
1. Durid概述
Apache Druid是一个集时间序列数据库、数据仓库和全文检索系统特点于一体的分析性数据平台。本文将带你简单了解Druid的特性,使用场景,技术特点和架构。这将有助于你选型数据存储方案,深入了解Druid存储,深入了解时间序列存储等。
Apache Druid是一个高性能的实时分析型数据库。
1.1 为什么使用
1.1.1 云原生数据库
一个现代化的云原生,流原生,分析型数据库
Druid是为快速查询和快速摄入数据的工作流而设计的。Druid强在有强大的UI,运行时可操作查询,和高性能并发处理。Druid可以被视为一个满足多样化用户场景的数据仓库的开源替代品。
1.1.2 轻松集成
轻松与现有的数据管道集成
Druid可以从消息总线流式获取数据(如Kafka,Amazon Kinesis),或从数据湖批量加载文件(如HDFS,Amazon S3和其他同类数据源)。
1.1.3 超高性能
比传统方案快100倍的性能
Druid对数据摄入和数据查询的基准性能测试大大超过了传统解决方案。
Druid的架构融合了数据仓库,时间序列数据库和检索系统最好的特性。
1.1.4 工作流
解锁新的工作流
Druid为Clickstream,APM(应用性能管理系统),supply chain(供应链),网络遥测,数字营销和其他事件驱动形式的场景解锁了新的查询方式和工作流。Druid专为实时和历史数据的快速临时查询而构建。
1.1.5 多种部署方式
可以部署在AWS/GCP/Azure,混合云,k8s和租用服务器上
Druid可以部署在任Linux环境中,无论是内部环境还是云环境。部署Druid是非常easy的:通过添加或删减服务来扩容缩容。
1.2 使用场景
Apache Druid适用于对实时数据提取,高性能查询和高可用要求较高的场景。因此,Druid通常被作为一个具有丰富GUI的分析系统,或者作为一个需要快速聚合的高并发API的后台。Druid更适合面向事件数据。
1.2.1 常见的使用场景
比较常见的使用场景
1.2.1.1 用户活动和行为
Druid经常用在点击流,访问流,和活动流数据上。具体场景包括:衡量用户参与度,为产品发布追踪A/B测试数据,并了解用户使用方式。Druid可以做到精确和近似计算用户指标,例如不重复计数指标。这意味着,如日活用户指标可以在一秒钟计算出近似值(平均精度98%),以查看总体趋势,或精确计算以展示给利益相关者。Druid可以用来做“漏斗分析”,去测量有多少用户做了某种操作,而没有做另一个操作。这对产品追踪用户注册十分有用。
