点击左上方蓝字关注我们

【飞桨开发者说】武秉泓,国内一线互联网大厂工程师,计算机视觉技术爱好者,研究方向为目标检测、医疗影像

内容简介
EfficientDet是由Google Brain于2019年末在目标检测领域所提出的当之无愧的新SOTA算法,并被收录于CVPR2020。本项目对目标检测算法EfficientDet进行了详细的解析,并介绍了基于官方目标检测开发套件PaddleDetection进行模型复现的细节。

EfficientDet源于CVPR2020年的一篇文章
https://arxiv.org/abs/1911.09070(源码:
https://github.com/google/automl/tree/master/efficientdet), 其主要核心是在已完成网络结构搜索的EfficientNet的基础上,通过新设计的BiFPN进一步进行多尺度特征融合,最后经由分类/回归分支生成检测框,从而实现从高效分类器到高效检测器的拓展。在整体结构上,EfficientDet与RetinaNet等一系列anchor-based的one-stage detector无明显差别,但在每个单一模块上,EfficientDet在计算/存储资源有限的情况下将模型性能提升到了极致。
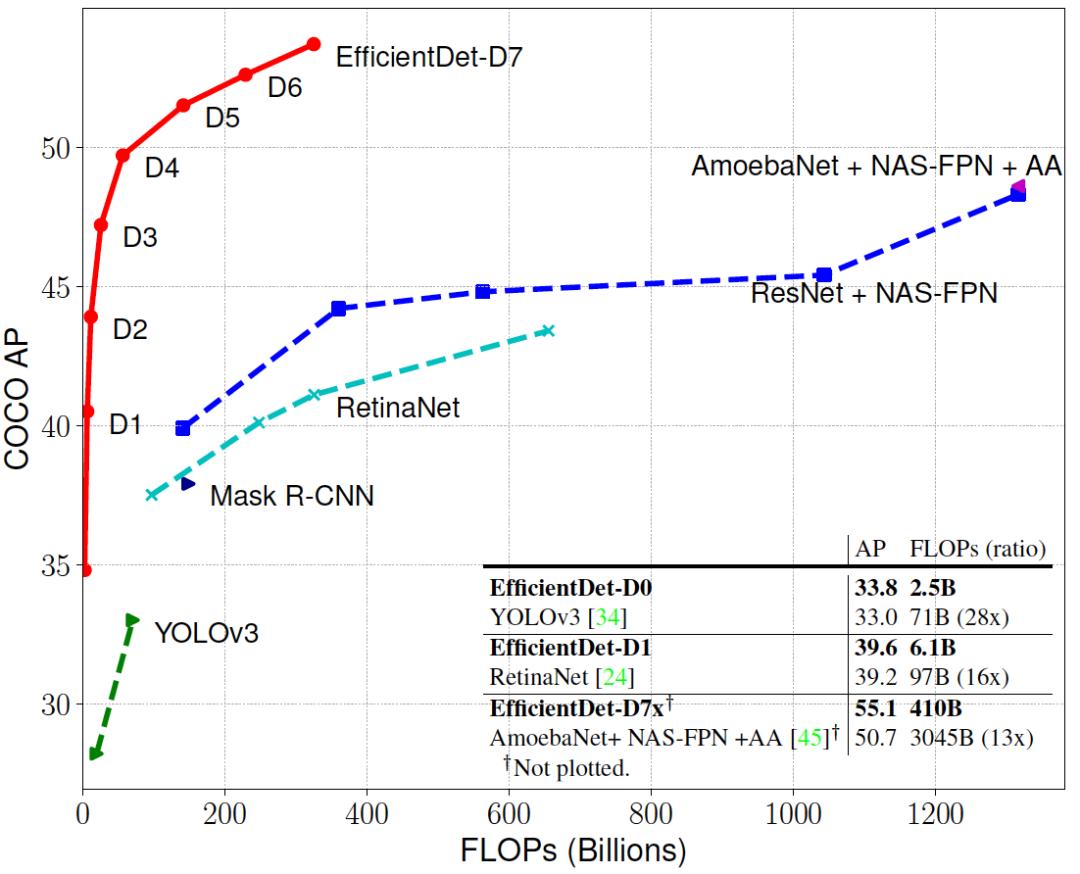
EfficientDet与现有其他主流模型的性能比对:
EfficientDet网络结构:
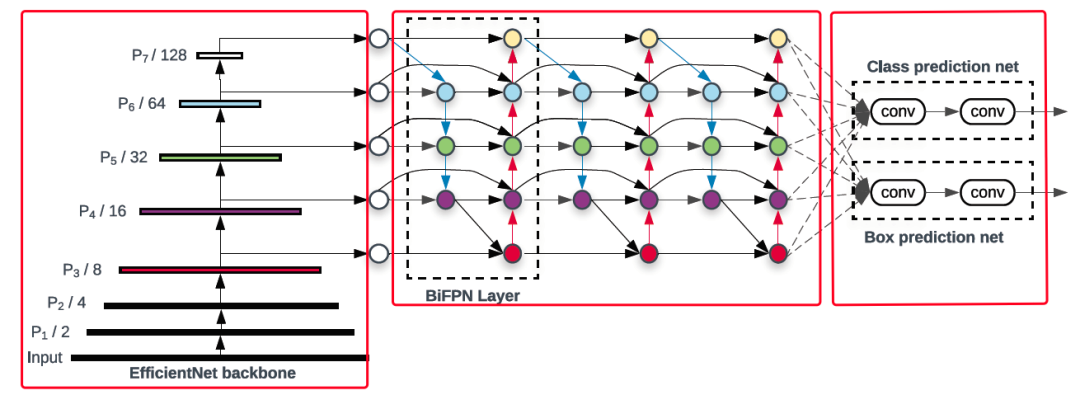
如上图从左至右所示,EfficientDet总共分为三个部分,依次为检测器的特征提取模块(Backbone)EfficientNet,检测器的多尺度特征融合模块(Neck)BiFPN,以及检测器的分类/回归预测模块(Head)Class/Box prediction net,其具体模型结构定义代码可见:
class EfficientDet(object):
"""
EfficientDet architecture, see https://arxiv.org/abs/1911.09070
Args:
backbone (object): backbone instance
fpn (object): feature pyramid network instance
retina_head (object): `RetinaHead` instance
"""
__category__ = 'architecture'
__inject__ = ['backbone', 'fpn', 'efficient_head', 'anchor_grid']
def __init__(self, backbone, fpn, efficient_head, anchor_grid, box_loss_weight=50.):
super(EfficientDet, self).__init__()
self.backbone = backbone
self.fpn = fpn
self.efficient_head = efficient_head
