本篇博文继续整理推荐系统系列,更多文章可以参考博主的以往系列论文:推荐系统专栏。
自监督学习在CV和NLP已经用的很多了,那很自然也会被迅速引进并占坑到推荐系统领域咯。而发掘推荐数据上的自监督信号,其实也是十分有利于推荐系统的,主要有以下优势:
- 舒缓数据稀疏。一般来说推荐系统的数据集,有点击的监督数据不便于收集,非常少,而且高度稀疏化,因此通过自监督学习是可以对数据进行增强和扩增的;
- 舒缓噪音干扰。不但数据集稀疏,而且比如点击数据存在误点错点击等等的现象,因此解决噪音干扰也是自监督学习可以提供的优势。
- 舒缓长尾分布。另外长尾问题甚至冷启动问题也基本是一直伴随着这个领域,所以一些冷门商品和用户的学习在这种情况下会更加的不充分,因此用自监督进行增强也是不错的选择。
同时也有一些论文提过某些设计良好的自监督任务可以完成跨域推荐,比如可以通过自监督学习融合多个域的信息来增强网络的表达能力。关于自监督的一些方法不会科普,现在主要用的最多的就是对比学习,可以考虑参考博主以往的整理:对比学习。现在直接来看看几篇有代表力的文章。
Self-supervised Learning for Large-scale Item Recommendations
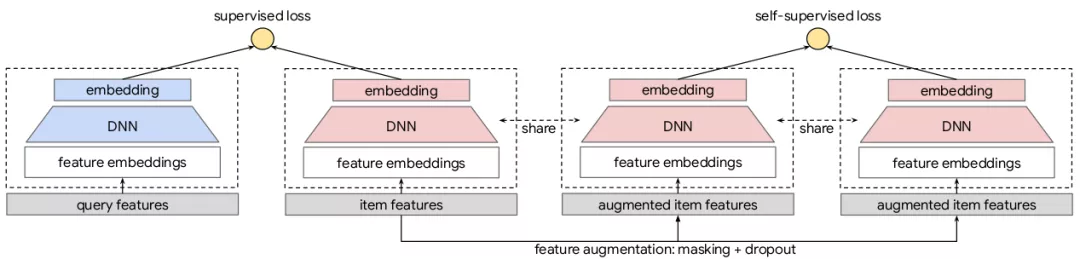
来自Google,想要解决的问题是数据稀疏+长尾。主要提出了一个针对大规模商品推荐的自监督学习(SSL)框架,模型框架如上图,基本思路就是想在双塔结构上做数据增强来更好地学习特征之间的潜在联系。
- 数据增强。有两种方式:Masking和Dropout,其中masking是随机掩掉一些输入特征,dropout就是简单的随机丢失一些输入特征,以增加自监督任务学习的难度。值得注意的是,这里的masking源自于BERT的mask方法,但由于特征之间不存在顺序关系,所以作者额外提出了Correlated Feature Masking (CFM)方法,通过挖掘特征之间的关联来设计更难一点的masking pattern。 