点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

前言:
在计算机视觉方向,数据增强的本质是人为地引入人视觉上的先验知识,可以很好地提升模型的性能,目前基本成为模型的标配。最近几年逐渐出了很多新的数据增强方法,在本文将对数据增强做一个总结。
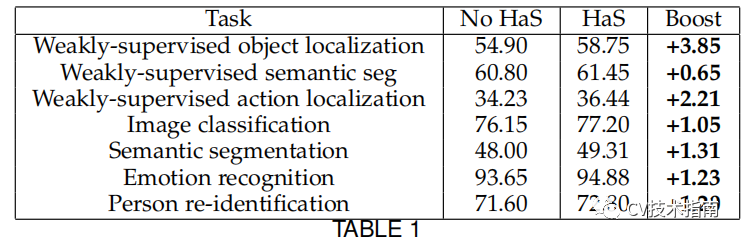
本文介绍了数据增强的作用,数据增强的分类,数据增强的常用方法,一些特殊的方法,如Cutout,Random Erasing,Mixup,Hide-and-Seek,CutMix,GridMask,FenceMask和KeepAugment等方法,还介绍了一些基于多样本的增强方法,如SMOTE, mosaic和SamplePairing。
值得一提的是,在这些论文中,几乎每一篇都使用CNN可视化方法来证明其增强方法的有效性,在某种程度上来说也是为了增加工作量和字数。对CNN可视化方法感兴趣的读者可在CV技术指南中阅读这系列总结文章。
《CNN可视化技术总结》
数据增强的作用
1. 避免过拟合。当数据集具有某种明显的特征,例如数据集中图片基本在同一个场景中拍摄,使用Cutout方法和风格迁移变化等相关方法可避免模型学到跟目标无关的信息。
2. 提升模型鲁棒性,降低模型对图像的敏感度。当训练数据都属于比较理想的状态,碰到一些特殊情况,如遮挡,亮度,模糊等情况容易识别错误,对训练数据加上噪声,掩码等方法可提升模型鲁棒性。
3. 增加训练数据,提高模型泛化能力。
4. 避免样本不均衡。在工业缺陷检测方面,医疗疾病识别方面,容易出现正负样本极度不平衡的情况,通过对少样本进行一些数据增强方法,降低样本不均衡比例。
数据增强的分类
根据数据增强方式,可分为两类:在线增强和离线增强。这两者的区别在于离线增强是在训练前对数据集进行处理,往往能得到多倍的数据集,在线增强是在训练时对加载数据进行预处理,不改变训练数据的数量。
离线增强一般用于小型数据集,在训练数据不足时使用,在线增强一般用于大型数据集。
常用方法
比较常用的几何变换方法主要有:翻转,旋转,裁剪,缩放,平移,抖动。值得注意的是,在某些具体的任务中,当使用这些方法时需要主要标签数据的变化,如目标检测中若使用翻转,则需要将gt框进行相应的调整。
比较常用的像素变换方法有:加椒盐噪声,高斯噪声,进行高斯模糊,调整HSV对比度,调节亮度,饱和度,直方图均衡化,调整白平衡等。
这些常用方法都比较简单,这里不多赘述。
Cutout(2017)
该方法来源于论文《Improved Regularization of Convolutional Neural Networks with Cutout》
在一些人体姿态估计,人脸识别,目标跟踪,行人重识别等任务中常常会出现遮挡的情况,为了提高模型的鲁棒性,提出了使用Cutout数据增强方法。该方法的依据是Cutout能够让CNN更好地利用图像的全局信息,而不是依赖于一小部分特定的视觉特征。
做法:对一张图像随机选取一个小正方形区域,在这个区域的像素值设置为0或其它统一的值。注:存在50%的概率不对图像使用Cutout。
效果图如下:

官方代码:
https://github.com/uoguelph-mlrg/Cutout
Random Erasing(2017)
该方法来源于论文《Random Erasing Data Augmentation》
这个方法有点类似于Cutout,这两者同一年发表的。与Cutout不同的是,Random Erasing掩码区域的长宽,以及区域中像素值的替代值都是随机的,Cutout是固定使用正方形,替代值都使用同一个。
具体算法如下:

其效果图如下:

