这部分的代码最重要最难且一定要掌握的是损失函数模块。所以这里重点讲的也是compute_loss和build_target两个函数。
train部分的代码较多,且通常会调用大量的函数,想要迅速掌握这部分的代码的运行流程,就要重要抓住代码主要框架。一个训练的脚本代码,一般都会包含5大部分:模型搭建、数据增强、优化器、损失函数、训练部分。
迅速的抓住这5个部分,train的脚本你一般都不会说看不懂。
项目全部代码已上传至GitHub: yolov3-spp-annotations.
目录标题
- 一、整体代码
- 1、LoadImagesAndLabels
- 2、DataLoader
- 3、DarkNet模型搭建
- 4、学习率设置
- 5、开始训练
- 5.1、train_one_epoch
- 5.1.1、warmup训练
- 5.1.2、amp混合精度训练
- 5.1.3、multi_scale多尺度训练
- 5.2、evaluate
- 6、Compute_loss
- 6.1、smooth_BCE
- 6.2、bbox_iou
- 6.3、build_target
- 6.4、FocalLoss
- 其他文件
- coco_eval.py
- coco_utils.py
- distributed_utils.py
- other_utils.py
一、整体代码
train.py
import torch
import argparse
import yaml
from torch.optim import lr_scheduler
from torch.utils.tensorboard import SummaryWriter
from torch import optim
from build_utils.datasets import LoadImagesAndLabels
from build_utils.parse_config import parse_data_cfg
from modules.model import DarkNet, YOLOLayer
from train_val_utils.coco_utils import get_coco_api_from_dataset
from train_val_utils.train_eval_body import train_one_epoch, evaluate
from train_val_utils.other_utils import check_file, init_seeds
import os
import math
import glob
def train(hyp):
init_seeds() # 初始化随机种子,保证结果可复现
device = torch.device(opt.device if torch.cuda.is_available() else "cpu")
print("Using {} device training.".format(device.type))
# ---------------------------------参数设置----------------------------------
# opt参数
cfg = opt.cfg
data = opt.data
epochs = opt.epochs
batch_size = opt.batch_size
accumulate = max(round(64 / batch_size), 1) # accumulate 每训练accumulate张图片更新权重
weights = opt.weights # initial training weights
results_file = opt.result_name
best = opt.best_weight
imgsz_train = opt.img_size # train image sizes
imgsz_test = opt.img_size # test image sizes
# 数据增强参数
multi_scale = opt.multi_scale # 多尺度训练(默认): True
warmup = opt.warmup
augment = opt.augment
rect = opt.rect
mosaic = opt.mosaic
# 路径参数 data/dataset.data
# configure run
data_dict = parse_data_cfg(data)
train_path = data_dict["train"]
test_path = data_dict["valid"]
nc = int(data_dict["classes"]) # number of classes
hyp["cls"] *= nc / 80 # update coco-tuned hyp['cls'] to current dataset
hyp["obj"] *= imgsz_test / 320
# ---------------------------------多尺度训练----------------------------------
# 图像要设置成32的倍数
gs = 32 # (pixels) grid size
assert math.fmod(imgsz_test, gs) == 0, "--img-size %g must be a %g-multiple" % (imgsz_test, gs)
grid_min, grid_max = imgsz_test // gs, imgsz_test // gs
# 是否多尺度训练 默认是
if multi_scale:
imgsz_min = opt.img_size // 1.5
imgsz_max = opt.img_size // 0.667
# 将给定的最大,最小输入尺寸向下调整到32的整数倍
grid_min, grid_max = imgsz_min // gs, imgsz_max // gs
imgsz_min, imgsz_max = int(grid_min * gs), int(grid_max * gs)
imgsz_train = imgsz_max # initialize with max size
print("Using multi_scale training, image range[{}, {}]".format(imgsz_min, imgsz_max)) # [320, 736]
# ---------------------------------其他----------------------------------
# 移除之前的resutl.txt
for f in glob.glob(results_file):
os.remove(f)
# ================================ step 1/5 数据处理(数据增强)=====================================
# 训练集的图像尺寸指定为multi_scale_range中最大的尺寸(736) 数据增强
train_dataset = LoadImagesAndLabels(train_path, imgsz_train, batch_size,
augment=augment,
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training 一般是在测试时使用
mosaic=mosaic)
# 验证集的图像尺寸指定为img_size(512)
val_dataset = LoadImagesAndLabels(test_path, imgsz_test, batch_size,
hyp=hyp,
rect=True) # 将每个batch的图像调整到合适大小,可减少运算量(并不是512x512标准尺寸)
# dataloader
# nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
# 这里调用LoadImagesAndLabels.__len__ 将train_dataset按batch_size分成batch份
train_dataloader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
num_workers=0, # win一般设为0
shuffle=not rect, # Shuffle=True unless rectangular training is used
pin_memory=True,
collate_fn=train_dataset.collate_fn)
val_datasetloader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
num_workers=0,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
# =================================== step 2/5 模型载入==========================================
# Initialize model
model = DarkNet(cfg).to(device)
# ---------------------------------训练参数设置(是否冻结训练)----------------------------------
# 是否冻结权重,freeze_layers=true 只训练3个predictor的权重
if opt.freeze_layers:
# 索引减一对应的是predictor的索引,YOLOLayer并不是predictor
output_layer_indices = [idx - 1 for idx, module in enumerate(model.module_list) if
isinstance(module, YOLOLayer)]
# 冻结除predictor和YOLOLayer外的所有层
freeze_layer_indeces = [x for x in range(len(model.module_list)) if
(x not in output_layer_indices) and
(x - 1 not in output_layer_indices)]
# Freeze non-output layers
# 总共训练3x2=6个parameters
for idx in freeze_layer_indeces:
for parameter in model.module_list[idx].parameters():
parameter.requires_grad_(False)
else:
# 默认是False
# 如果freeze_layer为False,默认仅训练除darknet53之后的部分
# 若要训练全部权重,删除以下代码
darknet_end_layer = 74 # only yolov3spp cfg
# Freeze darknet53 layers
# 总共训练21x3+3x2=69个parameters
for idx in range(darknet_end_layer + 1): # [0, 74]
for parameter in model.module_list[idx].parameters():
parameter.requires_grad_(False)
# =================================== step 3.1/5 优化器定义==========================================
# optimizer
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=hyp["lr0"], momentum=hyp["momentum"],
weight_decay=hyp["weight_decay"], nesterov=True)
# ---------------------------------载入pt----------------------------------
start_epoch = 0
best_map = 0.0
if weights.endswith(".pt") or weights.endswith(".pth"):
ckpt = torch.load(weights, map_location=device)
# load model
try:
ckpt["model"] = {k: v for k, v in ckpt["model"].items() if model.state_dict()[k].numel() == v.numel()}
model.load_state_dict(ckpt["model"], strict=False)
except KeyError as e:
s = "%s is not compatible with %s. Specify --weights '' or specify a --cfg compatible with %s. "
"See https://github.com/ultralytics/yolov3/issues/657" % (opt.weights, opt.cfg, opt.weights)
raise KeyError(s) from e
# load optimizer
if ckpt["optimizer"] is not None:
optimizer.load_state_dict(ckpt["optimizer"])
if "best_map" in ckpt.keys():
best_map = ckpt["best_map"]
# load results
if ckpt.get("training_results") is not None:
with open(results_file, "w") as file:
file.write(ckpt["training_results"]) # write results.txt
# epochs
start_epoch = ckpt["epoch"] + 1
if epochs < start_epoch:
print('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %
(opt.weights, ckpt['epoch'], epochs))
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt
# =================================== step 3.2/5 优化器学习率设置======================================
lf = lambda x: ((1 + math.cos(x * math.pi / epochs)) / 2) * (1 - hyp["lrf"]) + hyp["lrf"] # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
scheduler.last_epoch = start_epoch # 指定从哪个epoch开始
# # Plot lr schedule LR.png 学习率变化曲线 L
# y = []
# for _ in range(epochs):
# scheduler.step()
# y.append(optimizer.param_groups[0]['lr'])
# plt.plot(y, '.-', label='LambdaLR')
# plt.xlabel('epoch')
# plt.ylabel('LR')
# plt.tight_layout()
# plt.savefig('others/LR.png', dpi=300)
# model.yolo_layers = model.module.yolo_layers
# --------------------------------- step 4 损失函数参数 ----------------------------------
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.gr = 1.0 # giou loss ratio (obj_loss = 1.0 or giou)
# 计算每个类别的目标个数,并计算每个类别的比重
# model.class_weights = labels_to_class_weights(train_dataset.labels, nc).to(device) # attach class weights
# =================================== step 5/5 训练======================================
# start training
# caching val_data when you have plenty of memory(RAM)
# coco = None
coco = get_coco_api_from_dataset(val_dataset) # 方便后面计算MAP用
print("starting traning for %g epochs..." % epochs)
for epoch in range(start_epoch, epochs):
# 训练集
mloss, lr = train_one_epoch(model, optimizer, train_dataloader,
device, epoch + 1, epochs,
accumulate=accumulate, # 迭代多少batch才训练完64张图片
img_size=imgsz_train, # 输入图像的大小
multi_scale=multi_scale, # 是否需要多尺度训练
grid_min=grid_min, # grid的最小尺寸
grid_max=grid_max, # grid的最大尺寸
gs=gs, # grid step: 32
print_freq=1, # 每训练多少个step打印一次信息
warmup=warmup) # 第一个epoch要采用特殊的训练方式 慢慢训练
# 更新学习率
scheduler.step()