M I ( V i , V j ) = ∑ v i ∈ V i , v j ∈ V j P ( v i , v j ) l o g P ( v i , v j ) P ( v i ) P ( v j ) MI(V_i, V_j) = sum_{v_i in V_i, v_j in V_j} P(v_i, v_j)log frac{P(v_i, v_j)}{P(v_i)P(v_j)} MI(Vi,Vj)=vi∈Vi,vj∈Vj∑P(vi,vj)logP(vi)P(vj)P(vi,vj)具体做法是计算不同特征之间的互信息,再根据特征关联来进行特征的分割。即在masking的过程中,每次都选取互信息最大的几个特征进行mask,这样就能充分加大学习难度。
- 多任务学习。增强完数据之后就可以学习了,学习框架如上图,正常的数据和增强的数据都会过双塔的架构,其中三个粉色塔是shared的。然后分别算两个loss,即普通的Supervised loss和自监督的self-supervised loss。自监督的loss使用对比学习,文中所用的公式和SimCLR很像:
L s e l f ( { x i } ; H , G ) : = − 1 N ∑ i ∈ [ N ] l o g e x p ( s ( z i , z i ′ ) / τ ) ∑ j ∈ [ N ] e x p ( s ( z i , z j ′ ) / τ ) L_{self}({x_i};H, G) := -frac{1}{N}sum_{i in [N]}logfrac{exp(s(z_i, z_i')/tau)}{sum_{jin [N]}exp(s(z_i, z_j')/tau)} Lself({xi};H,G):=−N1i∈[N]∑log∑j∈[N]exp(s(zi,zj′)/τ)exp(s(zi,zi′)/τ)即希望模型能够将同一个物品的特征表示尽可能相同,不同的物品的特征表示尽可能不同。