1.2.1.2 网络流
Druid常常用来收集和分析网络流数据。Druid被用于管理以任意属性切分组合的流数据。Druid能够提取大量网络流记录,并且能够在查询时快速对数十个属性组合和排序,这有助于网络流分析。这些属性包括一些核心属性,如IP和端口号,也包括一些额外添加的强化属性,如地理位置,服务,应用,设备和ASN。Druid能够处理非固定模式,这意味着你可以添加任何你想要的属性。
1.2.1.3 数字营销
Druid常常用来存储和查询在线广告数据。这些数据通常来自广告服务商,它对衡量和理解广告活动效果,点击穿透率,转换率(消耗率)等指标至关重要。
Druid最初就是被设计成一个面向广告数据的强大的面向用户的分析型应用程序。在存储广告数据方面,Druid已经有大量生产实践,全世界有大量用户在上千台服务器上存储了PB级数据。
1.2.1.4 应用性能管理
Druid常常用于追踪应用程序生成的可运营数据。和用户活动使用场景类似,这些数据可以是关于用户怎样和应用程序交互的,它可以是应用程序自身上报的指标数据。Druid可用于下钻发现应用程序不同组件的性能如何,定位瓶颈,和发现问题。
不像许多传统解决方案,Druid具有更小存储容量,更小复杂度,更大数据吞吐的特点。它可以快速分析数以千计属性的应用事件,并计算复杂的加载,性能,利用率指标。比如,基于百分之95查询延迟的API终端。我们可以以任何临时属性组织和切分数据,如以天为时间切分数据,如以用户画像统计,如按数据中心位置统计。
1.2.1.5 物联网和设备指标
Driud可以作为时间序列数据库解决方案,来存储处理服务器和设备的指标数据。收集机器生成的实时数据,执行快速临时的分析,去估量性能,优化硬件资源,和定位问题。
和许多传统时间序列数据库不同,Druid本质上是一个分析引擎,Druid融合了时间序列数据库,列式分析数据库,和检索系统的理念。它在单个系统中支持了基于时间分区,列式存储,和搜索索引。这意味着基于时间的查询,数字聚合,和检索过滤查询都会特别快。
你可以在你的指标中包括百万唯一维度值,并随意按任何维度组合group和filter(Druid 中的 dimension维度类似于时间序列数据库中的tag)。你可以基于tag group和rank,并计算大量复杂的指标。而且你在tag上检索和过滤会比传统时间序列数据库更快。
1.2.1.6 OLAP和商业智能
