我是
靠谱客的博主
无聊飞机,这篇文章主要介绍
如何看懂一个深度学习的项目代码,现在分享给大家,希望可以做个参考。
搞深度学习的人,两大必备日常除了读论文之外就是读代码。
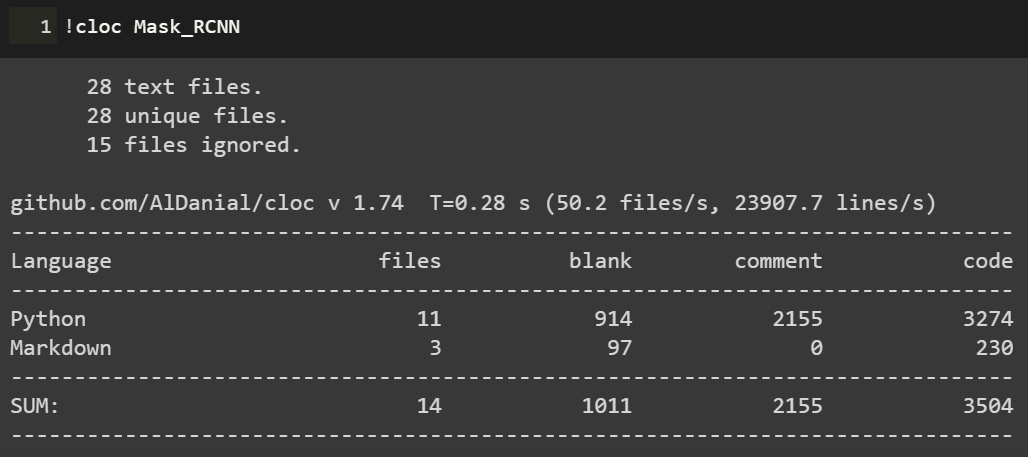
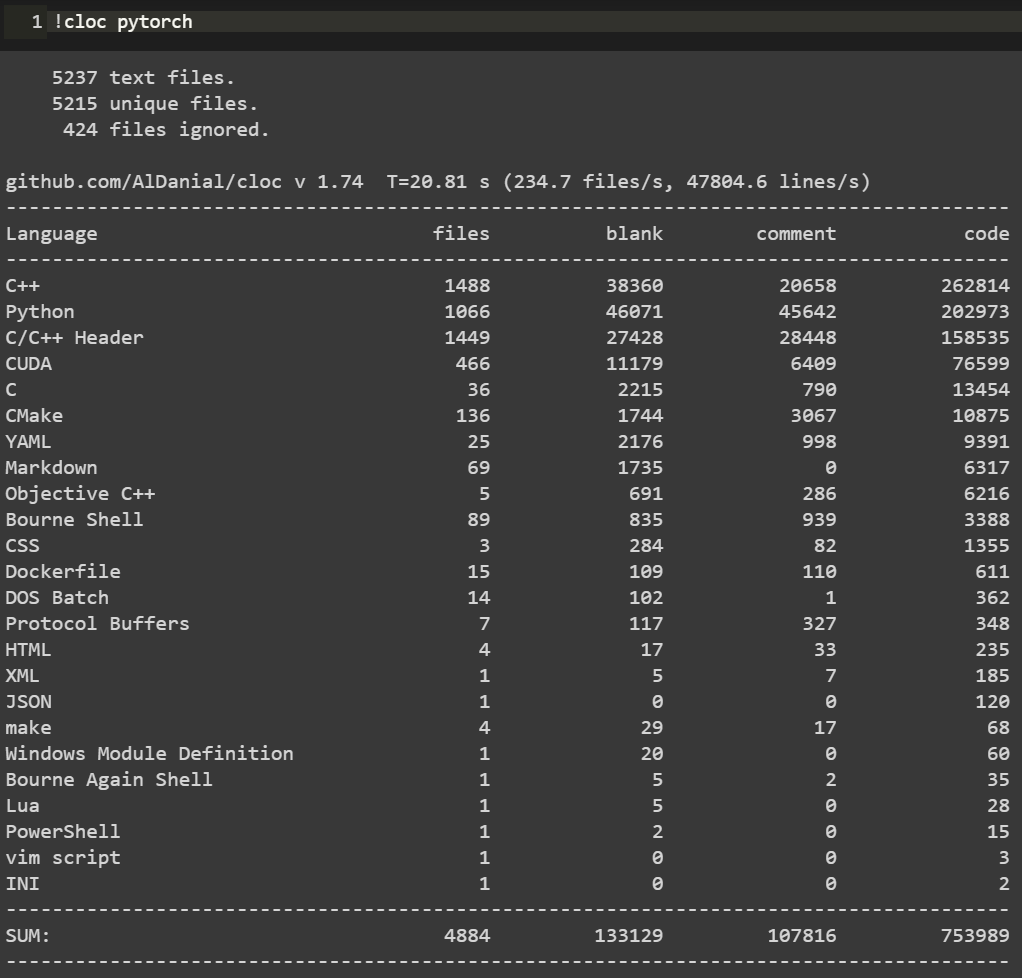
深度学习项目代码,小到几百行的测试demo,大到成千万行的开源项目,读起来方法肯定各有不同。 如下图Mask R-CNN项目代码和PyTorch源码的对比:
可以看到,Mask R-CNN作为一个经典的实例分割框架,其代码量可以说是中规中矩,3k的代码量在我们读完论文后集中花几天时间差不多可以过一遍。 但PyTorch的源码对大多数人而言就不那么友善了,750k的代码量,而且底层的C++代码占到整个项目中的一半之多,作为深度学习研究而言,堪称巨无霸级别了。 这样的代码量,就像初学者拿到一本PRML,往往投入巨大精力后不了了之。 所以,对于这两种类型的项目代码,阅读方法肯定会有所区别。
因为我们读代码的目的、场景和对象不尽相同,下面笔者从三个方面来和大家探讨如何阅读一份深度学习项目代码。
首先读代码的一些通用方法。 这一点而言不局限于深度学习项目代码,任何项目、任何语言的代码阅读都适用。 我们日常读代码无非是两个工具,一是将代码下载到本地,打开IDE,在IDE里安静的阅读:
第二个就是直接在GitHub的web端直接阅读,但GitHub没有像编辑器那样在左侧设置阅读目录,每次进入一个代码文件就必须退出来才能进入另一个文件,用户体验极差。 当然了,这都不是事。 chrome给我们提供了Octotree这样的辅助阅读插件,可以参考
github工具:Octotree安装和使用教程。
安装后我们就可以直接在web端就有IDE读代码的体验:
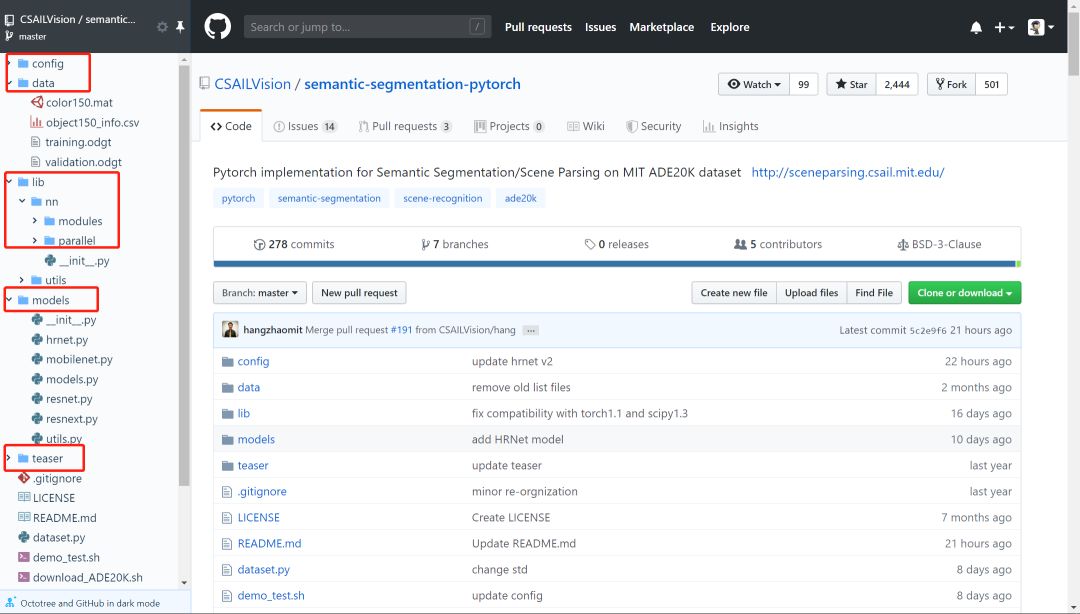
