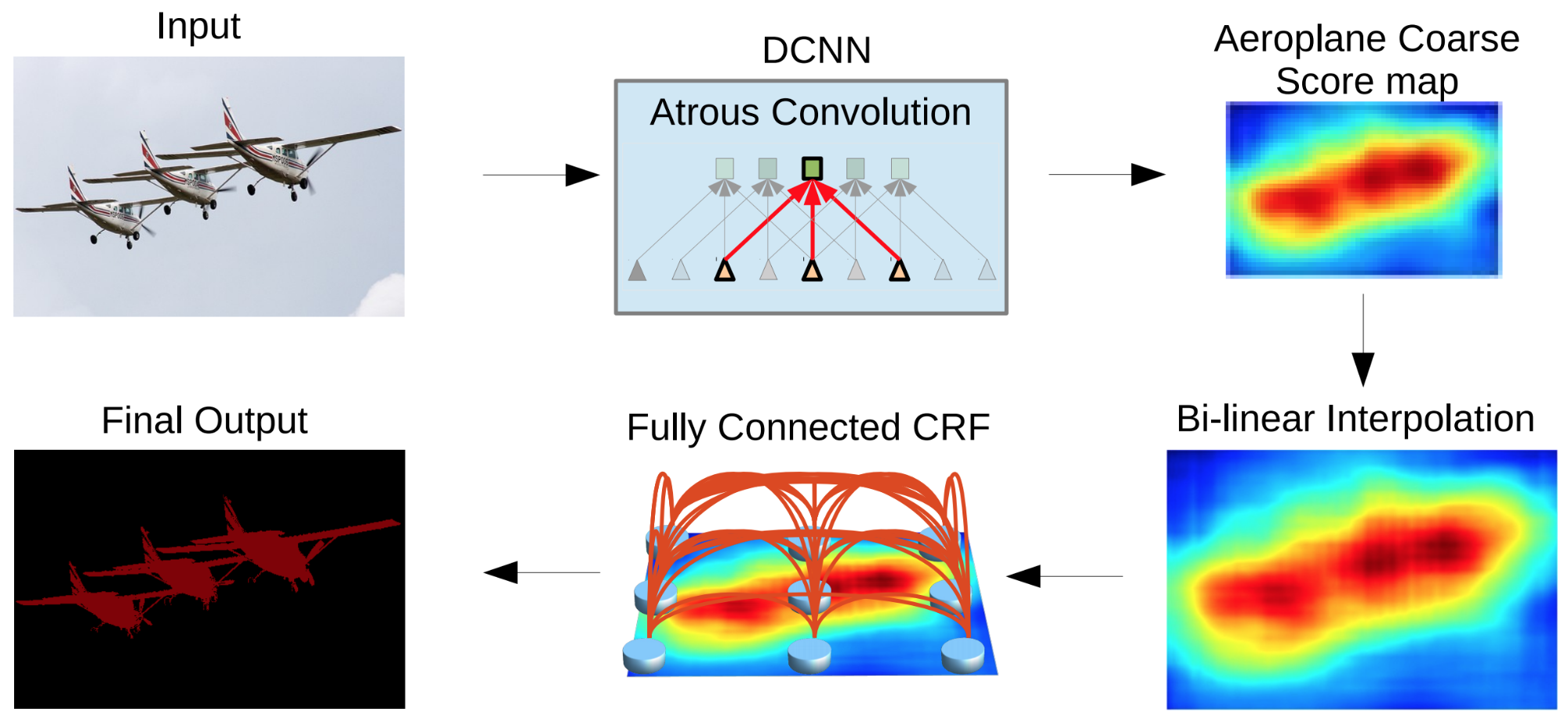
Figure 2. The DeepLab2 pipeline for image segmentation, by Liang-Chieh Chen, et al.: notice that the output of the CNN (top right) is very coarse, making it necessary to add extra steps to recover some of the lost details. From the paper DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs, figure reproduced with the kind permission of the authors. See this great post by S. Chilamkurthy to see how diverse and complex the architectures for semantic segmentation can get.
CapsNets 于 2011 年由 Geoffrey Hinton 等人在一篇名为 Transforming Autoencoders 的论文中首次引入,2017 年 11 月,Sara Sabour、Nicholas Frosst 和 Geoffrey Hinton 发表了一篇名为 Dynamic Routing 的论文在 Capsules 之间,介绍了 CapsNet 架构,该架构在 MNIST(著名的手写数字图像数据集)上达到了最先进的性能,并且在 MultiMNIST(一种不同数字对重叠的变体)上获得了比 CNN 更好的结果)。请参见图 3。

Figure 3. MultiMNIST images (white) and their reconstructions by a CapsNet (red+green). “R” = reconstructions; “L” = labels. For example, the predictions for the first example (top left) are correct, and so are the reconstructions. But in the fifth example, the prediction is wrong: (5,7) instead of (5,0). Therefore, the 5 is correctly reconstructed, but not the 0. From the paper: Dynamic routing between capsules, figure reproduced with the kind permission of the authors.
尽管具备这些特性,CapsNets 仍然远非完美。首先,目前它们在 CIFAR10 或 ImageNet 等较大图像上的表现不如 CNN。此外,它们是计算密集型的,当它们彼此太靠近时,它们无法检测到相同类型的两个对象(这被称为“拥挤问题”,并且已经证明人类也有这个问题)。但关键想法非常有前途,而且似乎只需要进行一些调整即可充分发挥其潜力。毕竟,现代 CNN 是 1998 年发明的,但经过一些调整,它们在 2012 年才击败了 ImageNet 上的最先进技术。
胶囊网络到底是什么?