Druid经常用于商业智能场景。公司部署Druid去加速查询和增强应用。和基于Hadoop的SQL引擎(如Presto或Hive)不同,Druid为高并发和亚秒级查询而设计,通过UI强化交互式数据查询。这使得Druid更适合做真实的可视化交互分析。
1.2.2 适合的场景
如果您的使用场景符合以下的几个特征,那么Druid是一个非常不错的选择:
- 数据插入频率比较高,但较少更新数据
- 大多数查询场景为聚合查询和分组查询(GroupBy),同时还有一定得检索与扫描查询
- 将数据查询延迟目标定位100毫秒到几秒钟之间
- 数据具有时间属性(Druid针对时间做了优化和设计)
- 在多表场景下,每次查询仅命中一个大的分布式表,查询又可能命中多个较小的lookup表
- 场景中包含高基维度数据列(例如URL,用户ID等),并且需要对其进行快速计数和排序
- 需要从Kafka、HDFS、对象存储(如Amazon S3)中加载数据
1.2.3 不适合的场景
如果您的使用场景符合以下特征,那么使用Druid可能是一个不好的选择:
- 根据主键对现有数据进行低延迟更新操作。Druid支持流式插入,但不支持流式更新(更新操作是通过后台批处理作业完成)
- 延迟不重要的离线数据系统
- 场景中包括大连接(将一个大事实表连接到另一个大事实表),并且可以接受花费很长时间来完成这些查询
2. Durid是什么
Apache Druid 是一个开源的分布式数据存储引擎。
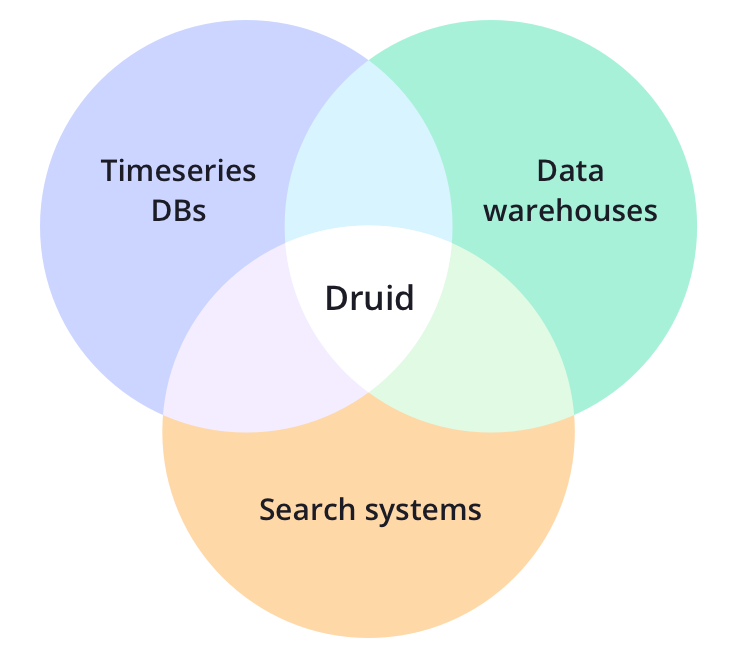
Druid的核心设计融合了OLAP/analytic databases,timeseries database,和search systems的理念,以创造一个适用广泛用例的统一系统。Druid将这三种系统的主要特性融合进Druid的ingestion layer(数据摄入层),storage format(存储格式化层),querying layer(查询层),和core architecture(核心架构)中。
2.1 主要特性
2.1.1 列式存储
Druid单独存储并压缩每一列数据。并且查询时只查询特定需要查询的数据,支持快速scan,ranking和groupBy。
2.2.2 原生检索索引
Druid为string值创建倒排索引以达到数据的快速搜索和过滤。
2.2.3 流式和批量数据摄入
开箱即用的Apache kafka,HDFS,AWS S3连接器connectors,流式处理器。