# 验证集 只测试最后一个epoch epochs=1,2,3...
if opt.notest is False or epoch == epochs:
# evaluate on the test dataset
result_info = evaluate(model, val_datasetloader,
coco=coco, device=device)
# --------------------------------- 打印输出 保存模型----------------------------------
coco_mAP = result_info[0]
voc_mAP = result_info[1]
coco_mAR = result_info[8]
# write into tensorboard
if tb_writer:
tags = ['train/giou_loss', 'train/obj_loss', 'train/cls_loss', 'train/loss', "learning_rate",
"mAP@[IoU=0.50:0.95]", "mAP@[IoU=0.5]", "mAR@[IoU=0.50:0.95]"]
for x, tag in zip(mloss.tolist() + [lr, coco_mAP, voc_mAP, coco_mAR], tags):
tb_writer.add_scalar(tag, x, epoch)
# write into txt
with open(results_file, "a") as f:
result_info = [str(round(i, 4)) for i in result_info]
txt = "epoch:{} {}".format(epoch, ' '.join(result_info))
f.write(txt + "n")
# update best mAP(IoU=0.50:0.95)
if coco_mAP > best_map:
best_map = coco_mAP
if opt.savebest is False:
# save weights every epoch
with open(results_file, 'r') as f:
save_files = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'training_results': f.read(),
'epoch': epoch,
'best_map': best_map}
torch.save(save_files, "./weights/yolov3spp-{}.pt".format(epoch))
else:
# only save best weights
if best_map == coco_mAP:
with open(results_file, 'r') as f:
save_files = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'training_results': f.read(),
'epoch': epoch,
'best_map': best_map}
torch.save(save_files, best.format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='cfg/yolov3-spp.cfg', help="cfg/*.cfg path")
parser.add_argument('--data', type=str, default='data/dataset.data', help='cfg/*.data path')
parser.add_argument('--hyp', type=str, default='cfg/hyp.yaml', help='hyperparameters path')
parser.add_argument('--weights', type=str, default='weights/yolov3spp-voc-512.pt',
help='pretrain weights path')
parser.add_argument('--result-name', type=str, default='outputs/result.txt', help='results.txt name')
parser.add_argument('--epochs', type=int, default=1, help="train epochs")
parser.add_argument('--batch-size', type=int, default=4, help="train batch_size")
parser.add_argument('--img-size', type=int, default=512, help='test size')
parser.add_argument('--savebest', type=bool, default=True, help='only save best checkpoint')
parser.add_argument('--best-weight', type=str, default='weights/best.pt', help='best weights path')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--freeze-layers', type=bool, default=False, help='Freeze non-output layers')
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
parser.add_argument('--multi-scale', type=bool, default=True,
help='adjust (67%% - 150%%) img_size every 10 batches')
parser.add_argument('--warmup', type=bool, default=False, help='warmup train')
parser.add_argument('--augment', type=bool, default=True, help='dataset augment')
parser.add_argument('--rect', type=bool, default=False, help='rect training')
parser.add_argument('--mosaic', type=bool, default=True, help='mosaic augment')
opt = parser.parse_args()
# 检查文件是否存在
opt.cfg = check_file(opt.cfg)
opt.data = check_file(opt.data)
opt.hyp = check_file(opt.hyp)
print(opt)
# 载入超参数文件
with open(opt.hyp, encoding='UTF-8') as f:
hyp = yaml.load(f, Loader=yaml.FullLoader)
# 实例化 tensorboard
tb_writer = SummaryWriter()
train(hyp)
qquad 训练部分的代码其实是比较简单的,加上我写的注释,我相信大部分都是可以看懂的,下面我就按代码顺序着重讲几点比较难的部分。
1、LoadImagesAndLabels
qquad 这部分内容我在另一篇博客作了详细介绍: 【YOLO-V3-SPP 源码解读】四、数据载入(数据增强).
2、DataLoader
略,后面更新
这部分想讲一下dataset、dataloader、datasample这三个部分的联系,理解数据到底是怎么分成一个个的batch并从文件中取出来的。
3、DarkNet模型搭建
qquad 这部分内容我在另一篇博客作了详细介绍: 【YOLO-V3-SPP 源码解读】二、模型搭建 .
4、学习率设置
# =================================== step 3.2/5 优化器学习率设置======================================
lf = lambda x: ((1 + math.cos(x * math.pi / epochs)) / 2) * (1 - hyp["lrf"]) + hyp["lrf"] # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
scheduler.last_epoch = start_epoch # 指定从哪个epoch开始
qquad 这部分代码如上所示,采用的cosine Warmup 学习率下降策略, 具体的原理解释可以看我的另一篇博客:【trick 6】warmup —— 一种学习率调优方法.
5、开始训练
入口:
train.py
for epoch in range(start_epoch, epochs):
# 训练集
mloss, lr = train_one_epoch(model, optimizer, train_dataloader,
device, epoch + 1, epochs,
accumulate=accumulate, # 迭代多少batch才训练完64张图片
img_size=imgsz_train, # 输入图像的大小
multi_scale=multi_scale, # 是否需要多尺度训练
grid_min=grid_min, # grid的最小尺寸
grid_max=grid_max, # grid的最大尺寸
gs=gs, # grid step: 32
print_freq=1, # 每训练多少个step打印一次信息
warmup=warmup) # 第一个epoch要采用特殊的训练方式 慢慢训练
# 更新学习率
scheduler.step()
# 验证集 只测试最后一个epoch epochs=1,2,3...
if opt.notest is False or epoch == epochs:
# evaluate on the test dataset
result_info = evaluate(model, val_datasetloader,
coco=coco, device=device)
最重要的就是train_one_epoch和evaluate两个部分
5.1、train_one_epoch
总体代码:
train_eval_body.py
def train_one_epoch(model, optimizer, data_loader, device, epoch, epochs,
print_freq, accumulate, img_size,
grid_min, grid_max, gs,
multi_scale=False, warmup=True):
"""
Args:
data_loader: len = 1430 1430个batch_size=1个epochs分成一块块的batch_size
print_freq: 每50个batch在logger中更新
accumulate: 1、多尺度训练时accumulate个batch改变一次图片的大小
2、每训练accumulate*batch_size张图片更新一次权重和学习率
第一个epoch accumulate=1
img_size: 训练图像的大小
grid_min, grid_max: 在给定最大最小输入尺寸范围内随机选取一个size(size为32的整数倍)
gs: grid_size
warmup: 用在训练第一个epoch时,这个时候的训练学习率要调小点,慢慢训练
Returns:
mloss: 每个epch计算的mloss [box_mean_loss, obj_mean_loss, class_mean_loss, total_mean_loss]
now_lr: 每个epoch之后的学习率
"""
model.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
header = 'Epoch: [{}/{}]'.format(epoch, epochs)
# 模型训练开始第一轮采用warmup训练 慢慢训练
lr_scheduler = None
if epoch == 1 and warmup is True: # 当训练第一轮(epoch=1)时,启用warmup训练方式,可理解为热身训练
warmup_factor = 1.0 / 1000
warmup_iters = min(1000, len(data_loader) - 1)
lr_scheduler = utils.warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)
accumulate = 1 # 慢慢训练,每个batch都改变img大小,每个batch都改变权重
# amp.GradScaler: 混合精度训练
# GradScaler: 在反向传播前给 loss 乘一个 scale factor,所以之后反向传播得到的梯度都乘了相同的 scale factor
# scaler: GradScaler对象用来自动做梯度缩放
# https://blog.csdn.net/l7H9JA4/article/details/114324414?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161944073216780357273770%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=161944073216780357273770&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-1-114324414.pc_search_result_cache&utm_term=amp.GradScaler%28enabled%3Denable_amp%29
enable_amp = True if "cuda" in device.type else False
scaler = amp.GradScaler(enabled=enable_amp)
# mean losses [box_mean_loss, obj_mean_loss, class_mean_loss, total_mean_loss]
mloss = torch.zeros(4).to(device)
now_lr = 0. # 本batch的lr
nb = len(data_loader) # number of batches
# imgs: [batch_size, 3, img_size, img_size]
# targets: [num_obj, 6] , that number 6 means -> (img_index, obj_index, x, y, w, h)
# paths: list of img path
# 这里调用一次datasets.__len__; batch_size次datasets.__getitem__; 再执行1次datasets.collate_fn
for i, (imgs, targets, paths, _, _) in enumerate(metric_logger.log_every(data_loader, print_freq, header)):
# ni 统计从epoch0开始的所有batch数
ni = i + nb * epoch # number integrated batches (since train start)
# imgs: [4, 3, 736, 736]一个batch的图片
# targets(真实框): [22, 6] 22: num_object 6: batch中第几张图(0,1,2,3),类别,x,y,w,h
imgs = imgs.to(device).float() / 255.0 # 对imgs进行归一化 uint8 to float32, 0 - 255 to 0.0 - 1.0
targets = targets.to(device)
# Multi-Scale
if multi_scale:
# 每训练accumulate个batch(batch_size*accumulate张图片),就随机修改一次输入图片大小
# 由于label已转为相对坐标,故缩放图片不影响label的值
if ni % accumulate == 0: # adjust img_size (67% - 150%) every 1 batch
# 在给定最大最小输入尺寸范围内随机选取一个size(size为32的整数倍)
img_size = random.randrange(grid_min, grid_max + 1) * gs # img_size = 320~736
sf = img_size / max(imgs.shape[2:]) # scale factor
# 如果图片最大边长不等于img_size, 则缩放一个batch图片,并将长和宽调整到32的整数倍
if sf != 1:
# gs: (pixels) grid size
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to 32-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# 混合精度训练上下文管理器,如果在CPU环境中不起任何作用
with amp.autocast(enabled=enable_amp):
# pred: tensor格式 list列表 存放三个tensor 对应的是三个yolo层的输出
# 例如[batch_size, 3, 23, 23, 25] [batch_size, 3, 46, 46, 25] [batch_size, 3, 96, 96, 25]
# [batch_size, anchor_num, grid_h, grid_w, xywh + obj + classes]
# 可以看出来这里的预测值是三个yolo层每个grid_cell(每个grid_cell有三个预测值)的预测值,后面肯定要进行正样本筛选
pred = model(imgs)
# dict格式 存放三分tensor 每个tensor对应一个loss的键值对
# loss的顺序(键)为: 'box_loss', 'obj_loss', 'class_loss'
# targets(数据增强后的真实框): [21, 6] 21: num_object 6: batch中第几张图(0,1,2,3)+类别+x+y+w+h
loss_dict = compute_loss(pred, targets, model)
losses = sum(loss for loss in loss_dict.values()) # 三个相加
# reduce losses over all GPUs for logging purpose
loss_dict_reduced = utils.reduce_dict(loss_dict)
losses_reduced = sum(loss for loss in loss_dict_reduced.values())
loss_items = torch.cat((loss_dict_reduced["box_loss"],
loss_dict_reduced["obj_loss"],
loss_dict_reduced["class_loss"],
losses_reduced)).detach()
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
# 如果losses_reduced无效,则输出对应图片信息
if not torch.isfinite(losses_reduced):
print('WARNING: non-finite loss, ending training ', loss_dict_reduced)
print("training image path: {}".format(",".join(paths)))
sys.exit(1)
losses *= 1. / accumulate # scale loss
# 1、backward 反向传播 scale loss 先将梯度放大 防止梯度消失
scaler.scale(losses).backward()
# optimize
# 每训练accumulate*batch_size张图片更新一次权重
if ni % accumulate == 0:
# 2、scaler.step() 首先把梯度的值unscale回来.
# 如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,
# 否则,忽略step调用,从而保证权重不更新(不被破坏)
scaler.step(optimizer)
# 3、准备着,看是否要增大scaler 不一定更新 看scaler.step(optimizer)的结果,需要更新就更新
scaler.update()
# 正常更新权重
optimizer.zero_grad()
metric_logger.update(loss=losses_reduced, **loss_dict_reduced)
now_lr = optimizer.param_groups[0]["lr"]
metric_logger.update(lr=now_lr)
# 每训练accumulate*batch_size张图片更新一次学习率(只在第一个epoch) warmup=True 才会执行
if ni % accumulate == 0 and lr_scheduler is not None:
lr_scheduler.step()
return mloss, now_lr
5.1.1、warmup训练
# 模型训练开始第一轮采用warmup训练 慢慢训练
lr_scheduler = None
if epoch == 1 and warmup is True: # 当训练第一轮(epoch=1)时,启用warmup训练方式,可理解为热身训练
warmup_factor = 1.0 / 1000
warmup_iters = min(1000, len(data_loader) - 1)
lr_scheduler = utils.warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)
accumulate = 1 # 慢慢训练,每个batch都改变img大小,每个batch都改变权重
qquad 这部分和上一节的学习率类似,都用到了warmup学习率下降策略,详细原理可看博客:【trick 6】warmup —— 一种学习率调优方法.
5.1.2、amp混合精度训练
qquad 这是一个训练加速策略, 具体的原理解释和使用方法可以看我的另一篇博客:【Trick2】【PyTorch】torch.cuda.amp自动混合精度训练 —— 节省显存并加快推理速度.
5.1.3、multi_scale多尺度训练
# Multi-Scale
if multi_scale:
# 每训练accumulate个batch(batch_size*accumulate张图片),就随机修改一次输入图片大小
# 由于label已转为相对坐标,故缩放图片不影响label的值
if ni % accumulate == 0: # adjust img_size (67% - 150%) every 1 batch
# 在给定最大最小输入尺寸范围内随机选取一个size(size为32的整数倍)
img_size = random.randrange(grid_min, grid_max + 1) * gs # img_size = 320~736
sf = img_size / max(imgs.shape[2:]) # scale factor
# 如果图片最大边长不等于img_size, 则缩放一个batch图片,并将长和宽调整到32的整数倍
if sf != 1:
# gs: (pixels) grid size
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to 32-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
qquad 这是一个训练策略, 具体的原理解释和使用方法可以看我的另一篇博客:【trick 5】multi-scale training多尺度训练 —— 提高模型对物体大小的鲁棒性.
5.2、evaluate
总体代码:
train_eval_body.py
@torch.no_grad()
def evaluate(model, data_loader, coco=None, device=None):
"""
Args:
coco: coco api
Returns:
"""
n_threads = torch.get_num_threads() # 8线程
# FIXME remove this and make paste_masks_in_image run on the GPU
torch.set_num_threads(1)
cpu_device = torch.device("cpu")
model.eval()
metric_logger = utils.MetricLogger(delimiter=" ")
header = "Test: "
if coco is None:
coco = get_coco_api_from_dataset(data_loader.dataset)
iou_types = _get_iou_types(model) # ['bbox']
coco_evaluator = CocoEvaluator(coco, iou_types)
# 这里调用一次datasets.__len__; batch_size次datasets.__getitem__; 再执行1次datasets.collate_fn
# 调用__len__将dataset分为batch个批次; 再调用__getitem__取出(增强后)当前批次的每一张图片(batch_size张);
# 最后调用collate_fn函数将当前整个批次的batch_size张图片(增强过的)打包成一个batch, 方便送入网络进行前向传播
for imgs, targets, paths, shapes, img_index in metric_logger.log_every(data_loader, 1, header):
imgs = imgs.to(device).float() / 255.0 # uint8 to float32, 0 - 255 to 0.0 - 1.0
# targets = targets.to(device)
# 当使用CPU时,跳过GPU相关指令
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
model_time = time.time()
pred = model(imgs)[0] # only get inference result [4, 5040, 25]
# [4, 5040, 25] => len=4 [57,6], [5,6], [14,6], [1,6] 6: batch中第几张图(0,1,2,3),类别,x,y,w,h
pred = non_max_suppression(pred, conf_thres=0.01, nms_thres=0.6, multi_cls=False)
outputs = []
for index, p in enumerate(pred):
if p is None:
p = torch.empty((0, 6), device=cpu_device)
boxes = torch.empty((0, 4), device=cpu_device)
else:
# xmin, ymin, xmax, ymax
boxes = p[:, :4]
# shapes: (h0, w0), ((h / h0, w / w0), pad)
# 将boxes信息还原回原图尺度,这样计算的mAP才是准确的
boxes = scale_coords(imgs[index].shape[1:], boxes, shapes[index][0]).round()
# 注意这里传入的boxes格式必须是xmin, ymin, xmax, ymax,且为绝对坐标
info = {"boxes": boxes.to(cpu_device),
"labels": p[:, 5].to(device=cpu_device, dtype=torch.int64),
"scores": p[:, 4].to(cpu_device)}
outputs.append(info)
model_time = time.time() - model_time
res = {img_id: output for img_id, output in zip(img_index, outputs)}
evaluator_time = time.time()
coco_evaluator.update(res)
evaluator_time = time.time() - evaluator_time
metric_logger.update(model_time=model_time, evaluator_time=evaluator_time)
# gather the stats from all processes
metric_logger.synchronize_between_processes()
print("Averaged stats:", metric_logger)
coco_evaluator.synchronize_between_processes()
# accumulate predictions from all images
coco_evaluator.accumulate()
coco_evaluator.summarize()
torch.set_num_threads(n_threads)
result_info = coco_evaluator.coco_eval[iou_types[0]].stats.tolist() # numpy to list
return result_info
def _get_iou_types(model):
model_without_ddp = model
if isinstance(model, torch.nn.parallel.DistributedDataParallel):
model_without_ddp = model.module
iou_types = ["bbox"]
return iou_types
qquad 这部分的代码和【YOLO-V3-SPP 源码解读】三、预测模块.其实是差不多的,可以学下。
qquad 唯一不同的是预测模块得到结果是直接调用draw_box_util将预测结果直接画在原图上,而这里的eval模块是将预测结果送入官网写的计算coco评价指标包里,计算出coco评价指标:mAP@[IoU=0.50:0.95]、mAP@[IoU=0.50]、mAR@[IoU=0.50:0.95]等,再送入train.py保存起来或打印出来。关于coco官方评价指标代码我会贴在最后面,这里就仔细讲解了,因为没必要就是掉包用就行了。
6、Compute_loss
qquad 可能细心的朋友就会发现我似乎没讲损失函数部分,是的,作为训练模块的5个最基本的部分,这部分是非常非常重要的,也是读的yolo源码里面最难最恶心的一部分,所以我把它放在了最后进行讲解。
代码入口:
train_eval_body.py
# pred: tensor格式 list列表 存放三个tensor 对应的是三个yolo层的输出
# 例如[batch_size, 3, 23, 23, 25] [batch_size, 3, 46, 46, 25] [batch_size, 3, 96, 96, 25]
# [batch_size, anchor_num, grid_h, grid_w, xywh + obj + classes]
# 可以看出来这里的预测值是三个yolo层每个grid_cell(每个grid_cell有三个预测值)的预测值,后面肯定要进行正样本筛选
pred = model(imgs)
# dict格式 存放三分tensor 每个tensor对应一个loss的键值对
# loss的顺序(键)为: 'box_loss', 'obj_loss', 'class_loss'
# targets(数据增强后的真实框): [21, 6] 21: num_object 6: batch中第几张图(0,1,2,3)+类别+x+y+w+h
loss_dict = compute_loss(pred, targets, model)
losses = sum(loss for loss in loss_dict.values()) # 三个相加
这里的pred输出来自于model.py:
if self.training:
# train
# yolo_out: tensor格式 list列表 存放三个tensor 对应的是三个yolo层的输出
# 例如[batch_size, 3, 23, 23, 25] [batch_size, 3, 46, 46, 25] [batch_size, 3, 96, 96, 25]
# [batch_size, anchor_num, grid_h, grid_w, xywh + obj + classes]
# 可以看出来这里的预测值是三个yolo层每个grid_cell(每个grid_cell有三个预测值)的预测值,后面肯定要进行正样本筛选
# 训练模式直接返回3个预测层的预测输出值(没有进行任何数值上的处理,即预测值是相对feature map的)
return yolo_out
qquad 如果有不熟悉模型搭建(model.py)的可以看我的另一篇博客 【YOLO-V3-SPP 源码解读】二、模型搭建.