官方代码:
https://github.com/zhunzhong07/Random-Erasing
Mixup(2018)
该方法来源于论文《mixup: BEYOND EMPIRICAL RISK MINIMIZATION》
主要思想是将在数据集中随机选择两张图片按照一定比例融合,包括标签值。在论文中给出了代码,看一眼代码即可很好的理解。

效果图如下:
一张海上帆船与熊猫的融合。

官方代码:
https://github.com/facebookresearch/mixup-cifar10
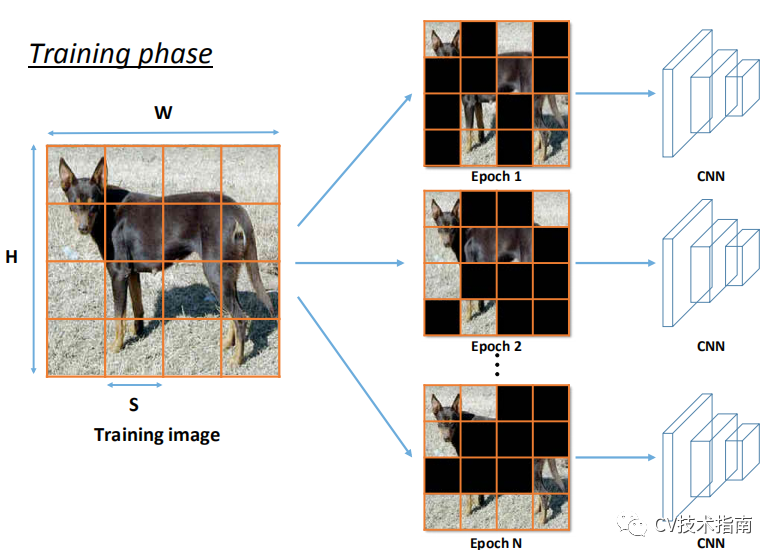
Hide-and-Seek(2018)
该方法来自论文《Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond》
其主要思想就是将图片划分为S x S的网格,每个网格按一定的概率(0.5)进行掩码。其中不可避免地会完全掩码掉一个完整的小目标。当这种思想用于行为识别时,做法是将视频帧分成多个小节,每一小节按一定的概率进行掩码。
注:论文提到掩码所使用的替代值会对识别有一定的影响,经过一些理论计算,采用整个图像的像素值的均值的影响最小。
在CNN可视化技术总结中,我们提到CNN可视化具有提高方法可信度,增加工作量,增加字数的作用,这点在这篇论文中得到了很好的体现,论文使用了CAM和卷积核可视化等可视化方法来分析该算法的合理性。
《CNN可视化技术总结--卷积核可视化》
《CNN可视化技术总结--类可视化》
效果:
官方代码:
https://github.com/kkanshul/Hide-and-Seek
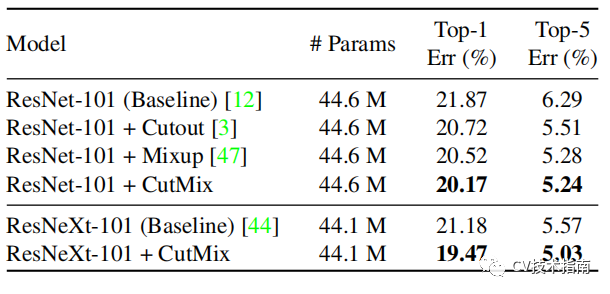
CutMix(2019)
该方法来源于《CutMix: Regularization Strategy to Train Strong Classififiers with Localizable Features》
该方法结合了Cutout、Random erasing和Mixup三者的思想,做了一些中间调和的改变,同样是选择一个小区域,进行掩码,但掩码的方式却是将另一张图片的该区域覆盖到这里。看图更能理解这种方法。


