本文介绍了上海科技大学屠可伟研究组与乐言科技的一项合作研究,提出了将正则表达式规则与神经网络深度融合的新思路。该论文已被 EMNLP 2020 接收为长文。
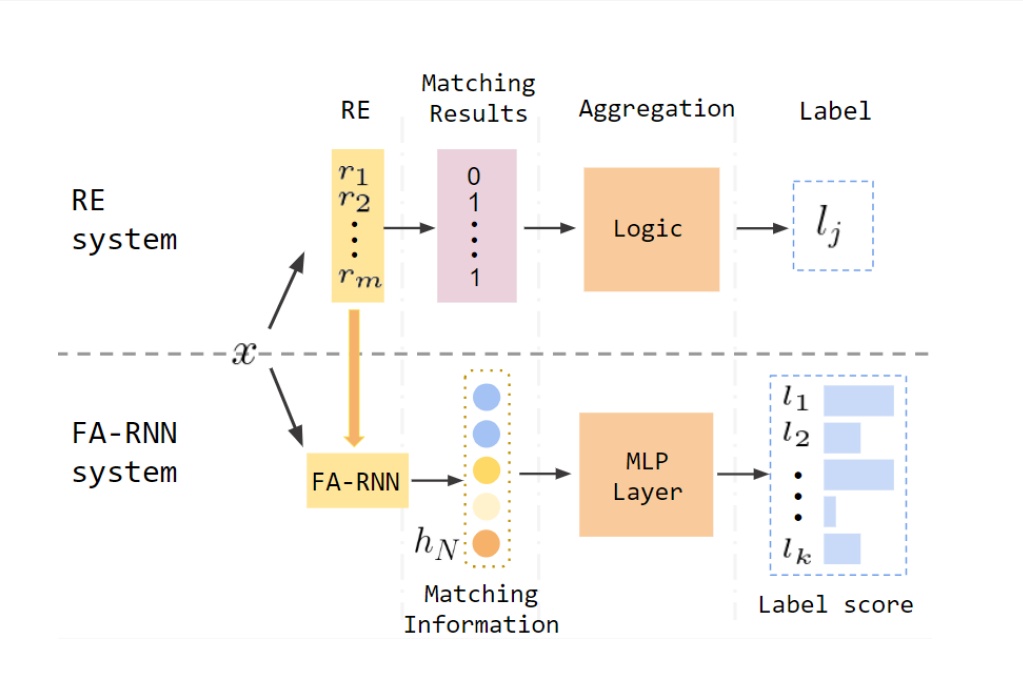
论文的作者将Regular Expression(RE)与Recurrent Neural Network(RNN)结合,创造了新的FA-RNN模型。该模型结合了RE的可解释性高的优点与RNN的可以利用标注文本进行训练的优点,能够获得比纯RE以及传统的深度学习模型更好的预测效果。
本文共分为五个部分,分别介绍了FA-RNN模型的名称解释、使用流程、与BERT的比较、预测效果、应用场景。
一、模型名称解释
这篇论文介绍了一种新的自然语言处理方法FA-RNN。这种方法实际上是两种现有方法的结合。
第一部分FA表示finite-automation(FA),它是从RE转化而来的一种工具,转化得到的FA所表达的信息和RE表达的信息是等价的。由于FA的特殊结构,可以方便地通过数学变换把FA转成RNN,因此RE蕴含的信息就能作为pretrained信息输入到RNN中(这也是要把RE转成FA的原因)。
第二部分就是RNN,这部分就是常规的Deep Learning(DL)的过程。用标注过的training set训练模型,RNN就能从训练集中获得增量的文本信息。
整合这两部分的方法是,通过β系数,调整两个部分在模型预测中的权重。这个β是hyper-parameter,需要手工设置,取值范围为[0,1]。
二、模型使用的流程
首先,请专家根据任务特征,写好若干条(通常在20条以上)能提取文本关键信息的RE规则,把每一条RE都对应到一个预测outcome上。例如下图是一个多分类任务,图中的正则表达式对应的outcome为“FLIGHT”,表示如果这个正则表达式匹配到内容,对应的标签为FLIGHT。
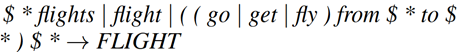
然后,将这些RE规则转化成FA,再转化成RNN(参考“一、模型名称解”)。这就是Pretrained Word Embedding。
之后,把training set给feed到RNN中,得到训练结果。
三、模型的优势以及与BERT的比较
(一)只需要很少的标注数据
1. 优势:根据作者的实验,这个模型只需要传统的RNN的10%甚至更少的标注数据,就能得到同样甚至更好的效果。在zero-shot and cold-start scenarios有很好的表现。
2. 和BERT的比较:这个优势是引入了pretrained的信息的优势。这个优势的原理其实和BERT非常相似。BERT是通过大量数据的预训练生成一个预训练的数据包,然后通过很少量的标注数据fine-tune。FA-RNN是要求专家事先写好一些提取关键特征的RE(FA的部分),然后通过很少量的标注数据fine-tune(RNN的部分)。不同点在于,BERT的pretrained information来自于预训练,FA-CNN的pretrained information来自于专家写的RE。
(二)模型调整灵活自由
1. 优势:由于引入了FA这个工具,可以随时(不论是在模型训练前还是训练完成后)根据专家意见,一条一条往RNN中加入新的RE,或者一条一条删除已有的RE,非常灵活。