qquad 这里的target真实标签来自于datasets.py数据增强后返回的真是标签 [num_object, 6],如果对这部分不是很熟悉的可以看我的另一篇博客【YOLO-V3-SPP 源码解读】四、数据载入(数据增强).
qquad 好了,有了上面的前提知识,就可以现在开始正式讲解损失函数部分,这部分是属于训练的后处理部分,其实也是整个训练过程中最重要(最难)的一部分,希望大家都能掌握(必须掌握)。
qquad
对损失函数没什么概念的可以先看下这个计算损失函数 compute_loss 流程图:
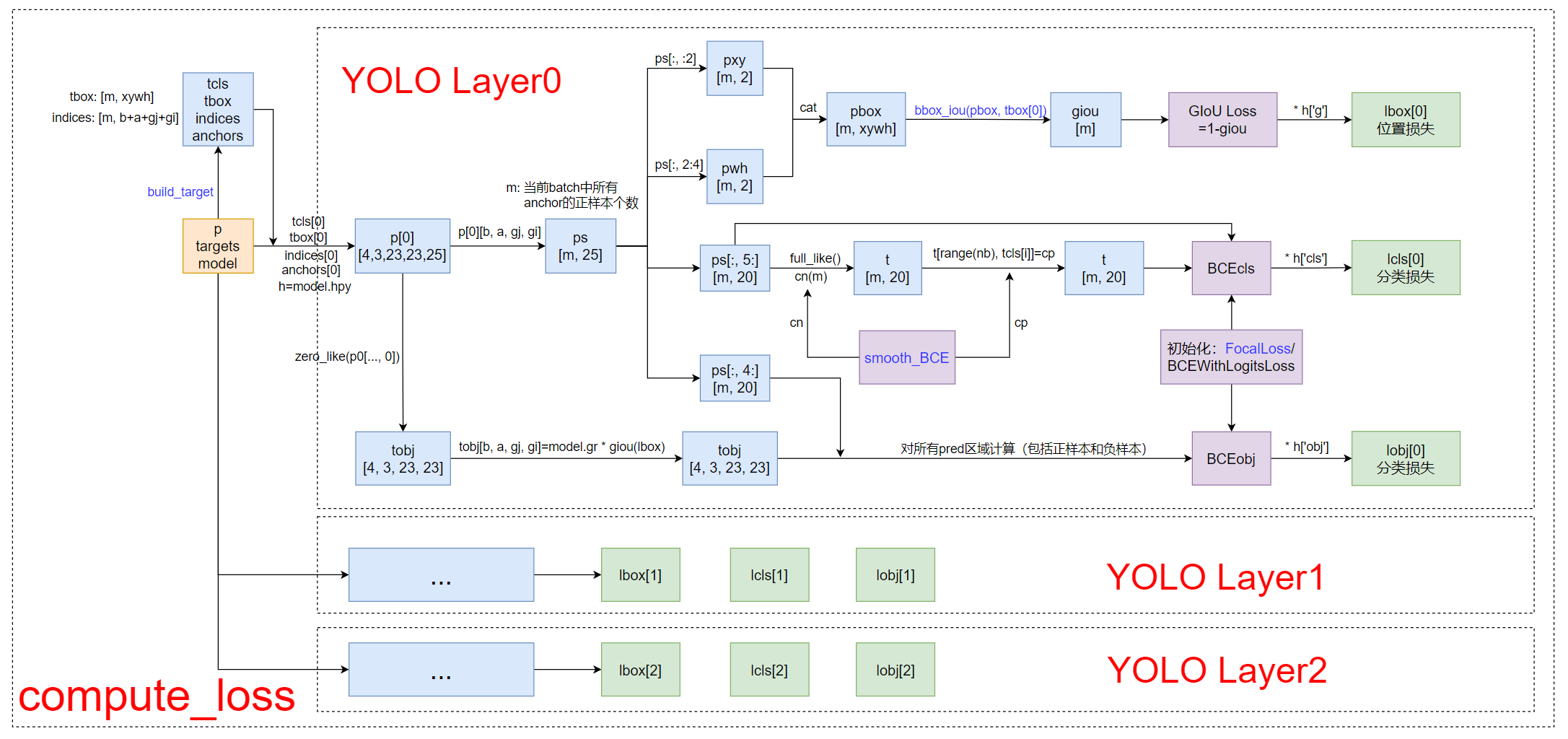
再看下面的代码会简单很多,我都打了注释的。
def compute_loss(p, targets, model):
"""
计算损失:所有anchor的正样本的损失
Args:
p: predictions 预测框 由模型构建中的yolo_out返回的三个yolo层的输出
tensor格式 list列表 存放三个tensor 对应的是三个yolo层的输出
例如:[4, 3, 23, 23, 25] [4, 3, 46, 46, 25] [4, 3, 96, 96, 25]
[batch_size, anchor_num, grid, grid, xywh + obj + classes]
可以看出来这里的预测值是三个yolo层每个grid_cell(每个grid_cell有三个预测值)的预测值,后面肯定要进行正样本筛选
targets: 数据增强后的真实框 [21, 6] 21: num_object 6: batch中第几张图(0,1,2,3)+类别+x+y+w+h真实框 [22, 6]
model: 初始化模型
Returns: lbox: 位置损失 tensor([1])
obj_loss: 置信度损失 tensor([1])
class_loss: 分类损失 tensor([1])
"""
device = p[0].device
lcls = torch.zeros(1, device=device) # Tensor([0.])
lbox = torch.zeros(1, device=device) # Tensor([0.])
lobj = torch.zeros(1, device=device) # Tensor([0.])
'''
Build targets for compute_loss(), input targets(image,class,x,y,w,h)
tbox: append [m(正样本个数), x偏移量(中心点坐标相对中心所在grid_cell左上角的偏移量) + y偏移量 + w + h]
存放着当前batch中所有anchor的正样本 某个anchor的正样本指的是当前的target由这个anchor预测
另外,同一个target可能由多个anchor预测,所以通常 m>nt
indices: append [m(正样本个数), b + a + gj + gi]
b: 和tbox一一对应 存放着tbox中对应位置的target(第a个anchor的正样本)属于这个batch中的哪一张图片
a: 和tbox一一对应 存放着tbox中对应位置的target是属于哪个anchor(index)的正样本(由哪个anchor负责预测)
gj: 和tbox一一对应 存放着tbox中对应位置的target的中心点所在grid_cell的左上角的y坐标(真实框的x的整数部分)
gi: 和tbox一一对应 存放着tbox中对应位置的target(第a个anchor的正样本)的中心点所在grid_cell的左上角的x坐标(真实框的y的整数部分)
tcls: append [m] 和tbox一一对应 存放着tbox中对应位置的target(第a个anchor的正样本)所属的类别
anch: append [m, 2] 和tbox一一对应 存放着tbox中对应位置的target是属于哪个anchor(shape)的正样本(由哪个anchor负责预测)
'''
tcls, tbox, indices, anchors = build_targets(p, targets, model) # targets 得到所有anchor的正样本
h = model.hyp # hyperparameters
red = 'mean' # Loss reduction (sum or mean)
# 初始化交叉熵损失函数:分类损失BCEcls 置信度BCEobj 如果不用Focal loss就用BCEWithLogitsLoss
# BCEWithLogitsLoss = Sigmoid-BCELoss合成一步 先用对output进行sigmoid再对output和target进行交叉熵
# pos_weight: 用于设置损失的class权重,用于缓解样本的不均衡问题
# reduction: 设为"sum"表示对样本进行求损失和;设为"mean"表示对样本进行求损失的平均值;而设为"none"表示对样本逐个求损失,输出与输入的shape一样。
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device), reduction=red)
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device), reduction=red)
# class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
# 标签平滑 cp: positive label smoothing BCE targets cn: negative label smoothing BCE targets
cp, cn = smooth_BCE(eps=0) # 平滑系数eps=0说明不采用标签平滑 要用通常为0.1
# focal loss 这里暂时没用到 一般是用到分类损失中
g = h['fl_gamma'] # focal loss gamma hpy中g默认=0
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
# 遍历每一个yolo层输出
nt = 0 # targets
# layer index(0,1,2), layer predictions [[batch_size, anchor_num, grid, grid, xywh + obj + classes]]
for i, pi in enumerate(p): # pi为第i层yolo层输出 [4,3,23,23,25]
# 获得每一层的所有正样本(三个anchor)信息
# b: 和tbox一一对应 存放着tbox中对应位置的target(第a个anchor的正样本)属于这个batch中的哪一张图片
# a: 和tbox一一对应 存放着tbox中对应位置的target是属于哪个anchor(index)的正样本(由哪个anchor负责预测)
# gj: 和tbox一一对应 存放着tbox中对应位置的target的中心点所在grid_cell的左上角的y坐标
# gi: 和tbox一一对应 存放着tbox中对应位置的target(第a个anchor的正样本)的中心点所在grid_cell的左上角的x坐标
b, a, gj, gi = indices[i]
tobj = torch.zeros_like(pi[..., 0], device=device) # 所有的target obj [4,3,23,23]
nb = b.shape[0] # target中的m 所有anchor的正样本数 并不是真实框的个数,应该大于真实框的个数,因为一个真实框可能在多个anchor中预测
if nb:
# 对应匹配到正样本的预测信息
# pi=[batch_size, anchor_num, grid, grid, xywh + obj + classes]
# ps=[m, xywh + obj + classes] 其中m是正样本的个数 其实对应的就是在target中所有正样本的个数
# ps其实就是拿到在预测信息pi中的 相对target所有正样本位置 的值 之后方便作损失计算
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets [30,25]
# lbox: 位置损失 GIoU Loss
pxy = ps[:, :2].sigmoid()
pwh = ps[:, 2:4].exp().clamp(max=1E3) * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
giou = bbox_iou(pbox.t(), tbox[i], x1y1x2y2=False, GIoU=True) # giou(prediction, target)
lbox += (1.0 - giou).mean() if red == "mean" else (1.0 - giou).sum() # giou loss
# obj model.gr=1 置为giou(有物体的地方,置信度为giou) model.gr在train.py中定义
# model.gr: giou loss ratio (obj_loss = 1.0 or giou)
# model.gr=1 obj_loss=giou; model.gr=0, obj_loss=1
tobj[b, a, gj, gi] = (1.0 - model.gr) + model.gr * giou.detach().clamp(0).type(tobj.dtype) # giou 公式