S^3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization
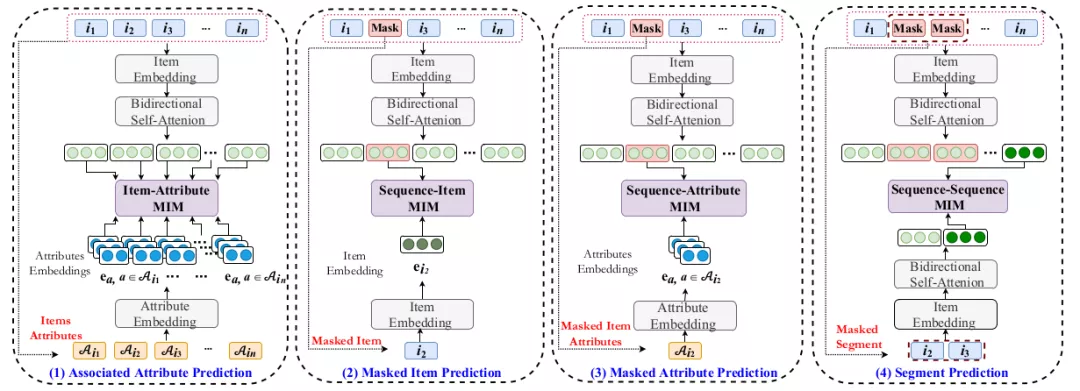
来自CIKM20’,任务是序列推荐,解决的问题是数据稀疏影响交互学习。这篇文章比较重要的贡献就是提供了4个自监督任务来分别学习商品-属性、序列-商品、序列-属性和序列-子序列。首先Base Model比较常见,就是embedding之后+自注意力感知上下文,然后实现序列预测。然后基于这样的base完成四个任务。
- Modeling Item-Attribute Correlation。物品属性提供细粒度信息, 因此通过对物品-属性相关性进行建模来融合物品和属性级别的信息。如图1的输入是属性,然后基于InfoNCE最大化物品和属性间的互信息来训练这个任务。
- Modeling Sequence-Item Correlation。这个任务和BERT的mask一致,随机掩输入序列中的一部分物品[mask], 然后尝试从上下文中预测被mask掉的物品。
- Modeling Sequence-Attribute Correlation。进一步融合序列上下文和物品属性信息,同样通过mask的方式来实现,这对于改善多粒度信息的数据表征很有用。
- Modeling Sequence-Segment Correlation。从单个物品扩展到物品子序列可以比单个物品反映出更稳定的用户偏好。具体做法是打乱子序列来共同训练。
Self-supervised Graph Learning for Recommendation
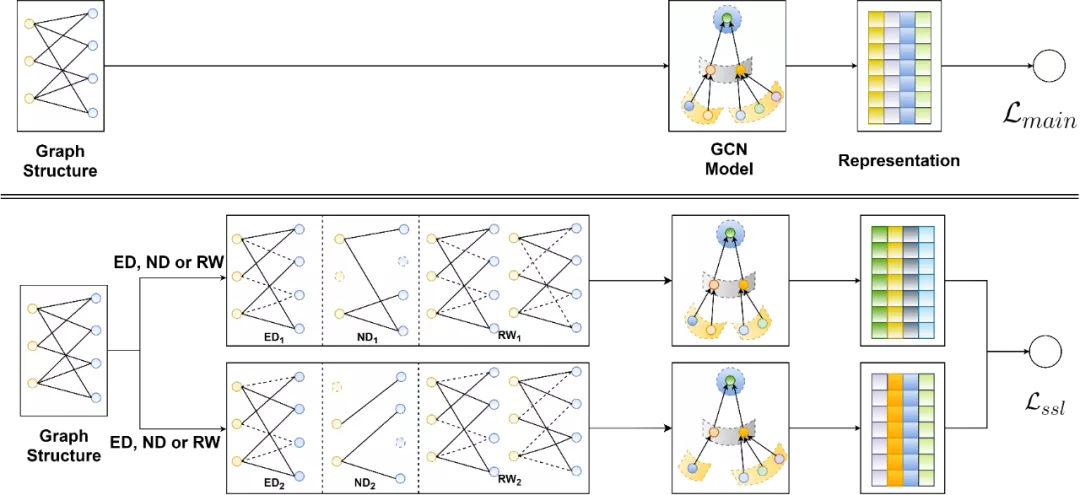
来自SIGIR2021,还是得看何向南组的文章。这篇文章把自监督学习做到Graph中,解决的问题也和开篇整理的问题类似:数据稀疏、数据长尾和存在噪声。主要的贡献应该集中在提供了集中在Graph上的数据增强方式以得到多个视角:node dropout, edge dropout 和 random walk。
