文章目录
- 1.手动设置全连接层
- 2.利用接口设置全连接层
- 3.GPU加速实现全连接层
- 4.可视化训练过程
1.手动设置全连接层
# 导入所需要的模块
import torch
import torch.nn.functional as F
import torch.nn as nn
import torch.optim as optim
import torchvision
# 自行定义数据集
w1, b1 = torch.randn(200, 784, requires_grad=True),torch.zeros(200, requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True),torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True), torch.zeros(10, requires_grad=True)
# 权值的初始化处理,这一步非常的重要,没有初始化会导致loss无法收敛,并且长时间不会更新
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
# 定义神经网络的结构,是三个全连接层,并且之后通过ReLU激活函数输出结果
def forward(x):
x = x@w1.t() + b1
x = F.relu(x)
x = x@w2.t() + b2
x = F.relu(x)
x = x@w3.t() + b3
x = F.relu(x) # logits
return x
# 学习率
learning_rate = 0.01
# 1个epoch等于使用训练集中的全部样本训练一次
epochs = 10
# 批大小。在深度学习中,一般采用SGD(随机梯度下降)训练,即每次训练在训练集中取batchsize个样本训练;
batch_size = 64
# 详细介绍batch_size设置技巧:https://blog.csdn.net/zqx951102/article/details/88918948
# GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优
# 数据集的下载与处理
# 训练集下载
# torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
# root :用于指定数据集在下载之后的存放路径。
# train:如果为True,则从training.pt创建数据集,否则从test.pt创建数据集。
# transform:用于指定导入数据集时需要对数据集进行哪种变换操作。这里注意,需要提前定义这些变换操作。
# target_transform :对label进行变换
# loader: 指定加载图片的函数,默认操作是读取PIL image对象。
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('datasets/mnist_data', # 设置下保存路径
train=True,
download=True, # 如果已经存在,则不会再次下载
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 数据类型转化
torchvision.transforms.Normalize((0.1307, ), (0.3081, )) # 数据归一化处理
])), batch_size=batch_size,shuffle=True) # # 从数据库中每次抽出batch_size个样本
# 测试集下载
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('datasets/mnist_data/',
train=False,
download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 数据类型转化
torchvision.transforms.Normalize((0.1307, ), (0.3081, )) # 数据归一化处理
])),batch_size=batch_size,shuffle=False)
# 指定需要处理的参数,也就是每一层神经网络的权值w与偏置b
optimizer = optim.SGD([w1,b1,w2,b2,w3,b3], lr = learning_rate)
# 交叉熵loss
criteon = nn.CrossEntropyLoss()
# 进行训练
for epoch in range(epochs):
# enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
for batch_idx,(data,target) in enumerate(train_loader):
# 其中的data就是手写数字的图片,以下操作是讲28*28的照片铺平,变成一个一维的数组
data = data.view(-1,28*28)
# 通过前诉的神经网络的结构,输出一个torch.Size([16, 10])的logits输出
logits = forward(data)
# 计算交叉熵的loss,其中的logits通过了神经网络输出之后又的预测值,target为真实数据值
loss = criteon(logits,target)
# 以下三步基本上标准步骤
# 梯度信息设置为0
optimizer.zero_grad()
# 直接生成相关参数的梯度信息,随后再进行更新
loss.backward()
# 权值更新一次以下过程
optimizer.step()
# 输出相关的信息
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 以下是进行测试,具体的测试的思路可以参考下一个代码块
# 测试集,在更新了参数之后计算神经网络的正确率
test_loss = 0
correct = 0
# 使用测试集来计算
for data, target in test_loader:
data = data.view(-1, 28 * 28)