# lcls: 所有正样本的分类损失
if model.nc > 1: # cls loss (only if multiple classes)
# cn: negative label(label smooth中的负样本值) [m, 20] 全是cn
t = torch.full_like(ps[:, 5:], cn, device=device) # targets
# nb: m tcls[i]: 真实框的类别位置 cp: positive label(label smooth中的正样本值)
# 真实框的类别对应的位置就置为cp 其他类别位置就置为cn
t[range(nb), tcls[i]] = cp
# BCE class loss 如果打开focal loss ,这里会调用focal loss
lcls += BCEcls(ps[:, 5:], t)
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + 'n') for x in torch.cat((txy[i], twh[i]), 1)]
# lobj: 置信度损失(有无物体) lobj是对所有prediction区域计算的 即包括正样本也包括负样本
# 这样训练才能让负样本处预测值接近0,正样本处预测值接近1
lobj += BCEobj(pi[..., 4], tobj) # obj loss
# 乘上每种损失的对应权重
# 因为目标检测主要的loss来自位置损失,所有给lbox乘一个较小的权重 平衡各个损失,防止损失函数被个别损失掌控
lbox *= h['giou'] # 3.54
lobj *= h['obj'] # 102.88
lcls *= h['cls'] # 9.35
# loss = lbox + lobj + lcls
return {"box_loss": lbox,
"obj_loss": lobj,
"class_loss": lcls}
6.1、smooth_BCE
def smooth_BCE(eps=0.1):
# https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
# eps 平滑系数 [0, 1] => [0.95, 0.05]
# return positive, negative label smoothing BCE targets
# positive label= y_true * (1.0 - label_smoothing) + 0.5 * label_smoothing
# y_true=1 label_smoothing=eps=0.1
return 1.0 - 0.5 * eps, 0.5 * eps
qquad 对上面代码smooth_BCE(label smooth标签平滑策略)不是很清楚的,可以看看我的另一篇文章:【trick 1】Label Smoothing(标签平滑)—— 分类问题中错误标注的一种解决方法.
6.2、bbox_iou
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False):
"""
Args:
box1: 预测框
box2: 真实框
x1y1x2y2: False
Returns:
box1和box2的IoU/GIoU/DIoU/CIoU
"""
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
box2 = box2.t() # 转置 ???
# Get the coordinates of bounding boxes
if x1y1x2y2: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else: # transform from xywh to xyxy
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2 # b1左上角和右下角的x坐标
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2 # b1左下角和右下角的y坐标
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2 # b2左上角和右下角的x坐标
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2 # b2左下角和右下角的y坐标
# Intersection area tensor.clamp(0): 将矩阵中小于0的元数变成0
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) *
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1
union = (w1 * h1 + 1e-16) + w2 * h2 - inter # 1e-16: 防止分母为0
iou = inter / union # iou
if GIoU or DIoU or CIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # 两个框的最小闭包区域的width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # 两个框的最小闭包区域的height
if GIoU: # Generalized IoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + 1e-16 # convex area
return iou - (c_area - union) / c_area # return GIoU
if DIoU or CIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
# convex diagonal squared
c2 = cw ** 2 + ch ** 2 + 1e-16
# centerpoint distance squared
rho2 = ((b2_x1 + b2_x2) - (b1_x1 + b1_x2)) ** 2 / 4 + ((b2_y1 + b2_y2) - (b1_y1 + b1_y2)) ** 2 / 4 # 中心点距离 d^2
if DIoU:
return iou - rho2 / c2 # DIoU
elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (1 - iou + v)
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou
qquad 对上面代码bbox_iou(IoU/GIoU/DIoU/CIoU)不是很清楚的,可以看看我的另一篇文章:【trick 3】Bounding Box regression loss: IoU Loss、GIoU Loss、DIoU Loss、CIoU Loss.
而剩下代码的难点主要集中在以下两个函数:
6.3、build_target
qquad
这个函数其实是在为YOLO Layer输出的3个feature map对应的每个anchor筛选正样本。
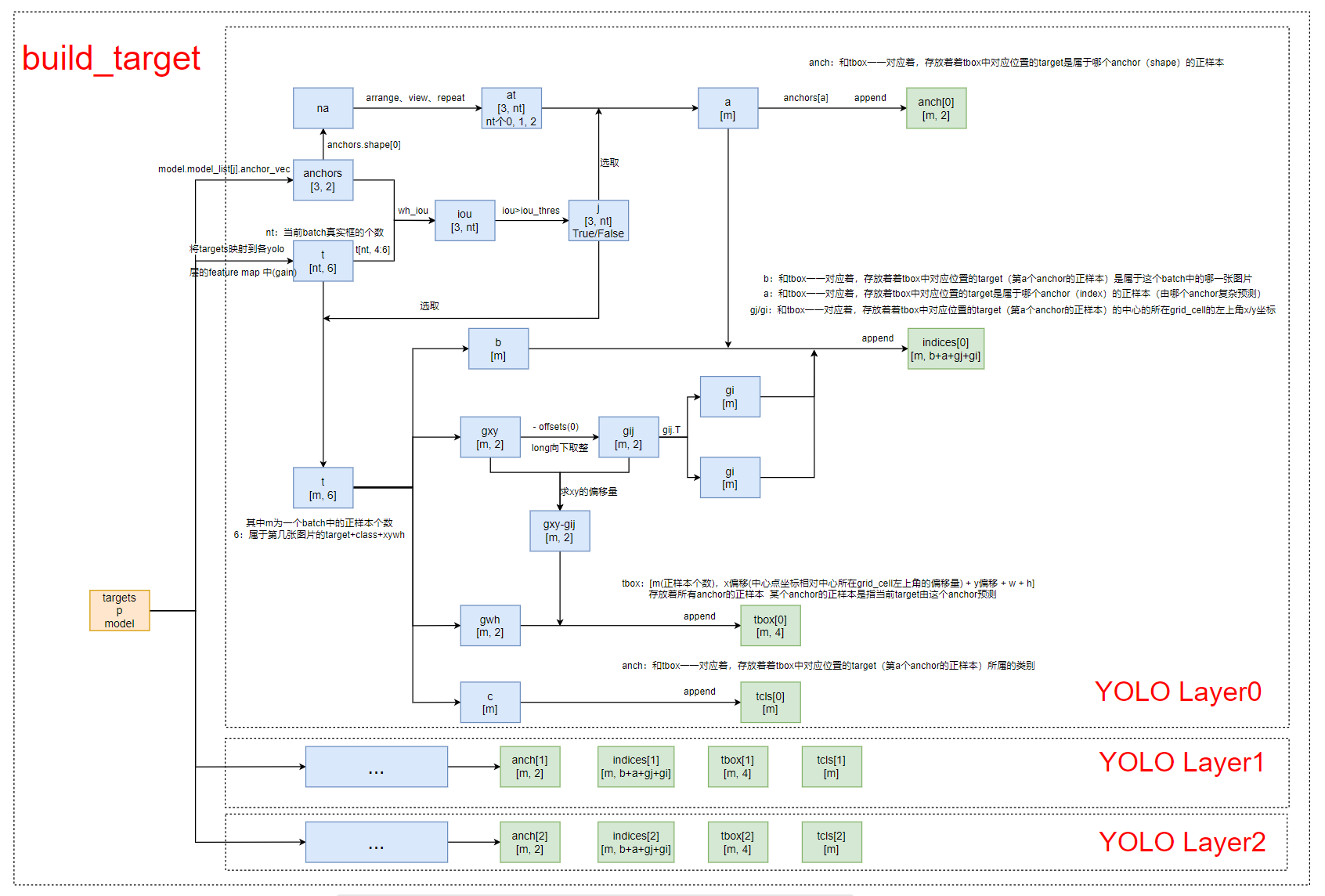
def build_targets(p, targets, model):
"""
Build targets for compute_loss(), input targets(image,class,x,y,w,h)
:param p: 预测框 由模型构建中的yolo_out返回的三个yolo层的输出
tensor格式 list列表 存放三个tensor 对应的是三个yolo层的输出
例如:[4, 3, 23, 23, 25] [4, 3, 46, 46, 25] [4, 3, 96, 96, 25] (736x736尺度下)
[batch_size, anchor_num, grid, grid, xywh + obj + classes]
p[i].shape
:param targets: 数据增强后一个batch的真实框 [21, 6] 21: num_object 6: batch中第几张图(0,1,2,3)+类别+x+y+w+h真实框
:param model: 初始化的模型
:return: tbox: append [m(正样本个数), x偏移量(中心点坐标相对中心所在grid_cell左上角的偏移量) + y偏移量 + w + h]
存放着当前batch中所有anchor的正样本 某个anchor的正样本指的是当前的target由这个anchor预测
另外,同一个target可能由多个anchor预测,所以通常 m>nt
indices: append [m(正样本个数), b + a + gj + gi]
b: 和tbox一一对应 存放着tbox中对应位置的target(第a个anchor的正样本)属于这个batch中的哪一张图片
a: 和tbox一一对应 存放着tbox中对应位置的target是属于哪个anchor(index)的正样本(由哪个anchor负责预测)
