目录
问题和初步
问题表述
基于符号的方法
基于步行的方法
提出的方法:RuleGuider
模型架构
Relation Agent
Entity Agent
Policy Network
Model Learning
奖励设计
培训程序
实验
实验装置
Datasets
Hyperparameters
结果
消融研究
人工评估
结论
问题和初步
-
问题表述
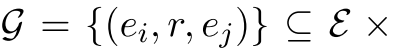
![]()
给定一个查询: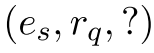 。
。
KG推理的任务是找到一组对象实体![]() ,使得
,使得![]() ,其中
,其中![]() 是
是![]() 中缺少的事实三元组。
中缺少的事实三元组。
为了与大多数现有作品保持一致,本文只考虑尾部查询。![]()
-
基于符号的方法
某些以前的方法是从KG挖掘Horn规则,并通过将这些规则作为基础来预测缺失的事实。 最近的方法AnyBURL(Meilicke et al.,2019)表现出与基于嵌入技术的最先进方法相当的性能。
但是,这些方法有局限性。 例如,从不同KG提取的规则可能具有不同的质量,这使得推理者难以选择规则。 图1显示了这种差异。 根据预测目标实体的准确性对规则进行排序。 WN18RR的最高规则比FB15K-237的最高价值。
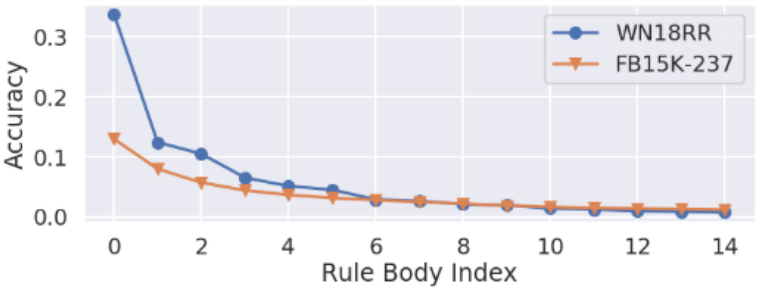
图1:数据集之间的规则质量差异。 WN18RR存在高质量的规则。
-
基于步行的方法
给定查询![]() ,基于步行的方法训练RL代理以查找从
,基于步行的方法训练RL代理以查找从![]() 到期望的对象实体
到期望的对象实体![]() 的路径,该路径暗含查询关系
的路径,该路径暗含查询关系![]() 。 在步骤t,当前状态由元组
。 在步骤t,当前状态由元组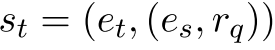 表示,其中
表示,其中![]() 是当前实体。然后,代理对下一个关系实体对进行采样,以从可能的动作
是当前实体。然后,代理对下一个关系实体对进行采样,以从可能的动作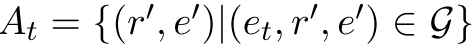 中访问。 代理到达
中访问。 代理到达![]() 时会收到奖励。
时会收到奖励。
提出的方法:RuleGuider
RuleGuider由一个基于符号的方法(称为规则挖掘器)和一个基于步行的方法(称为代理)组成。
规则挖掘者首先挖掘逻辑规则,然后代理遍历KG,以在规则的指导下(通过奖励)学习推理路径的概率分布。
当代理遍历关系和实体时,我们建议将代理分为两个子代理:关系和实体代理。 分离之后,搜索空间将被大幅修剪。 图2详细显示了这两种代理的结构。
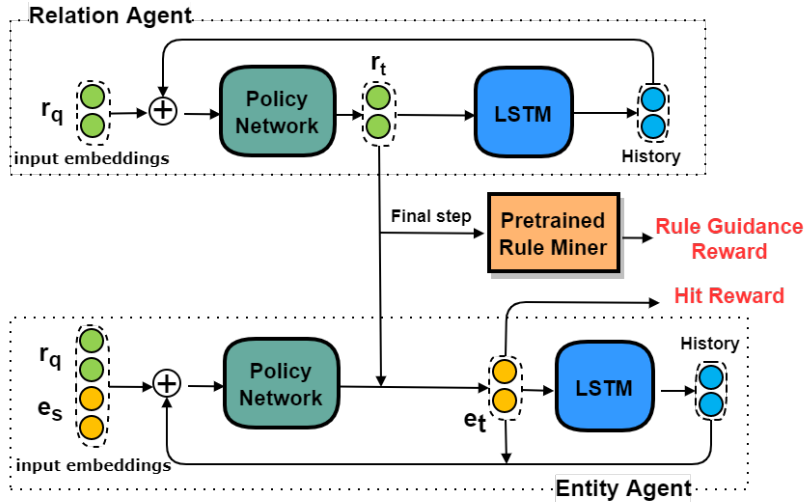
图2:两个代理的体系结构。 关系和实体代理相互交互以生成路径。 在每个步骤,实体代理首先从有效实体中选择一个实体。 然后,关系代理根据所选实体对关系进行抽样。 在最后一步,他们将根据最后选择的实体获得点击奖励,并根据选择的路径从预先挖掘的规则集中获得规则指导奖励。
-
模型架构
Relation Agent
在步骤![]() 是跃点数),关系代理选择入射到当前实体et-1的单个关系rt,其中e0 = es。 给定一个查询
