1 致谢
感谢网友wzy_zju提供的资料,链接如下:
https://blog.csdn.net/wzy_zju/article/details/81262453
2 前言
今天在学习CNN~
我之前一直对BN的作用还不是很明白,所以今天再来复习一下~
首先我们来看看关于 norm layer 的经典示意图
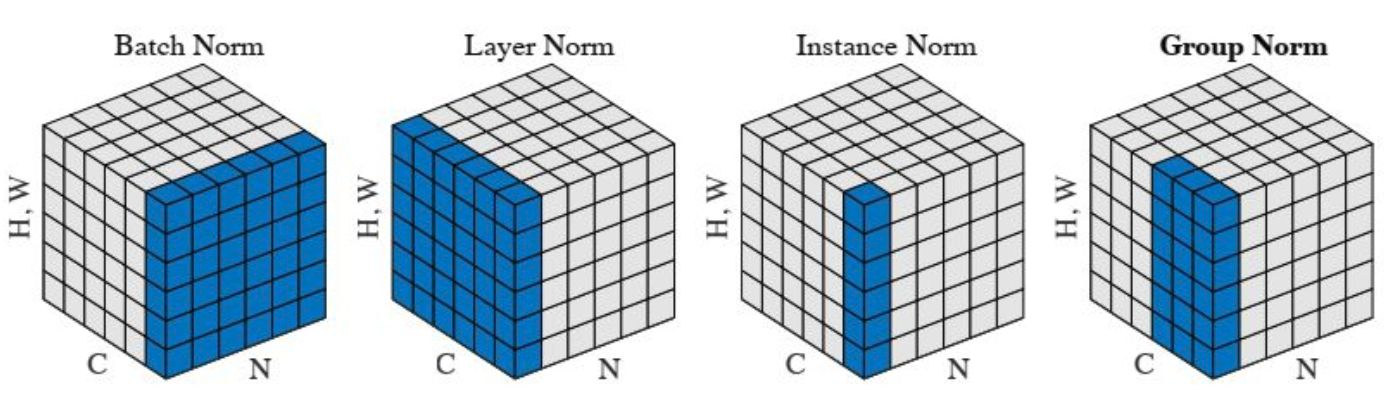
3 BN:Batch Normalization
3.1 BN所解决的问题
其实BN的效果跟图像归一化的效果是类似的,都是为了解决特征数值归一化的问题;
3.2 Batch Normalization的算法思路
这里我们可以参考一下原始论文的算法图:

γ
pmb{gamma}
γγ:可学习参数,缩放因子;
β
pmb{beta}
ββ:可学习参数,平移因子;
(这里“可学习参数”的意思是,这里的
γ
gamma
γ和
β
beta
β会跟其它权值一样参加BP的计算,也就是一个“普通的权值”)
3.3 BN的非线性
BN是一个非线性算子;
算子:算子是一个函数空间到函数空间上的映射
O
:
X
→
Y
O: Xrightarrow Y
O:X→Y。
下面我们对BN层的非线性进行说明,这里采用一个简单的方法进行论证,BN层其实包含了两个算子操作:归一化算子和线性算子
γ
x
+
β
gamma x + beta
γx+β,
易知,线性算子
γ
x
+
β
gamma x + beta
γx+β必然是线性的;
这里我们将第一层运算
x
^
i
←
x
i
−
μ
B
σ
B
2
+
ϵ
hat{x}_i leftarrow frac{x_i - mu_mathcal{B}}{sqrt{sigma^2_mathcal{B}+epsilon}}
x^i←σB2+ϵxi−μB看作是归一化操作,
ϵ
epsilon
ϵ为数值稳定项,在理论推导时看作
0
0
0;
下面我们对归一化算子的非线性进行证明:
首先,看看线性算子的定义,线性算子需满足以下性质,设
X
X
X和
Y
Y
Y是两个线性空间,
T
T
T是
X
X
X到
Y
Y
Y的映射,
T
(
α
x
1
+
β
x
2
)
=
α
T
(
x
1
)
+
β
T
(
x
2
)
T(alpha x_1+ beta x_2) =alpha Tleft ( x_1right ) +beta Tleft(x_2right)
T(αx1+βx2)=αT(x1)+βT(x2)
等价于同时满足以下两个性质
- 可加性: T ( x 1 + x 2 ) = T ( x 1 ) + T ( x 2 ) T(x_1+ x_2) =Tleft ( x_1right ) +Tleft(x_2right) T(x1+x2)=T(x1)+T(x2)
- 齐次性: T ( k x 1 ) = k T ( x 1 ) T(k x_1) =kTleft ( x_1right ) T(kx1)=kT(x1)
现在证明归一化算子
N
N
N不满足齐次性,
归一化算子的公式如下
N
(
x
)
=
x
−
D
(
x
)
σ
(
x
)
N(x) = frac{x-D(x)}{sigmaleft(xright )}
N(x)=σ(x)x−D(x)
则有
N
(
a
x
)
=
a
x
−
D
(
a
x
)
σ
(
a
x
)
=
a
x
−
a
⋅
D
(
x
)
a
⋅
σ
(
x
)
