对paper《Semantic Image Synthesis with Spatially-Adaptive Normalization》的代码梳理,主要用的是ade20k数据集
train.py
# Training
# train generator
if i % opt.D_steps_per_G == 0:
trainer.run_generator_one_step(data_i)通过这一行代码开始训练。
trainers/pix2pix_trainer.py
def run_generator_one_step(self, data):
self.optimizer_G.zero_grad()
g_losses, generated = self.pix2pix_model(data, mode='generator')
g_loss = sum(g_losses.values()).mean()
g_loss.backward()
self.optimizer_G.step()
self.g_losses = g_losses
self.generated = generated在这个函数中通过调用self.pix2pix_model(data,mode='generator')训练。(我在想为什么这样的模型架构都要用pix2pix命名,后来发现原来这种从一张图像生成另一张图像的架构都叫做pix2pix,和cgan的区别在于cgan是从噪音+图像生成另一张图像的)
class Pix2PixTrainer():
"""
Trainer creates the model and optimizers, and uses them to
updates the weights of the network while reporting losses
and the latest visuals to visualize the progress in training.
"""
def __init__(self, opt):
self.opt = opt
self.pix2pix_model = Pix2PixModel(opt)
if len(opt.gpu_ids) > 0:
self.pix2pix_model = DataParallelWithCallback(self.pix2pix_model,
device_ids=opt.gpu_ids)
self.pix2pix_model_on_one_gpu = self.pix2pix_model.module
else:
self.pix2pix_model_on_one_gpu = self.pix2pix_model
self.generated = None
if opt.isTrain:
self.optimizer_G, self.optimizer_D =
self.pix2pix_model_on_one_gpu.create_optimizers(opt)
self.old_lr = opt.lr在这个类的构造函数里定义了self.pix2pix_model是通过Pix2PixModel来的,其中多卡的时候有个跨卡BN的操作。
models/pix2pix_model.py
def forward(self, data, mode):
input_semantics, real_image = self.preprocess_input(data)
if mode == 'generator':
g_loss, generated = self.compute_generator_loss(
input_semantics, real_image)
return g_loss, generated
elif mode == 'discriminator':
d_loss = self.compute_discriminator_loss(
input_semantics, real_image)
return d_loss
elif mode == 'encode_only':
z, mu, logvar = self.encode_z(real_image)
return mu, logvar
elif mode == 'inference':
with torch.no_grad():
fake_image, _ = self.generate_fake(input_semantics, real_image)
return fake_image
else:
raise ValueError("|mode| is invalid")当mode为generator的时候,调用self.compute_generator_loss(input_semantics,real_image)
这里看下这两个输入条件是通过self.preprocess_input(data)来的,具体是:
def preprocess_input(self, data):
# move to GPU and change data types
data['label'] = data['label'].long()
if self.use_gpu():
data['label'] = data['label'].cuda()
data['instance'] = data['instance'].cuda()
data['image'] = data['image'].cuda()
# create one-hot label map
label_map = data['label']
bs, _, h, w = label_map.size()
nc = self.opt.label_nc + 1 if self.opt.contain_dontcare_label
else self.opt.label_nc
input_label = self.FloatTensor(bs, nc, h, w).zero_()
input_semantics = input_label.scatter_(1, label_map, 1.0)
# concatenate instance map if it exists
if not self.opt.no_instance:
inst_map = data['instance']
instance_edge_map = self.get_edges(inst_map)
input_semantics = torch.cat((input_semantics, instance_edge_map), dim=1)
return input_semantics, data['image'] def compute_generator_loss(self, input_semantics, real_image):