2.2.4 灵活的数据模式
Druid优雅地适应不断变化的数据模式和嵌套数据类型。
2.2.5 基于时间的优化分区
Druid基于时间对数据进行智能分区。因此,Druid基于时间的查询将明显快于传统数据库。
2.2.6 支持SQL语句
除了原生的基于JSON的查询外,Druid还支持基于HTTP和JDBC的SQL。
2.2.7 水平扩展能力
百万/秒的数据摄入速率,海量数据存储,亚秒级查询。
2.2.8 易于运维
可以通过添加或移除Server来扩容和缩容。Druid支持自动重平衡,失效转移。
2.3 技术选型
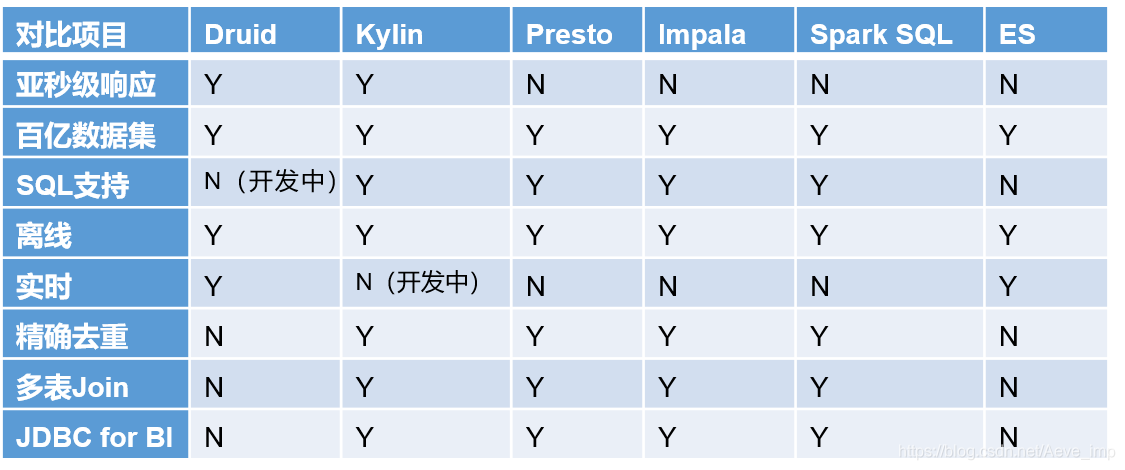
技术对比
Druid
是一个实时处理时序数据的OLAP数据库,它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
Kylin
核心是Cube,Cube是一种预计算技术,预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
Presto
它没有使用MapReduce,大部分场景下比Hive快一个数量级,其中的关键是所有的处理都在内存中完成。
Impala
基于内存运算,速度快,支持的数据源没有Presto多。
Spark SQL
基于Spark平台上的一个OLAP框架,基本思路是增加机器来并行计算,从而提高查询速度。
ES
最大的特点是使用了倒排索引解决索引问题。根据研究,ES在数据获取和聚集用的资源比在Druid高。
框架选型
- 从超大数据的查询效率来看: Druid > Kylin > Presto > Spark SQL
- 从支持的数据源种类来讲: Presto > Spark SQL > Kylin > Druid
2.4 数据摄入
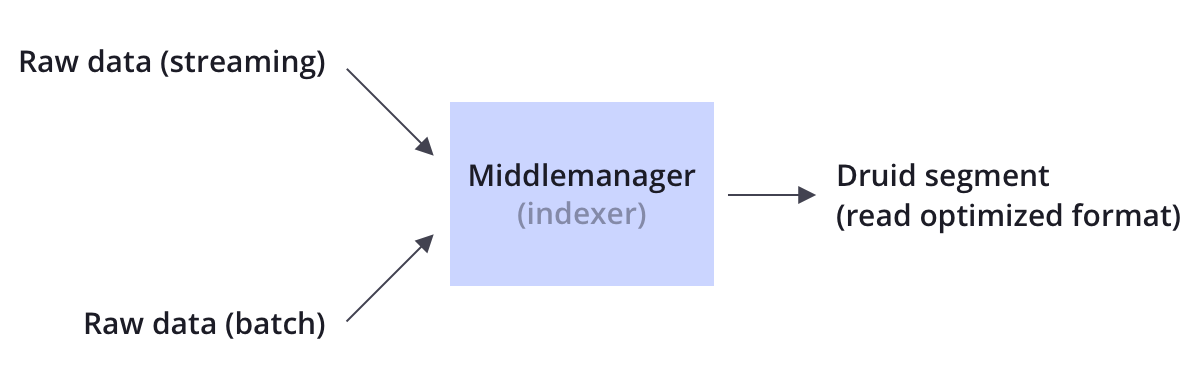
Druid同时支持流式和批量数据摄入。Druid通常通过像Kafka这样的消息总线(加载流式数据)或通过像HDFS这样的分布式文件系统(加载批量数据)来连接原始数据源。
Druid通过Indexing处理将原始数据以segment的方式存储在数据节点,segment是一种查询优化的数据结构。
2.5 数据存储
像大多数分析型数据库一样,Druid采用列式存储。根据不同列的数据类型(string,number等),Druid对其使用不同的压缩和编码方式。Druid也会针对不同的列类型构建不同类型的索引。