=
x
−
⋅
D
(
x
)
σ
(
x
)
=
N
(
x
)
begin{aligned} N(ax) &= frac{ax-D(ax)}{sigmaleft(axright )}\ & = frac{ax-acdot D(x)}{a cdot sigma left(xright)}\ & = frac{x-cdot D(x)}{sigma left(xright)}\ & = Nleft(xright) end{aligned}
N(ax)=σ(ax)ax−D(ax)=a⋅σ(x)ax−a⋅D(x)=σ(x)x−⋅D(x)=N(x)
不满足第二个性质,
∴
therefore
∴归一化算子是非线性算子。
nn.BatchNorm2d()
BatchNorm2d包含以下五个内部参数:
weight:可学习权值参数,对应 γ gamma γ;bias:可学习偏置参数,对应 β beta β;running_mean:持久参数,记录分布的均值,对应 E [ x ] text{E}[x] E[x]running_var:持久参数,记录分布的方差,对应 Var [ x ] text{Var}[x] Var[x]num_batches_tracked
4 MABN——“BN variant”
MABN论文:Towards Stabilizing Batch Statistics in Backward Propagation of Batch Normalization
备注:在ShuffleNetv2中试了一下MABN,实验没有效果,
5 FRN (Filter Response Normalization)
FRN是我在知乎上面看到的norm-layer,感觉还是有点帅的;
这里记录一下FRN的torch实现:
- 《超越BatchNorm你不可不知的两种方案:FRN与MABN》——给出的FRN的代码实现
- 《深度学习5种标准化层BN、GN、LN、IN、SN + 谷歌提出新的标准化层:FRN》——从图像归一化和标准化的角度来理解BN的作用
6 NormLayer的归一化代码理解
关于NormLayer的分布归一化的实现理解,请参考《PyTorch45——五种归一化的原理与代码逐行实现(BatchNorm/LayerNorm/InsNorm/GroupNorm/WeightNorm)》;
这个教程使用PyTorch的计算函数验证了各种NormLayer的分布归一化的操作;
7 NormLayer类的继承关系
.: `Module`
|--> `_NormBase`: norm-layer的基类
| |--> `_BatchNorm`: BatchNorm层的基类
| |-- components:组件代码,包括:HomePage
| |-- file
|-- examples.desktop
|-- file
最后
以上就是要减肥铅笔最近收集整理的关于CNN——NormLayer(BN、FRN)的学习笔记~1 致谢2 前言3 BN:Batch Normalization4 MABN——“BN variant”5 FRN (Filter Response Normalization)6 NormLayer的归一化代码理解7 NormLayer类的继承关系的全部内容,更多相关CNN——NormLayer(BN、FRN)的学习笔记~1内容请搜索靠谱客的其他文章。








发表评论 取消回复