gj: 和tbox一一对应 存放着tbox中对应位置的target的中心点所在grid_cell的左上角的y坐标
gi: 和tbox一一对应 存放着tbox中对应位置的target(第a个anchor的正样本)的中心点所在grid_cell的左上角的x坐标
tcls: append [m] 和tbox一一对应 存放着tbox中对应位置的target(第a个anchor的正样本)所属的类别
anch: append [m, 2] 和tbox一一对应 存放着tbox中对应位置的target是属于哪个anchor(shape)的正样本(由哪个anchor负责预测)
"""
nt = targets.shape[0] # 当前batch真实框的数量 num of target
# 定义一些变量
# anch append [m, 2] 和tbox一一对应 存放着对应位置的target是属于哪个anchor(shape)的正样本(由哪个anchor负责预测)
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(6, device=targets.device) # normalized to gridspace gain tensor([1,1,1,1,1,1])
multi_gpu = type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel) # 一般False
for i, j in enumerate(model.yolo_layers): # [89, 101, 113] i,j = 0, 89 1, 101 2, 113
# 获取该yolo predictor对应的anchors的大小,不过这里是缩放到feature map上的 shape=[3, 2]
# 而且它就是cfg文件中的anchors除以了缩放比例stride得到的
# 比如:[3.6250, 2.8125] / 13 * 416 (缩放比例为32)= [116,90] 等于cfg文件中的anchor的大小
anchors = model.module.module_list[j].anchor_vec if multi_gpu else model.module_list[j].anchor_vec
# gain中存放的是feature map的尺寸信息
# 在原图尺度为(736,736)情况下 p[0]=[4,3,23,23,25] p[1]=[4,3,46,46,25] p[2]=[4,3,92,92,25]
# 如原图(736x736) gain=Tensor([1,1,23,23,23,23]) 或 Tensor([1,1,46,46,46,46]) 或 Tensor([1,1,92,92,92,92])
gain[2:] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
na = anchors.shape[0] # number of anchors 3个
# [3] -> [3, 1] -> [3, nt]
# anchor tensor, same as .repeat_interleave(nt) at.shape=[3,21] 21个0, 1, 2
at = torch.arange(na).view(na, 1).repeat(1, nt)
# Match targets to anchors
# t = targets * gain: 将box坐标(在box标签生成中,对box坐标进行了归一化,即除以图像的宽高)转换到当前yolo层输出的特征图上
# 通过将归一化的box乘以特征图尺度,从而将box坐标投影到特征图上
# 广播原理 targets=[21,6] gain=[6] => gain=[6,6] => t=[21,6]
a, t, offsets = [], targets * gain, 0
if nt: # 如果存在target的话
# 把yolo层的anchor在该feature map上对应的wh(anchors)和所有预测真实框在该feature map上对应的wh(t[4:6])做iou,
# 若大于model.hyp['iou_t']=0.2, 则为正样本保留,否则则为负样本舍弃
# anchors: [3, 2]: 当前yolO层的三个anchor(且都是相对416x416的, 不过初始框的wh多大都可以,反正最后都是做回归)
# t[:, 4:6]: [nt, 2]: 所有target真是框的w和h, 且都是相对当前feature map的
# j: [3, nt]
j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n) = wh_iou(anchors(3,2), gwh(n,2))
# t.repeat(na, 1, 1): [nt, 6] -> [3, nt, 6]
# 获取iou大于阈值的anchor与target对应信息
# a=tensor[30]: anchor_index(0、1、2) 0表示是属于第一个anchor(包含4张图片)的正样本 同理第二。。。
# 再解释下什么是正样本: 表示当前target可以由第i个anchor检测,就表示当前target是这个anchor的正样本
# t=tensor[30,6]: 第0、1、2、3(4张图片)的target, class, x, y, w, h(相对于当前feature map尺度)
# 与a变量一一对应,a用来指示t中相对应的位置的target是属于哪一个anchor的正样本
# 注意:这里的同一个target是可能会同属于多个anchor的正样本的,由多个anchor计算同一个target
# 不然t个数也不会大于正样本数(30>21)
a, t = at[j], t.repeat(na, 1, 1)[j] # filter 选出所有anchor对应属于它们的正样本
# Define
# b: 对应图片的index 即当前target是属于哪张图片的
# c: 当前target是属于哪个类
# long等于to(torch.int64), 数值向下取整 这里都是整数,long()只起到了float->int的作用
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy 对应于当前feature map的target的xy坐标
gwh = t[:, 4:6] # grid wh 对应于当前feature map的target的wh坐标
# 匹配targets所在的grid cell左上角坐标
# (gxy-0).long 向下取整 得到当前target的中心点所在左上角的坐标
gij = (gxy - offsets).long()
# grid xy indices 左上角x, y坐标
gi, gj = gij.T
# Append
indices.append((b, a, gj, gi)) # image index, anchor, grid indices(x, y)
tbox.append(torch.cat((gxy - gij, gwh), 1)) # gt box相对当前feature map的x,y偏移量以及w,h
anch.append(anchors[a]) # anchors
tcls.append(c) # class
if c.shape[0]: # if any targets
# 目标的标签数值不能大于给定的目标类别数
assert c.max() < model.nc, 'Model accepts %g classes labeled from 0-%g, however you labelled a class %g. '
'See https://github.com/ultralytics/yolov3/wiki/Train-Custom-Data' % (
model.nc, model.nc - 1, c.max())
return tcls, tbox, indices, anch
def wh_iou(wh1, wh2):
"""
把yolo层的anchor在该feature map上对应的wh(anchors)和所有预测真实框在该feature map上对应的wh(t[4:6])做iou,
若大于model.hyp['iou_t']=0.2, 则为正样本保留,否则则为负样本舍弃 筛选出符合该yolo层对应的正样本
Args:
wh1: anchors [3, 2]
wh2: target [22,2]
Returns:
wh1 和 wh2 的iou [3, 22]
"""
# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
wh1 = wh1[:, None] # [N,1,2] [3, 1, 2]
wh2 = wh2[None] # [1,M,2] [1, 22, 2]
inter = torch.min(wh1, wh2).prod(2) # [N,M] [3, 22]
return inter / (wh1.prod(2) + wh2.prod(2) - inter) # iou = inter / (area1 + area2 - inter)
6.4、FocalLoss
qquad 关于FocalLoss理论(公式)不是很清楚的,可以看看我的另一个博文: 【trick 4】Focus Loss —— 解决one-stage目标检测中正负样本不均衡的问题.