在理解上面这个图后,实现方式比较简单,公式如下:
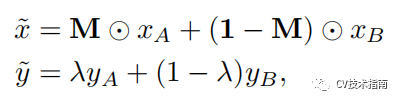
关于这个掩码区域大小的设置,使用如下公式确定:
其中宽和高的大小始终满足后面这个等式。
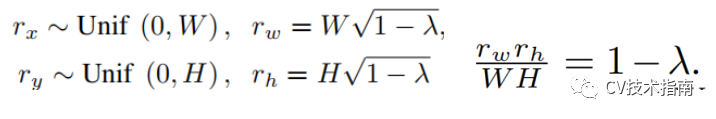
效果如下:
官方代码:
https://github.com/clovaai/CutMix-PyTorch
GridMask(2020)
该方法来源于《GridMask Data Augmentation》
主要思想是对前几种方法的改进,由于前几种对于掩码区域的选择都是随机的,因此容易出现对重要部位全掩盖的情况。而GridMask则最多出现部分掩盖,且几乎一定会出现部分掩盖。使用的方式是排列的正方形区域来进行掩码。


具体实现是通过设定每个小正方形的边长,两个掩码之间的距离d来确定掩码,从而控制掩码细粒度。
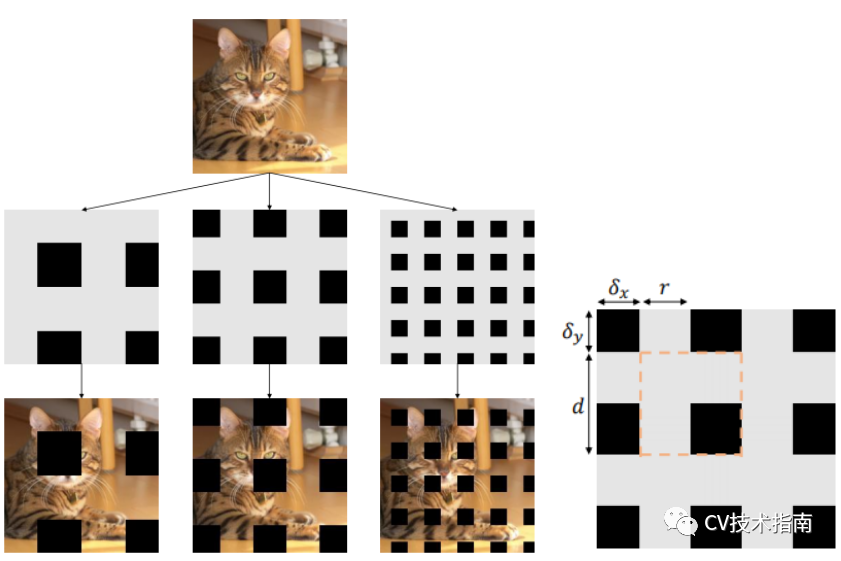
效果如下:

官方代码:
https://github.com/akuxcw/GridMask
FenceMask(2020)
该方法来源于《FenceMask: A Data Augmentation Approach for Pre-extracted Image Features》
该方法是对前面GridMask的改进,认为使用正方形的掩码会对小目标有很大的影响。因此提出了更好的形状,FenceMask具有更好的细粒度。

效果对比如下:

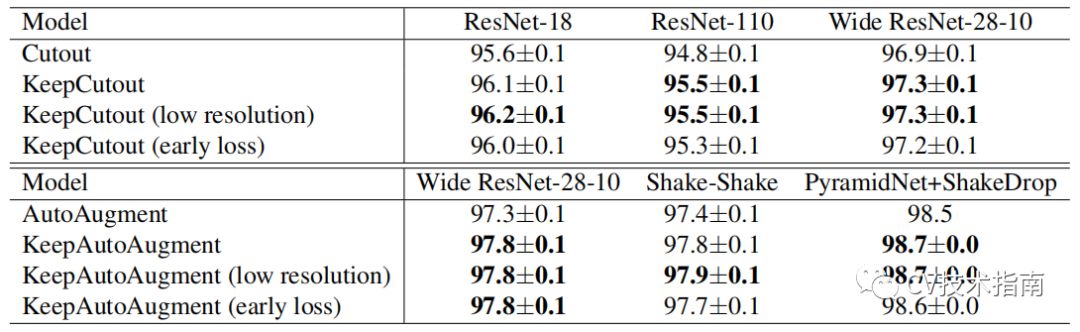
KeepAugment(2020)
该方法来源于《KeepAugment: A Simple Information-Preserving Data Augmentation Approach》
主要思想是对前几种方法中随机选择掩码区域的改进,通过得出Saliency map,分析出最不重要的区域,选择这个区域进行Cutout,或者分析出最重要区域进行CutMix。

saliency map区域的计算方式与类可视化的方法一致,通过计算回传梯度,获得每个像素值的梯度,从而确定每个像素值对类别的影响程度。而最重要区域和最不重要区域的划分是通过这个区域的所有梯度值之和大于或小于某个相应的阈值来确定。
具体如何计算saliency map请阅读《CNN可视化技术总结--类可视化》。
算法如下:(其中Selcetive-cut是使用Cutout, Selective-paste是使用CutMix)