G_losses = {}
fake_image, KLD_loss = self.generate_fake(
input_semantics, real_image, compute_kld_loss=self.opt.use_vae)###在这里输入数据,生成fake_image
if self.opt.use_vae:
G_losses['KLD'] = KLD_loss
pred_fake, pred_real = self.discriminate(
input_semantics, fake_image, real_image)
G_losses['GAN'] = self.criterionGAN(pred_fake, True,
for_discriminator=False)
if not self.opt.no_ganFeat_loss:
num_D = len(pred_fake)
GAN_Feat_loss = self.FloatTensor(1).fill_(0)
for i in range(num_D): # for each discriminator
# last output is the final prediction, so we exclude it
num_intermediate_outputs = len(pred_fake[i]) - 1
for j in range(num_intermediate_outputs): # for each layer output
unweighted_loss = self.criterionFeat(
pred_fake[i][j], pred_real[i][j].detach())
GAN_Feat_loss += unweighted_loss * self.opt.lambda_feat / num_D
G_losses['GAN_Feat'] = GAN_Feat_loss
if not self.opt.no_vgg_loss:
G_losses['VGG'] = self.criterionVGG(fake_image, real_image)
* self.opt.lambda_vgg
return G_losses, fake_image def generate_fake(self, input_semantics, real_image, compute_kld_loss=False):
z = None
KLD_loss = None
if self.opt.use_vae:
z, mu, logvar = self.encode_z(real_image)
if compute_kld_loss:
KLD_loss = self.KLDLoss(mu, logvar) * self.opt.lambda_kld
fake_image = self.netG(input_semantics, z=z)
assert (not compute_kld_loss) or self.opt.use_vae,
"You cannot compute KLD loss if opt.use_vae == False"
return fake_image, KLD_loss
#在训练时,采用的是不考虑vae的,也就是不会对real_image做encode操作得到一个z,
#此处的z为None,送去生成网络self.netG的只有语义标签图和Z,没有real_image。
#我一开始很迷惑这一步,只有纯语义标签用来生成,这样的话mask怎么去学习image的风格呢
#先往下看class Pix2PixModel(torch.nn.Module):
@staticmethod
def modify_commandline_options(parser, is_train):
networks.modify_commandline_options(parser, is_train)
return parser
def __init__(self, opt):
super().__init__()
self.opt = opt
self.FloatTensor = torch.cuda.FloatTensor if self.use_gpu()
else torch.FloatTensor
self.ByteTensor = torch.cuda.ByteTensor if self.use_gpu()
else torch.ByteTensor
self.netG, self.netD, self.netE = self.initialize_networks(opt)
##在这里得到初始化网络后(这里的初始化不是真的在做初始化)的self.netG, def initialize_networks(self, opt):
netG = networks.define_G(opt) ##在这里得到netG
netD = networks.define_D(opt) if opt.isTrain else None
netE = networks.define_E(opt) if opt.use_vae else None
if not opt.isTrain or opt.continue_train:
netG = util.load_network(netG, 'G', opt.which_epoch, opt)
if opt.isTrain:
netD = util.load_network(netD, 'D', opt.which_epoch, opt)
if opt.use_vae:
netE = util.load_network(netE, 'E', opt.which_epoch, opt)
return netG, netD, netEmodels/networks/__init__.py (是network下面的__init__.py而不是model下面的)
def define_G(opt):
netG_cls = find_network_using_name(opt.netG, 'generator')
return create_network(netG_cls, opt)def find_network_using_name(target_network_name, filename):
### target_network_name 是SPADE,filename是generator
target_class_name = target_network_name + filename
