文章目录
- 前言
- 一、jieba分词
- (一)特点
- (二)主要功能
- 1.分词
- (三)载入词典
- (四)载入词典
- (五)关键词抽取
- 1.基于 TF-IDF 算法的关键词抽取
- 2.基于 TextRank 算法的关键词抽取
- (六)词性标注
- 二、collections 词频统计
前言
jieba是目前python中文分词组件中最好的,安装如下:
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
引用通过:import jieba
一、jieba分词
概述:
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
(一)特点
- 支持四种分词模式:
| 模式 | 特点 |
|---|---|
| 精确模式 | 试图将句子最精确地切开,适合文本分析 |
| 全模式 | 把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义 |
| 搜索引擎模式 | 在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词 |
| paddle模式 | 利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注 |
注:paddle模式使用需安装paddlepaddle-tiny,pip install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba v0.40以下版本,请升级jieba: pip install jieba --upgrade 。 PaddlePaddle官网.
- 支持繁体分词
- 支持自定义词典
- MIT 授权协议
(二)主要功能
1.分词
jieba.cut方法:返回的结构都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语(unicode)。
接受四个参数:
- 需要分词的字符串
- cut_all 参数:是否使用全模式,默认值为 False
- HMM 参数:用来控制是否使用 HMM 模型,默认值为 True
- use_paddle 参数:用来控制是否使用paddle模式下的分词模式
jieba.cut_for_search 方法:接受两个参数,适合用于搜索引擎构建倒排索引的分词,粒度比较细。
- 需要分词的字符串;
- 否使用 HMM 模型,默认值为 True。
jieba.lcut方法:直接返回 list。接受参数与jieba.cut方法一样。
**jieba.lcut_for_search 方法 **:直接返回 list,接受参数与jieba.cut_for_search方法一样。
jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。 jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
例子:
import jieba
#精确模式 试图将句子最精确地切开,适合文本分析
print("/ ".join(list(jieba.cut('我来到了重庆工商大学'))))#因为默认状态是精确模式,所以不用去定义cut_all
#我/ 来到/ 了/ 重庆/ 工商大学
# 全模式 把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
print("/ ".join(list(jieba.cut('我来到了重庆工商大学',cut_all=True))))
#我/ 来到/ 了/ 重庆/ 工商/ 工商大学/ 商大/ 大学
#用jieba.lcut就可以不用list就可以返回
print("{0}".format(jieba.lcut('我来到了重庆工商大学')))
#['我', '来到', '了', '重庆', '工商大学']
print("/ ".join(list(jieba.cut('我来到了重庆工商大学',cut_all=True))))
#我/ 来到/ 了/ 重庆/ 工商/ 工商大学/ 商大/ 大学
# 默认是精确模式 和启用 HMM
# HMM 模型 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
print("/ ".join(list(jieba.cut('他来到了网易杭研大厦'))))
# 他/ 来到/ 了/ 网易/ 杭研/ 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
# 默认是精确模式(cut_all=False) 和启用 HMM(HMM=True)
# HMM 模型 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
print("/ ".join(list(jieba.cut('他来到了网易杭研大厦',cut_all=True))))
# 他/ 来到/ 了/ 网易/ 杭/ 研/ 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
# 不启用 HMM(HMM=False)
print("/ ".join(list(jieba.cut('他来到了网易杭研大厦',HMM=False))))
# 他/ 来到/ 了/ 网易/ 杭/ 研/ 大厦 (未能识别“杭研”)
# 搜索引擎模式
print(list(jieba.cut_for_search('今天,西藏中南部等地的部分地区有小雪或雨夹雪')))
# ['今天', ',', '西藏', '中南', '南部', '中南部', '等', '地', '的', '部分', '地区', '有', '小雪', '或', '雨夹雪']
print(list(jieba.lcut_for_search('今天,西藏中南部等地的部分地区有小雪或雨夹雪')))
# ['今天', ',', '西藏', '中南', '南部', '中南部', '等', '地', '的', '部分', '地区', '有', '小雪', '或', '雨夹雪']
(三)载入词典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率。
用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
字典的格式是:
词语、词频(可省略)、词性(可省略) 空格隔开
创新办 3 i
云计算 5
凱特琳 nz
台中
import jieba
strs = "小明是创新办主任也是云计算方面的专家"
# 未加载词典
print('/ '.join(jieba.cut(strs)))
小明/ 是/ 创新/ 办/ 主任/ 也/ 是/ 云/ 计算/ 方面/ 的/ 专家
# 载入词典
jieba.load_userdict("data.txt")
# 加载词典后
print('/ '.join(jieba.cut(strs)))
小明/ 是/ 创新办/ 主任/ 也/ 是/ 云计算/ 方面/ 的/ 专家
(四)载入词典
- 使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典
import jieba
jieba.add_word('石墨烯') #增加自定义词语
jieba.add_word('凱特琳', freq=42, tag='nz') #设置词频和词性
jieba.del_word('自定义词') #删除自定义词语
- 使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来
import jieba
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#结果:如果/放到/post/中将/出错/。
jieba.suggest_freq(('中', '将'), True)
#结果:494
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#结果:如果/放到/post/中/将/出错/。
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#结果:「/台/中/」/正确/应该/不会/被/切开
jieba.suggest_freq('台中', True)
#结果:69
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#结果:「/台中/」/正确/应该/不会/被/切开
- 注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
(五)关键词抽取
jieba 提供了两种关键词提取方法,分别基于 TF-IDF 算法和 TextRank 算法。
导包
import jieba.analyse
1.基于 TF-IDF 算法的关键词抽取
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
参数解释:
- sentence:为待提取的文本
- topK:为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight:是否一并返回关键词权重值,默认值为 False
- allowPOS:仅包括指定词性的词,默认值为空,即不筛选
例如:
import jieba
import jieba.analyse
s='''
4月28日消息,
中国互联网络信息中心(CNNIC)今日发布第45次《中国互联网络发展状况统计报告》,
报告显示,截至2020年3月,我国网民规模为9.04亿,互联网普及率达64.5%。
'''
# 关键词一并返回关键词权重值
for x, w in jieba.analyse.extract_tags(s, topK=20, withWeight=True):
print('%s %s' % (x, w))
结果如下:

2.基于 TextRank 算法的关键词抽取
通过 jieba.analyse.textrank 方法可以使用基于 TextRank 算法的关键词提取,其与 jieba.analyse.extract_tags 有一样的参数,但前者默认过滤词性(allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’))。
例子:
jieba.analyse.textrank(s, topK=20, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v'))# 直接使用,接口相同,注意默认过滤词性。
结果如下:

(六)词性标注
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
例子:
import jieba
import jieba.posseg as pseg
words = pseg.cut("我爱北京天安门") #jieba默认模式
jieba.enable_paddle() #启动paddle模式。 0.40版之后开始支持,早期版本不支持
words = pseg.cut("我爱北京天安门",use_paddle=True) #paddle模式
for word, flag in words:
print('%s %s' % (word, flag))
结果如下:
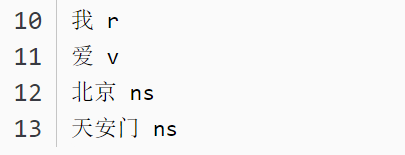
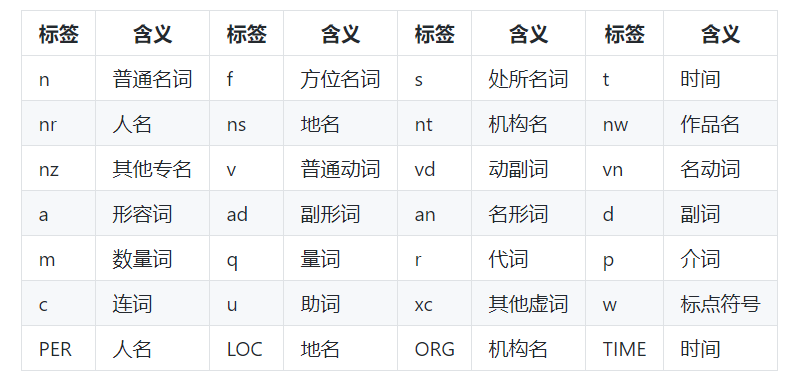
paddle模式词性标注对应表如下:
paddle模式词性和专名类别标签集合如下表,其中词性标签 24 个(小写字母),专名类别标签 4 个(大写字母)。
二、collections 词频统计
#导包
from collections import Counter
import jieba
#获取文本
with open(r'D:论文threekingdoms.txt',encoding='UTF-8') as f:
txt = f.read()#因为是中文文本,所以encoding='UTF-8'
#分词
words = jieba.lcut(txt)
words#查看文字有很多标点符号
#过滤文本
for ch in ',。? !“” ;:、 n':#中文的标点符号,n是换行符
if ch in words:
for i in range(words.count(ch)):
words.remove(ch)#remove只能删除文中第一次出现的,因此采用for循环
#统计词语及个数
# if len(word) >=2:只统计2次以上的字
counts = {}
for word in words:
if len(word) >=2:
counts[word] = counts.get(word,0) + 1#get方法找不到单词的次数就返回默认值0,找到了就获得次数值上再加1
# 排序输出
items = list(counts.items())#items将字典的键值对以元组(键x[0]和值x[1]的形式打包,为了方便后续进行sort()排序,将元组转化为列表类型
items.sort(key = lambda x:x[1],reverse = True)
for i in range(20):
word,count = items[i]
#print('{0:<5} {1:>5}'.format(word,count))
print('{0:<{width}}{1}'.format(word,count,width = 10-(len(word.encode('GBK'))-len(word))))#输出对齐
结果如下:

最后
以上就是聪慧胡萝卜最近收集整理的关于jieba分词+collections 词频统计前言一、jieba分词二、collections 词频统计的全部内容,更多相关jieba分词+collections内容请搜索靠谱客的其他文章。








发表评论 取消回复