简而言之,CapsNet 由胶囊而非神经元组成。胶囊是一小组神经元,它学习检测图像给定区域内的特定对象(例如,矩形),并输出一个向量(例如,一个 8 维向量),其长度表示对象存在的估计概率[1],并且其方向(例如,在 8D 空间中)对对象的姿态参数(例如,精确位置、旋转等)进行编码。如果对象稍有变化(例如,移动、旋转、调整大小等),则胶囊将输出相同长度的向量,但方向略有不同。因此,胶囊是等变的(equivariant)。
与常规神经网络非常相似,CapsNet 由多个层组成(参见图 4)。最低层的胶囊称为初级胶囊:它们中的每一个都接收图像的一个小区域作为输入(称为其感受野),并尝试检测特定模式的存在和姿势,例如矩形。更高层的胶囊(称为路由胶囊)检测更大和更复杂的物体,例如船。
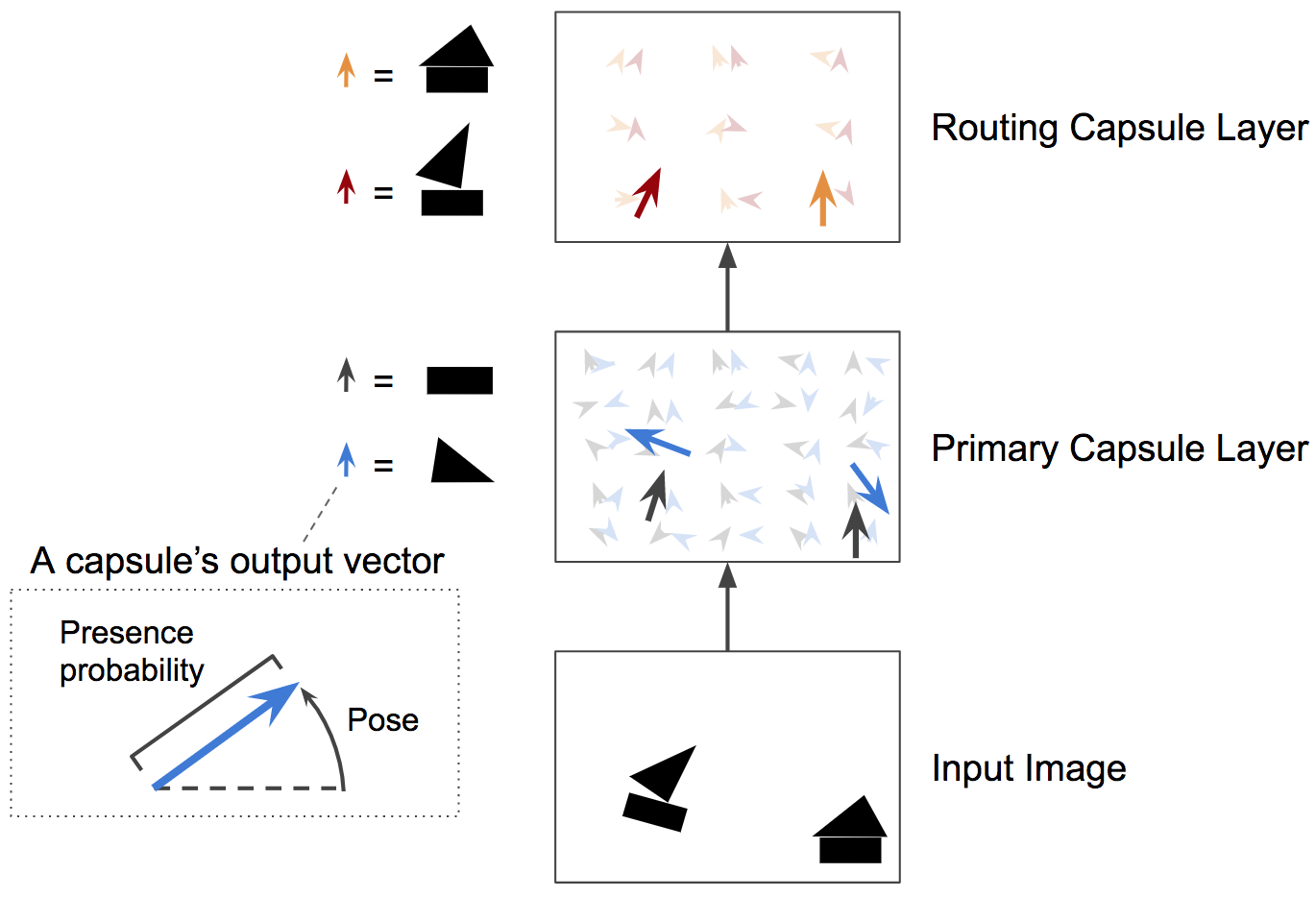
Figure 4. A two-layer CapsNet. In this example, the primary capsule layer has two maps of 5×5 capsules, while the second capsule layer has two maps of 3×3 capsules. Each capsule outputs a vector. Each arrow represents the output of a different capsule. Blue arrows represent the output of a capsule that tries to detect triangles, black arrows represent the output of a capsule that tries to detect rectangles, and so on. Image by Aurélien Géron.
初级胶囊(primary capsule)层是使用几个常规卷积层实现的。例如,在论文中,他们使用两个卷积层输出 256 个包含标量的 6×6 特征图。他们重塑这个输出以获得 32 个 6×6 的特征图,其中包含 8 维向量。最后,他们使用一种新的压缩函数来确保这些向量的长度在 0 和 1 之间(表示概率)。就是这样:这给出了初级胶囊的输出。
下一层的胶囊也尝试检测物体及其姿势,但它们的工作方式非常不同,使用一种称为协议路由(routing by agreement)的算法。下面看一个例子。
假设只有两个初级胶囊:一个矩形胶囊和一个三角形胶囊,并假设它们都检测到了他们正在寻找的东西。矩形和三角形都可以是房屋或船的一部分(参见图 5)。考虑到稍微向右旋转的矩形的姿势,房子和船也必须稍微向右旋转。考虑到三角形的姿势,房子必须几乎是倒置的,而船会稍微向右旋转。请注意,形状和整体/部分关系都是在训练期间学习的。现在请注意,矩形和三角形在船的姿态上是一致的,而在房子的姿态上却是非常不一致的。因此,矩形和三角形很可能是同一条船的一部分,并且没有房子。
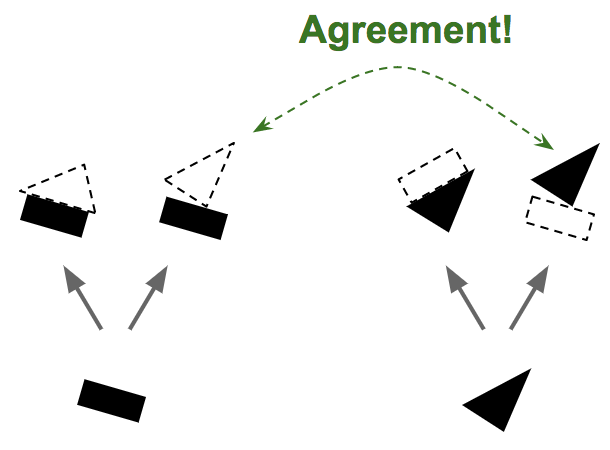
Figure 5. Routing by agreement, step 1—predict the presence and pose of objects based on the presence and pose of object parts, then look for agreement between the predictions. Image by Aurélien Géron.