module_name = 'models.networks.' + filename
network = util.find_class_in_module(target_class_name, module_name)
#在models.networks.generator里面找到SPADEGenerator这个模块并返回
assert issubclass(network, BaseNetwork),
"Class %s should be a subclass of BaseNetwork" % network
return networkdef create_network(cls, opt):
net = cls(opt) #输入一些网络参数
net.print_network() #打印网络
if len(opt.gpu_ids) > 0:
assert(torch.cuda.is_available())
net.cuda()
net.init_weights(opt.init_type, opt.init_variance) #这里才是真的在做初始化网络
return net接下来,具体看它调用的SPADEGenerator的网络结构
models/networks/generator.py
class SPADEGenerator(BaseNetwork):
@staticmethod
def modify_commandline_options(parser, is_train):
parser.set_defaults(norm_G='spectralspadesyncbatch3x3')
parser.add_argument('--num_upsampling_layers',
choices=('normal', 'more', 'most'), default='normal',
help="If 'more', adds upsampling layer between the two middle resnet blocks. If 'most', also add one more upsampling + resnet layer at the end of the generator")
return parser
def __init__(self, opt):
super().__init__()
self.opt = opt
nf = opt.ngf
self.sw, self.sh = self.compute_latent_vector_size(opt)
### 输入为256x256,得到的sw=2,sh=2 计算潜向量的大小
if opt.use_vae:
# In case of VAE, we will sample from random z vector
self.fc = nn.Linear(opt.z_dim, 16 * nf * self.sw * self.sh)
else:
# Otherwise, we make the network deterministic by starting with
# downsampled segmentation map instead of random z
self.fc = nn.Conv2d(self.opt.semantic_nc, 16 * nf, 3, padding=1)
self.head_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.G_middle_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.G_middle_1 = SPADEResnetBlock(16 * nf, 16 * nf, opt)
self.up_0 = SPADEResnetBlock(16 * nf, 8 * nf, opt)
self.up_1 = SPADEResnetBlock(8 * nf, 4 * nf, opt)
self.up_2 = SPADEResnetBlock(4 * nf, 2 * nf, opt)
self.up_3 = SPADEResnetBlock(2 * nf, 1 * nf, opt)
final_nc = nf
if opt.num_upsampling_layers == 'most':
self.up_4 = SPADEResnetBlock(1 * nf, nf // 2, opt)
final_nc = nf // 2
self.conv_img = nn.Conv2d(final_nc, 3, 3, padding=1)
self.up = nn.Upsample(scale_factor=2)
def compute_latent_vector_size(self, opt):
if opt.num_upsampling_layers == 'normal':
num_up_layers = 5
elif opt.num_upsampling_layers == 'more':
num_up_layers = 6
elif opt.num_upsampling_layers == 'most':
num_up_layers = 7
else:
raise ValueError('opt.num_upsampling_layers [%s] not recognized' %
opt.num_upsampling_layers)
sw = opt.crop_size // (2**num_up_layers)
sh = round(sw / opt.aspect_ratio)
return sw, sh
def forward(self, input, z=None):
seg = input ### 这里的input是语义标签图
if self.opt.use_vae:
# we sample z from unit normal and reshape the tensor
if z is None:
z = torch.randn(input.size(0), self.opt.z_dim,
dtype=torch.float32, device=input.get_device())
x = self.fc(z)
x = x.view(-1, 16 * self.opt.ngf, self.sh, self.sw)
else:
# we downsample segmap and run convolution
x = F.interpolate(seg, size=(self.sh, self.sw)) ##对语义标签图插值后变成size更小的特征图?