是跃点数),关系代理选择入射到当前实体et-1的单个关系rt,其中e0 = es。 给定一个查询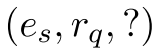 和一组规则R,可以将该过程表示为
和一组规则R,可以将该过程表示为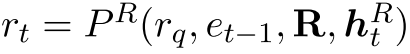 其中
其中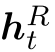 是关系历史记录。 代理首先过滤出与rq头不同的规则,然后从其余规则主体的第t个原子(即规则模式中的bt(··))中选择rt。由于规则挖掘者提供了规则的置信度分数,因此我们首先使用RL技术使用分数对该代理进行预训练。 在训练期间,代理会应用预训练的策略(分布),并通过利用嵌入提供的语义信息来不断调整分布。 换句话说,关系代理既可以利用预先制定的规则的置信度得分,也可以嵌入有形的点击奖励。
是关系历史记录。 代理首先过滤出与rq头不同的规则,然后从其余规则主体的第t个原子(即规则模式中的bt(··))中选择rt。由于规则挖掘者提供了规则的置信度分数,因此我们首先使用RL技术使用分数对该代理进行预训练。 在训练期间,代理会应用预训练的策略(分布),并通过利用嵌入提供的语义信息来不断调整分布。 换句话说,关系代理既可以利用预先制定的规则的置信度得分,也可以嵌入有形的点击奖励。
Entity Agent
在步骤t,代理基于![]() ,
,![]() 和实体历史
和实体历史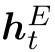 生成所有候选实体的分布。 给定当前关系rt,此过程可以正式表示为
生成所有候选实体的分布。 给定当前关系rt,此过程可以正式表示为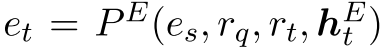 。 代理从所有发生在rt的实体中选择一个实体。 这样,实体和关联代理可以独立进行推理。在实验中,我们还尝试让实体代理根据关联代理修剪的实体空间生成分布。 以这种方式,实体代理接受选定的关系,并且可以利用来自该关系代理的信息。 但是,实体空间可能非常小,很难学习。 这会使实体代理的效率降低,尤其是在大而密集的KG上。
。 代理从所有发生在rt的实体中选择一个实体。 这样,实体和关联代理可以独立进行推理。在实验中,我们还尝试让实体代理根据关联代理修剪的实体空间生成分布。 以这种方式,实体代理接受选定的关系,并且可以利用来自该关系代理的信息。 但是,实体空间可能非常小,很难学习。 这会使实体代理的效率降低,尤其是在大而密集的KG上。
Policy Network
通过嵌入rq和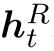 来参数化关联代理的搜索策略。 关系历史使用LSTM(Hochreiter和Schmidhuber,1997)进行编码:
来参数化关联代理的搜索策略。 关系历史使用LSTM(Hochreiter和Schmidhuber,1997)进行编码: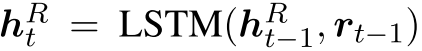 ,其中
,其中![]() 是最后一个关系的嵌入。 我们初始化
是最后一个关系的嵌入。 我们初始化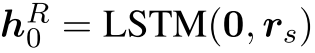 ,其中rs是一个特殊的开始关系嵌入,与源实体嵌入es形成一个初始的关系实体对。