效果如下:
其它的数据增强方法
RandAugment,FastAugment,AutoAugment这几种方式都是属于构造一个数据增强方式的集合,采用强化学习的方式搜索适合指定数据集的数据增强方法。这些方法的最大特点是成本大,需要的时间很长很长,因此这里不多介绍。
注:前面提到的那些方法,基本都是接近零成本,更具有普遍使用的特性,这里几种只适合贵族。
此外还有通过GAN来实现风格迁移等数据增强方式。
多样本数据增强方法
前面提到的方法除了CutMix和Mixup外,基本都属于单样本增强,此外还有多样本增强方法,主要原理是利用多个样本来产生新的样本。
SMOTE--该方法来自遥远的2002年。主要应用在小型数据集上来获得新的样本,实现方式是随机选择一个样本,计算它与其它样本的距离,得到K近邻,从K近邻中随机选择多个样本构建出新样本。之所以不提论文中的构建方式,是因为该方法并不是用于图像,但读者可自主设计出图像的构建方式。
Mosaic--该方法来源于YOLO_v4,原理是使用四张图片拼接成一张图片。这样做的好处是图片的背景不再是单一的场景,而是在四种不同的场景下,且当使用BN时,相当于每一层同时在四张图片上进行归一化,可大大减少batch-size。
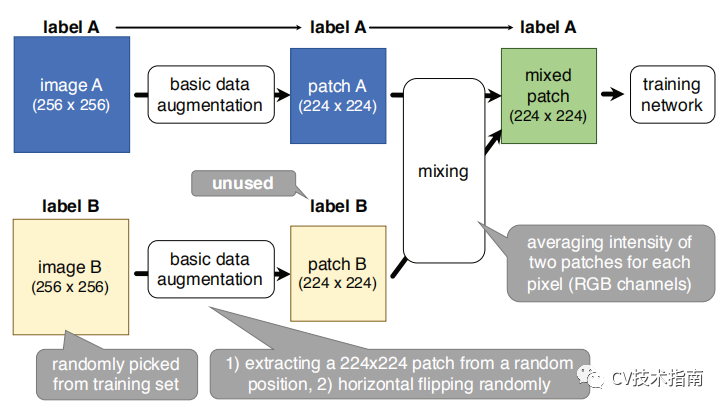
SamplePairing--该方法的原理是从训练集中随机选择两张图片,经过几何变化的增强方法后,逐像素取平均值的方式合成新的样本。具体如下图所示:
总结
本文介绍了常用的数据增强方法,几种特殊的增强方法,几种多样本增强方法。
理论上来说,数据增强方法还应该包括对一些用于解决正负样本不均衡的方法,如hard negative example mining,focal loss等。
此外在网络中使用DropOut , DropConnect 和 DropBlock,也应该算是数据增强方法,因为它们与Cutout,Hide-and-Seek和GridMask等方法类似,同样是选择性丢弃一些数据。
注:在CV技术指南中回复“数据增强”可获取数据增强相关13篇论文。
参考论文
Improved Regularization of Convolutional Neural Networks with Cutout
Random Erasing Data Augmentation
mixup: BEYOND EMPIRICAL RISK MINIMIZATION
Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond
CutMix: Regularization Strategy to Train Strong Classififiers with Localizable Features
GridMask Data Augmentation
FenceMask: A Data Augmentation Approach for Pre-extracted Image Features
KeepAugment: A Simple Information-Preserving Data Augmentation Approach
SMOTE: Synthetic Minority Over-sampling Technique
YOLOv4: Optimal Speed and Accuracy of Object Detection
Data Augmentation by Pairing Samples for Images Classifification
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 
最后
以上就是贪玩雨最近收集整理的关于计算机视觉数据增强方法汇总的全部内容,更多相关计算机视觉数据增强方法汇总内容请搜索靠谱客的其他文章。








发表评论 取消回复