x = self.fc(x) #卷积操作
x = self.head_0(x, seg) #这里的x已经变成了sh X sw这么大,通道为16*nf的特征图了,而seg还是原图大小,特征通道为151的初始input
x = self.up(x) #上采样2倍
x = self.G_middle_0(x, seg) #不改变通道值的SPADEResnetBlock,建议先去看一下SPADEResnetBlock的构造
if self.opt.num_upsampling_layers == 'more' or
self.opt.num_upsampling_layers == 'most':
x = self.up(x)
x = self.G_middle_1(x, seg) #SPADEResnetBlock
x = self.up(x)
x = self.up_0(x, seg)
x = self.up(x)
x = self.up_1(x, seg)
x = self.up(x)
x = self.up_2(x, seg)
x = self.up(x)
x = self.up_3(x, seg)
if self.opt.num_upsampling_layers == 'most':
x = self.up(x)
x = self.up_4(x, seg)
x = self.conv_img(F.leaky_relu(x, 2e-1))
x = F.tanh(x)
return x这一步我觉得需要注意的是输入到generator的input,把mask作为input是为了得到spatial信息的。但我之前一直以为是把mask做encode之后用image来学习仿射变换的参数“注射”到特征图的标准化中,原来generator从头到尾都用不到image啊,估计只有loss的时候才用到。这里提出的生成器里,主要分为1.用vae(这里又分为有没有提供real image)2.不用vae 。用vae的时候如果提供了real image,就算real image的均值和方差得到一个z向量,如果没有提供,就生成一个符合标准正太分布的随机噪声,然后连接全连接层生成一个z向量。不用vae的时候是对segmantic map做降采样处理作为输入。
models/networks/architecture.py
class SPADEResnetBlock(nn.Module):
def __init__(self, fin, fout, opt):
super().__init__()
# Attributes
self.learned_shortcut = (fin != fout)
fmiddle = min(fin, fout)
# create conv layers
self.conv_0 = nn.Conv2d(fin, fmiddle, kernel_size=3, padding=1)
self.conv_1 = nn.Conv2d(fmiddle, fout, kernel_size=3, padding=1)
if self.learned_shortcut:
self.conv_s = nn.Conv2d(fin, fout, kernel_size=1, bias=False)
# apply spectral norm if specified
if 'spectral' in opt.norm_G:
self.conv_0 = spectral_norm(self.conv_0)
self.conv_1 = spectral_norm(self.conv_1)
if self.learned_shortcut:
self.conv_s = spectral_norm(self.conv_s)
# define normalization layers
spade_config_str = opt.norm_G.replace('spectral', '')
self.norm_0 = SPADE(spade_config_str, fin, opt.semantic_nc)
self.norm_1 = SPADE(spade_config_str, fmiddle, opt.semantic_nc)
if self.learned_shortcut:
self.norm_s = SPADE(spade_config_str, fin, opt.semantic_nc)
# note the resnet block with SPADE also takes in |seg|,
# the semantic segmentation map as input
def forward(self, x, seg):
x_s = self.shortcut(x, seg)
dx = self.conv_0(self.actvn(self.norm_0(x, seg)))
dx = self.conv_1(self.actvn(self.norm_1(dx, seg)))
out = x_s + dx
return out
def shortcut(self, x, seg):
if self.learned_shortcut:
x_s = self.conv_s(self.norm_s(x, seg))
else:
x_s = x
return x_s
def actvn(self, x):
return F.leaky_relu(x, 2e-1)models/networks/normalization.py
class SPADE(nn.Module):
def __init__(self, config_text, norm_nc, label_nc):
super().__init__()
assert config_text.startswith('spade')
parsed = re.search('spade(D+)(d)xd', config_text)
param_free_norm_type = str(parsed.group(1))
ks = int(parsed.group(2))
if param_free_norm_type == 'instance':
self.param_free_norm = nn.InstanceNorm2d(norm_nc, affine=False)
elif param_free_norm_type == 'syncbatch':
self.param_free_norm = SynchronizedBatchNorm2d(norm_nc, affine=False)
elif param_free_norm_type == 'batch':
self.param_free_norm = nn.BatchNorm2d(norm_nc, affine=False)
else:
raise ValueError('%s is not a recognized param-free norm type in SPADE'
% param_free_norm_type)