- 节点舍弃(Node Dropout)。以概率p的可能性在图中舍弃节点,以识别出有影响的节点,并使表征学习对结构变化不那么敏感。
- 边舍弃(Edge Dropout)。和节点舍弃类似,捕获节点局部结构的有用模式,并进一步赋予表示对噪声交互的更强的鲁棒性。
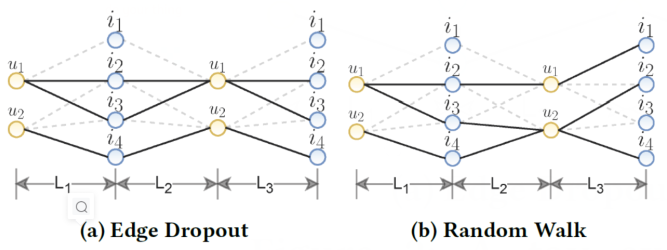
- 随机游走(Random Walk)。上述两种方法都是在同一层中生成不同子图,而随机游走则是为不同层分配不同子图。如下图是三层GCN的示意图,即在a中如果u1和i3有边,那么多层GCN它们仍然有边,但是在b中则是不会依照Graph中的双向性规则,纯游走。
然后用对比学习的方式,来最大化不同节点表示的差距。这样的数据增强和预训练方式能够从原始的图数据中发掘出更多的监督信号,使得图神经网络能够更好的学习到节点表示。
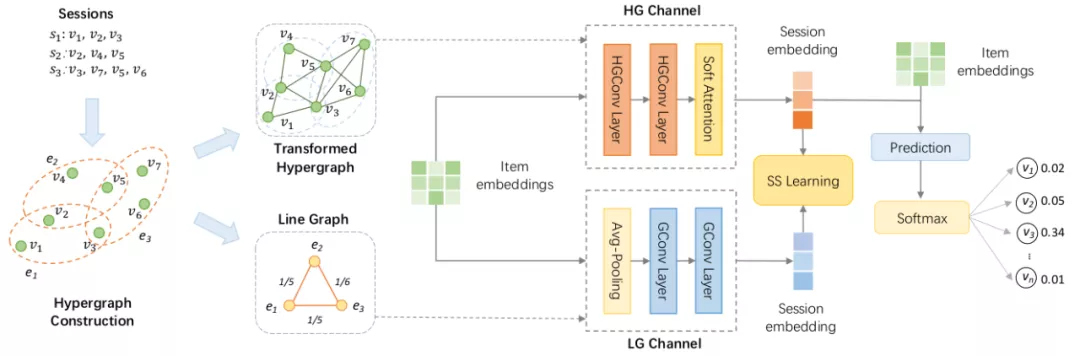
Self-Supervised Hypergraph Convolutional Networks for Session-based Recommendation
来自AAAI 2021,任务是会话推荐,主要通过双通道超图卷积网络DHCN来学习,dual channel指超图Hyper Graph和线超图 Line Graph。超图是直接拿session来构,而线图则是一个基于session相似度来构建的完全图。模型图如上,构完图之后会先过超图卷积进行图学习,然后才是利用自监督学习来增强embedding表示,理由是会话数据的稀疏性可能会阻碍超图建模。