- 路由(routing):底层胶囊将输入向量传递到高层胶囊的过程。
- 高层胶囊和底层胶囊的权重通过动态路由(dynamic routing)获得。
由于我们现在确信矩形和三角形是船的一部分,因此将矩形和三角形胶囊的输出更多地发送到船胶囊,而不是房屋胶囊是有意义的:这样,船胶囊将接收更有用的输入信号,并且房子胶囊将收到更少的噪音。对于每个连接,按协议路由算法维护一个路由权重(参见图 6):它在达成一致时增加路由权重,在不一致时减少权重。
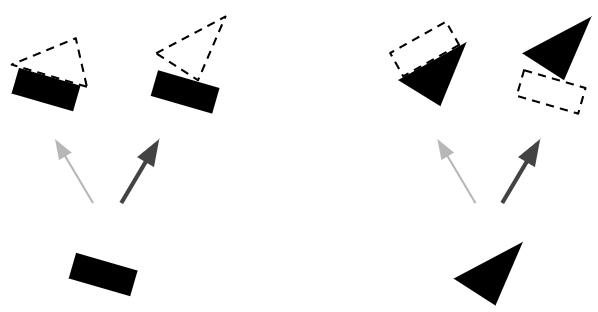
Figure 6. Routing by agreement, step 2—update the routing weights. Image by Aurélien Géron.
协议路由算法包括协议检测+路由更新的几次迭代(注意,这对于每次预测都会发生,而不仅仅是一次,也不仅仅是在训练时)。这在拥挤的场景中特别有用:例如,在图7中,场景是模糊的,因为您可以在中间看到一个颠倒的房子,但这会留下底部的矩形和顶部的三角形无法解释,因此按协议路由算法很可能会收敛到一个更好的解释:底部是一艘船,顶部是一所房子。这种模糊性被称为“解释掉了”:下面的矩形最好用一艘船的存在来解释,这也解释了下面的三角形,一旦这两个部分被解释掉,剩下的部分就很容易解释为一座房子。
协议路由算法涉及协议检测 + 路由更新的几次迭代(请注意,这发生在每个预测中,不仅仅是一次,也不仅仅是在训练时)。这在拥挤的场景中特别有用:例如,在图 7 中,场景不明确,可以看到在中间有一个倒置的房子,但这会使底部矩形和顶部三角形无法解释,因此路由协议算法很可能会收敛到更好的解释:底部有船,顶部有房子。歧义被说成是 “被解释掉了(explained away”)”:下面的矩形最好用船的存在来解释,这也解释了下面的三角形,一旦这两个部分被解释掉,剩下的部分就很容易解释为房子了。
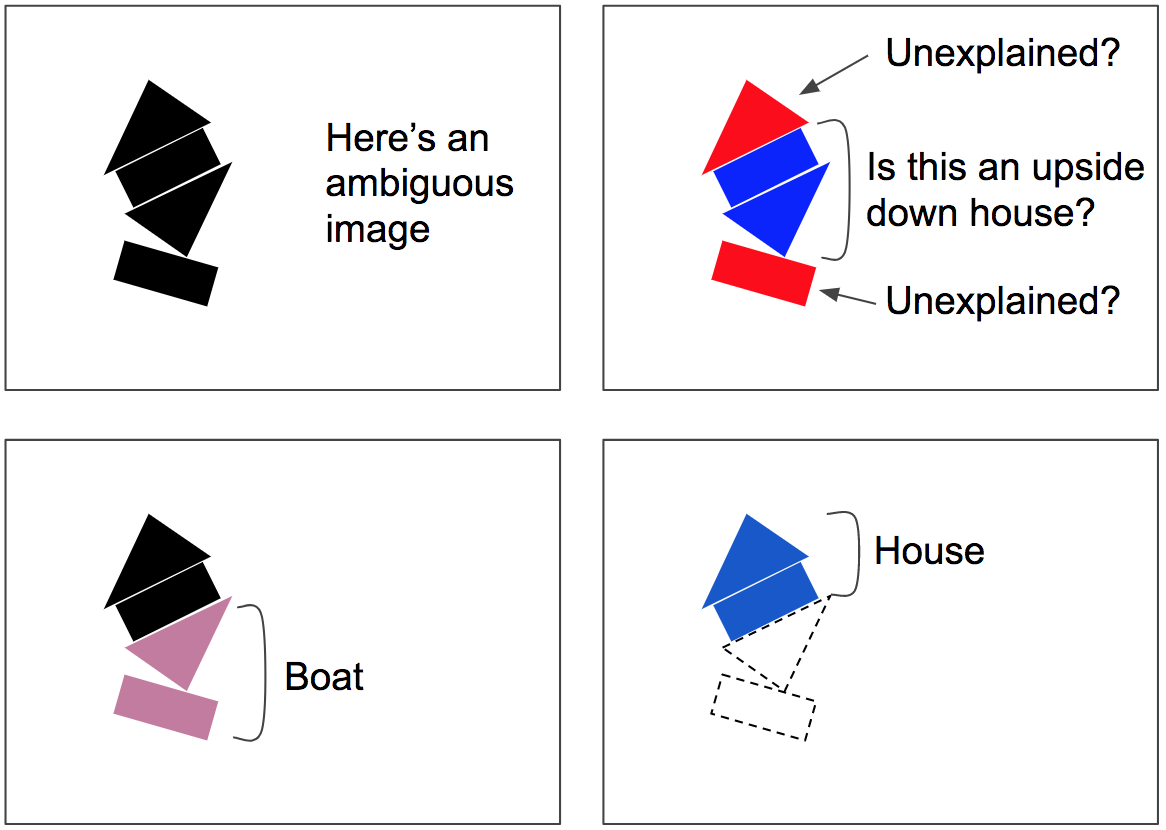
Figure 7. Routing by agreement can parse crowded scenes, such as this ambiguous image, which could be misinterpreted as an upside-down house plus some unexplained parts. Instead, the lower rectangle will be routed to the boat, and this will also pull the lower triangle into the boat as well. Once that boat is “explained away,” it’s easy to interpret the top part as a house. Image by Aurélien Géron.
首先看一下CNN有哪些问题?