# The dimension of the intermediate embedding space. Yes, hardcoded.
nhidden = 128
pw = ks // 2
self.mlp_shared = nn.Sequential(
nn.Conv2d(label_nc, nhidden, kernel_size=ks, padding=pw),
nn.ReLU()
)
self.mlp_gamma = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw)
self.mlp_beta = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw)
def forward(self, x, segmap):
# Part 1. generate parameter-free normalized activations
normalized = self.param_free_norm(x) # 与仿射变换参数无关的标准化
# Part 2. produce scaling and bias conditioned on semantic map
segmap = F.interpolate(segmap, size=x.size()[2:], mode='nearest')
#对segmap做resize
actv = self.mlp_shared(segmap)
gamma = self.mlp_gamma(actv)
beta = self.mlp_beta(actv)
# apply scale and bias
out = normalized * (1 + gamma) + beta
#这里解释一个为什么是1+gamma而不是gamma,作者自己解释是因为怕gamma学习到的结果接近于0,
#那乘以normalized以后就为0了,失去了normalized的作用,所以要用1+gamma,确保
#normalized有发挥作用同时还能学习仿射变换
return out这里我放一下paper里的网络图,可以对照代码看一下
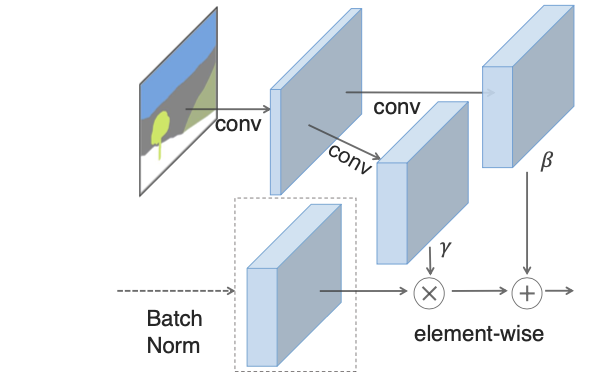 (对应SPADE)
(对应SPADE)
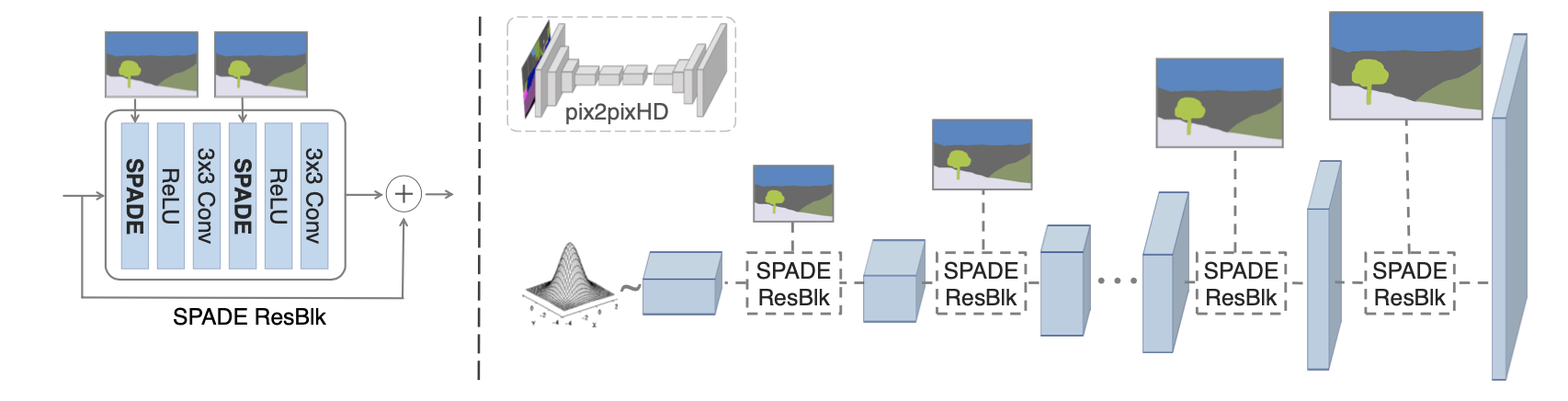 (左边对应SPADEResnetBlock,右边对应Generator)
(左边对应SPADEResnetBlock,右边对应Generator)
最后,还是说一下我看这篇paper的一个疑惑问题,除了做语义图像合成,比如像上面这些代码,如果我们不用--use_vae的话,那训练的时候就是一个mask对应一个real image,最后学到的风格是一致的,还可以用来做不同风格的图像生成吗(考虑输入real image来影响生成结果)?看看作者在github的回复:
To produce outputs with different styles, you need to train with VAE by using --use_vae flag. It it was not trained with VAE, it cannot generate different styles.