类似于检索系统,Druid为string列创建反向索引,以达到更快速的搜索和过滤。类似于时间序列数据库,Druid基于时间对数据进行智能分区,以达到更快的基于时间的查询。
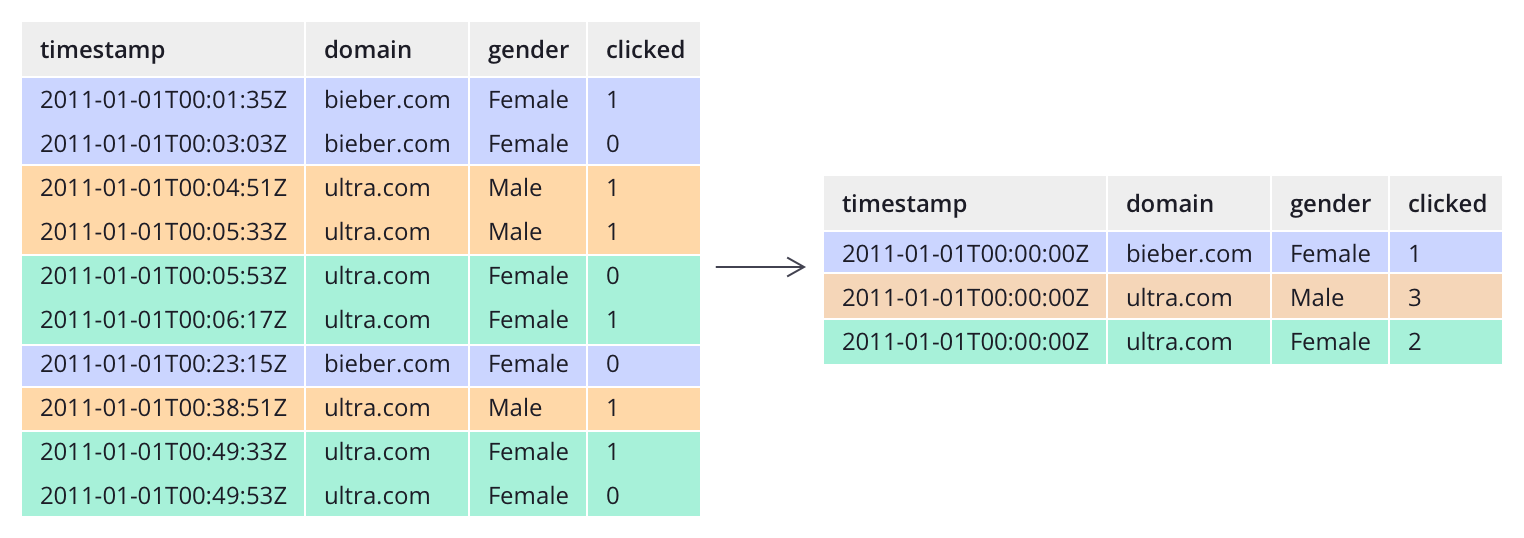
不像大多数传统系统,Druid可以在数据摄入前对数据进行预聚合。这种预聚合操作被称之为rollup,这样就可以显著的节省存储成本。
2.6 查询
Druid支持JSON-over-HTTP和SQL两种查询方式。除了标准的SQL操作外,Druid还支持大量的唯一性操作,利用Druid提供的算法套件可以快速的进行计数,排名和分位数计算。
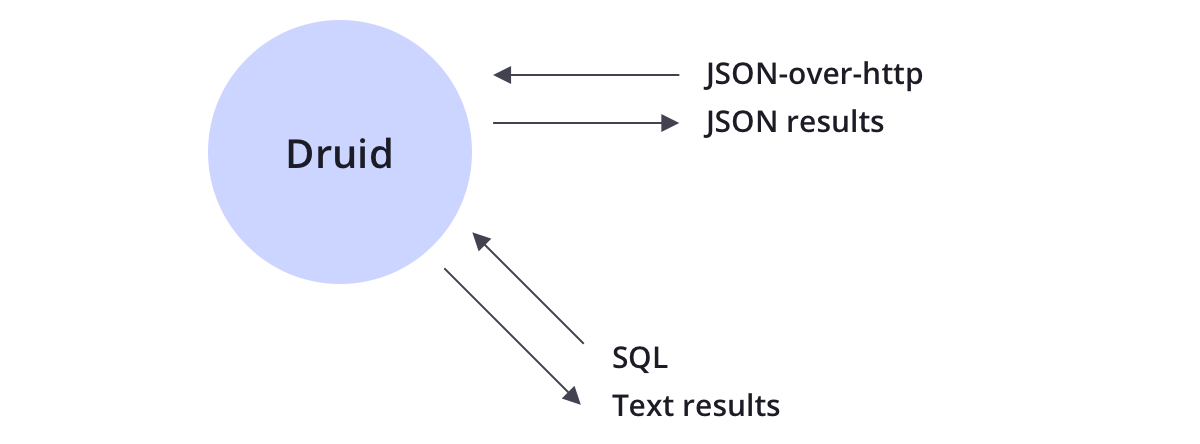
Drui被设计成一个健壮的系统,它需要7*24小时运行。
Druid拥有以下特性,以确保长期运行,并保证数据不丢失。
2.6.1 数据副本
Druid根据配置的副本数创建多个数据副本,所以单机失效不会影响Druid的查询。
2.6.2 独立服务
Druid清晰的命名每一个主服务,每一个服务都可以根据使用情况做相应的调整。服务可以独立失败而不影响其他服务的正常运行。例如,如果数据摄入服务失效了,将没有新的数据被加载进系统,但是已经存在的数据依然可以被查询。
2.6.3 自动数据备份
Druid自动备份所有已经indexed的数据到一个文件系统,它可以是分布式文件系统,如HDFS。你可以丢失所有Druid集群的数据,并快速从备份数据中重新加载。
2.6.4 滚动更新
通过滚动更新,你可以在不停机的情况下更新Druid集群,这样对用户就是无感知的。所有Druid版本都是向后兼容。
3. 安装部署
3.1 环境介绍
3.1.1 Durid端口列表
以下是Durid默认的端口列表,防止因为端口占用导致服务器启动失败
| 角色 | 端口 | 介绍 |
|---|---|---|
| Coordinator | 8081 | 管理集群上的数据可用性 |
| Historical | 8083 | 存储历史查询到的数据 |
| Broker | 8082 | 处理来自外部客户端的查询请求 |
| Realtime | 8084 | |
| Overlord | 8090 | 控制数据摄取工作负载的分配 |
| MiddleManager | 8091 | 负责摄取数据 |
