文章目录
- 架构设计
- 原理
- table与schema
- Kudu存储模型
- RowSet组成:
- tablet发现过程
架构设计
kudu是典型的主从架构,主Master:管理集群,管理元数据
从:table server 负责最终数据存储对外提供数据读写能力,里面存储的是一个个tablet
master:特殊的CataLog Table ,只有一个tablet,且在内存中有完整的缓存,缓存catalog table数据主要是为了提高性能,因为客户端需要通过它定位数据位置
1.master不需要较大存储,不需要很好的硬件
2.master配置多台,最低三台(三副本策略)
其中table server 相当于HDFS中 dataNode与hbase的 region server合体,需要负责执行所有与数据相关的操作,存储,访问,编码,压缩,compaction和复制,与master相比它工作繁重,支持水平扩展
| 选项 | 最佳性能(建议值) | 限制 |
|---|---|---|
| tablet server数 | 不超过100 | 300+ |
| tablet数/tablet server(含副本) | 1000+ | 4000+ |
| tablet数/表/tablet server(含副本) | 60+ | 60+ |
| 单台tablet server存储数据(含副本,压缩后) | 8TB+ | 10TB+ |
| 单tablet存储数据(超过会性能下降、合并失败、启动慢) | 10G | 50G |
- tablet server不能非常优雅的退役
- tablet server不能修改IP和端口
- tablet server强依赖NTP时间同步,如果时间不同步就会宕机(master亦是如此)
注意:随着版本升级和硬件的改善,上述限制会发生变化,请参阅对应版本的文档。
https://kudu.apache.org/releases/1.10.0/docs/known_issues.html
原理
table与schema
kudu设计是面向结构化存储,因此kudu需要用户在建表时定义它的schema信息,这些schema信息包含:列定义(含类型),Primary Key定义(用户指定的若干个列的有序组合)数据的唯一性,依赖于用户所提供的Primary Key中的Column组合的值的唯一性。Kudu提供了Alter命令来增删列,但位于Primary Key中的列是不允许删除的。
从用户角度来看,kudu是一种存储结构化数据表的存储系统,一个kudu集群中可以定义任意数量table,每个table都需要定义好schema,每个table的列数是确定的,每一列都需要名字和类型,表中可以把一列或者多列定义为主键,kudu更像关系型数据库,但是不支持二级索引
Kudu存储模型