可以看到在页面左侧有一个类似IDE的目录栏,大大方便了我们查看和阅读项目代码。 这是通用方法中的工具层面,我们再来看一些基本的阅读规矩。 有了IDE和Octotree工具,我们第一点一定是仔细看代码目录,对整个项目代码结构和分布有一个整体的认识,对于深度学习而言通常目录中各个模块相对比较固定,比如是models目录下放着模型搭建和训练的代码,conifg目录下放着模型的一些配置文件,data目录下放着项目所使用的数据信息等等。 如下面语义分割项目的目录结构:
对深度学习项目代码的结构熟络之后,读的多了自然就会轻车熟路起来,后面阅读效率也就提高了。
通用方法的第二个是快速找到readme文档。 通常来说,根目录下的readme文档包含了这份代码的使用方法,里面有可以让你快速了解这个项目的关键信息。 一般来说,开源项目的readme里作者都会写明如何使用代码和进行部署。 下图是DenseNet的readme文档:
对于大型项目,可能每一个子目录下都有readme文档,这都是我们需要仔细阅读的部分,作者把关键信息都放里面了。 所以不管这样,第一时间读找到readme进行阅读是你了解该项目的必备步骤和通用方法。
第三个通用方法就是具体如何读的问题。
就是我们得确定一个阅读主线。
这一点是针对于深度学习项目代码的通用方法,对于一个深度学习项目,我们一般想要了解的最关键点无非就是数据、模型和如何训练等几个方面。
如果你想快速看看这个开源项目的测试效果,直接读readme看使用方法即可。
如果这个项目作者提出了一个新的模型框架,比如说bert,你想了解它的模型框架细节,直接定位到models目录下的带有model字眼的.py文件开始读。
或者是你想看这个项目是如何训练的,都用了哪些训练的tricks,它的参数初始化是如何做的,batchsize用的多大,训练过程中学习率如何调整的等等,那么话不多说,直接定位到带train的.py文件即可。
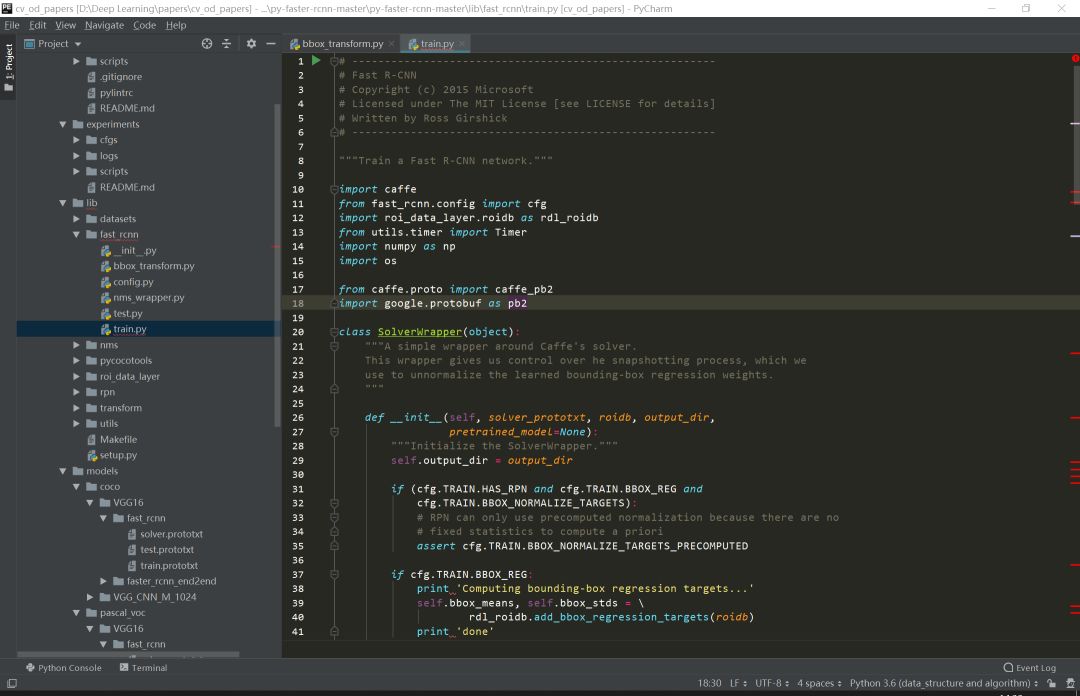
如下图faster-rcnn的3个训练文件。
根据目的不管是model还是train的主线,在阅读过程中一定会涉及到其他分支,比如说数据和配置等其他分支线。 在主线阅读过程中不断完善对分支的理解,久而久之,一个完整的项目就会被你消化了。