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=2, alpha=0.25):
super(FocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma # 参数gamma
self.alpha = alpha # 参数alpha
# reduction: 控制损失输出模式 sum/mean/none 这里定义的交叉熵损失BCE都是mean
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # 不知道这句有什么用? required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true) # 普通BCE Loss
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # 如果模型最后没有 nn.Sigmoid(),那么这里就需要对预测结果计算一次 Sigmoid 操作 prob from logits
# ture=0,p_t=1-p; true=1, p_t=p
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
# ture=0, alpha_factor=1-alpha; true=1,alpha_factor=alpha
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
# loss = focus loss(代入公式即可)
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean': # 一般是mean
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
其他文件
这部分文件都是一些工具类的文件,和训练本身并没有太多关心,会掉包就行了。所以,可看可不看
coco_eval.py
import json
import copy
from collections import defaultdict
import numpy as np
import torch
import torch._six
from pycocotools.cocoeval import COCOeval
from pycocotools.coco import COCO
import pycocotools.mask as mask_util
from train_val_utils.distributed_utils import all_gather
class CocoEvaluator(object):
def __init__(self, coco_gt, iou_types):
assert isinstance(iou_types, (list, tuple))
coco_gt = copy.deepcopy(coco_gt)
self.coco_gt = coco_gt
self.iou_types = iou_types
self.coco_eval = {}
for iou_type in iou_types:
self.coco_eval[iou_type] = COCOeval(coco_gt, iouType=iou_type)
self.img_ids = []
self.eval_imgs = {k: [] for k in iou_types}
def update(self, predictions):
img_ids = list(np.unique(list(predictions.keys())))
self.img_ids.extend(img_ids)
for iou_type in self.iou_types:
results = self.prepare(predictions, iou_type)
coco_dt = loadRes(self.coco_gt, results) if results else COCO()
coco_eval = self.coco_eval[iou_type]
coco_eval.cocoDt = coco_dt
coco_eval.params.imgIds = list(img_ids)
img_ids, eval_imgs = evaluate(coco_eval)
self.eval_imgs[iou_type].append(eval_imgs)
def synchronize_between_processes(self):
for iou_type in self.iou_types:
self.eval_imgs[iou_type] = np.concatenate(self.eval_imgs[iou_type], 2)
create_common_coco_eval(self.coco_eval[iou_type], self.img_ids, self.eval_imgs[iou_type])
def accumulate(self):
for coco_eval in self.coco_eval.values():
coco_eval.accumulate()
def summarize(self):
for iou_type, coco_eval in self.coco_eval.items():
print("IoU metric: {}".format(iou_type))
coco_eval.summarize()
def prepare(self, predictions, iou_type):
if iou_type == "bbox":
return self.prepare_for_coco_detection(predictions)
elif iou_type == "segm":
return self.prepare_for_coco_segmentation(predictions)
elif iou_type == "keypoints":
return self.prepare_for_coco_keypoint(predictions)
else:
raise ValueError("Unknown iou type {}".format(iou_type))
def prepare_for_coco_detection(self, predictions):
coco_results = []
for original_id, prediction in predictions.items():
if len(prediction) == 0:
continue
boxes = prediction["boxes"]
boxes = convert_to_xywh(boxes).tolist()
scores = prediction["scores"].tolist()
labels = prediction["labels"].tolist()
coco_results.extend(
[
{
"image_id": original_id,
"category_id": labels[k],
"bbox": box,
"score": scores[k],
}
for k, box in enumerate(boxes)
]
)
return coco_results
def prepare_for_coco_segmentation(self, predictions):
coco_results = []
for original_id, prediction in predictions.items():
if len(prediction) == 0:
continue
scores = prediction["scores"]
labels = prediction["labels"]
masks = prediction["masks"]
masks = masks > 0.5
scores = prediction["scores"].tolist()
labels = prediction["labels"].tolist()
rles = [
mask_util.encode(np.array(mask[0, :, :, np.newaxis], dtype=np.uint8, order="F"))[0]
for mask in masks
]
for rle in rles:
rle["counts"] = rle["counts"].decode("utf-8")
coco_results.extend(
[
{
"image_id": original_id,
"category_id": labels[k],
"segmentation": rle,
"score": scores[k],
}
for k, rle in enumerate(rles)
]
)
return coco_results
def prepare_for_coco_keypoint(self, predictions):
coco_results = []
for original_id, prediction in predictions.items():
if len(prediction) == 0:
continue
boxes = prediction["boxes"]
boxes = convert_to_xywh(boxes).tolist()
scores = prediction["scores"].tolist()
labels = prediction["labels"].tolist()
keypoints = prediction["keypoints"]
keypoints = keypoints.flatten(start_dim=1).tolist()
coco_results.extend(
[
{
"image_id": original_id,
"category_id": labels[k],
'keypoints': keypoint,
"score": scores[k],
}
for k, keypoint in enumerate(keypoints)
]
)
return coco_results
def convert_to_xywh(boxes):
xmin, ymin, xmax, ymax = boxes.unbind(1)
return torch.stack((xmin, ymin, xmax - xmin, ymax - ymin), dim=1)
def merge(img_ids, eval_imgs):
all_img_ids = all_gather(img_ids)
all_eval_imgs = all_gather(eval_imgs)
merged_img_ids = []
for p in all_img_ids:
merged_img_ids.extend(p)
merged_eval_imgs = []
for p in all_eval_imgs:
merged_eval_imgs.append(p)
merged_img_ids = np.array(merged_img_ids)
merged_eval_imgs = np.concatenate(merged_eval_imgs, 2)
# keep only unique (and in sorted order) images
merged_img_ids, idx = np.unique(merged_img_ids, return_index=True)
merged_eval_imgs = merged_eval_imgs[..., idx]
return merged_img_ids, merged_eval_imgs
def create_common_coco_eval(coco_eval, img_ids, eval_imgs):
img_ids, eval_imgs = merge(img_ids, eval_imgs)
img_ids = list(img_ids)
eval_imgs = list(eval_imgs.flatten())
coco_eval.evalImgs = eval_imgs
coco_eval.params.imgIds = img_ids
coco_eval._paramsEval = copy.deepcopy(coco_eval.params)
#################################################################
# From pycocotools, just removed the prints and fixed
# a Python3 bug about unicode not defined
#################################################################
# Ideally, pycocotools wouldn't have hard-coded prints
# so that we could avoid copy-pasting those two functions
def createIndex(self):
# create index
# print('creating index...')
anns, cats, imgs = {}, {}, {}
imgToAnns, catToImgs = defaultdict(list), defaultdict(list)
if 'annotations' in self.dataset:
for ann in self.dataset['annotations']:
imgToAnns[ann['image_id']].append(ann)
anns[ann['id']] = ann
if 'images' in self.dataset:
for img in self.dataset['images']:
imgs[img['id']] = img
if 'categories' in self.dataset:
for cat in self.dataset['categories']:
cats[cat['id']] = cat
if 'annotations' in self.dataset and 'categories' in self.dataset:
for ann in self.dataset['annotations']:
catToImgs[ann['category_id']].append(ann['image_id'])
# print('index created!')
# create class members
self.anns = anns
self.imgToAnns = imgToAnns
self.catToImgs = catToImgs
self.imgs = imgs
self.cats = cats
maskUtils = mask_util
def loadRes(self, resFile):
"""
Load result file and return a result api object.
:param resFile (str) : file name of result file
:return: res (obj) : result api object
"""
res = COCO()
res.dataset['images'] = [img for img in self.dataset['images']]
# print('Loading and preparing results...')
# tic = time.time()
if isinstance(resFile, torch._six.string_classes):
anns = json.load(open(resFile))
elif type(resFile) == np.ndarray:
anns = self.loadNumpyAnnotations(resFile)
else:
anns = resFile
assert type(anns) == list, 'results in not an array of objects'
annsImgIds = [ann['image_id'] for ann in anns]
assert set(annsImgIds) == (set(annsImgIds) & set(self.getImgIds())),
'Results do not correspond to current coco set'
if 'caption' in anns[0]:
imgIds = set([img['id'] for img in res.dataset['images']]) & set([ann['image_id'] for ann in anns])
res.dataset['images'] = [img for img in res.dataset['images'] if img['id'] in imgIds]
for id, ann in enumerate(anns):
ann['id'] = id + 1
elif 'bbox' in anns[0] and not anns[0]['bbox'] == []:
res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])
for id, ann in enumerate(anns):
bb = ann['bbox']
x1, x2, y1, y2 = [bb[0], bb[0] + bb[2], bb[1], bb[1] + bb[3]]
if 'segmentation' not in ann:
ann['segmentation'] = [[x1, y1, x1, y2, x2, y2, x2, y1]]
ann['area'] = bb[2] * bb[3]
ann['id'] = id + 1
ann['iscrowd'] = 0
elif 'segmentation' in anns[0]:
res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])
for id, ann in enumerate(anns):
# now only support compressed RLE format as segmentation results
ann['area'] = maskUtils.area(ann['segmentation'])
if 'bbox' not in ann:
ann['bbox'] = maskUtils.toBbox(ann['segmentation'])
ann['id'] = id + 1
ann['iscrowd'] = 0
elif 'keypoints' in anns[0]:
res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])
for id, ann in enumerate(anns):
s = ann['keypoints']
x = s[0::3]
y = s[1::3]
x1, x2, y1, y2 = np.min(x), np.max(x), np.min(y), np.max(y)
ann['area'] = (x2 - x1) * (y2 - y1)
ann['id'] = id + 1
ann['bbox'] = [x1, y1, x2 - x1, y2 - y1]
# print('DONE (t={:0.2f}s)'.format(time.time()- tic))
res.dataset['annotations'] = anns
createIndex(res)
return res
def evaluate(self):
'''
Run per image evaluation on given images and store results (a list of dict) in self.evalImgs
:return: None
'''