然后其实具体做法挺简明的。其实item embedding经过两个通道即Hyper Graph和 Line Graph的学习之后,就可以被视为标签的增广了。所以直接最大化超图通道的表示与线超图通道的表示之间的互信息即可,即如果两个会话Embedding在两个视图中都表示同一个会话,就将这一对标记为正例,否则为负例。
paper:https://arxiv.org/abs/2012.06852
code:https://github.com/xiaxin1998/DHCN
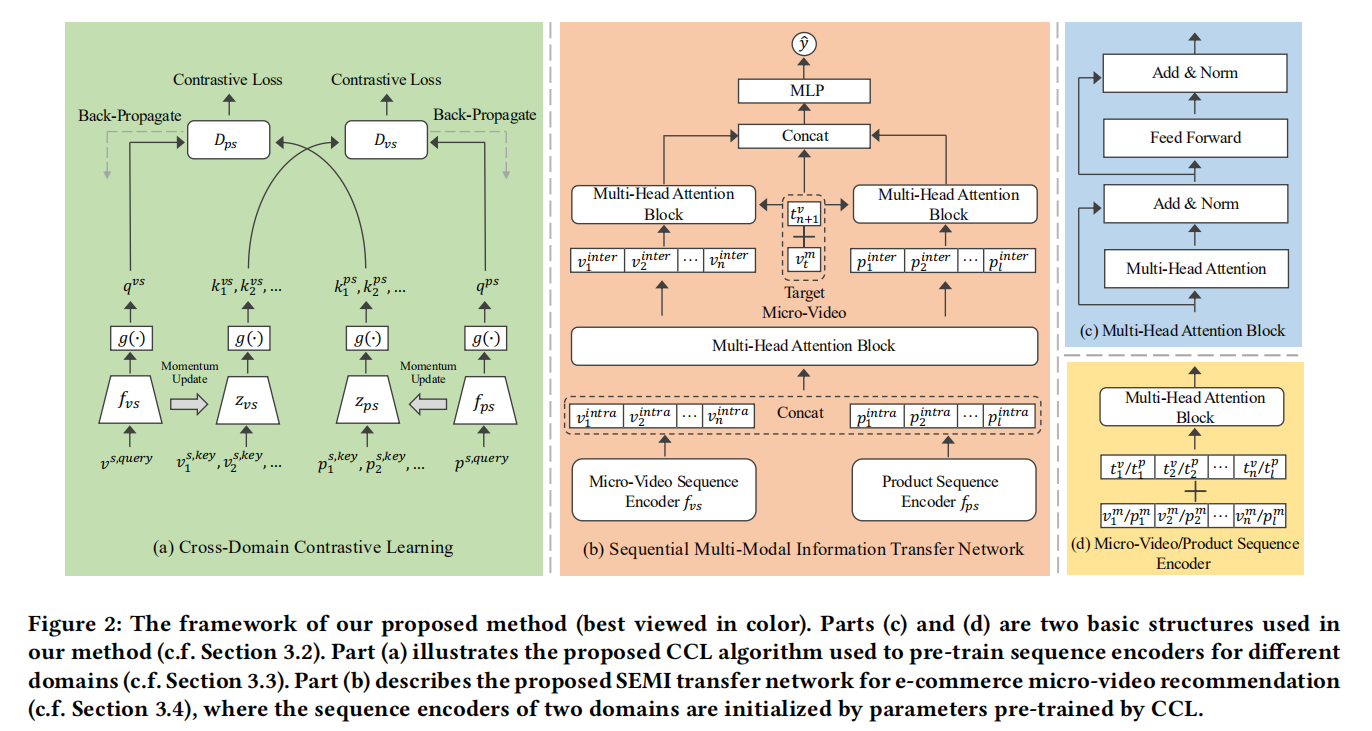
SEMI: A Sequential Multi-Modal Information Transfer Network for E-Commerce Micro-Video Recommendations
来自KDD2021],跨域短视频推荐。动机在于现有的短视频推荐方法只关注用户的浏览行为,而忽略了用户在电子商务环境中的购买意图。因此,作者设计了一个均衡多模态信息传输网络(SEquential Multi-modal Information transfer network,SEMI),它利用产品域的用户行为来辅助短视频推荐。模型图如上。
具体来说,主要通过跨域对比学习(Cross-Domain Contrastive Learning,CCL)来优化视频域和产品域之间的行为模式差距,如上图最左的a图。CCL通过最小化在同一用户行为会话中微视频和相同的产品表示之间的距离,对跨域序列行为施加双重约束。
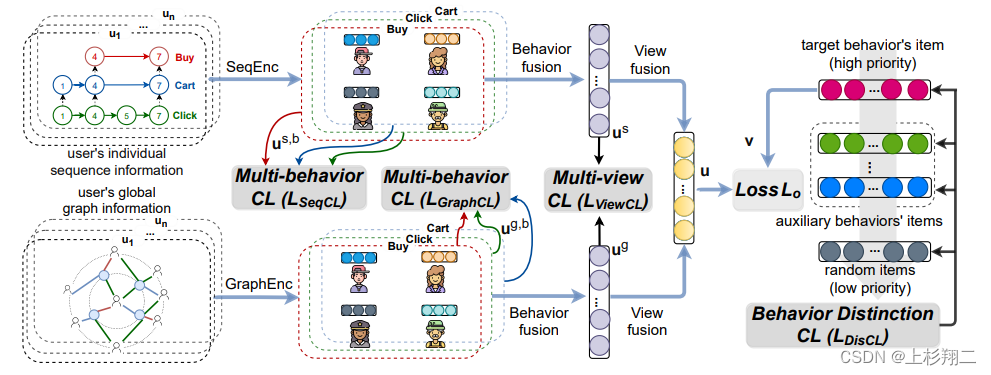
Multi-view Multi-behavior Contrastive Learning in Recommendation
补文DASFAA 2022,多视图多行为对比学习推荐系统。任务是多行为推荐(MBR),旨在联合考虑多种行为以提高目标行为的推荐效果,作者们的出发点在于:
- 如何对用户行为之间的粗粒度共性进行建模?
- 如何联合考虑用户个体和全局的视图?
- 如何学习用户多行为之间的细粒度差距?