以上说的是深度学习项目代码阅读的一些通用方法。 下面再具体讲两个场景的代码阅读。 毕竟大家做事讲究目的性,往往带有较强的目的性去做某事效率一般会特别高。
第一个场景是在大家做研究做项目时遇到问题时。
不知道这个问题如何解决,直接谷歌又找不到好合适的方法的时候。
这时候我们可能会寄希望于在GitHub上搜罗一番。
比如说我们想要知道对于极度数据不平衡时如何给损失函数加权重的方法,再比如对于多标签问题进行模型预测时如何找到最佳分类阈值等等。
这些问题都是我们在做实际项目时都可能会碰上的,在这种情况下若是能在GitHub上找到类似场景的处理方法,相信你会瞬间来了精神。
下述基于keras的CNN多标签分类项目对于多标签分类阈值寻优使用了matthews_corrcoef来确定最佳分类预测阈值。 至于什么是matthews_corrcoef,这些都是你在解决问题过程中需要学习和吸收的地方。 总之,带有目的性的读某个项目的代码往往是只读某个block甚至是某几个关键行,数量不在多,在于能够解决你的问题。
第二个场景就是为了自我个人精进的读代码。
所谓个人精进,就是有大量可支配的个人学习和研究时间,高度的自律性和超强的学习力是人进行能力跃迁的关键所在。
笔者虽然平时偶尔会有去GitHub读一些代码,但说要达到个人精进的level,还远远不够。
比如说前面的PyTorch 750k的源码,这么大的代码量,阅读策略一定是分治思想,分散包围和各个击破。
把项目进行分解,设定阅读计划和目标,在超强的执行力下还是有可能完成的。
这不是普通人干的事,但我相信能在深度学习领域精进的人都不会是普通人。
当然了,我个人的补充是:先看readme文档,先运行成功再说,否则空谈。
遇见bug怎么办?
- 第一类bug,环境不兼容导致的bug,严格按照作者提供的运行环境,并对照环境的版本信息,对齐本地环境和作者要求的环境。
- 第二类bug,深度学习框架带来的bug,这部分bug可以在bing上进行搜索,查看解决方案。