| Router | 8888 | 可以将请求路由到Brokers, Coordinators, and Overlords |
3.2 安装方式
获取Druid安装包有以下几种方式
3.2.1 源代码编译
druid/release,主要用于定制化需求时,比如结合实际环境中的周边依赖,或者是加入支持特定查询的部分的优化等。
3.2.2 官网下载
官网安装包下载:download,包含Druid部署运行的最基本组件
3.2.3 Imply组合套件
Imply,该套件包含了稳定版本的Druid组件、实时数据写入支持服务、图形化展示查询Web UI和SQL查询支持组件等,目的是为更加方便、快速地部署搭建基于Druid的数据分析应用产品。
3.3 单机配置参考
3.3.1 Nano-Quickstart
1 CPU, 4GB 内存
- 启动命令:
bin/start-nano-quickstart - 配置目录:
conf/druid/single-server/nano-quickstart
3.3.2 微型快速入门
4 CPU, 16GB 内存
- 启动命令:
bin/start-micro-quickstart - 配置目录:
conf/druid/single-server/micro-quickstart
3.3.3 小型
8 CPU, 64GB 内存 (~i3.2xlarge)
- 启动命令:
bin/start-small - 配置目录:
conf/druid/single-server/small
3.3.4 中型
16 CPU, 128GB 内存 (~i3.4xlarge)
- 启动命令:
bin/start-medium - 配置目录:
conf/druid/single-server/medium
3.3.5 大型
32 CPU, 256GB 内存 (~i3.8xlarge)
- 启动命令:
bin/start-large - 配置目录:
conf/druid/single-server/large
3.3.6 超大型
64 CPU, 512GB 内存 (~i3.16xlarge)
- 启动命令:
bin/start-xlarge - 配置目录:
conf/druid/single-server/xlarge
3.4 单机版安装
3.4.1 软件要求
- Java 8 (8u92+)
- Linux, Mac OS X, 或者其他的类Unix OS (Windows是不支持的)
- 安装Docker环境
