tuple类型数据的获取:
大家都知道,元组里面的数据获取只能通过下标的方式去获取,
比如 :
a = ('username', 'age', 'phone')要获取username的话 ,就需要用a[0]的方式去获取,当元组中数据比较多的时候,用下标的方式获取数据就容易写错索引值。在这些场景下,用tuple存储数据就没那么方便,就会采用其他的方式去存储数据。
今天在学习的时候了解到了namedtuple 这么一种新的数据存储格式。
namedtuple 介绍:
namedtuple()是产生具有命名字段的元组的工厂函数,namedtuple 比普通tuple具有更好的可读性,可以使代码更易于维护。同时与字典相比,又更加的轻量和高效。
namedtuple还有一个非常好的一点是,它与tuple是完全兼容的。也就是说,我们依然可以用索引去访问一个namedtuple。
namedtuple()调用方式如下:
from collections import namedtuplenamedtuple(typename, field_names, *, verbose=False, rename=False,module=None)
返回一个新类,名为typename,它是元组tuple的子类。它的特性与tuple类似,是可索引可迭代的。
field_names的格式通常为字符串序列,如['name', 'age', 'phone', 'email']
,也可以是一个单一的字符串,每个字段以逗号分隔。
如果rename=True,无效的字段名将被自动更换为位置名称,如下所示:
['abc', 'def', 'ghi', 'abc']中无效的字段名为关键字'def'与重复字段名'abc',均视为无效,所以将自动更换为如下形式:['abc', '_1', 'ghi', '_3']。
下面演示namedtuple的具体用法:
from collections import namedtupleuserinfo = namedtuple('user_obj', ['name', 'age', 'phone', 'email'])user1 = userinfo('admin', '18', '13578451256', '13578451256@163.com')print(type(user1), user1)print(user1.name)print(user1.age)输出:<class '__main__.user_obj'> user_obj(name='admin', age='18', phone='13578451256', email='13578451256@163.com')admin18
从以上演示的代码中可以发现,要获取某个值非常的方便。
演示rename的效果:
from collections import namedtupleb = namedtuple('user_obj1', ['name', 'def'], rename=True)b1 = b('libo' ,'12')print(b1)输出:user_obj1(name='libo', _1='12')
做测试,namedtuple可以用在哪些地方呢?
以前封装接口测试框架的时候,测试用例是写在excel里面的,读取到的每一行数据都是一个列表,获取元素的时候通过索引去获取的话,如果万一哪一天用例模板要加一列或者减一列,就有可能要改脚本,因为,之前的想法是,读取excel的每一行内容转成dict进行存储,用excel表头的内容当做dict的key,这样读取数据处理起来就非常麻烦:
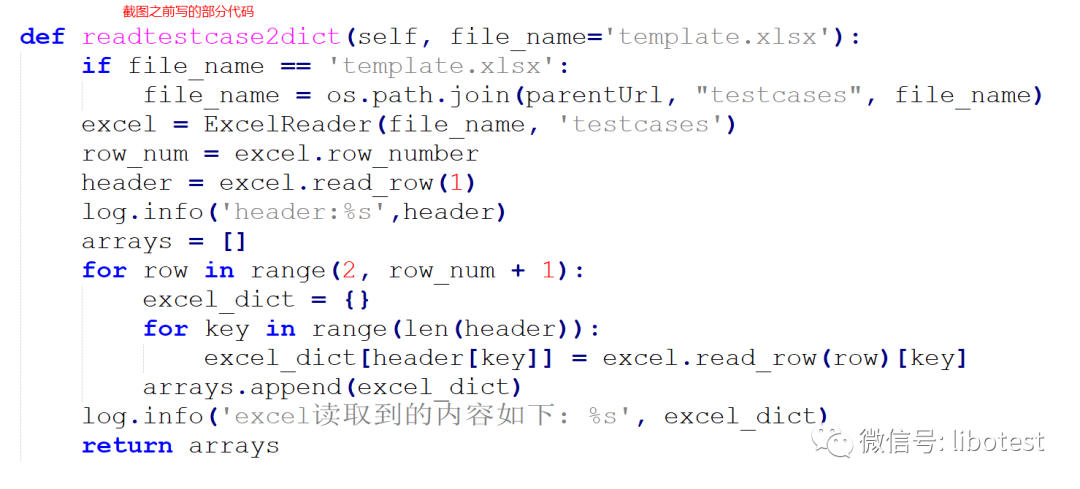
现在,学了namedtuple之后,那么读取excel存储的格式就可以改为namedtuple进行存储,后面取数还是按照类似dict的方式去进行提取,方便多了,代码也比较优雅。这里暂时不演示改之前读excel的脚本了,等后面重新设计框架的时候可以考虑用namedtuple。
谈一下我对namedtuple的认知:
感觉namedtuple跟java编程里面的javabean实体类比较相似,定义了一个class,以及class下的一些属性值,每创建一条namedtuple的数据都是生成了对应class的一个实例对象,最终把这些对象存到list里面就是对象的集合。
from collections import namedtuple#就好比有一个user_obj对象,里面有4个属性userinfo = namedtuple('user_obj', ['name', 'age', 'phone', 'email'])# 分别创建3个对象user1 = userinfo('admin', '18', '13578451256', '13578451256@163.com')user2 = userinfo('demo', '19', '13512345678', '13512345678@163.com')user3 = userinfo('user03', '35', '13875456545', '13875456545@163.com')user_list = [user1, user2, user3]for i in user_list:print(i.name)
看到上面这段代码,学过java的朋友,是不是有种似曾相识的感觉。这是不是就是面向对象编程呢 。本次的namedtuple讲解暂时就到这结束啦,如果后面有学习到更深入的用法再来进行补充!
。本次的namedtuple讲解暂时就到这结束啦,如果后面有学习到更深入的用法再来进行补充!
最后
以上就是合适酒窝最近收集整理的关于python高级用法之命名元组namedtuple的全部内容,更多相关python高级用法之命名元组namedtuple内容请搜索靠谱客的其他文章。



![Pytest单元测试系列[v1.0.0][mock模拟函数调用]](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)




发表评论 取消回复