The pretrained models of COCO, ADE20K and Cityscapes are all without VAE, because we actually didn't want random generation of styles, in order to keep the evaluation metric reproducible. As you know. for GauGAN video, we trained with VAE. Once you finish training with VAE, to produce different styles for the same semantic layout input, simply run the model multiple times. It will always generate different results.
如果你想要在同样的Mask上生成多种风格的结果,用--use_vae即可。
好吧,再看看use_vae做了什么
models/pix2pix_model.py
def generate_fake(self, input_semantics, real_image, compute_kld_loss=False):
z = None
KLD_loss = None
if self.opt.use_vae:
z, mu, logvar = self.encode_z(real_image) ###在这里生成了z
if compute_kld_loss:
KLD_loss = self.KLDLoss(mu, logvar) * self.opt.lambda_kld
fake_image = self.netG(input_semantics, z=z)
assert (not compute_kld_loss) or self.opt.use_vae,
"You cannot compute KLD loss if opt.use_vae == False"
return fake_image, KLD_loss def encode_z(self, real_image):
mu, logvar = self.netE(real_image)
z = self.reparameterize(mu, logvar)
return z, mu, logvar def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return eps.mul(std) + mumodels/networks/encoder.py
class ConvEncoder(BaseNetwork):
""" Same architecture as the image discriminator """
def __init__(self, opt):
super().__init__()
kw = 3
pw = int(np.ceil((kw - 1.0) / 2))
ndf = opt.ngf
norm_layer = get_nonspade_norm_layer(opt, opt.norm_E)
self.layer1 = norm_layer(nn.Conv2d(3, ndf, kw, stride=2, padding=pw))
self.layer2 = norm_layer(nn.Conv2d(ndf * 1, ndf * 2, kw, stride=2, padding=pw))
self.layer3 = norm_layer(nn.Conv2d(ndf * 2, ndf * 4, kw, stride=2, padding=pw))
self.layer4 = norm_layer(nn.Conv2d(ndf * 4, ndf * 8, kw, stride=2, padding=pw))
self.layer5 = norm_layer(nn.Conv2d(ndf * 8, ndf * 8, kw, stride=2, padding=pw))
if opt.crop_size >= 256:
self.layer6 = norm_layer(nn.Conv2d(ndf * 8, ndf * 8, kw, stride=2, padding=pw))
self.so = s0 = 4
self.fc_mu = nn.Linear(ndf * 8 * s0 * s0, 256)
self.fc_var = nn.Linear(ndf * 8 * s0 * s0, 256)
self.actvn = nn.LeakyReLU(0.2, False)
self.opt = opt
def forward(self, x):
if x.size(2) != 256 or x.size(3) != 256:
x = F.interpolate(x, size=(256, 256), mode='bilinear')
x = self.layer1(x)
x = self.layer2(self.actvn(x))
x = self.layer3(self.actvn(x))
x = self.layer4(self.actvn(x))
x = self.layer5(self.actvn(x))
if self.opt.crop_size >= 256:
x = self.layer6(self.actvn(x))
x = self.actvn(x)
x = x.view(x.size(0), -1)
mu = self.fc_mu(x)
logvar = self.fc_var(x)
return mu, logvarencode具体就不分析。
写的比较乱,主要是为了梳理一下自己的思路,如果有错误还请评论指正。
最后
以上就是唠叨彩虹最近收集整理的关于SPADE 代码略解 ade20k数据集的全部内容,更多相关SPADE内容请搜索靠谱客的其他文章。








发表评论 取消回复