Kudu的底层数据文件的存储,未采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统主要是
1.快速的列式查询
2.快速的随机更新
3.更为稳定的查询性能保障
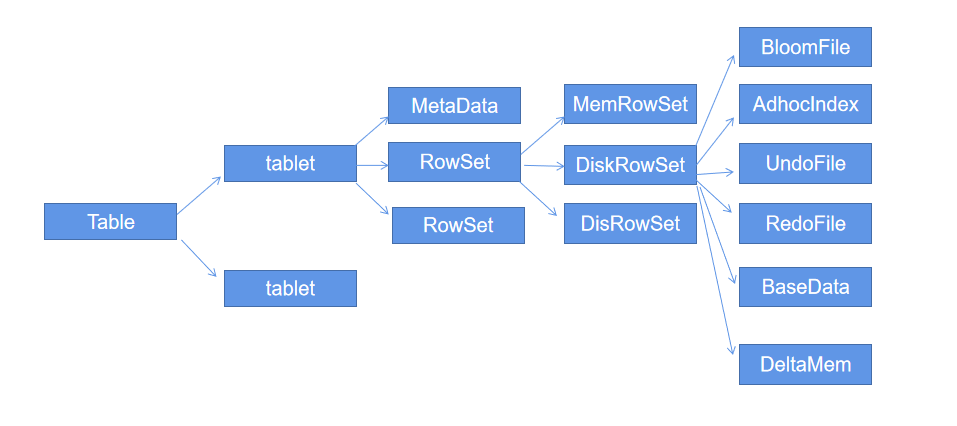
一张table会分成若干个tablet,每个tablet包括MetaData元信息及若干个RowSet。RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、AdhocIndex、BaseData、DeltaMem及若干个RedoFile和UndoFile( UndoFile一般情况下只有一个 )
RowSet组成:
MemRowSet
用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。默认是1G或者或者120S
DiskRowSet
用于老数据的变更,后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
BloomFile
根据一个DiskRowSet中的key生成一个bloom filter,用于快速模糊定位某个key是否在DiskRowSet中。
AdhocIndex
是主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置
BaseData
是MemRowSet flush下来的数据,按列存储,按主键有序。
UndoFile
是基于BaseData之前时间的历史数据,通过在BaseData上apply UndoFile中的记录,可以获得历史数据。
RedoFile
是基于BaseData之后时间的变更记录,通过在BaseData上apply RedoFile中的记录,可获得较新的数据。
DeltaMem
用于DiskRowSet中数据的变更,先写到内存中,写满后flush到磁盘形成
RedoFile
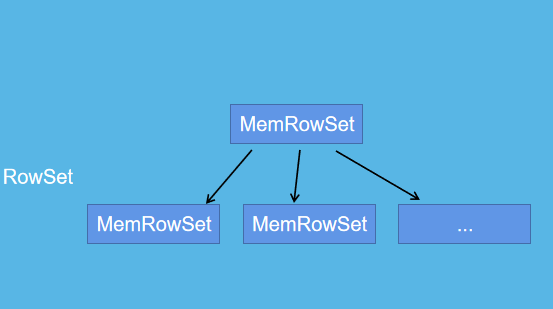
MemRowSets与DiskRowSets的区别:
Kudu
HBase
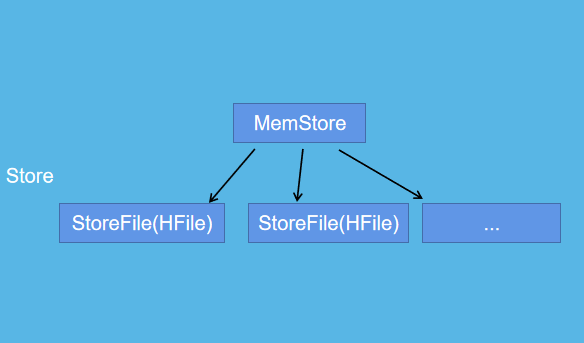
对比可知,MemRowSets中数据Flush磁盘后,形成DiskRowSets,DiskRowSets中数据32M大小为单位,按序划分一个个DiskRowSet,DiskRowSet中的数据按照Column进行组织,类比Parquet,这是Kudu可支持一些分析性查询的基础,每一个Column存储在一个相邻的数据区域,而这个数据区域进一步细分为一个个小Page单元,与hbase的File中Block类似,对于每个Column Page可以采用一些Encoding算法,以及通用的Compression算法.