- 安装Docker-compose环境
3.4.2 硬件要求
Druid包括几个单服务配置示例,以及使用这些配置启动Druid进程的脚本。
如果您在笔记本电脑等小型机器上运行以进行快速评估,那么micro-quickstart配置是一个不错的选择,适用于 4CPU/16GB RAM环境。如果您计划在教程之外使用单机部署进行进一步评估,我们建议使用比micro-quickstart更大的配置。
虽然为大型单台计算机提供了示例配置,但在更高规模下,我们建议在集群部署中运行Druid,以实现容错和减少资源争用。
3.5 imply方式安装
安装推荐Imply方式,Imply方式出了提供druid组件,还有图形化、报表等功能
3.5.1 安装perl
因为启动druid 需要用到perl环境,需要安装下
yum install perl gcc kernel-devel3.5.2 关闭防火墙
#查看防火状态
systemctl status firewalld
#暂时关闭防火墙
systemctl stop firewalld
#永久关闭防火墙
systemctl disable firewalld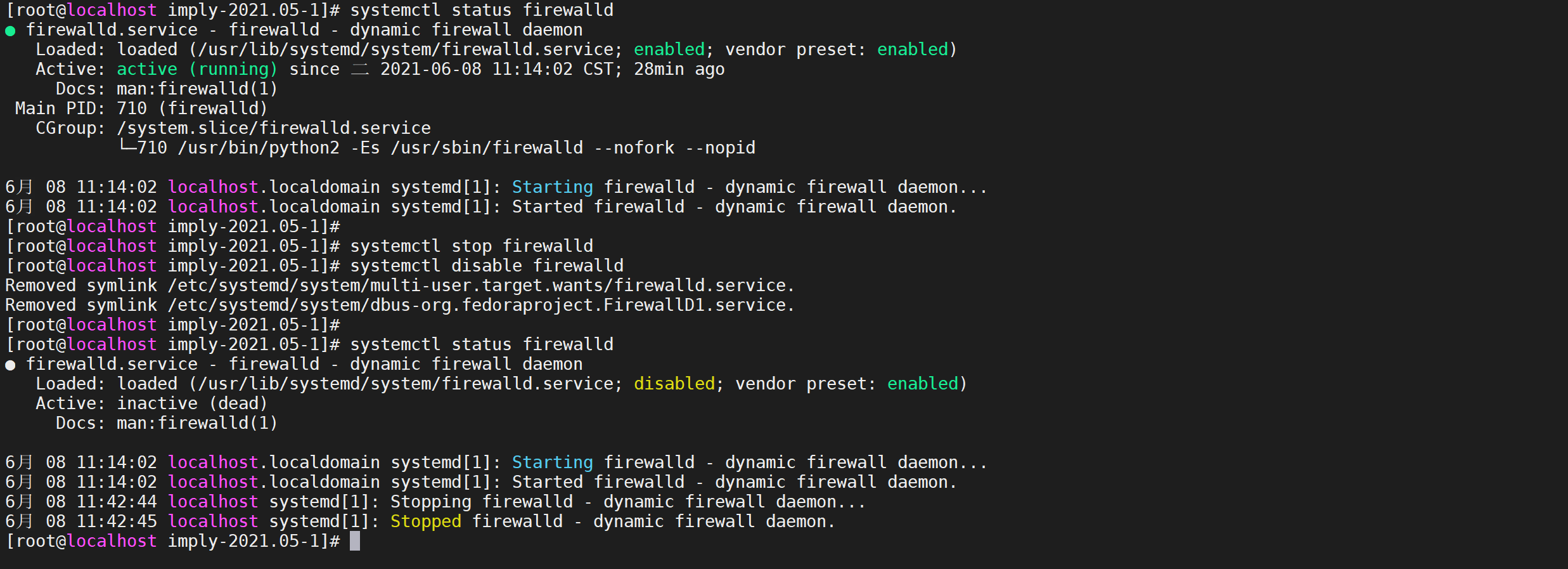
3.5.3 安装JDK
选择与自己系统相匹配的版本,我的是Centos7 64位的,所以如果是我的话我会选择此版本,要记住的你们下载的话选择的是以tar.gz结尾的。
3.5.3.1 下载JDK
到Oracle 官网下载jdk1.8,选择
jdk-8u301-linux-x64.tar.gz
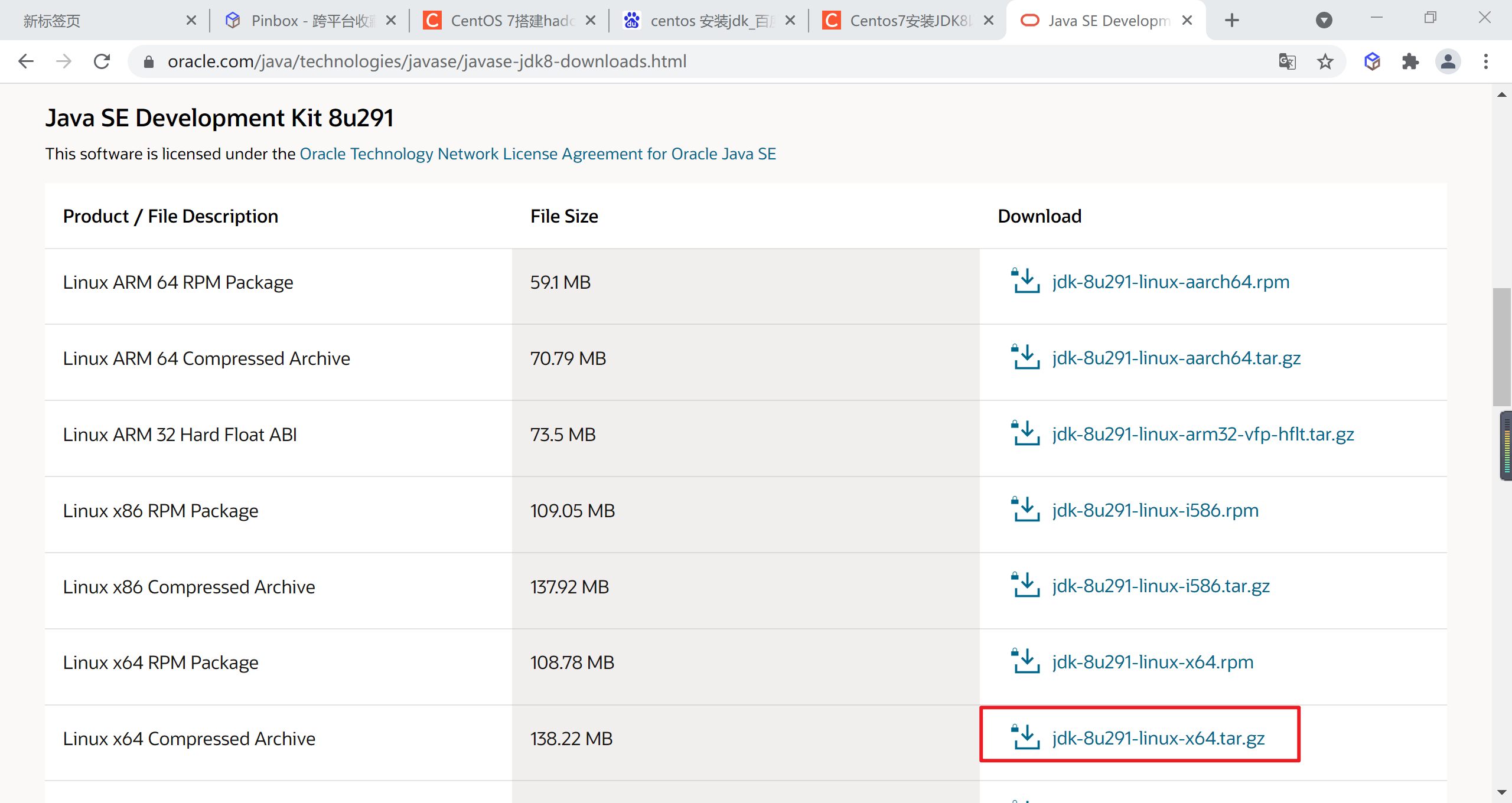
将文件下载到本地后上传到linux目录下
3.5.3.2 上传解压
上传文件
mkdir /usr/local/java解压目录
tar -zxvf jdk-8u301-linux-x64.tar.gz3.5.3.3 配置环境变量
配置环境变量,修改profile文件并加入如下内容
vi /etc/profileexport JAVA_HOME=/usr/local/java/jdk1.8.0_301
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin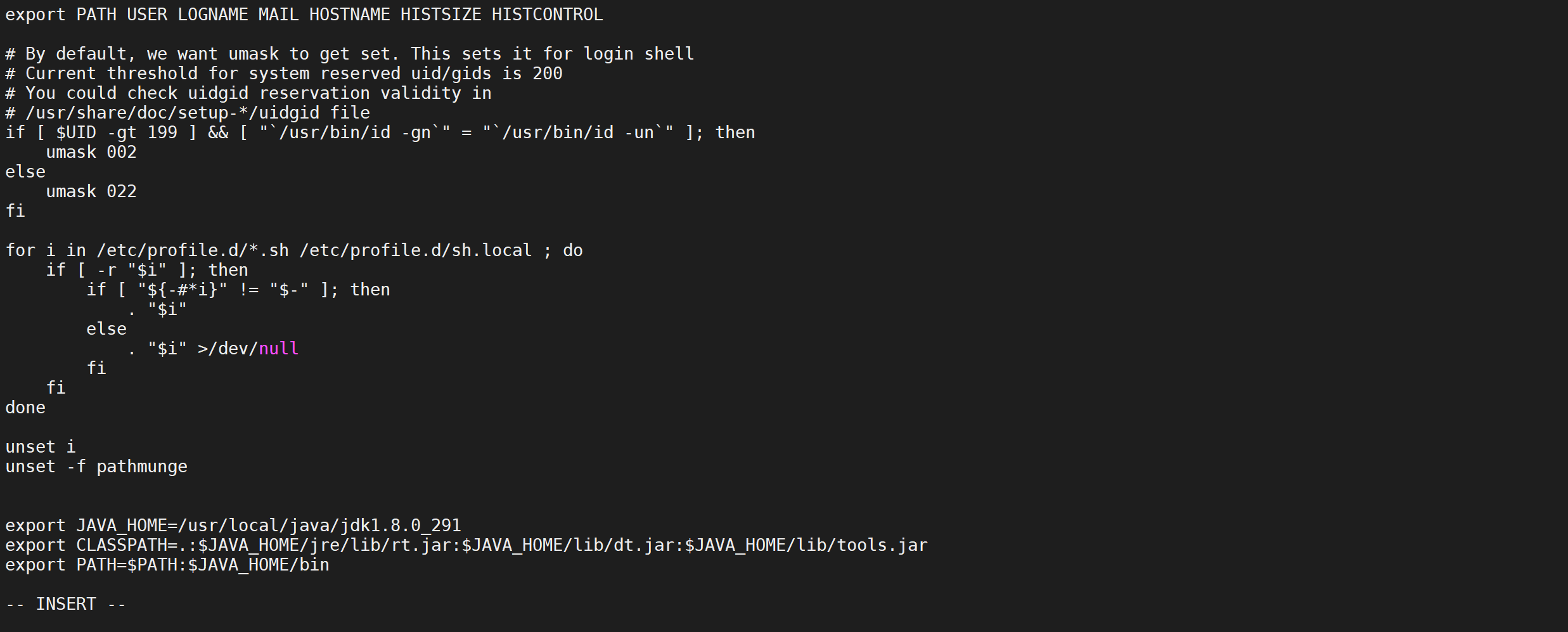
3.5.3.4 生效配置