2. 和BERT的比较:这点FA-RNN完胜。根据Google团队的论文,没有看到BERT有这个功能。不过,我觉得这个点还是胜在模型的可解释性上。手动地删减RE,在效率上(成果/时间)不一定划算。
(三)模型的可解释性高
1. 优势:由于引入了FA这个工具,训练好的RNN可以转化为FA再转化为RE,这样熟练RE的人就能看懂具体是用什么样的规则来处理的;对于不熟练RE的人,可以运行这个由RNN转换来的RE,以此展示是句子的哪一个部分对于预测一个label起到最大的作用。
2. 和BERT的比较:BERT不具有这种功能。
四、模型的预测效果
作者使用了三个数据集来验证FA-RNN的效果。对于每一个数据集,分别取了训练集的1%、10%、100%,来验证模型在训练集样本较少的情况下的预测效果。下图是作者用FA-RNN做文本分类任务的效果。
Columns的名称是三个用于检测的数据集,class表示是需要predict的Y是几分类的。下面的1%,10%,100%表示用到了训练集(样本量都在5000左右)的多少比例的数据。
Index的名称是用来对比的模型。带FA的(最上面四个)都是作者发明的FA-RNN模型及其变体。Bi表示在模型中加入了双向理解语义的修改。+i、+o等,表示对模型形式进行了其他一些很小的微调。
数字是Accuracy,加粗的数字是表现最好的值。
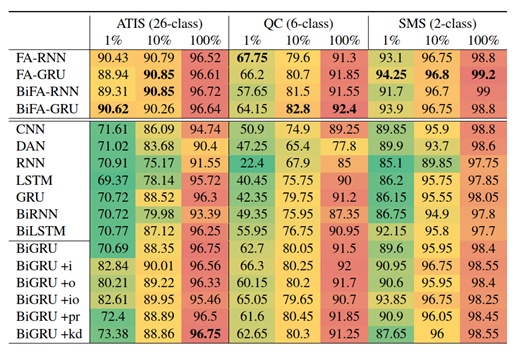
可以发现,表现最好的模型,基本都是带FA的,也就是作者发明的FA-RNN模型。尤其是在training set非常小的时候,例如只用1%的training set(将近500个observation),在效果上比其他的模型有很大的领先。
五、模型的应用场景
FA-RNN要求事先人工输入一定量的RE来提取文本特征。在zero-shot(也就是没有training-set,不训练RNN)的情况下,可以获得和RE几乎相同的效果(这里表示由RE转化成RNN的过程不会带来预测效果的损失),以及超越传统DN模型的效果。在有很小的training-set的情况下,可以获得超过RE以及传统的DN模型的效果。
FA-RNN和BERT相比,在预测准确性以及对于人工工作量方面,我觉得没有优势。在预测准确性方面,估计FA-RNN最多就是达到90%,可能BERT还要好一些。在人工工作量方面,FA-RNN要求预先准备若干条RE并要求它们能较好的提取文本特征,这还是需要一定的时间的。BERT本身拥有预训练模型,需要做的就是为fine-tune准备标注好的数据。具体运用中,去网上找别人标注好的数据更省时间。
因此,FA-RNN最重要的应用场景就是可以应对对于可解释性要求高的任务,它的学习结果可以重新转化成RE,在演示的过程中,更容易理解。
最后
以上就是鲜艳金针菇最近收集整理的关于取值范围的正则表达式_将正则表达式引入RNN从而提升深度学习的可解释性的全部内容,更多相关取值范围内容请搜索靠谱客的其他文章。






![[论文阅读] CKAN: Collaborative Knowledge-aware Atentive Network for Recommender Systems](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)

发表评论 取消回复