声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
A comparison of streaming models and data augmentation methods for robust speech recognition
本文为三星在2021.11.19更新的文章,主要对比端到端流式ASR系统Monotonic Chunkwise Attention (MoChA) 和 Recurrent Neural Network-Transducer (RNN-T)的性能以及multi-conditioned training using an acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment等数据增广对比试验,主要为经验分享,具体的文章链接https://arxiv.org/pdf/2111.10043.pdf
1 背景
端到端的ASR最近几年受到重大关注,其使用一个网络结构来完成传统的ASR多个模块共同完成的任务,大大降低其复杂程度。在现实场景中,ASR需要满足时延低的特性,因此streaming asr被研究。本文对比了目前主流的端到端streaming ASR的方案:Monotonic Chunkwise Attention (MoChA) 和 Recurrent Neural Network-Transducer (RNN-T)。另外也对比三种数据增广方案的实验对比:multi-conditioned training using an acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment。
2 详细设计
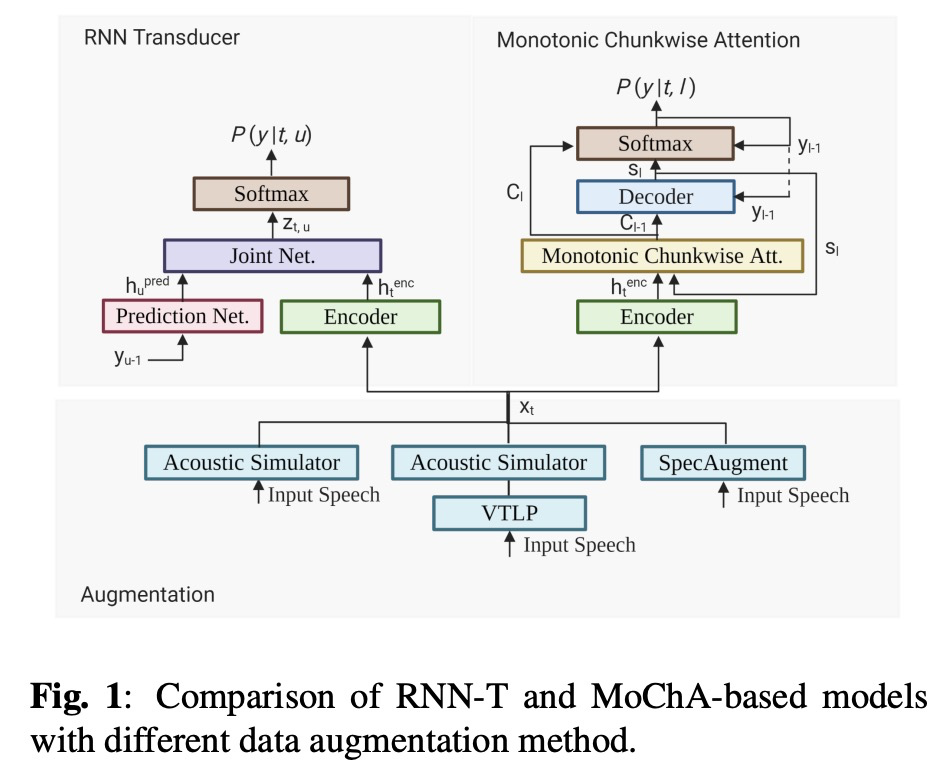
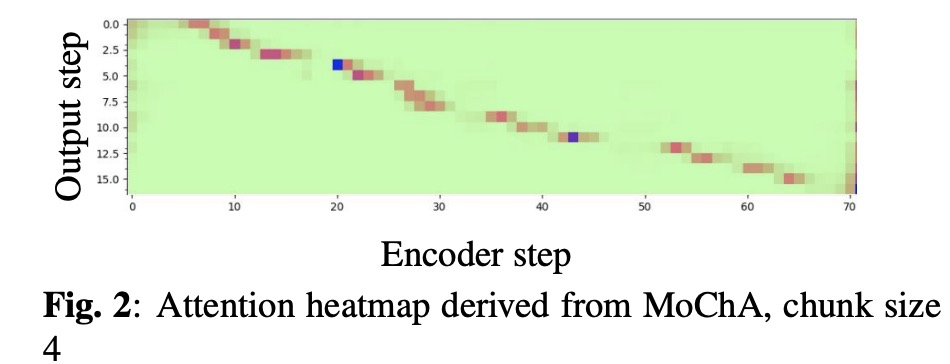
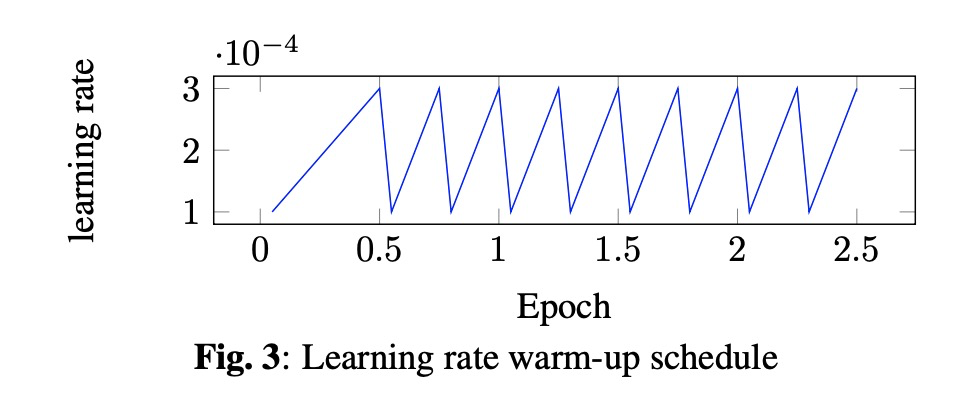
本文先回顾了MoChA和RNN-T的网络结构(图1所示),为了对比公平,本文的encoder部分的结构及超参相同,都使用LSTM的结构。其中MoChA的chunk设置为4,其对齐如图2所示。另外本文训练模型使用了warm-up 的策略,其学习率随着添加layer而变化如图3所示。
3 实验
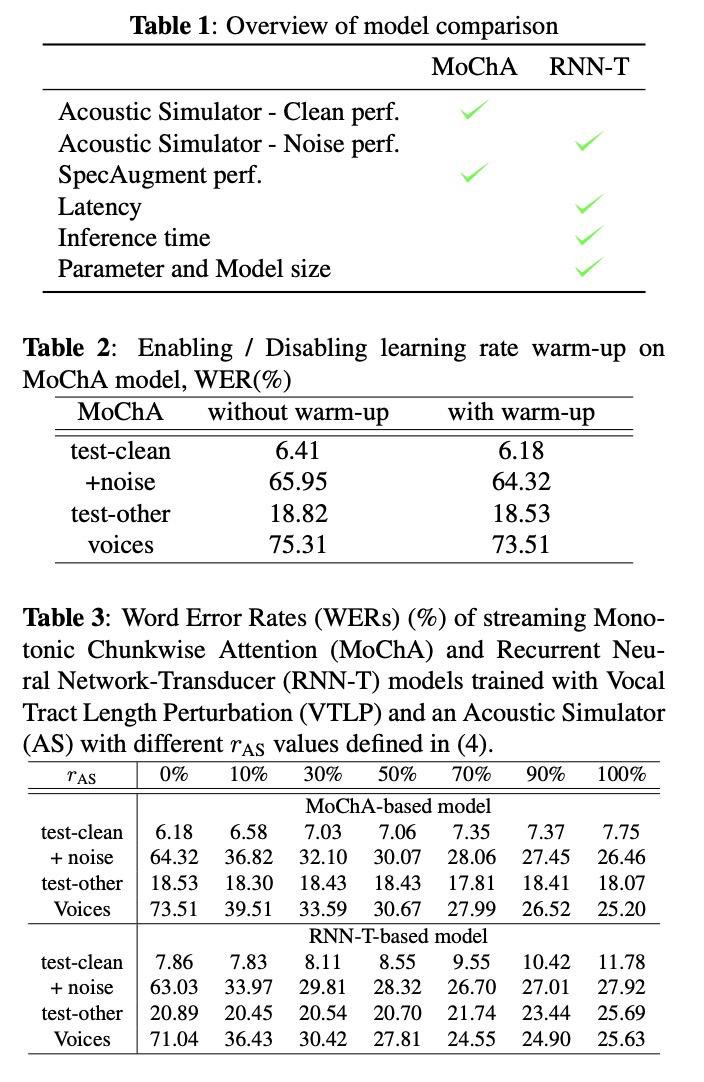
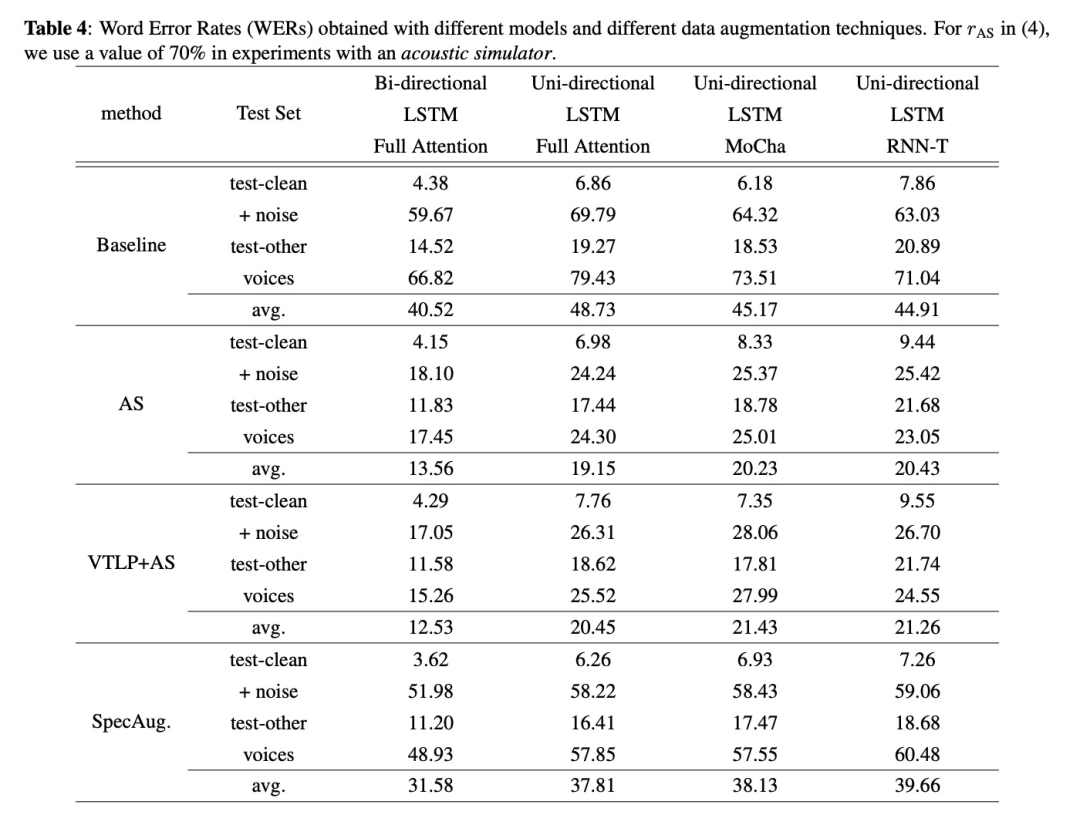
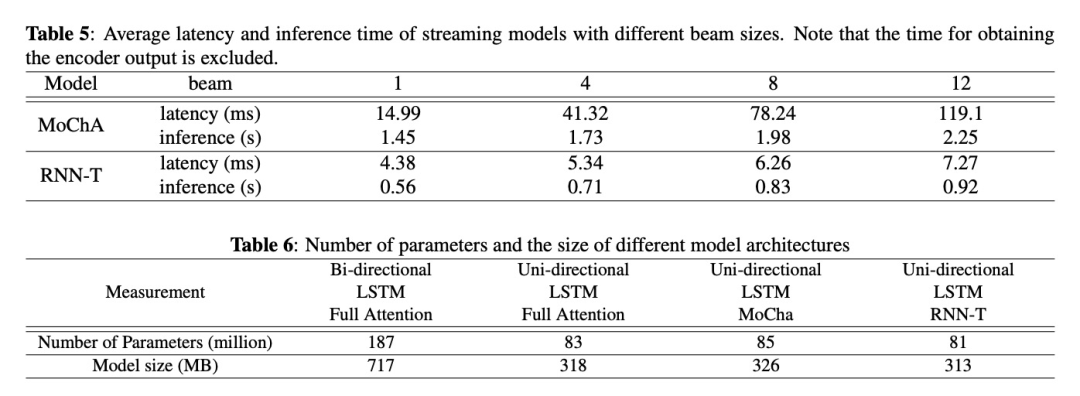
本文除了对比MoChA和RNN-T流式模型,还对比了非流式模型Bi-directional LSTM with Full Attention (BFA) models and Uni-directional LSTM with Full Attention (UFA) 。训练使用的数据为LibriSpeech Corpus,测试数据为Test set - LibriSpeech clean with noise和Test set - VOiCES。另外对比了数据增广的方案Room acoustics simulation,Vocal Tract Length Perturbation和 SpecAugment,训练添加的Room acoustics simulation占比如公司4所示。首先看table1对比了MoChA和RNN-T在每种方案的对比试验,在clean数据上MoChA表现好,在noise数据上RNN-T表现好。另外RNN-T在时延、模型大小上更占优势,更适合在端上进行部署使用。Table2对比warm-up的效果,结果显示warm-up训练提高性能。Table 3对比数据增广acoustics simulation的影响,有结果可知该数据增广在noise数据上效果显著,clean数据集效果反而下降。Table 4对比三种数据增广方案在流式和非流式系统上的性能,其大大提高的系统的性能,而且在非流式系统上表现更突出。Table5和Table6对比了MoChA和RNN-T的速度和参数量,其结果显示RNN-T更具备优势,更适合在边缘设备上进行部署的方案。

4 总结
本文对比端到端流式ASR系统Monotonic Chunkwise Attention (MoChA) 和 Recurrent Neural Network-Transducer (RNN-T)的性能以及acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment等数据增广对比试验,主要为经验分享。
最后
以上就是快乐天空最近收集整理的关于语音识别(ASR)论文优选:A comparison of streaming models and data augmentation methods for robust speech recog的全部内容,更多相关语音识别(ASR)论文优选:A内容请搜索靠谱客的其他文章。








发表评论 取消回复