CNN 在对非常接近数据集的图像进行分类时表现异常出色。如果图像有旋转、倾斜或任何其他不同的方向,那么 CNN 的性能就会很差。这个问题是通过在训练期间添加同一图像的不同变体来解决的。在 CNN 中,每一层都以更精细的层次理解图像。让我们通过一个例子来理解这一点。如果要对船只和马匹进行分类。最内层或第 1 层了解小曲线和边缘。第二层可能理解直线或较小的形状,如船的桅杆或整个尾部的曲率。更高的层次开始理解更复杂的形状,比如整个尾巴或船体。最后一层试图看到更整体的画面,比如整艘船或整匹马。我们在每一层之后使用池化来使其在合理的时间范围内进行计算。但本质上它也丢失了位置信息。
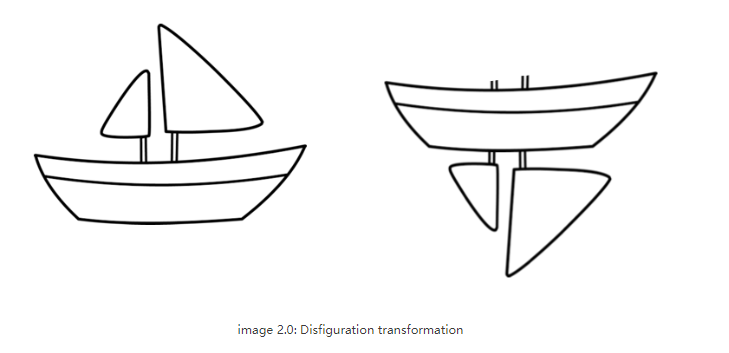
池化有助于创建位置不变性。否则 CNN 将仅适用于非常接近训练集的图像或数据。这种不变性也导致对于具有船的部件但顺序不正确的图像触发假阳性。所以系统会误认为上图中两幅图是一样的。池化层也增加了这种不变性。
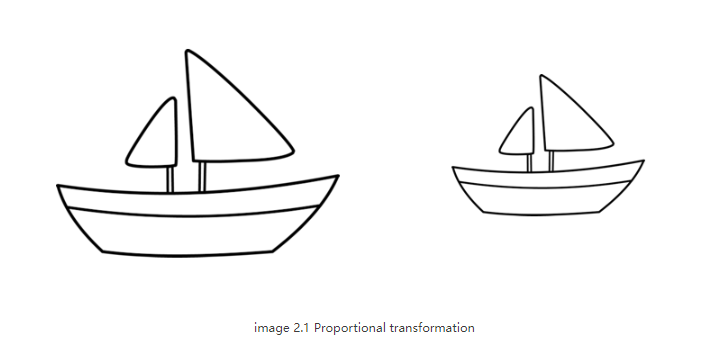
这从来都不是池化层的意图。池化应该做的是引入位置、方向、比例不变性。但是非常粗糙。实际上,它增加了各种位置不变性。从而导致将图 2.0 中右侧的船判断为正确的船。我们需要的不是不变性(invariance),而是等变性(equivariance)。不变性使 CNN 能够容忍视角的微小变化。等变性使 CNN 了解旋转或比例变化并相应地调整自身,从而不会丢失图像内的空间位置信息。一艘船仍将是一艘较小的船,但 CNN 将减小其尺寸以检测到这一点。这将我们引向 Capsule Networks 的最新进展。
参考:
What is a CapsNet or Capsule Network?
Introducing capsule networks
胶囊网络:更强的可解释性
Abstract
A capsule is a group of neurons whose activity vector represents the instantiation parameters of a specific type of entity such as an object or an object part. We use the length of the activity vector to represent the probability that the entity exists and its orientation to represent the instantiation parameters. Active capsules at one level make predictions, via transformation matrices, for the instantiation parameters of higher-level capsules. When multiple predictions agree, a higher level capsule becomes active. We show that a discrimininatively trained, multi-layer capsule system achieves state-of-the-art performance on MNIST and is considerably better than a convolutional net at recognizing highly overlapping digits. To achieve these results we use an iterative routing-by-agreement mechanism: A lower-level capsule prefers to send its output to higher level capsules whose activity vectors have a big scalar product with the prediction coming from the lower-level capsule.
胶囊是一组神经元,其活动向量表示特定类型实体(例如对象或对象部分)的实例化参数。我们用活动向量的长度来表示实体存在的概率,用它的方向来表示实例化参数。一层的活动胶囊通过变换矩阵对更高级别胶囊的实例化参数进行预测。当多个预测一致时,更高级别的胶囊变得活跃。我们表明,经过判别训练的多层胶囊系统在 MNIST 上实现了最先进的性能,并且在识别高度重叠的数字方面明显优于卷积网络。为了达到这些结果,我们使用了一个迭代的路由协议机制(routing-by-agreement mechanism):一个较低级别的胶囊更喜欢将其输出发送到较高级别的胶囊,其活动向量与来自较低级别胶囊的预测具有较大的标量积(scalar product)。
1 Introduction
人类视觉通过使用仔细确定的注视点序列(sequence of fixation points)来忽略不相关的细节,以确保只有极小部分的光学阵列(optic array)以最高分辨率被处理。内省(Introspection)对于理解我们对一个场景的知识有多少来自于注视点序列以及我们从一次注视中收集了多少是一个很差的指导,但是在本文中我们将假设一次注视(single fixation)给我们的不仅仅是一个单一的被识别的物体及其属性。我们假设多层视觉系统在每个注视点上创建了一个类似解析树(Parse trees)的结构,并且我们忽略了这些单个注视点的解析树如何在多个注视点上协调的问题。