,其中rs是一个特殊的开始关系嵌入,与源实体嵌入es形成一个初始的关系实体对。
关系空间嵌入![]() 由步骤t的关系空间Rt中所有关系的嵌入组成。 最后,关系代理输出概率分布
由步骤t的关系空间Rt中所有关系的嵌入组成。 最后,关系代理输出概率分布 并从中采样一个关系。
并从中采样一个关系。![]() 其中σ是softmax运算符,W1和W2是可训练的参数。 我们将关系代理的历史依赖策略设计为
其中σ是softmax运算符,W1和W2是可训练的参数。 我们将关系代理的历史依赖策略设计为 。
。
同样,实体代理的历史相关政策为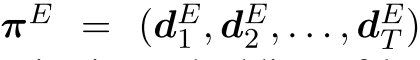 。 实体代理可以获取其上一步
。 实体代理可以获取其上一步![]() 的嵌入,实体空间嵌入Et,其历史
的嵌入,实体空间嵌入Et,其历史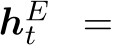
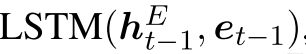 以及实体
以及实体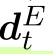 的概率分布。
的概率分布。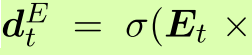
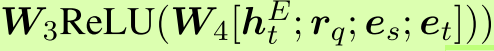 ,其中W3和W4是可训练的参数。 请注意,实体代理使用不同的LSTM编码实体历史。
,其中W3和W4是可训练的参数。 请注意,实体代理使用不同的LSTM编码实体历史。
-
Model Learning
我们通过让上述两个代理从特定实体开始并以固定的跳数遍历KG来训练模型。 agents在最后一步会收到奖励。
奖励设计
给定查询后,关系代理将首选将路径定向到正确的对象实体的路径。 因此,给定一个关系路径,我们根据从规则挖掘者获取的信任度给予奖励,称为规则指导奖励Rr。 我们还将Laplace平滑pc = 5添加到最终Rr的置信度分数中。 除Rr之外,代理还将获得一次命中奖励Rh,如果预测的三元组为![]()
![]() ,则为1。否则,我们使用
,则为1。否则,我们使用![]() 的嵌入 像Lin等人那样衡量报酬。 (2018)。
的嵌入 像Lin等人那样衡量报酬。 (2018)。![]()
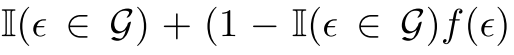 其中
其中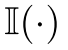 是一个指标函数,
是一个指标函数,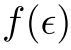 是一个使用嵌入进行奖励整形的合成函数。
是一个使用嵌入进行奖励整形的合成函数。
培训程序
我们分四个阶段训练模型。
1)使用基于嵌入的方法训练关系和实体嵌入。
2)应用规则挖掘器来检索规则及其相关的置信度分数。
3)通过冻结实体代理并要求关联代理采样路径来对关联代理进行预训练。 我们仅使用规则挖掘器评估路径并根据预先确定的置信度得分计算Rr。
4)联合训练关系和实体代理,以利用嵌入来计算Rh。 最终奖励R包含常数因子λ的Rr和![]() 。 使用REINFORCE(Williams,1992)算法训练了两个代理的策略网络,以最大化R。