self.anchor_grid = anchor_grid
self.box_loss_weight = box_loss_weight
def build(self, feed_vars, mode='train'):
im = feed_vars['image']
if mode == 'train':
gt_labels = feed_vars['gt_label']
gt_targets = feed_vars['gt_target']
fg_num = feed_vars['fg_num']
else:
im_info = feed_vars['im_info']
mixed_precision_enabled = mixed_precision_global_state() is not None
if mixed_precision_enabled:
im = fluid.layers.cast(im, 'float16')
body_feats = self.backbone(im)
if mixed_precision_enabled:
body_feats = [fluid.layers.cast(f, 'float32') for f in body_feats]
body_feats = self.fpn(body_feats)
anchors = self.anchor_grid()
if mode == 'train':
loss = self.efficient_head.get_loss(body_feats, gt_labels, gt_targets, fg_num)
loss_cls = loss['loss_cls']
loss_bbox = loss['loss_bbox']
total_loss = loss_cls + self.box_loss_weight * loss_bbox
loss.update({'loss': total_loss})
return loss
else:
pred = self.efficient_head.get_prediction(body_feats, anchors, im_info)
return pred
在主体结构上,EfficientDet使用了从简易到复杂的不同的配置来做到速度和精度上的权衡,以EfficientDet-D0为例,模型组网&训练配置参数可见(YML文件格式):
architecture: EfficientDet
…
pretrain_weights: https://paddle-imagenet-models-name.bj.bcebos.com/EfficientNetB0_pretrained.tar
weights: output/efficientdet_d0/model_final
…
EfficientDet:
backbone: EfficientNet
fpn: BiFPN
efficient_head: EfficientHead
anchor_grid: AnchorGrid
box_loss_weight: 50.