解析树通常是通过动态分配内存来动态构建的。然而,根据Hinton等人[2000],我们将假设,对于单次注视,解析树是从固定的多层神经网络中雕刻出来的,就像是从岩石中雕刻出来的雕塑。每一层将被分成许多称为“胶囊 (capsules)”的神经元小组 (Hinton等人[2011]),解析树中的每个节点将对应于一个活动胶囊。使用迭代路由过程(iterative routing process),每个活动胶囊将选择上一层中的胶囊作为其在树中的父胶囊。对于视觉系统的更高层次,这个迭代过程将解决将部分分配给整体的问题。
活动胶囊内神经元的活动代表了图像中存在的特定实体的各种属性。这些属性可以包括许多不同类型的实例化参数,例如姿态(位置、大小、方向)、变形、速度、反照率、色调、纹理等。一个非常特殊的属性是图像中实例化实体(entity)的存在。表示存在(existence)的一种明显方法是使用单独的逻辑单元,其输出是实体存在的概率。在本文中,我们探索了一个有趣的替代方案,即使用实例化参数向量的总长度来表示实体的存在,并强制向量的方向来表示实体的属性。我们通过应用非线性来确保胶囊的向量输出的长度不超过1,该非线性使向量的方向保持不变,但是按比例缩小其幅度。
胶囊的输出是一个向量,使得可以使用强大的动态路由机制来确保胶囊的输出被发送到上层的适当父节点。最初,输出被路由到所有可能的父节点,但通过总和为 1 的耦合系数按比例缩小。对于每个可能的父节点,胶囊通过将自己的输出乘以权重矩阵来计算“预测向量”。如果该预测向量与可能的父节点的输出具有较大的标量积,则存在自上而下的反馈,该反馈会增加该父节点的耦合系数,并降低其他父节点的耦合系数。这增加了胶囊对该父代的贡献,从而进一步增加了胶囊预测与父代输出的标量积。这种类型的**“按协议路由 (routing-by-agreement)”应该比通过最大池化实现的非常原始的路由形式更有效,最大池化允许一层中的神经元忽略该层中除最活跃的特征检测器之外的所有特征检测器**。我们证明了我们的动态路由机制是实现分割高度重叠对象所需的“解释”的有效方法。
卷积神经网络 (CNN) 使用学习特征检测器的翻译副本。这允许 CNN 将在图像中的一个位置获取的良好权重值的知识转换到其他位置。事实证明,这对图像解释非常有帮助。尽管我们正在用向量输出胶囊替换 CNN 的标量输出特征检测器,用协议路由代替了最大池化,我们仍然希望跨空间复制学到的知识。为了实现这一点,胶囊的最后一层使用成卷积。与 CNN 一样,我们让更高级别的胶囊覆盖图像的更大区域。然而,与最大池化不同的是,我们不会丢弃有关实体在区域内的精确位置的信息。对于低级胶囊,位置信息是由活动的胶囊“位置编码”的。随着我们提升层次结构,越来越多的位置信息在胶囊输出向量的实值分量中被“速率编码”。这种从位置编码到速率编码的转变,再加上更高级别的胶囊代表具有更多自由度的更复杂实体的事实,表明胶囊的维度应该随着我们提升层次结构而增加。
2 How the vector inputs and outputs of a capsule are computed
有许多可能的方法来实现胶囊的一般思想。本文的目的不是探索整个领域,而是简单地说明一个相当简单的实现工作良好,并且动态路由有所帮助。
我们希望胶囊的输出向量的长度表示胶囊所代表的实体存在于当前输入中的概率。因此,我们使用非线性“挤压”函数来确保短向量的长度缩小到几乎为零,而长向量的长度缩小到略低于 1。我们将其留给判别学习以充分利用这种非线性。
我们希望一个胶囊的输出向量的长度能够代表该胶囊所代表的实体出现在当前输入中的概率。因此,我们使用非线性“挤压”函数来确保短向量收缩到几乎为零长度,而长向量收缩到略小于 1 的长度。我们将其留给判别学习以充分利用这种非线性。
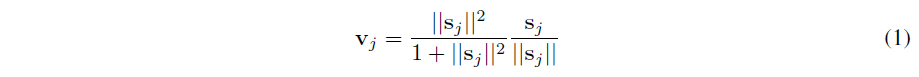
其中 v j v_j vj 是胶囊 j j j 的矢量输出, s j s_j sj 是其总输入。
对于除了第一层胶囊之外的所有胶囊,胶囊sj的总输入是来自下层胶囊的所有“预测向量”uj|i的加权和,
对于除第一层胶囊之外的所有胶囊,胶囊
s
j
s_j
sj 的总输入是来自下一层胶囊的所有“预测向量”
u
^
j
∣
i
hat{u}_{j|i}
u^j∣i 的加权和,并且通过将下层胶囊的输出
u
i
u_i
ui 乘以权重矩阵
W
i
j
W_{ij}
Wij来产生

其中 c i j c_{ij} cij 是由迭代动态路由过程确定的耦合系数。
胶囊
i
i
i 和上层所有胶囊之间的耦合系数总和为 1,并由“routing softmax”确定,其初始 logits
b
i
j
b_{ij}
bij 是胶囊
i
i
i 应耦合到胶囊
j
j
j 的对数先验概率。
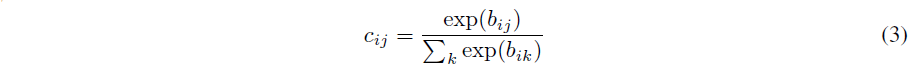
对数先验可以与所有其他权重同时被有区别地学习。它们取决于两个胶囊的位置和类型,但不取决于当前输入图像。然后,通过测量上一层中每个胶囊
j
j
j 的当前输出
v
j
v_j
vj 与胶囊
i
i
i 的预测
u
j
∣
i
u_{j|i}
uj∣i 之间的一致性,迭代地改进初始耦合系数。
该协议只是标量积 a i j = v j . u ^ j ∣ i a_{ij} = v_{j.} hat{u}_{j|i} aij=vj.u^j∣i。该一致性被视为对数似然,并在计算将胶囊 i i i 链接到更高级别胶囊的所有耦合系数的新值之前添加到初始 logit, b i j b_{ij} bij。
在卷积胶囊层中,每个胶囊对网格的每个成员以及每种类型的胶囊使用不同的变换矩阵,向上层中的每种类型的胶囊输出向量的局部网格。

3 Margin loss for digit existence