# 将测试集通过神经网络
logits = forward(data)
# 交叉熵loss,.item()操作是讲数据变成一个np格式而不是tensor格式
test_loss += criteon(logits, target).item()
# 以下两式与再以下的两式的作用是一样
# pred = logits.data.max(1)[1]
# correct += pred.eq(target.data).sum()
# 通过argmax找到没组图片的最大概率是哪一张,然后再与真实照片索引作出对比
pred = logits.argmax(dim=1)
# 计算出总的判断正确的数目,eq(target.data)函数可以将tensor对应位置相同的数据标注为1
correct += pred.eq(target).float().sum().item()
test_loss /= len(test_loader.dataset)
print('nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
# 设置一个epoch进行训练,以下是没有对权值w进行初始化的结果,可以看见梯度处于2.3025的时候长时间没有得到更新
# Train Epoch: 0 [0/60000 (0%)] Loss: 3190.210938
# Train Epoch: 0 [6400/60000 (11%)] Loss: 2.302583
# Train Epoch: 0 [12800/60000 (21%)] Loss: 2.266606
# Train Epoch: 0 [19200/60000 (32%)] Loss: 2.302583
# Train Epoch: 0 [25600/60000 (43%)] Loss: 2.302583
# Train Epoch: 0 [32000/60000 (53%)] Loss: 2.266606
# Train Epoch: 0 [38400/60000 (64%)] Loss: 2.302583
# Train Epoch: 0 [44800/60000 (75%)] Loss: 2.302583
# Train Epoch: 0 [51200/60000 (85%)] Loss: 2.302583
# Train Epoch: 0 [57600/60000 (96%)] Loss: 2.302583
# Test set: Average loss: 0.0361, Accuracy: 982/10000 (10%)
# 使用了torch.nn.init.kaiming_normal_对权值进行更新,再次测试,结果如下
# Train Epoch: 0 [0/60000 (0%)] Loss: 2.643014
# Train Epoch: 0 [6400/60000 (11%)] Loss: 1.149605
# Train Epoch: 0 [12800/60000 (21%)] Loss: 0.669285
# Train Epoch: 0 [19200/60000 (32%)] Loss: 0.385965
# Train Epoch: 0 [25600/60000 (43%)] Loss: 0.162021
# Train Epoch: 0 [32000/60000 (53%)] Loss: 0.259103
# Train Epoch: 0 [38400/60000 (64%)] Loss: 0.419779
# Train Epoch: 0 [44800/60000 (75%)] Loss: 0.214157
# Train Epoch: 0 [51200/60000 (85%)] Loss: 0.259678
# Train Epoch: 0 [57600/60000 (96%)] Loss: 0.199925
# Test set: Average loss: 0.0041, Accuracy: 9208/10000 (92%)
# 可以看见渐渐的是可以收敛,这就是自行定义神经网络的时候需要注意的地方,一定要初始化
# 10个epoch之后可以实现Test set: Average loss: 0.0015, Accuracy: 9710/10000 (97%)效果
- 其中的测试思路:
import torch
import torch.nn.functional as F
# 假设数据集为logits,其是4张照片,没张照片是10类中高的其中一种
logits = torch.rand(4,10)
# tensor([[0.1623, 0.3626, 0.9268, 0.6949, 0.8661, 0.1230, 0.2154, 0.8825, 0.7519, 0.1369],
# [0.9101, 0.5187, 0.8810, 0.7803, 0.2923, 0.5907, 0.6182, 0.7335, 0.1510, 0.5623],
# [0.9530, 0.2641, 0.8086, 0.9568, 0.4336, 0.8214, 0.6749, 0.3108, 0.9380, 0.8266],
# [0.8573, 0.2797, 0.9934, 0.3970, 0.2576, 0.1881, 0.4945, 0.7880, 0.4161, 0.7721]])
# 每一张的每一类的概率是pred
pred = F.softmax(logits,dim = 1)
# tensor([[0.0669, 0.0818, 0.1437, 0.1140, 0.1353, 0.0643, 0.0706, 0.1375, 0.1207, 0.0652],
# [0.1324, 0.0895, 0.1286, 0.1163, 0.0714, 0.0962, 0.0989, 0.1110, 0.0620, 0.0935],
# [0.1251, 0.0628, 0.1083, 0.1256, 0.0744, 0.1097, 0.0947, 0.0658, 0.1233, 0.1103],
# [0.1318, 0.0739, 0.1510, 0.0832, 0.0723, 0.0675, 0.0917, 0.1229, 0.0848, 0.1210]])
# 得出每一张图片最大概率的分类数组
pred_label = pred.argmax(dim = 1)