EfficientNet:
norm_type: sync_bn
scale: b0
use_se: true
BiFPN:
num_chan: 64
repeat: 3
levels: 5
EfficientHead:
repeat: 3
num_chan: 64
prior_prob: 0.01
num_anchors: 9
gamma: 1.5
alpha: 0.25
delta: 0.1
output_decoder:
score_thresh: 0.05 # originally 0.
nms_thresh: 0.5
pre_nms_top_n: 1000 # originally 5000
detections_per_im: 100
nms_eta: 1.0
AnchorGrid:
anchor_base_scale: 4
num_scales: 3
aspect_ratios: [[1, 1], [1.4, 0.7], [0.7, 1.4]]
…
EfficientNet是由同作者Mingxing Tan发表于ICML 2019的分类网络,主要是在计算资源有限的情况下,考虑如何更高效地进行网络结构组合,从而使得模型具有更高的分类精度。在EfficientNet的网络设计时,其主要考虑三个维度对模型性能和资源占用的影响:网络深度(depth)、网络宽度(width)和输入图像分辨率 (resolution)大小。在进行网络结构搜索的背景下,作者所定义的优化目标如下:

在网络结构搜索时,网络深度(depth)、网络宽度(width)和输入图像分辨率 (resolution)则为可变量,为了在固定计算资源的情况下建模三者之间的关联,作者又提出了以下的建模方式,用来表示三者之间的约束关系:
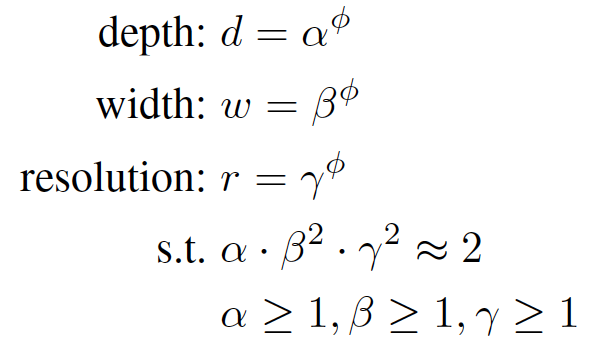
在网络结构搜索时,与其他网络设计文章所不同的是,EfficientNet提出了复合扩张方法(compound scaling method),其主要分为两步:
1. 在计算资源固定的情况下,通过网格搜索得到基准的网络深度/宽度/分辨率大小;
2. 通过复合系数(compound coefficient) 对深度/宽度/分辨率进行同时增加,从而得到一系列的网络结构EfficientNet-B0至B7。
在PaddleDetection中EfficientNet实现如下所示:
from __future__ import absolute_import
from __future__ import division
import collections
import math
import re
from paddle import fluid
from paddle.fluid.regularizer import L2Decay
from ppdet.core.workspace import register
__all__ = ['EfficientNet']
GlobalParams = collections.namedtuple('GlobalParams', [
'batch_norm_momentum', 'batch_norm_epsilon', 'width_coefficient', 'depth_coefficient', 'depth_divisor'
])
BlockArgs = collections.namedtuple('BlockArgs', [
'kernel_size', 'num_repeat', 'input_filters', 'output_filters', 'expand_ratio', 'stride', 'se_ratio'
])
GlobalParams.__new__.__defaults__ = (None, ) * len(GlobalParams._fields)
BlockArgs.__new__.__defaults__ = (None, ) * len(BlockArgs._fields)
def _decode_block_string(block_string):
assert isinstance(block_string, str)
ops = block_string.split('_')
options = {}
for op in ops:
splits = re.split(r'(d.*)', op)
if len(splits) >= 2:
key, value = splits[:2]
options[key] = value
assert (('s' in options and len(options['s']) == 1) or (len(options['s']) == 2 and options['s'][0] == options['s'][1]))
return BlockArgs(
kernel_size=int(options['k']),
num_repeat=int(options['r']),
input_filters=int(options['i']),
output_filters=int(options['o']),
expand_ratio=int(options['e']),
se_ratio=float(options['se']) if 'se' in options else None,
stride=int(options['s'][0]))
def get_model_params(scale):
block_strings = [
'r1_k3_s11_e1_i32_o16_se0.25',
'r2_k3_s22_e6_i16_o24_se0.25',
'r2_k5_s22_e6_i24_o40_se0.25',
'r3_k3_s22_e6_i40_o80_se0.25',
'r3_k5_s11_e6_i80_o112_se0.25',
'r4_k5_s22_e6_i112_o192_se0.25',
'r1_k3_s11_e6_i192_o320_se0.25',
]
block_args = []
for block_string in block_strings:
block_args.append(_decode_block_string(block_string))
params_dict = {
# width, depth
'b0': (1.0, 1.0),
'b1': (1.0, 1.1),
'b2': (1.1, 1.2),
'b3': (1.2, 1.4),
'b4': (1.4, 1.8),
'b5': (1.6, 2.2),
'b6': (1.8, 2.6),
'b7': (2.0, 3.1),
}
w, d = params_dict[scale]
global_params = GlobalParams(