我们使用实例化向量的长度来表示胶囊实体存在的概率。当且仅当图像中存在该数字时,我们希望数字类 k 的顶层(top-level)胶囊具有长实例化向量。为了允许多个数字,我们为每个数字胶囊 k 使用单独的边际损失
L
k
L_k
Lk:
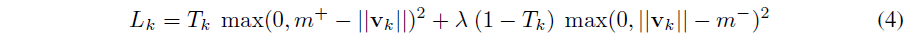
其中 T k = 1 T_k = 1 Tk=1 当且仅当存在 k k k 类数字,且 m + = 0.9 m^+ = 0.9 m+=0.9 且 m − = 0.1 m^- = 0.1 m−=0.1。缺少数字类别的损失的 λ λ λ 向下加权阻止了初始学习缩小所有数字胶囊的活动向量的长度。我们使用 λ = 0.5。总损失只是所有数字胶囊损失的总和。
4 CapsNet architecture
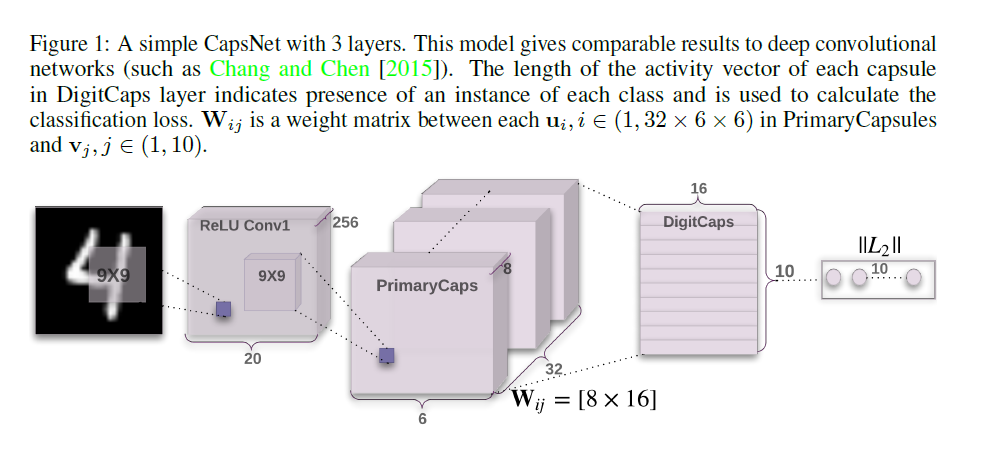
一个简单的 CapsNet 架构如图1所示。该架构是浅层的,只有两个卷积层和一个全连接层。Conv1 有 256 个 9 × 9 卷积核,步长为 1,ReLU 激活函数。该层将像素强度转换为局部特征检测器的活动,然后将其用作初级胶囊的输入。
主胶囊(primary capsules)是多维实体的最低级别,并且从逆图形的角度来看,激活初级胶囊对应于反转渲染过程(rendering process)。这是一种与将实例化的部分拼凑成熟悉的整体非常不同的计算类型,而这正是胶囊所擅长的。
第二层(PrimaryCapsules)是一个卷积胶囊层,具有 32 个通道的卷积 8D 胶囊(即每个初级胶囊包含 8 个卷积单元,卷积核为 9×9,步幅为 2)。每个主胶囊输出看到所有 256 × 81 Conv1 单元的输出,其感受野与胶囊中心的位置重叠。 PrimaryCapsules 总共有 [32 × 6 × 6] 个胶囊输出(每个输出是一个 8D 向量),并且 [6 × 6] 网格中的每个胶囊彼此共享它们的权重。可以将 PrimaryCapsules 视为卷积层,等式 1 作为其块非线性。最后一层(DigitCaps)每个数字类有一个 16D 胶囊,每个胶囊都接收来自下一层所有胶囊的输入。
我们只在两个连续的胶囊层之间进行路由(例如 PrimaryCapsules 和 DigitCaps)。由于 Conv1 输出是一维的,因此其空间中没有一致的方向。因此,Conv1 和 PrimaryCapsules 之间不使用路由。所有路由 logits (bij) 都初始化为零。因此,最初胶囊输出 (ui) 以相等的概率 (cij) 发送到所有父胶囊 (v0…v9)。我们在 TensorFlow (Abadi et al. [2016]) 中实现,使用 Adam 优化器 (Kingma and Ba [2014]) 及其默认参数,包括指数衰减的学习率,以最小化等式 4 中的边际损失总和。
4.1 Reconstruction as a regularization method
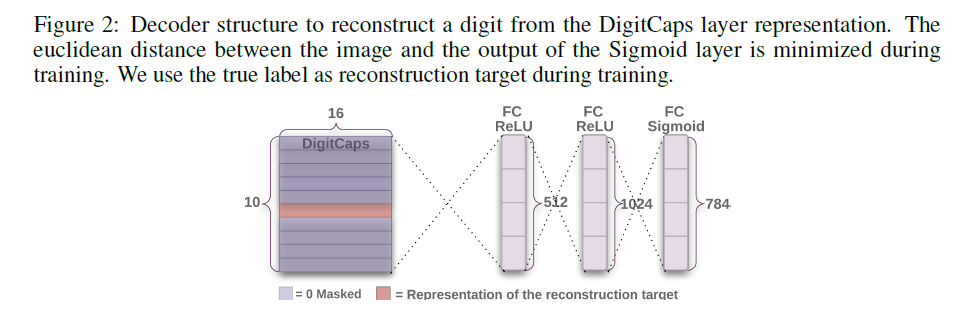
我们使用额外的重建损失来鼓励数字胶囊对输入数字的实例化参数进行编码。在训练期间,我们屏蔽(mask)了除正确数字胶囊的活动向量之外的所有向量。然后我们使用这个活动向量来重建输入图像。数字胶囊的输出被馈送到由 3 个全连接层组成的解码器,这些层对像素强度进行建模,如图 2 所示。我们最小化逻辑单元输出与像素强度之间的平方差之和。我们将这个重建损失按比例缩小 0.0005,这样它就不会在训练期间占主导地位。如图 3 所示,来自 CapsNet 的 16D 输出的重建是稳健的,同时只保留了重要的细节。

5 Capsules on MNIST
训练是在 28 × 28 MNIST (LeCun et al. [1998]) 图像上进行的,这些图像在每个方向上用零填充移动了 2 个像素。没有使用其他数据增强/变形。该数据集分别有 60K 和 10K 图像用于训练和测试。
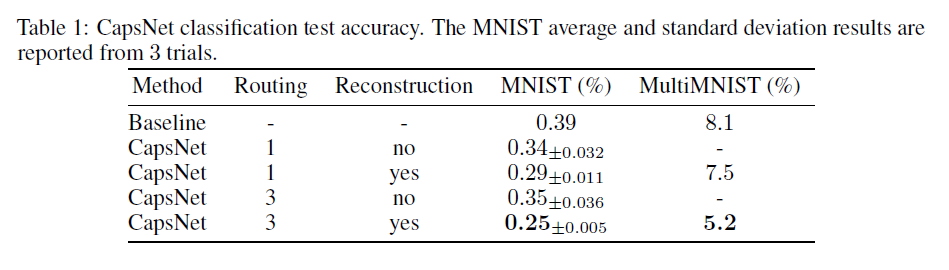
我们使用没有任何模型平均的单个模型进行测试。Wan et al. [2013] 通过旋转和缩放来集成和扩充数据,实现了 0.21% 的测试误差。没有它们,它们达到 0.39%。我们在一个三层网络上获得了一个低测试误差(0.25%),以前只有更深的网络才能实现。表 1 报告了不同 CapsNet 设置在 MNIST 上的测试错误率,并显示了路由和重建正则化器的重要性。添加重建正则化器通过在胶囊向量中执行姿态编码来提高路由性能。
基线是一个标准的 CNN,具有 256、256、128 个通道的三个卷积层。每个都有 5x5 的内核和步长为 1。最后一个卷积层后面是两个大小为 328、192 的全连接层。最后一个全连接层通过 dropout 连接到具有交叉熵损失的 10 类 softmax 层。基线还使用 Adam 优化器在 2 像素移位的 MNIST 上进行训练。该基线旨在在 MNIST 上实现最佳性能,同时保持计算成本与 CapsNet 接近。就参数数量而言,baseline 有 3540 万个参数,而 CapsNet 有 820 万个参数和 680 万个参数,没有重建子网络。
5.1 What the individual dimensions of a capsule represent

由于我们只传递一个数字的编码并将其他数字归零,因此数字胶囊的维度应该学会跨越该类数字实例化方式的变化空间。这些变化包括笔画粗细、偏斜和宽度。它们还包括特定于数字的变化,例如数字 2 的尾部长度。我们可以通过使用解码器网络看到各个维度代表什么。在为正确的数字胶囊计算活动向量之后,我们可以将该活动向量的扰动版本提供给解码器网络,并查看扰动如何影响重建。这些扰动的例子如图 4 所示。我们发现胶囊的一维(16 维中)几乎总是代表手指的宽度。虽然一些维度表示全局变化的组合,但还有其他维度表示数字局部部分的变化。例如,对于数字 6 的上升部分的长度和循环的大小,使用了不同的尺寸。