因此提出了一种新颖的多行为多视图对比学习推荐(MMCLR)框架,模型图如上。
- 序列编码和图编码模块。将用户的行为历史,构造成不同的视图,这里是图视图和序列视图。Bert4Rec和LightGCN分别作为序列编码器和图编码器。
- 三个对比学习任务,包括多行为对比学习、多视图对比学习和行为区别对比学习。多行为对比学习其核心是一个用户的不同行为之间的表示应当要比另一个用户更加接近,因为用户的不同行为均在某种程度上表示了用户的兴趣片偏好。多视图对比学习其核心是同一个用户不同视图下的表示应当比另一个用户更为接近。行为区别对比学习其核心是目标行为的优先级要高于辅助行为,辅助行为的优先级要高于随机采用的物品。
paper:https://arxiv.org/pdf/2203.10576
code:https://github.com/wyqing20/MMCLR
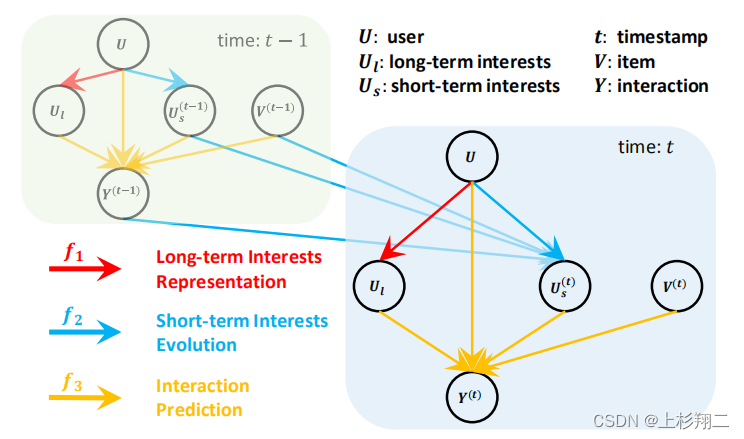
[WWW2022] Disentangling Long and Short-Term Interests for Recommendation
继续补文,来自WWW22的文章。motivation来自于建模用户的长期和短期兴趣虽然很重要,长期兴趣提供了用户偏好的整体视图,总结了整个历史交互,而短期兴趣随着时间的推移而动态演变,反映了最近的交互。
但由于没有标签,现有的方法总是很难分清这俩,这可能导致推荐的准确性和可解释性较差。如上图,用户兴趣建模由三种机制组成,即长期兴趣表示(红色边)、短期兴趣演化(蓝色边)和交互预测(黄色边)。
因此作者们用对比学习将长期和短期的推荐兴趣分离。具体来说,模型结构图如下:
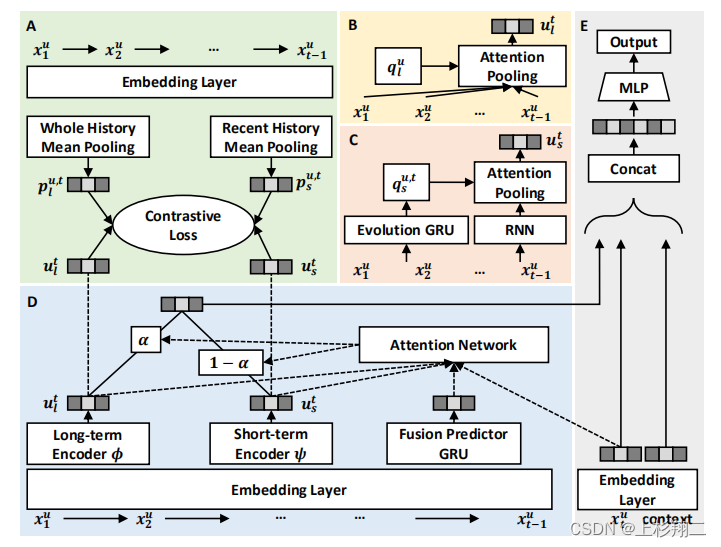
- 首先两个独立的编码器分别捕获不同时间尺度的用户兴趣。其中长期由注意力池化得到,短期由rnn进行编码。
- 然后从交互序列中提取长期和短期兴趣代理作为用户兴趣的伪标签。即计算整个交互历史的平均表示作为长期利益的代理,并使用最近的????交互的平均表示作为短期利益的代理。
- 两两对比任务的设计是为了监督最新表征与其对应的兴趣代理之间的相似性。
- 最后,由于长期和短期兴趣的重要性是动态变化的,因此注意力聚合起来进行预测。
paper:https://arxiv.org/pdf/2202.13090v1
code:https://github.com/tsinghua-fib-lab/CLSR
最后
以上就是健康雪碧最近收集整理的关于对比学习用于推荐系统问题(SSL,S^3-Rec,SGL,DHCN,SEMI,MMCLR)的全部内容,更多相关对比学习用于推荐系统问题(SSL内容请搜索靠谱客的其他文章。








发表评论 取消回复