batch_norm_momentum=0.99,
batch_norm_epsilon=1e-3,
width_coefficient=w,
depth_coefficient=d,
depth_divisor=8)
return block_args, global_params
def round_filters(filters, global_params):
multiplier = global_params.width_coefficient
if not multiplier:
return filters
divisor = global_params.depth_divisor
filters *= multiplier
min_depth = divisor
new_filters = max(min_depth, int(filters + divisor / 2) // divisor * divisor)
if new_filters < 0.9 * filters: # prevent rounding by more than 10%
new_filters += divisor
return int(new_filters)
def round_repeats(repeats, global_params):
multiplier = global_params.depth_coefficient
if not multiplier:
return repeats
return int(math.ceil(multiplier * repeats))
def conv2d(inputs, num_filters, filter_size, stride=1, padding='SAME', groups=1, use_bias=False, name='conv2d'):
param_attr = fluid.ParamAttr(name=name + '_weights')
bias_attr = False
if use_bias:
bias_attr = fluid.ParamAttr(name=name + '_offset', regularizer=L2Decay(0.))
feats = fluid.layers.conv2d(inputs, num_filters, filter_size, groups=groups, name=name, stride=stride, padding=padding, param_attr=param_attr, bias_attr=bias_attr)
return feats
def batch_norm(inputs, momentum, eps, name=None):
param_attr = fluid.ParamAttr(name=name + '_scale', regularizer=L2Decay(0.))
bias_attr = fluid.ParamAttr(name=name + '_offset', regularizer=L2Decay(0.))
return fluid.layers.batch_norm(input=inputs, momentum=momentum, epsilon=eps, name=name, moving_mean_name=name + '_mean', moving_variance_name=name + '_variance', param_attr=param_attr, bias_attr=bias_attr)
def mb_conv_block(inputs, input_filters, output_filters, expand_ratio, kernel_size, stride, momentum, eps, se_ratio=None, name=None):
feats = inputs
num_filters = input_filters * expand_ratio
if expand_ratio != 1:
feats = conv2d(feats, num_filters, 1, name=name + '_expand_conv')
feats = batch_norm(feats, momentum, eps, name=name + '_bn0')
feats = fluid.layers.swish(feats)
feats = conv2d(feats, num_filters, kernel_size, stride, groups=num_filters, name=name + '_depthwise_conv')
feats = batch_norm(feats, momentum, eps, name=name + '_bn1')
feats = fluid.layers.swish(feats)
if se_ratio is not None:
filter_squeezed = max(1, int(input_filters * se_ratio))
squeezed = fluid.layers.pool2d(feats, pool_type='avg', global_pooling=True)
squeezed = conv2d(squeezed, filter_squeezed, 1, use_bias=True, name=name + '_se_reduce')
squeezed = fluid.layers.swish(squeezed)
squeezed = conv2d(squeezed, num_filters, 1, use_bias=True, name=name + '_se_expand')
feats = feats * fluid.layers.sigmoid(squeezed)
feats = conv2d(feats, output_filters, 1, name=name + '_project_conv')
feats = batch_norm(feats, momentum, eps, name=name + '_bn2')
if stride == 1 and input_filters == output_filters:
feats = fluid.layers.elementwise_add(feats, inputs)
return feats
@register
class EfficientNet(object):
"""
EfficientNet, see https://arxiv.org/abs/1905.11946
Args:
scale (str): compounding scale factor, 'b0' - 'b7'.