# tensor([2, 0, 3, 2])
# 也就是依次类推依次分别是可能是第2类,可能是第0类....等等
# 假设正确的分类是[2,4,3,9],label也就是相当于是真实的数据标签
label = torch.tensor([2,4,3,9])
# 将神经网络推算出的结果与真实的数据标签作对比,判断正确的标准为1,也就是对应位置的数值相同
correct = torch.eq(pred_label,label)
# 输出为:tensor([ True, False, True, False])
# 最后根据正确的数目,就可以计算出正确率,.item()操作是讲tensor的数据类型变为标量形式
correct.sum().float().item()/4
# 输出为:0.5,也就是正确的判断对了一半
2.利用接口设置全连接层
将上诉的自行定义每一层的相关参数代码可以进行更换:
# 自行定义数据集
# w1, b1 = torch.randn(200, 784, requires_grad=True),torch.zeros(200, requires_grad=True)
# w2, b2 = torch.randn(200, 200, requires_grad=True),torch.zeros(200, requires_grad=True)
# w3, b3 = torch.randn(10, 200, requires_grad=True), torch.zeros(10, requires_grad=True)
# 上下实现的意思是一样的,而且nn.Linear可以自动的帮助我们实现对参数的初始化操作,效果实在不好的时候可以再另行初始化
layer1 = nn.Linear(784,200)
layer2 = nn.Linear(200,200)
layer3 = nn.Linear(200,10)
# layer1(x).shape的输出为:torch.Size([1, 200])
# layer2(x).shape的输出为:torch.Size([1, 200])
# layer3(x).shape的输出为:torch.Size([1, 10]))
# 也就是将一个28*28的照片最后输出为一个[1,10]的数据
对于之前自定义的那个神经网络forward函数也可以利用接口封装成一个类:
# 定义神经网络的结构,是三个全连接层,并且之后通过ReLU激活函数输出结果
'''
def forward(x):
x = x@w1.t() + b1
x = F.relu(x)
x = x@w2.t() + b2
x = F.relu(x)
x = x@w3.t() + b3
x = F.relu(x) # logits
return x
'''
# 自定义结构的神经网络类
class MLP(nn.Module):
def __init__(self):
super(MLP,self).__init__()
# 使用nn.Linear函数实现全连接层
# 将每一层的输出通过一个激活函数变成非线性输出
self.model = nn.Sequential(
nn.Linear(784,200),
nn.ReLU(inplace = True),
nn.Linear(200,200),
nn.ReLU(inplace = True),
nn.Linear(200,10),
nn.ReLU(inplace = True)
)
def forward(self,x):
x = self.model(x)
return x
完整的代码如下:
# 导入工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
# 初始化参数,参数不变
batch_size=200
learning_rate=0.01
epochs=10
# 与前手动设置神经网络结构一样
# 训练集下载
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('datasets/mnist_data', # 设置下保存路径
train=True,
download=True, # 如果已经存在,则不会再次下载
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 数据类型转化
torchvision.transforms.Normalize((0.1307, ), (0.3081, )) # 数据归一化处理
])), batch_size=batch_size,shuffle=True) # # 从数据库中每次抽出batch_size个样本
# 测试集下载
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('datasets/mnist_data/',
train=False,
download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 数据类型转化
torchvision.transforms.Normalize((0.1307, ), (0.3081, )) # 数据归一化处理
])),batch_size=batch_size,shuffle=False)
# 利用pytorch的API接口,将神经网络封装成一个类
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
# 具体的神经网络结构,与前自定义的结构是一样的,但是简洁了很多
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 10),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
# 创造出一个神经网络的对象
net = MLP()
# net.parameters()函数可以自动的实现将需要求导的参数全自动的导入进来
# 这样就不需自己罗列,对于此网络来说net.parameters() = [w1, b1, w2, b2, w3, b3]
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