- 第三类bug,项目本身相关的bug,这类bug最好是在github的issue区域进行查找,如果无法解决可以在issue部分详细描述自己的问题,等待项目库作者的解答。
运行顺利的话,代表可以进行debug操作,对文件某些细节不确定的话,可以通过debug的方式查看变量详细内容。
用IDE打开项目:
笔者是vscode党,推荐使用vscode+scp+mobaxterm+远程服务器的方式进行运行。
打开项目以后,从运行入口开始阅读:
阅读入口文件的逻辑,查看调用到了哪些包。
通过IDE的功能跳转到对应类或者函数进行继续阅读,配合代码注释进行分析。
分析过程可能会需要软件工程的知识,比如画一个类图来表述项目的关系。
一开始可以泛读,大概了解整体流程,做一些代码注释。而后可以精读,找到文章的核心,反复理解核心实现,抽丝剥茧,一定可以对这个项目有进一步的理解。
话说回来:深度学习的代码结构是没有一个统一标准的。一方面,代码结构取决于开发者自身的编程观念和水平,有人会一路长函数写到底,有人会利用面向对象进行封装和复用。另一方面,不同规模的项目,本身需要的结构也是很不一样的。Prototype代码讲究简洁易懂,而平台级别的库讲究模块化和可维护性,这也是为什么大家看懂了MNIST上的代码,却经常看不懂开源库的原因。
训练和测试代码一般写在主程序里,也有的会封装成叫train或者test/inference之类的函数。模型定义部分一般是一个独立文件,叫model.py。数据集读取和预处理代码一般在data.py或者utils.py之类的文件里。
参考:
https://www.cnblogs.com/pprp/p/14819944.html
https://www.zhihu.com/question/406133826/answer/1925821995
最后
以上就是无聊飞机最近收集整理的关于如何看懂一个深度学习的项目代码的全部内容,更多相关如何看懂一个深度学习内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。









发表评论 取消回复