use_se (bool): use squeeze and excite module.
norm_type (str): normalization type, 'bn' and 'sync_bn' are supported
"""
__shared__ = ['norm_type']
def __init__(self, scale='b0', use_se=True, norm_type='bn'):
assert scale in ['b' + str(i) for i in range(8)], "valid scales are b0 - b7"
assert norm_type in ['bn', 'sync_bn'], "only 'bn' and 'sync_bn' are supported"
super(EfficientNet, self).__init__()
self.norm_type = norm_type
self.scale = scale
self.use_se = use_se
def __call__(self, inputs):
blocks_args, global_params = get_model_params(self.scale)
momentum = global_params.batch_norm_momentum
eps = global_params.batch_norm_epsilon
num_filters = round_filters(32, global_params)
feats = conv2d(inputs, num_filters=num_filters, filter_size=3, stride=2, name='_conv_stem')
feats = batch_norm(feats, momentum=momentum, eps=eps, name='_bn0')
feats = fluid.layers.swish(feats)
layer_count = 0
feature_maps = []
for b, block_arg in enumerate(blocks_args):
for r in range(block_arg.num_repeat):
input_filters = round_filters(block_arg.input_filters, global_params)
output_filters = round_filters(block_arg.output_filters, global_params)
kernel_size = block_arg.kernel_size
stride = block_arg.stride
se_ratio = None
if self.use_se:
se_ratio = block_arg.se_ratio
if r > 0:
input_filters = output_filters
stride = 1
feats = mb_conv_block(feats, input_filters, output_filters, block_arg.expand_ratio, kernel_size, stride, momentum, eps, se_ratio=se_ratio, name='_blocks.{}.'.format(layer_count))
layer_count += 1
feature_maps.append(feats)
return list(feature_maps[i] for i in [2, 4, 6])
其中EfficientNet入参scale即对应着原文的复合系数compound coefficient,可选项为b0 - b7,在模型训练/推理时,会将最后三个不同block的feature map返回,并送入BiFPN进行进一步的多尺度特征融合。
Neck:BiFPN
作为EfficientDet的主要创新点,BiFPN主要通过堆叠多个“BiFPN Layer”来实现不同尺度特征的高度融合。下图为BiFPN Layer和不同结构的FPN的对比,相比于基本的FPN结构,BiFPN在具有top-down连接之外,同时有具有第二次bottom up的自底向上的特征融合同路。而相比于同样具有第二次bottom up的PANet,BiFPN具有同尺度特征的跨层连接(紫色箭头),且每个BiFPN Layer中每个层均带有独立的attention权重,在计算每个节点的特征图时,均以连接此节点的箭头末端的feature map先进行尺度上的缩放,再乘以归一化权重之后进行特征融合,从而得到该节点的feature map。