source /etc/profile3.5.3.5 检查环境
java -version
3.5.4 安装imply
3.5.4.1 登录Imply官网
访问https://imply.io/get-started,进入Imply官网,查找合适的imply的版本的安装包,并填写简要信息后就可以下载了
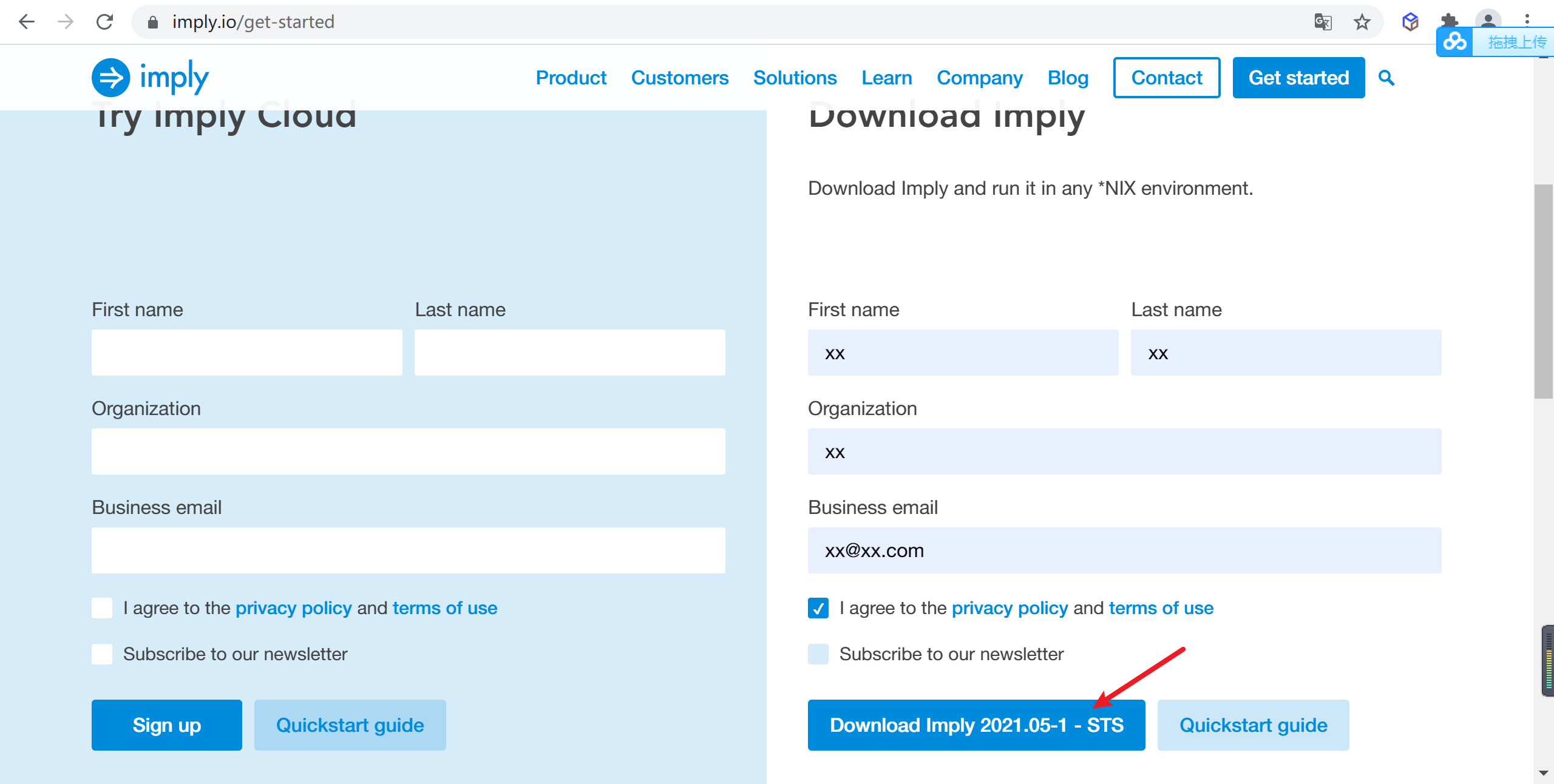
3.5.4.2 解压imply
下载后上传到服务器,并进行解压
# 创建imply安装目录
mkdir /usr/local/imply
# 解压imply
tar -zxvf imply-2021.05-1.tar.gz3.5.4.3 环境准备
进入
imply-2021.05-1目录后
# 进入imply目录
cd imply-2021.05-13.5.4.4 快速启动
使用本地存储、默认元数据存储derby,自带zookeeper启动,来体验下
druid
# 创建日志目录
mkdir logs
# 使用命令启动
nohup bin/supervise -c conf/supervise/quickstart.conf > logs/quickstart.log 2>&1 &3.5.4.5 查看日志
通过
quickstart.log来查看impl启动日志
tail -f logs/quickstart.log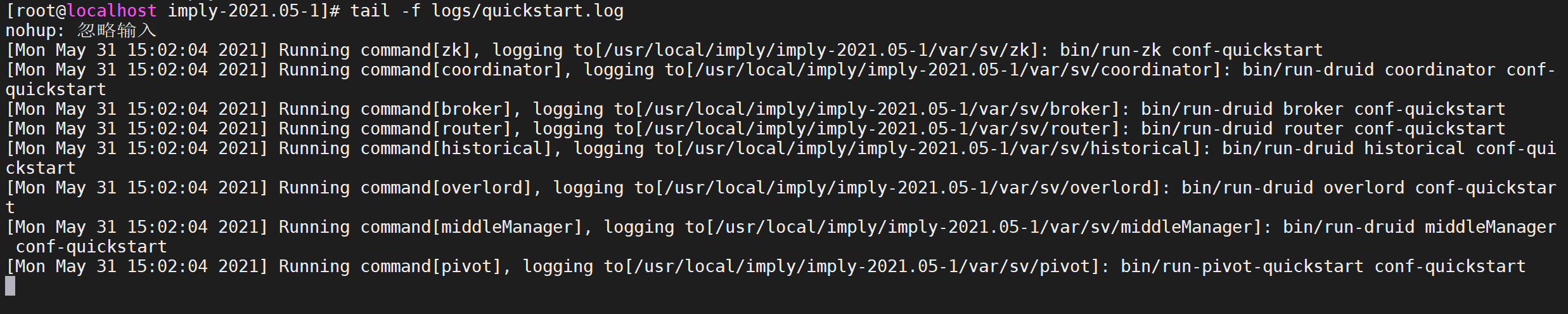
每启动一个服务均会打印出一条日志。可以通过var/sv/xxx/current查看服务启动时的日志信息
tail -f var/sv/broker/current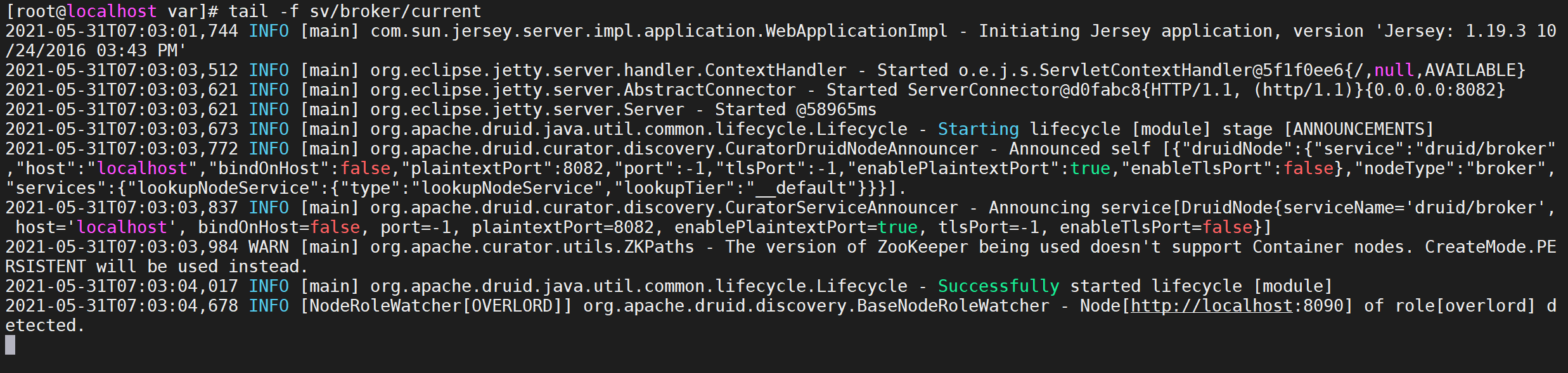
3.5.4.6 访问Imply
可以通过访问
9095端口来访问imply的管理页面
http://192.168.64.173:9095/
3.5.4.7 访问Druid
访问
8888端口就可以访问到我们的druid了
http://192.168.64.173:8888/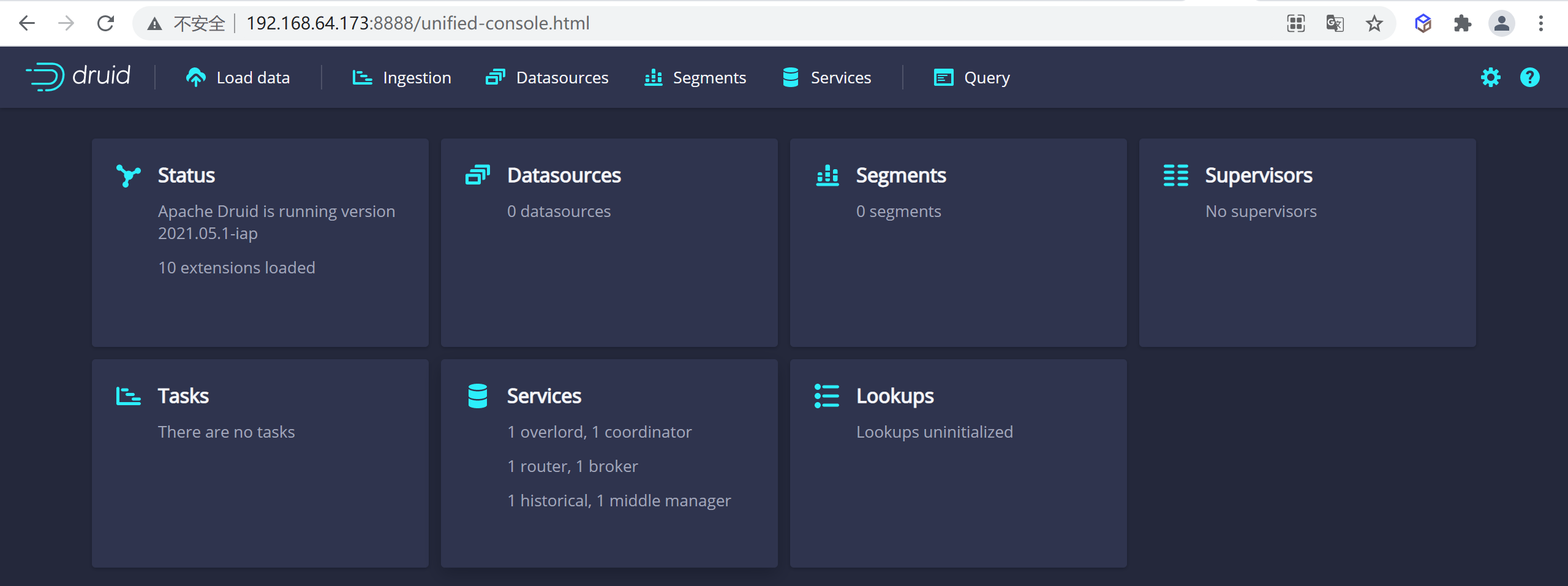
专注Java技术干货分享,欢迎志同道合的小伙伴,一起交流学习
最后
以上就是个性心锁最近收集整理的关于【超详细】Apache Durid从入门到安装详细教程的全部内容,更多相关【超详细】Apache内容请搜索靠谱客的其他文章。








发表评论 取消回复