# 通过前诉的神经网络的结构,输出一个torch.Size([16, 10])的logits输出
# 相当于前诉的这一句代码:logits = forward(data)
logits = net(data)
# 计算交叉熵的loss
loss = criteon(logits, target)
# 三部曲,与前一样:梯度设置为0,生成相关参数的梯度信息,然后权值更新一次
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试集,在更新了参数之后计算神经网络的正确率
test_loss = 0
correct = 0
# 使用测试集来计算
for data, target in test_loader:
data = data.view(-1, 28 * 28)
# 将测试集通过神经网络
logits = forward(data)
# 交叉熵loss,.item()操作是讲数据变成一个np格式而不是tensor格式
test_loss += criteon(logits, target).item()
# 以下两式与再以下的两式的作用是一样
# pred = logits.data.max(1)[1]
# correct += pred.eq(target.data).sum()
# 通过argmax找到没组图片的最大概率是哪一张,然后再与真实照片索引作出对比
pred = logits.argmax(dim=1)
# 计算出总的判断正确的数目,eq(target.data)函数可以将tensor对应位置相同的数据标注为1
correct += pred.eq(target).float().sum().item()
test_loss /= len(test_loader.dataset)
print('nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
9个Epoch之后的结果为:
Train Epoch: 9 [0/60000 (0%)] Loss: 0.509781
Train Epoch: 9 [20000/60000 (33%)] Loss: 0.386184
Train Epoch: 9 [40000/60000 (67%)] Loss: 0.401284
Test set: Average loss: 0.0022, Accuracy: 8484/10000 (85%)
3.GPU加速实现全连接层
为了加快计算速度,可以使用GPU来计算,利用pytorch的接口,关键的代码为:
device = torch.device('cudu:0')
# 然后将需要计算的函数或者是数据全部都搬运到GPU当中去
net = MLP().to(device) # 创建神经网络结构对象
criteon = nn.CrossEntropyLoss().to(device) # 计算交叉熵
# 原型为
net = MLP() # 创建神经网络结构对象
criteon = nn.CrossEntropyLoss() # 计算交叉熵
# 总结:也就是在需要搬运的数据之后增加了一个操作.to(device)
# 同样,对于数据也是类似的操作,如下所示:
# 对于训练集
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
# 对于测试集
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
# 总结:.to(device)操作与.cuda()的操作效果是一样的,但是建议使用前者
# 对于其他的结构基本没有改变
完整代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
# 关键步骤
device = torch.device('cuda:0')
# 使用GPU加速
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
# 使用GPU加速
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
# 使用GPU加速
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
# # 使用GPU加速
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
# pred = logits.data.max(1)[1]
# correct += pred.eq(target.data).sum()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
test_loss /= len(test_loader.dataset)
print('nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
代码运行时:
中断运行时:
输出结果为:
Train Epoch: 0 [0/60000 (0%)] Loss: 1.019166
Train Epoch: 0 [20000/60000 (33%)] Loss: 0.914937
Train Epoch: 0 [40000/60000 (67%)] Loss: 0.573446
Test set: Average loss: 0.0021, Accuracy: 8887.0/10000 (89%)
Train Epoch: 1 [0/60000 (0%)] Loss: 0.370093
Train Epoch: 1 [20000/60000 (33%)] Loss: 0.434548
Train Epoch: 1 [40000/60000 (67%)] Loss: 0.356622
Test set: Average loss: 0.0017, Accuracy: 9042.0/10000 (90%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.335962
Train Epoch: 2 [20000/60000 (33%)] Loss: 0.373230