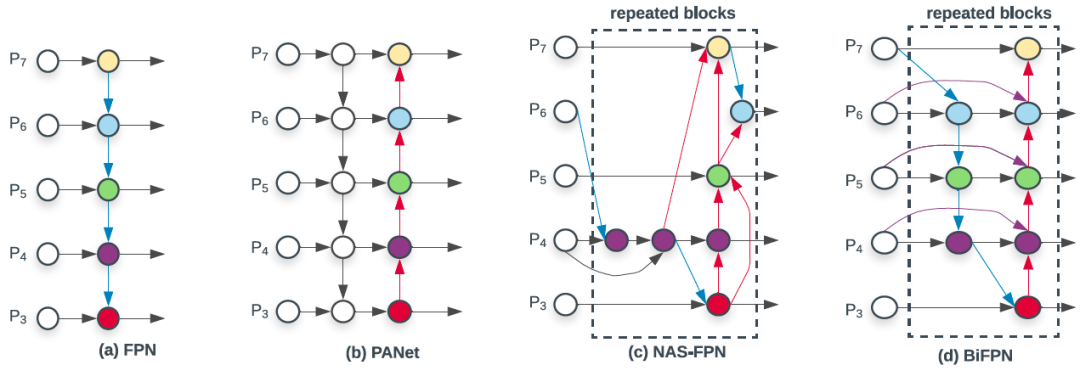
以P6节点为例,特征融合方式如下,其中为中间一列节点的计算方式,则为最后一列:
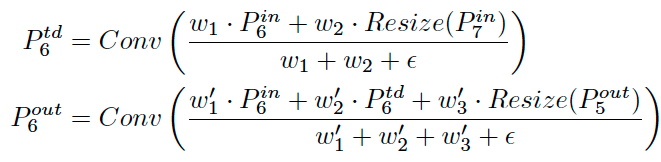
BiFPN Layer具体实现代码如下所示(BiFPNCell类):
from __future__ import absolute_import
from __future__ import division
from paddle import fluid
from paddle.fluid.param_attr import ParamAttr
from paddle.fluid.regularizer import L2Decay
from paddle.fluid.initializer import Constant, Xavier
from ppdet.core.workspace import register
__all__ = ['BiFPN']
class FusionConv(object):
def __init__(self, num_chan):
super(FusionConv, self).__init__()
self.num_chan = num_chan
def __call__(self, inputs, name=''):
x = fluid.layers.swish(inputs)
# depthwise
x = fluid.layers.conv2d(x, self.num_chan, filter_size=3, padding='SAME', groups=self.num_chan, param_attr=ParamAttr(initializer=Xavier(), name=name + '_dw_w'), bias_attr=False)
# pointwise
x = fluid.layers.conv2d(x, self.num_chan, filter_size=1, param_attr=ParamAttr(nitializer=Xavier(), name=name + '_pw_w'), bias_attr=ParamAttr(regularizer=L2Decay(0.), name=name + '_pw_b'))
# bn + act
x = fluid.layers.batch_norm(x, momentum=0.997, epsilon=1e-04, param_attr=ParamAttr(initializer=Constant(1.0), regularizer=L2Decay(0.), name=name + '_bn_w'), bias_attr=ParamAttr(regularizer=L2Decay(0.), name=name + '_bn_b'))
return x
class BiFPNCell(object):
def __init__(self, num_chan, levels=5):
super(BiFPNCell, self).__init__()
self.levels = levels
self.num_chan = num_chan
num_trigates = levels - 2
num_bigates = levels
self.trigates = fluid.layers.create_parameter(shape=[num_trigates, 3], dtype='float32', default_initializer=fluid.initializer.Constant(1.))
self.bigates = fluid.layers.create_parameter(shape=[num_bigates, 2], dtype='float32', default_initializer=fluid.initializer.Constant(1.))
self.eps = 1e-4
def __call__(self, inputs, cell_name=''):
assert len(inputs) == self.levels
def upsample(feat):
return fluid.layers.resize_nearest(feat, scale=2.)