对于数据的更新和删除,Kudu与hbase蕾西,通过增加一条新记录来描述数据更新和删除,虽然对于DiskRowSet不可修改,Kudu将DiskRowSet划分两个部分,BaseData,DeltaStores,BaseData负责存储基础数据,DeltaStore负责存储BaseData中变更数据
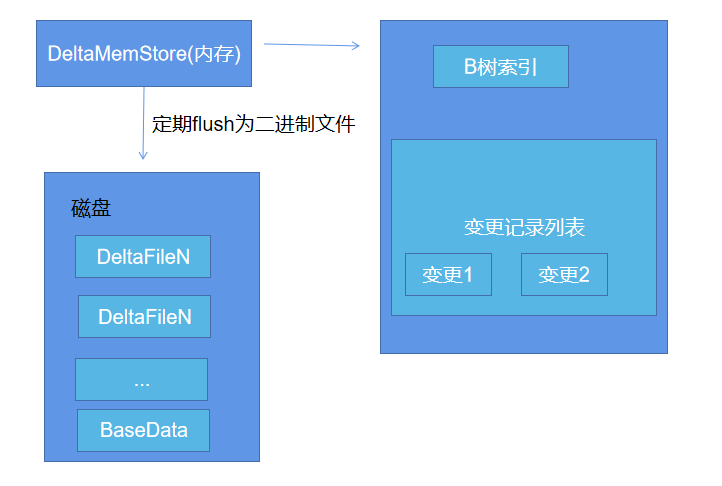
数据从 MemRowSet 刷到磁盘后就形成了一份 DiskRowSet(只包含 base data),每份DiskRowSet 在内存中都会有一个对应的 DeltaMemStore,负责记录此 DiskRowSet 后续的数据变更映射到每个 row_offset 对应的数据变更。
DeltaMemStore 数据增长到一定程度后转化成二进制文件存储到磁盘,形成一个 DeltaFile,随着base data 对应数据的不断变更,DeltaFile 逐渐增长。下图是DeltaFile生成过程的示意图(更新、删除)。DeltaMemStore 内部维护一个 B-树索引
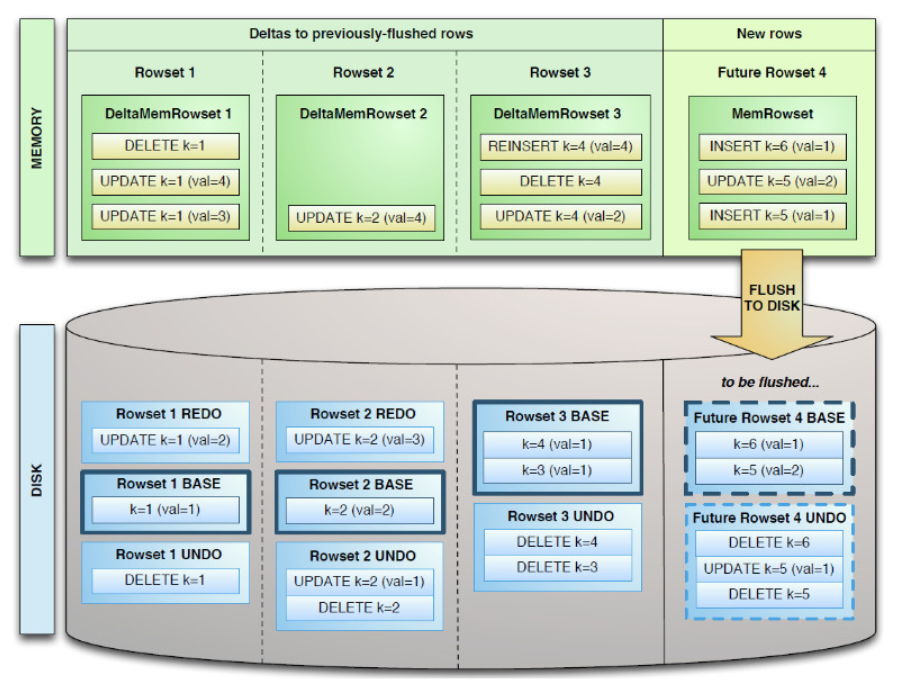
Delta数据部分包含REDO与UNDO两部分:这里的REDO与UNDO与关系型数据库中的REDO与UNDO日志类似(在关系型数据库中,REDO日志记录了更新后的数据,可以用来恢复尚未写入DataFile的已成功事务更新的数据。而UNDO日志用来记录事务更新之前的数据,可以用来在事务失败时进行回滚),但也存在一些细节上的差异:
- REDO Delta Files包含了Base Data自上一次被Flush/Compaction之后的变更值。REDO Delta Files按照Timestamp顺序排列。
- UNDO Delta Files包含了Base Data自上一次Flush/Compaction之前的变更值。这样才可以保障基于一个旧Timestamp的查询能够看到一个一致性视图。UNDO按照Timestamp倒序排列。
tablet发现过程
Kudu客户端无论在执行写入还是读操作,先从master获取tablet位置信息,这个过程为tablet发现
当创建Kudu客户端时,其会从主服务器上获取tablet位置信息,然后直接与服务于该tablet的服务器进行交谈,为了优化读取和写入路径,客户顿将保留该信息的本地缓存,防止每一个请求都要查询tablet位置信息,随着时间推移,并且当写入被发送不再是tablet的leader服务器时,被拒绝,然后客户顿通过查询主服务器发现新领导者位置来更新缓存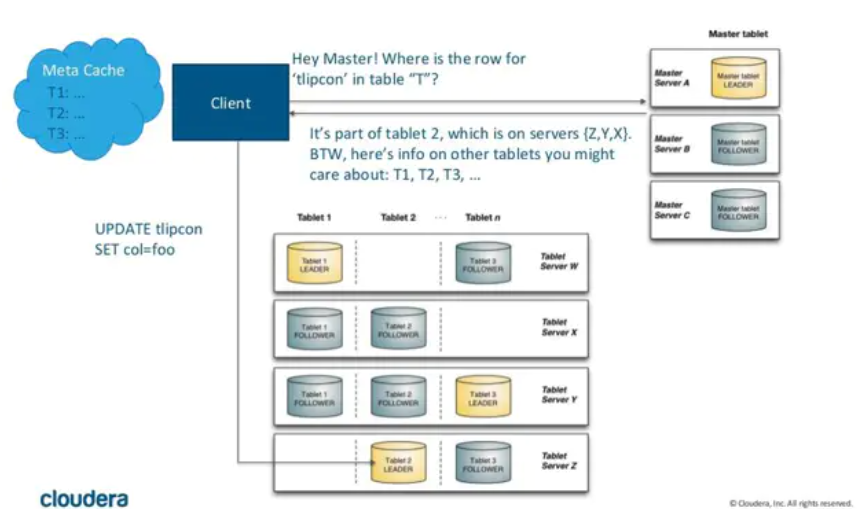
最后
以上就是快乐钥匙最近收集整理的关于KUDU(二)kudu架构设计的全部内容,更多相关KUDU(二)kudu架构设计内容请搜索靠谱客的其他文章。








发表评论 取消回复