。 使用REINFORCE(Williams,1992)算法训练了两个代理的策略网络,以最大化R。
实验
-
实验装置
Datasets
(1) FB15k-237 (Toutanova et al., 2015)
(2) WN18RR (Dettmers et al., 2018)
(3) NELL-995 (Xiong et al., 2017)
Hyperparameters
-
结果
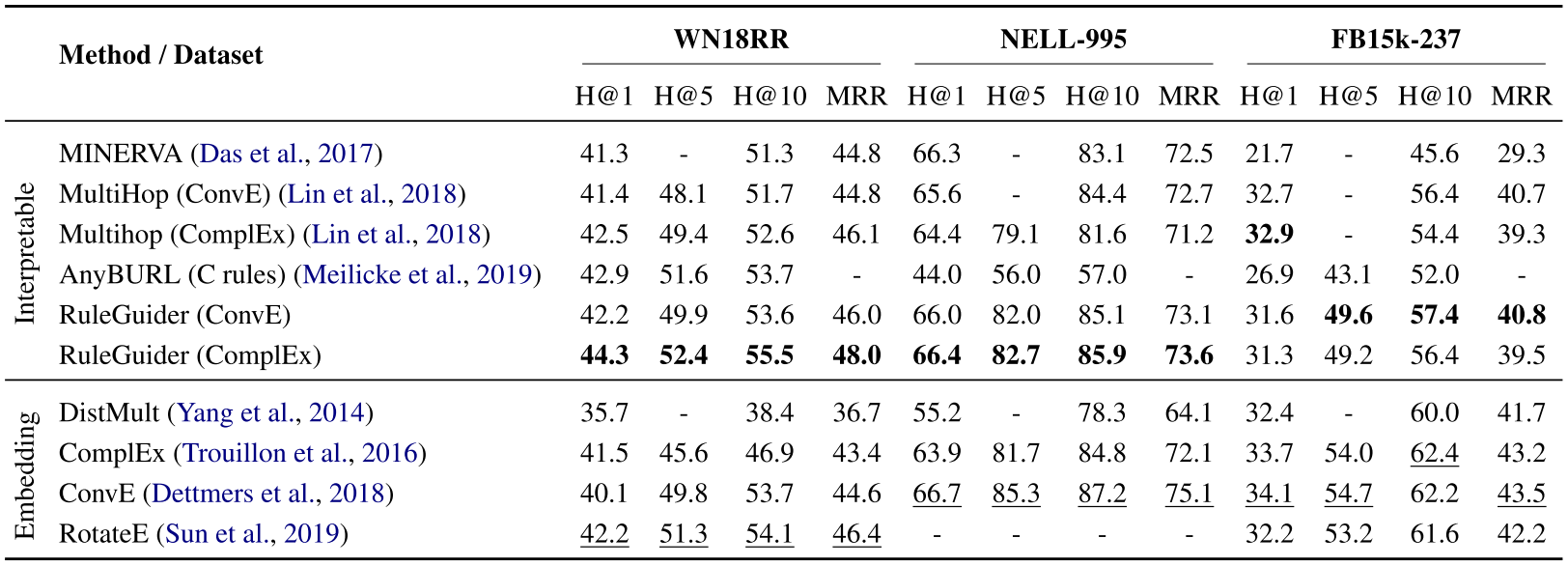
表1:与基于步行的方法的性能比较。 可解释方法和基于嵌入的方法中的最佳分数分别为粗体和下划线。 此外,我们还提供了基于嵌入式技术的最新方法的报告分数作为参考。 我们强调了该类别中表现最好的产品。
基于嵌入的方法不受图形中严格遍历的影响,有时由于图形的不完整性而受益于此属性。 通过利用规则,我们还结合了一些全局信息作为指导,以弥补离散推理过程中潜在的搜索空间损失。

表2:在对预训练和训练阶段结束时设定的开发进行推断的过程中,RuleGuider(ComplEx)用于预测![]() (波束0)的规则百分比。
(波束0)的规则百分比。
它表明我们的模型放弃了一些规则来进一步提高训练阶段的命中表现。
-
消融研究
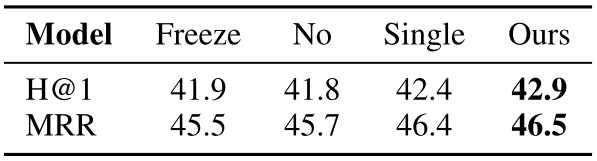
表3:Freeze, No and Single代表具有冻结的预训练关联试剂,没有预训练且没有分离试剂的模型。
冻结性能较差的经过预训练的代理程序,表明需要击中奖励。 消除性能较差的预训练表明,基于步行的座席将从逻辑规则中受益。 性能较差的单个代理变量显示了修剪操作空间的有效性。
-
人工评估
除评估指标外,我们还分析导致正确预测实体的推理路径是否合理。我们在Amazon Mechanical Turk上进行人工评估。我们使用FB15k-237上的均匀分布从开发集中随机抽取了300个三元组的评估集。在评估过程中,给定地面实况三元组,要求三名法官在以下两者之间选择一条更好的解释/分解路径:1.通过我们的方法生成的路径。 2.通过Multihop方法生成的路径。 3.开奖或没有一个是合理的。请注意,有2.6%的预测路径相同,因此将它们从评估集中排除。对于每个三元组,我们将多数票作为评估结果。由于三名法官可能各自选择不同的选项,因此每个选项都有一票表决权。在这种情况下,我们不将其计入最终评估结果中(表4)。出乎意料的是,没有三人在“铁”上获得超过一票。与具有ComplEx奖励整形的Multihop相比,RuleGuider具有更好的性能,并且推理路径对人类法官更有意义。
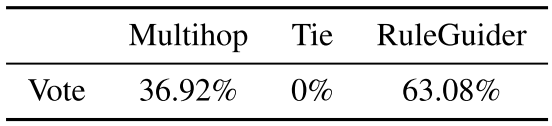
表4:Multihop(Lin等人,2018)和ruleGuider之间的人为评估投票,以正确预测FB15K-237开发集上的路径。 两种模型都使用ComplEx奖励整形。
结论
在未来的工作中,我们想研究如何将非循环规则引入基于步行的系统。
最后
以上就是哭泣小白菜最近收集整理的关于Learning Collaborative Agents with Rule Guidance for Knowledge Graph Reasoning-学习笔记问题和初步提出的方法:RuleGuider实验结论的全部内容,更多相关Learning内容请搜索靠谱客的其他文章。








发表评论 取消回复