def downsample(feat):
return fluid.layers.pool2d(feat, pool_type='max', pool_size=3, pool_stride=2, pool_padding='SAME')
fuse_conv = FusionConv(self.num_chan)
# normalize weight
trigates = fluid.layers.relu(self.trigates)
bigates = fluid.layers.relu(self.bigates)
trigates /= fluid.layers.reduce_sum(trigates, dim=1, keep_dim=True) + self.eps
bigates /= fluid.layers.reduce_sum(bigates, dim=1, keep_dim=True) + self.eps
feature_maps = list(inputs) # make a copy
# top down path
for l in range(self.levels - 1):
p = self.levels - l - 2
w1 = fluid.layers.slice(bigates, axes=[0, 1], starts=[l, 0], ends=[l + 1, 1])
w2 = fluid.layers.slice(bigates, axes=[0, 1], starts=[l, 1], ends=[l + 1, 2])
above = upsample(feature_maps[p + 1])
feature_maps[p] = fuse_conv(w1 * above + w2 * inputs[p], name='{}_tb_{}'.format(cell_name, l))
# bottom up path
for l in range(1, self.levels):
p = l
name = '{}_bt_{}'.format(cell_name, l)
below = downsample(feature_maps[p - 1])
if p == self.levels - 1:
# handle P7
w1 = fluid.layers.slice(bigates, axes=[0, 1], starts=[p, 0], ends=[p + 1, 1])
w2 = fluid.layers.slice(bigates, axes=[0, 1], starts=[p, 1], ends=[p + 1, 2])
feature_maps[p] = fuse_conv(w1 * below + w2 * inputs[p], name=name)
else:
w1 = fluid.layers.slice(trigates, axes=[0, 1], starts=[p - 1, 0], ends=[p, 1])
w2 = fluid.layers.slice(trigates, axes=[0, 1], starts=[p - 1, 1], ends=[p, 2])
w3 = fluid.layers.slice(trigates, axes=[0, 1], starts=[p - 1, 2], ends=[p, 3])
feature_maps[p] = fuse_conv(w1 * feature_maps[p] + w2 * below + w3 * inputs[p], name=name)
return feature_maps
@register
class BiFPN(object):
"""
Bidirectional Feature Pyramid Network, see https://arxiv.org/abs/1911.09070
Args:
num_chan (int): number of feature channels
repeat (int): number of repeats of the BiFPN module
level (int): number of FPN levels, default: 5
"""
def __init__(self, num_chan, repeat=3, levels=5):
super(BiFPN, self).__init__()
self.num_chan = num_chan
self.repeat = repeat
self.levels = levels
def __call__(self, inputs):
feats = []
# NOTE add two extra levels
for idx in range(self.levels):
if idx <= len(inputs):
if idx == len(inputs):
feat = inputs[-1]
else:
feat = inputs[idx]
if feat.shape[1] != self.num_chan:
feat = fluid.layers.conv2d(feat, self.num_chan, filter_size=1, padding='SAME', param_attr=ParamAttr(initializer=Xavier()), bias_attr=ParamAttr(regularizer=L2Decay(0.)))
feat = fluid.layers.batch_norm(feat, momentum=0.997, epsilon=1e-04, param_attr=ParamAttr(initializer=Constant(1.0), regularizer=L2Decay(0.)), bias_attr=ParamAttr(regularizer=L2Decay(0.)))
if idx >= len(inputs):
feat = fluid.layers.pool2d(feat, pool_type='max', pool_size=3, pool_stride=2, pool_padding='SAME')
feats.append(feat)
biFPN = BiFPNCell(self.num_chan, self.levels)
for r in range(self.repeat):
feats = biFPN(feats, 'bifpn_{}'.format(r))
return feats
在此BiFPN layer的基础上,通过堆叠不同个数的BiFPN Layer即组成了BiFPN,在backbone使用不同复杂程度的EfficientNet的配置时,BiFPN同样沿用了EfficientNet的部分设计思想:通过类似的复合系数来控制BiFPN的宽度和深度,其具体公式如下:
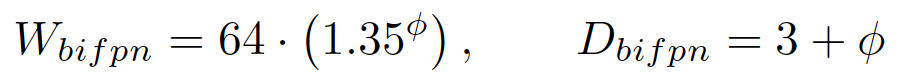
通过与EfficientNet类似的复合系数的控制,backbone和BiFPN的配比规模如下所示:
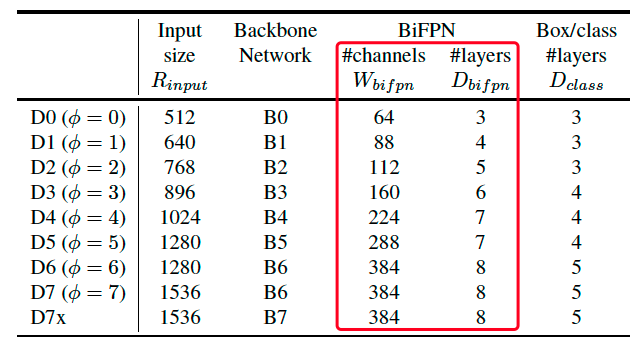
在PaddleDetection实现中,BiFPN实现如上链接中BiFPN所示,而参数修改则对应为配置文件efficientdet_d0.yml链接中的BiFPN处,其中repeat参数对应为BiFPN中“#layers”,num_chan参数则对应为BiFPN中“#channels”。总体来看,随着EfficientDet的backbone网络的不断复杂加深,BiFPN也随之不断继续堆叠,且通道数也同时随之增长。
Head:Class prediction net
& Box prediction net
作为Anchor based的目标检测算法,EfficientDet的Head与现有其他SOTA算法基本一致,同样是通过对从BiFPN中所获取的5个不同尺度的特征图分别进行检测框的分类与回归。在实现逻辑上,Class prediction net和Box prediction net均使用深度可分离卷积层(Depthwise separable convolution layer),且不同复杂度的backbone同样对应着不同的堆叠次数。而与其他Anchor-based detector所不同的是,EfficientDet的分类和回归卷积层采取了“参数共享”的方式来减小模型的参数量,具体而言,即分类和回归的大部分卷积层在特征计算的时候使用的同样的卷积核参数,但需要注意的是,两者的BN层相互独立,如下可见,卷积层的名称不受level参数的影响,而bn层则随着level参数的不同而不同:
def subnet(inputs, prefix, level):
feat = inputs
for i in range(self.repeat):
# NOTE share weight across FPN levels
conv_name = '{}_pred_conv_{}'.format(prefix, i)
feat = separable_conv(feat, self.num_chan, name=conv_name)
# NOTE batch norm params are not shared
bn_name = '{}_pred_bn_{}_{}'.format(prefix, level, i)
feat = fluid.layers.batch_norm(input=feat, act='swish', momentum=0.997, epsilon=1e-4, moving_mean_name=bn_name + '_mean', moving_variance_name=bn_name + '_variance', param_attr=ParamAttr(name=bn_name + '_w', initializer=Constant(value=1.), regularizer=L2Decay(0.)), bias_attr=ParamAttr(name=bn_name + '_b', regularizer=L2Decay(0.)))
return feat
训练方式
在efficientdet原文中所注明的是,训练efficientdet d0-d7使用了128的batchsize,并在32块TPUv3上训练了300个epoch(D7/D7x使用了600个epoch)。使用我们在paddledetection上所复现的efficientdet-d0的配置进行训练,在第216个epoch的时候完成收敛,在coco-minival上测试性能如下,与原文指标波动在0.02map内:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.341
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.523
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.360
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.134
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.401
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.525
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.289
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.445
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.471
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.196
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.559
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.690
由此可见,所复现的EfficientDet-D0性能与原文所描述效果基本符合,全部复现代码与相关模型将在近期更新至PaddleDetection官方代码库上,后期也会陆续增加更高配置的coco预训练模型,欢迎小伙伴们多提意见、多多使用:
https://github.com/PaddlePaddle/PaddleDetection
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨PaddleDetection目标检测套件项目地址·
GitHub:
https://github.com/PaddlePaddle/PaddleDetection
Gitee:
https://gitee.com/paddlepaddle/PaddleDetection
·飞桨官网地址·
https://www.paddlepaddle.org.cn/

扫描二维码 | 关注我们
微信号 : PaddleOpenSource
END
精彩活动

最后
以上就是土豪小猫咪最近收集整理的关于基于飞桨复现目标检测网络EfficientDet,感受CVPR2020的新SOTA算法的威力 的全部内容,更多相关基于飞桨复现目标检测网络EfficientDet,感受CVPR2020内容请搜索靠谱客的其他文章。








发表评论 取消回复