Train Epoch: 2 [40000/60000 (67%)] Loss: 0.324064
Test set: Average loss: 0.0015, Accuracy: 9122.0/10000 (91%)
Train Epoch: 3 [0/60000 (0%)] Loss: 0.269804
Train Epoch: 3 [20000/60000 (33%)] Loss: 0.242959
Train Epoch: 3 [40000/60000 (67%)] Loss: 0.318957
Test set: Average loss: 0.0014, Accuracy: 9186.0/10000 (92%)
Train Epoch: 4 [0/60000 (0%)] Loss: 0.274826
Train Epoch: 4 [20000/60000 (33%)] Loss: 0.219436
Train Epoch: 4 [40000/60000 (67%)] Loss: 0.317634
Test set: Average loss: 0.0013, Accuracy: 9264.0/10000 (93%)
Train Epoch: 5 [0/60000 (0%)] Loss: 0.312060
Train Epoch: 5 [20000/60000 (33%)] Loss: 0.279157
Train Epoch: 5 [40000/60000 (67%)] Loss: 0.344636
Test set: Average loss: 0.0012, Accuracy: 9294.0/10000 (93%)
Train Epoch: 6 [0/60000 (0%)] Loss: 0.185812
Train Epoch: 6 [20000/60000 (33%)] Loss: 0.294017
Train Epoch: 6 [40000/60000 (67%)] Loss: 0.243185
Test set: Average loss: 0.0012, Accuracy: 9318.0/10000 (93%)
Train Epoch: 7 [0/60000 (0%)] Loss: 0.320503
Train Epoch: 7 [20000/60000 (33%)] Loss: 0.213913
Train Epoch: 7 [40000/60000 (67%)] Loss: 0.396971
Test set: Average loss: 0.0011, Accuracy: 9338.0/10000 (93%)
Train Epoch: 8 [0/60000 (0%)] Loss: 0.311513
Train Epoch: 8 [20000/60000 (33%)] Loss: 0.179201
Train Epoch: 8 [40000/60000 (67%)] Loss: 0.246100
Test set: Average loss: 0.0011, Accuracy: 9376.0/10000 (94%)
Train Epoch: 9 [0/60000 (0%)] Loss: 0.144586
Train Epoch: 9 [20000/60000 (33%)] Loss: 0.247070
Train Epoch: 9 [40000/60000 (67%)] Loss: 0.180631
Test set: Average loss: 0.0010, Accuracy: 9387.0/10000 (94%)
训练10个epoch之后正确率有94%
4.可视化训练过程
以下部分代码的解析见:visdom安装与基本用法
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from visdom import Visdom
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('datasets/mnist_data', # 设置下保存路径
train=True,
download=True, # 如果已经存在,则不会再次下载
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 数据类型转化
torchvision.transforms.Normalize((0.1307, ), (0.3081, )) # 数据归一化处理
])), batch_size=batch_size,shuffle=True) # # 从数据库中每次抽出batch_size个样本
# 测试集下载
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('datasets/mnist_data/',
train=False,
download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 数据类型转化
torchvision.transforms.Normalize((0.1307, ), (0.3081, )) # 数据归一化处理
])),batch_size=batch_size,shuffle=False)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.', legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
real_ph = data
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred', opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
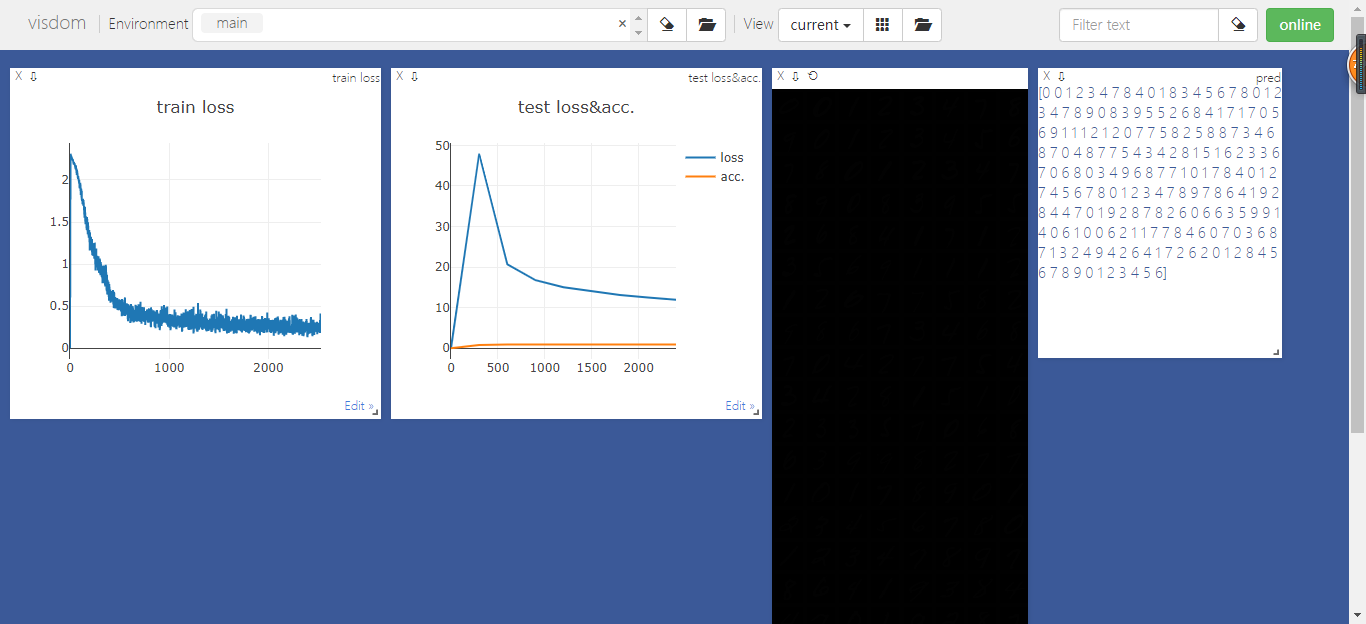
出现了一个问题:图片没有显示出来,待解决
最后
以上就是冷傲战斗机最近收集整理的关于【4】全连接层的认识与实现的全部内容,更多相关【4】全连接层内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复