5.2 Robustness to Affine Transformations
实验表明,与传统的卷积网络相比,每个 DigitCaps 胶囊为每个类别学习了更稳健的表示。由于手写数字的倾斜、旋转、样式等存在自然变化,因此经过训练的 CapsNet 对训练数据的小型仿射变换具有中等鲁棒性。
为了测试 CapsNet 对仿射变换的鲁棒性,我们在填充和翻译的 MNIST 训练集上训练了 CapsNet 和传统的卷积网络(使用 MaxPooling 和 DropOut),其中每个示例都是随机放置在 40 × 40 像素的黑色背景上的 MNIST 数字。然后我们在 affNIST 数据集上测试了这个网络,其中每个示例都是一个带有随机小仿射变换的 MNIST 数字。除了翻译和标准 MNIST 中看到的任何自然变换之外,我们的模型从未接受过仿射变换的训练。一个训练不足的 CapsNet 在扩展的 MNIST 测试集上实现了 99.23% 的准确率,在 affnist 测试集上实现了 79% 的准确率。具有相似数量参数的传统卷积模型在扩展的 mnist 测试集上实现了相似的准确度(99.22%),但在 affnist 测试集上仅达到了 66%。
6 Segmenting highly overlapping digits
动态路由可以被视为一种并行注意机制,它允许一个级别的每个胶囊关注下一层的一些活动胶囊并忽略其他胶囊。这应该允许模型识别图像中的多个对象,即使对象重叠。Hinton等人提出分割和识别高度重叠数字的任务(Hinton et al. [2000] 和其他人已经在类似的领域测试了他们的网络(Goodfellow et al. [2013], Ba et al. [2014], Greff et al. [ 2016])。协议路由应该可以使用关于对象形状的先验来帮助分割,并且应该避免在像素域中做出更高级别的分割决策。
6.1 MultiMNIST dataset
我们通过将一个数字叠加在来自相同集合(训练或测试)但不同类别的另一个数字之上来生成多专家训练和测试数据集。每个数位在每个方向上最多移位4个像素,产生一个36 × 36的图像。考虑到28 × 28图像中的一个数字被限制在20 × 20的框中,两个数字边界框平均有80%的重叠。对于MNIST数据集中的每个数字,我们生成1K个多部样本。因此,训练集大小为60M,测试集大小为10M。
我们通过将一个数字覆盖在来自同一组(训练或测试)但不同类别的另一个数字之上来生成 MultiMNIST 训练和测试数据集。每个数字在每个方向上最多移动 4 个像素,从而产生 36 × 36 的图像。考虑到 28 × 28 图像中的一个数字被限定在一个 20 × 20 的框内,两个数字的边界框平均有 80% 的重叠。对于 MNIST 数据集中的每个数字,我们生成 1K MultiMNIST 示例。所以训练集大小为60M,测试集大小为10M。
6.2 MultiMNIST results
我们在 MultiMNIST 训练数据上从头开始训练的 3 层 CapsNet 模型比我们的基线卷积模型实现了更高的测试分类精度。我们在高度重叠的数字对上实现了与 Ba等人[2014] 的顺序注意模型相同的 5.0% 的分类错误率。 [2014] 实现了一个更简单的任务,重叠少得多(在我们的案例中,两位数周围的框有 80% 的重叠,而 Ba et al. [2014] 的重叠率 < 4%)。在由来自测试集的图像对组成的测试图像上,我们将两个最活跃的数字胶囊视为胶囊网络产生的分类。在重建过程中,我们一次选择一个数字,并使用所选数字胶囊的活动向量来重建所选数字的图像(我们知道该图像是因为我们使用它来生成合成图像)。与我们的 MNIST 模型的唯一区别是我们将学习率的衰减步骤的周期增加了 10 倍,因为训练数据集更大。
图 5 所示的重建表明 CapsNet 能够将图像分割成两个原始数字。由于这种分割不是像素级的,我们观察到模型能够正确处理重叠(一个像素在两个数字上都是 on),同时考虑所有像素。每个数字的位置和样式都以 DigitCaps 编码。解码器已经学会在给定编码的情况下重建一个数字。它能够在不考虑重叠的情况下重建数字这一事实表明,每个数字胶囊都可以从它从 PrimaryCapsules 层接收的投票中获取样式和位置。
标签。表 1 强调了带有路由的胶囊在此任务中的重要性。作为 CapsNet 准确度分类的基线,我们训练了一个卷积网络,该网络具有两个卷积层和两个全连接层。第一层有 512 个大小为 9×9 和步幅为 1 的卷积核。第二层有 256 个大小为 5×5 和步幅为 1 的卷积核。在每个卷积层之后,模型有一个大小为 2×2 和步幅为 2 的池化层。第三层是1024D全连接层。所有三层都具有 ReLU 非线性。最后一层 10 个单元是全连接的。我们使用 TensorFlow 默认的 Adam 优化器(Kingma 和 Ba [2014])在最后一层的输出上训练 sigmoid 交叉熵损失。该模型有 2456 万个参数,是 CapsNet 的 1136 万个参数的 2 倍。我们从一个较小的 CNN(32 和 64 个 5 × 5 和步长为 1 的卷积核和一个 512D 全连接层)开始,并逐渐增加网络的宽度,直到我们在 MultiMNIST 数据的 10K 子集上达到最佳测试精度。我们还在 10K 验证集上搜索了正确的衰减步骤。
我们一次解码两个最活跃的 DigitCaps 胶囊并获得两张图像。然后通过将具有非零强度的任何像素分配给每个数字,我们得到每个数字的分割结果。