# tic = time.time()
# print('Running per image evaluation...')
p = self.params
# add backward compatibility if useSegm is specified in params
if p.useSegm is not None:
p.iouType = 'segm' if p.useSegm == 1 else 'bbox'
print('useSegm (deprecated) is not None. Running {} evaluation'.format(p.iouType))
# print('Evaluate annotation type *{}*'.format(p.iouType))
p.imgIds = list(np.unique(p.imgIds))
if p.useCats:
p.catIds = list(np.unique(p.catIds))
p.maxDets = sorted(p.maxDets)
self.params = p
self._prepare()
# loop through images, area range, max detection number
catIds = p.catIds if p.useCats else [-1]
if p.iouType == 'segm' or p.iouType == 'bbox':
computeIoU = self.computeIoU
elif p.iouType == 'keypoints':
computeIoU = self.computeOks
self.ious = {
(imgId, catId): computeIoU(imgId, catId)
for imgId in p.imgIds
for catId in catIds}
evaluateImg = self.evaluateImg
maxDet = p.maxDets[-1]
evalImgs = [
evaluateImg(imgId, catId, areaRng, maxDet)
for catId in catIds
for areaRng in p.areaRng
for imgId in p.imgIds
]
# this is NOT in the pycocotools code, but could be done outside
evalImgs = np.asarray(evalImgs).reshape(len(catIds), len(p.areaRng), len(p.imgIds))
self._paramsEval = copy.deepcopy(self.params)
# toc = time.time()
# print('DONE (t={:0.2f}s).'.format(toc-tic))
return p.imgIds, evalImgs
#################################################################
# end of straight copy from pycocotools, just removing the prints
#################################################################
coco_utils.py
from tqdm import tqdm
import torch
import torchvision
import torch.utils.data
from pycocotools.coco import COCO
def convert_to_coco_api(ds):
coco_ds = COCO()
# annotation IDs need to start at 1, not 0
ann_id = 1
dataset = {'images': [], 'categories': [], 'annotations': []}
categories = set()
# 遍历dataset中的每张图像
for img_idx in tqdm(range(len(ds)), desc="loading eval info for coco tools."):
# find better way to get target
targets, shapes = ds.coco_index(img_idx)
# targets: [num_obj, 6] , that number 6 means -> (img_index, obj_index, x, y, w, h)
img_dict = {}
img_dict['id'] = img_idx
img_dict['height'] = shapes[0]
img_dict['width'] = shapes[1]
dataset['images'].append(img_dict)
for obj in targets:
ann = {}
ann["image_id"] = img_idx
# 将相对坐标转为绝对坐标
# box (x, y, w, h)
boxes = obj[1:]
# (x, y, w, h) to (xmin, ymin, w, h)
boxes[:2] -= 0.5*boxes[2:]
boxes[[0, 2]] *= img_dict["width"]
boxes[[1, 3]] *= img_dict["height"]
boxes = boxes.tolist()
ann["bbox"] = boxes
ann["category_id"] = int(obj[0])
categories.add(int(obj[0]))
ann["area"] = boxes[2] * boxes[3]
ann["iscrowd"] = 0
ann["id"] = ann_id
dataset["annotations"].append(ann)
ann_id += 1
dataset['categories'] = [{'id': i} for i in sorted(categories)]
coco_ds.dataset = dataset
coco_ds.createIndex()
return coco_ds
def get_coco_api_from_dataset(dataset):
for _ in range(10):
if isinstance(dataset, torchvision.datasets.CocoDetection):
break
if isinstance(dataset, torch.utils.data.Subset):
dataset = dataset.dataset
if isinstance(dataset, torchvision.datasets.CocoDetection):
return dataset.coco
return convert_to_coco_api(dataset)
distributed_utils.py
from collections import defaultdict, deque
import datetime
import pickle
import time
import torch
import torch.distributed as dist
# 分布式训练部分代码
def all_gather(data):
"""
Run all_gather on arbitrary picklable data (not necessarily tensors)
Args:
data: any picklable object
Returns:
list[data]: list of data gathered from each rank
"""
world_size = get_world_size()
if world_size == 1:
return [data]
# serialized to a Tensor
buffer = pickle.dumps(data)
storage = torch.ByteStorage.from_buffer(buffer)
tensor = torch.ByteTensor(storage).to("cuda")
# obtain Tensor size of each rank
local_size = torch.tensor([tensor.numel()], device="cuda")
size_list = [torch.tensor([0], device="cuda") for _ in range(world_size)]
dist.all_gather(size_list, local_size)
size_list = [int(size.item()) for size in size_list]
max_size = max(size_list)
# receiving Tensor from all ranks
# we pad the tensor because torch all_gather does not support
# gathering tensors of different shapes
tensor_list = []
for _ in size_list:
tensor_list.append(torch.empty((max_size,), dtype=torch.uint8, device="cuda"))
if local_size != max_size:
padding = torch.empty(size=(max_size - local_size,), dtype=torch.uint8, device="cuda")
tensor = torch.cat((tensor, padding), dim=0)
dist.all_gather(tensor_list, tensor)
data_list = []
for size, tensor in zip(size_list, tensor_list):
buffer = tensor.cpu().numpy().tobytes()[:size]
data_list.append(pickle.loads(buffer))
return data_list
def get_world_size():
if not is_dist_avail_and_initialized(): # 不支持分布式环境
return 1
return dist.get_world_size()
def is_dist_avail_and_initialized():
"""检查是否支持分布式环境"""
if not dist.is_available():
return False
if not dist.is_initialized():
return False
return True
class MetricLogger(object):
def __init__(self, delimiter="t"):
self.meters = defaultdict(SmoothedValue)
self.delimiter = delimiter
def update(self, **kwargs):
for k, v in kwargs.items():
if isinstance(v, torch.Tensor):
v = v.item()
assert isinstance(v, (float, int))
self.meters[k].update(v)
def __getattr__(self, attr):
if attr in self.meters:
return self.meters[attr]
if attr in self.__dict__:
return self.__dict__[attr]
raise AttributeError("'{}' object has no attribute '{}'".format(
type(self).__name__, attr))
def __str__(self):
loss_str = []
for name, meter in self.meters.items():
loss_str.append(
"{}: {}".format(name, str(meter))
)
return self.delimiter.join(loss_str)
def synchronize_between_processes(self):
for meter in self.meters.values():
meter.synchronize_between_processes()
def add_meter(self, name, meter):
self.meters[name] = meter
def log_every(self, iterable, print_freq, header=None):
i = 0
if not header:
header = ""
start_time = time.time()
end = time.time()
iter_time = SmoothedValue(fmt='{avg:.4f}')
data_time = SmoothedValue(fmt='{avg:.4f}')
space_fmt = ":" + str(len(str(len(iterable)))) + "d"
if torch.cuda.is_available():
log_msg = self.delimiter.join([header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}',
'max mem: {memory:.0f}'])
else:
log_msg = self.delimiter.join([header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}'])
MB = 1024.0 * 1024.0
# 这里进入dataset中的getitem函数
for obj in iterable:
data_time.update(time.time() - end)
yield obj # 进入forward
iter_time.update(time.time() - end)
if i % print_freq == 0 or i == len(iterable) - 1:
eta_second = iter_time.global_avg * (len(iterable) - i)
eta_string = str(datetime.timedelta(seconds=eta_second))
if torch.cuda.is_available():
print(log_msg.format(i, len(iterable),
eta=eta_string,
meters=str(self),
time=str(iter_time),
data=str(data_time),
memory=torch.cuda.max_memory_allocated() / MB))
else:
print(log_msg.format(i, len(iterable),
eta=eta_string,
meters=str(self),
time=str(iter_time),
data=str(data_time)))
i += 1
end = time.time()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('{} Total time: {} ({:.4f} s / it)'.format(header,
total_time_str,
total_time / len(iterable)))
class SmoothedValue(object):
"""Track a series of values and provide access to smoothed values over a
window or the global series average.
"""
def __init__(self, window_size=20, fmt=None):
if fmt is None:
fmt = "{median:.4f} ({global_avg:.4f})"
self.deque = deque(maxlen=window_size) # deque简单理解成加强版list
self.total = 0.0
self.count = 0
self.fmt = fmt
def update(self, value, n=1):
self.deque.append(value)
self.count += n
self.total += value * n
def synchronize_between_processes(self):
"""
Warning: does not synchronize the deque!
"""
if not is_dist_avail_and_initialized():
return
t = torch.tensor([self.count, self.total], dtype=torch.float64, device="cuda")
dist.barrier()
dist.all_reduce(t)
t = t.tolist()
self.count = int(t[0])
self.total = t[1]
@property
def median(self): # @property 是装饰器,这里可简单理解为增加median属性(只读)
d = torch.tensor(list(self.deque))
return d.median().item()
@property
def avg(self):
d = torch.tensor(list(self.deque), dtype=torch.float32)
return d.mean().item()
@property
def global_avg(self):
return self.total / self.count
@property
def max(self):
return max(self.deque)
@property
def value(self):
return self.deque[-1]
def __str__(self):
return self.fmt.format(
median=self.median,
avg=self.avg,
global_avg=self.global_avg,
max=self.max,
value=self.value)
def reduce_dict(input_dict, average=True):
"""
Args:
input_dict (dict): all the values will be reduced
average (bool): whether to do average or sum
Reduce the values in the dictionary from all processes so that all processes
have the averaged results. Returns a dict with the same fields as
input_dict, after reduction.
"""
world_size = get_world_size()
if world_size < 2: # 单GPU的情况/cpu
return input_dict
with torch.no_grad(): # 多GPU的情况
names = []
values = []
# sort the keys so that they are consistent across processes
for k in sorted(input_dict.keys()):
names.append(k)
values.append(input_dict[k])
values = torch.stack(values, dim=0)
dist.all_reduce(values)
if average:
values /= world_size
reduced_dict = {k: v for k, v in zip(names, values)}
return reduced_dict
other_utils.py
import torch
import random
import numpy as np
from torch.backends import cudnn
import os
import glob
import time
def init_seeds(seed=0):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
# Reduce randomness (may be slower on Tesla GPUs) # https://pytorch.org/docs/stable/notes/randomness.html
if seed == 0:
cudnn.deterministic = False
cudnn.benchmark = True
def check_file(file):
# Searches for file if not found locally
if os.path.isfile(file):
return file
else:
files = glob.glob('./**/' + file, recursive=True) # find file
assert len(files), 'File Not Found: %s' % file # assert file was found
return files[0] # return first file if multiple found
def time_synchronized():
torch.cuda.synchronize() if torch.cuda.is_available() else None
return time.time()
最后
以上就是温婉果汁最近收集整理的关于【YOLO-V3-SPP 源码解读】四、训练模块一、整体代码1、LoadImagesAndLabels2、DataLoader3、DarkNet模型搭建4、学习率设置5、开始训练6、Compute_loss其他文件的全部内容,更多相关【YOLO-V3-SPP内容请搜索靠谱客的其他文章。








发表评论 取消回复