7 Other datasets
我们在 CIFAR10 上测试了我们的胶囊模型,并在 7 个模型的集合中实现了 10.6% 的误差,每个模型都在 24 × 24 图像块上进行了 3 次路由迭代训练。每个模型与我们用于 MNIST 的简单模型具有相同的架构,除了有三个颜色通道并且我们使用了 64 种不同类型的初级胶囊。我们还发现它有助于为路由 softmax 引入“非上述”类别,因为我们不希望最后一层 10 个胶囊来解释图像中的所有内容。 10.6% 的测试误差是标准卷积网络首次应用于 CIFAR10 时所达到的结果(Zeiler 和 Fergus [2013])。
Capsules 与生成模型共有的一个缺点是它喜欢考虑图像中的所有内容,因此当它可以对混乱进行建模时,它比在动态路由中仅使用额外的“孤立”类别时做得更好。在 CIFAR-10 中,背景变化太大,无法在合理大小的网络中建模,这有助于解释较差的性能。
我们还在 smallNORB (LeCun et al. [2004]) 上测试了与用于 MNIST 完全相同的架构,并实现了 2.7% 的测试错误率,这与最先进的技术 (Ciresan et al. [2011])。 smallNORB 数据集由 96x96 立体灰度图像组成。我们将图像大小调整为 48x48,并在训练期间随机处理 32x32 裁剪图像。我们在测试期间通过了中央 32x32 补丁。
我们还在 SVHN 的小型训练集(Netzer et al. [2011])上训练了一个较小的网络,只有 73257 张图像。我们将第一个卷积层通道的数量减少到 64 个,主胶囊层减少到 16 个 6D 胶囊,最后是 8D 最终胶囊层,在测试集上达到了 4.3%。

8 Discussion and previous work
三十年来,语音识别领域的最新技术使用具有高斯混合的隐马尔可夫模型作为输出分布。这些模型在小型计算机上很容易学习,但它们有一个最终致命的表征限制:与使用分布式表征的循环神经网络相比,它们使用的 n 选一表征效率呈指数级低下。为了使 HMM 可以记住的关于它迄今为止生成的字符串的信息量加倍,我们需要对隐藏节点的数量进行平方。对于循环网络,我们只需要将隐藏神经元的数量加倍。
既然卷积神经网络已成为对象识别的主要方法,那么询问是否存在可能导致其消亡的指数低效率是有意义的。一个很好的候选者是卷积网络在推广到新观点时遇到的困难。处理平移的能力是内置的,但是对于仿射变换的其他维度,我们必须在随维度数量呈指数增长的网格上复制特征检测器,或以类似的指数方式增加标记训练集的大小之间做出选择。 Capsules (Hinton et al. [2011]) 通过将像素强度转换为已识别片段的实例化参数向量,然后将变换矩阵应用于片段以预测较大片段的实例化参数,从而避免了这些指数级的低效率。学习编码部分和整体之间的内在空间关系的变换矩阵构成了视点不变知识,其自动概括为新的视点。Hinton et al. [2011] 提出了转换自动编码器以生成 PrimaryCapsule 层的实例化参数,并且它们的系统需要从外部提供转换矩阵。我们提出了一个完整的系统,该系统还回答了“如何通过使用由活动的、低级别胶囊预测的姿态的一致性来识别更大和更复杂的视觉实体”。
胶囊做了一个非常强的代表性假设:在图像中的每个位置,最多有一个胶囊所代表的实体类型的实例。这个假设是由称为“拥挤”(Pelli et al. [2004])的感知现象推动的,消除了绑定问题(Hinton [1981a])并允许胶囊使用分布式表示(其活动向量)进行编码该类型实体在给定位置的实例化参数。这种分布式表示比通过激活高维网格上的一个点来编码实例化参数的效率呈指数级更高,并且通过正确的分布式表示,胶囊可以充分利用空间关系可以通过矩阵乘法建模的事实。
胶囊使用随着视点变化而变化的神经活动,而不是试图从活动中消除视点变化。这使它们比空间变换网络(Jaderberg et al. [2015])等“标准化”方法具有优势:它们可以同时处理不同对象或对象部分的多个不同仿射变换。
Capsules 也非常适合处理分割,这是视觉中另一个最棘手的问题,因为实例化参数的向量允许它们使用按协议路由,正如我们在本文中所展示的那样。动态路由过程的重要性也得到了视觉皮层中不变模式识别的生物学合理模型的支持。 Hinton [1981b] 提出了动态连接和基于规范对象的参考框架,以生成可用于对象识别的形状描述。Olshausen et al. [1993] 改进了 Hinton [1981b] 的动态连接,并提出了一个生物学上合理的、位置和尺度不变的对象表示模型。
现在对胶囊的研究与本世纪初用于语音识别的循环神经网络研究处于相似阶段。相信这是一种更好的方法有基本的代表性原因,但它可能需要更多的小见解才能超越高度发达的技术。一个简单的胶囊系统已经在分割重叠数字方面提供了无与伦比的性能这一事实早期表明胶囊是一个值得探索的方向。
最后
以上就是陶醉超短裙最近收集整理的关于【CV】胶囊网络 CapsNet:胶囊之间的动态路由机制Abstract1 Introduction2 How the vector inputs and outputs of a capsule are computed3 Margin loss for digit existence4 CapsNet architecture5 Capsules on MNIST6 Segmenting highly overlapping digits7 Other datasets8 Discussio的全部内容,更多相关【CV】胶囊网络内容请搜索靠谱客的其他文章。








发表评论 取消回复