
????日报合辑 | ????电子月刊 | ????公众号下载资料 | ????@韩信子
???? 微软推出AI设计软件 Designer,正面硬刚 PS?
https://designer.microsoft.com/
近日微软宣布,将推出一款名为 Designer 的图像设计软件,用户只需要输入文字指令,软件就能够自动设计对应图案。Microsoft Designer 由 AI 技术提供支持,包括 OpenAI 的 DALL∙E 2。软件将集成到 Microsoft 365,作为免费应用发布,并为个人版和家庭版的订阅者提供更多高级功能。
虽然微软明确表示 Adobe 是公司的主要竞争对手,但明眼人都知道其实它是瞄准的行业内占据优势地位的另外一款设计软件 Canva。
工具&框架
???? 『arxiv2latex』一键下载多篇Arxiv论文Latex源码
https://github.com/liuyixin-louis/arxiv2latex
arxiv2latex 是一键下载多篇 Arxiv 论文 Latex 源码的工具。写论文过程中有时会下载和参考其他人的论文的latex源代码,然而如果有很多论文需要下载,这个过程会变得非常机械和重复,借助arxiv2latex可以很方便完成。
???? 『MarkDownload』浏览器插件,将网页保存为Markdown文件
https://github.com/deathau/markdownload
MarkDownload 是一个扩展,用于将网页或部分网页内容下载为可读的 markdown 文件。想离线保存正在浏览的网页,只需点击 MarkDownload 扩展程序的图标,弹出的窗口显示了渲染后的样式,此时可以进行编辑内容、复制文本、或下载为.md文件。
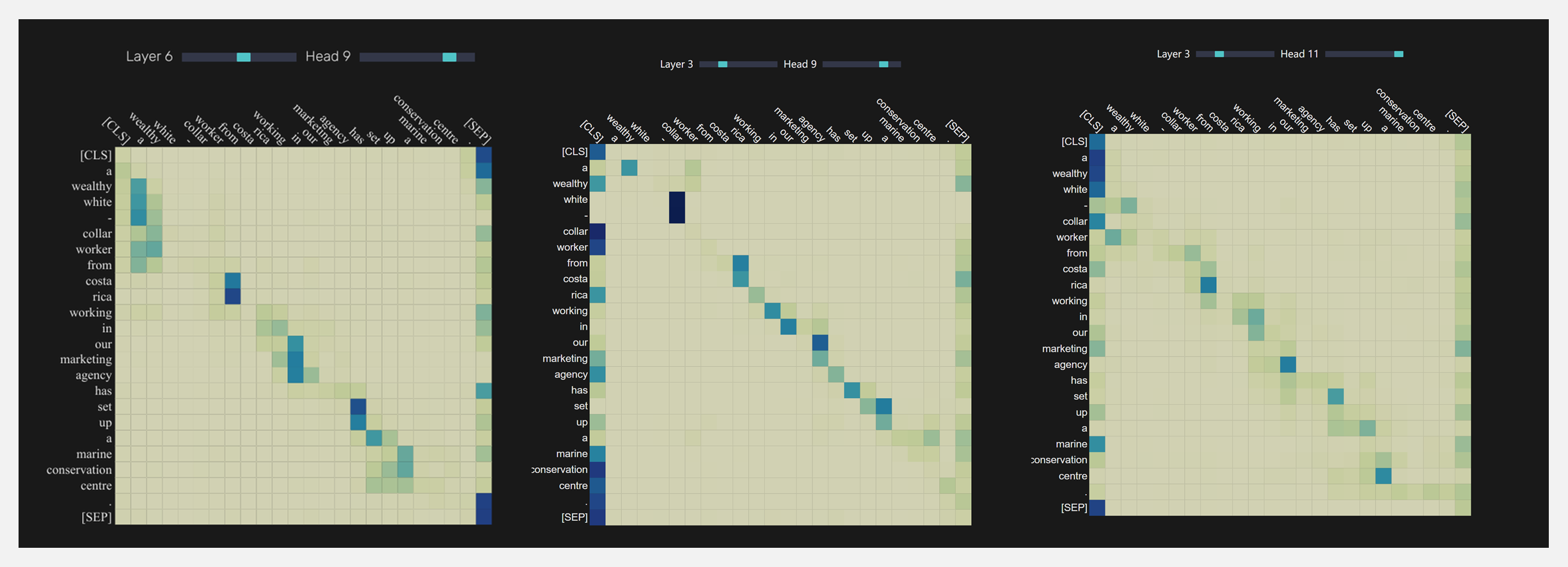
???? 『TrAVis』Transformer 注意力矩阵的可视化工具
https://github.com/ayaka14732/TrAVis
https://ayaka14732.github.io/TrAVis/
原始论文『Attention Is All You Need』证明了注意力机制在 Transformer 模型中的核心地位。基于 Transformer 的模型在计算注意力机制的过程中产生了注意力矩阵,显示模型是如何处理输入数据的,也被看视作机制的具体表现。TrAVis 工具库则可以将注意力矩阵进行可视化,并支持在浏览器中完成之一过程。
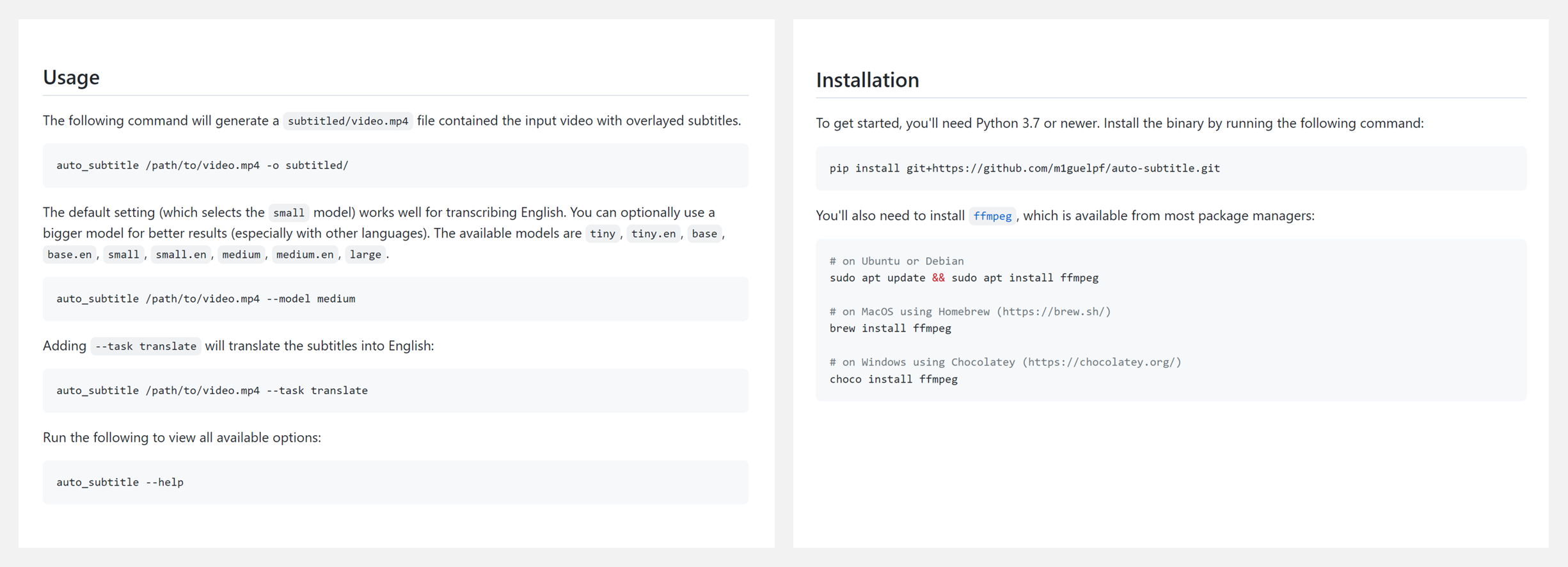
???? 『Automatic subtitles in your videos』用ffmpeg+OpenAI 的 Whisper为视频文件自动加字幕
https://github.com/m1guelpf/auto-subtitle
这个项目把 ffmpeg 和 OpenAI 的 Whisper 组合成一个工具,用来自动生成任何视频的字幕。
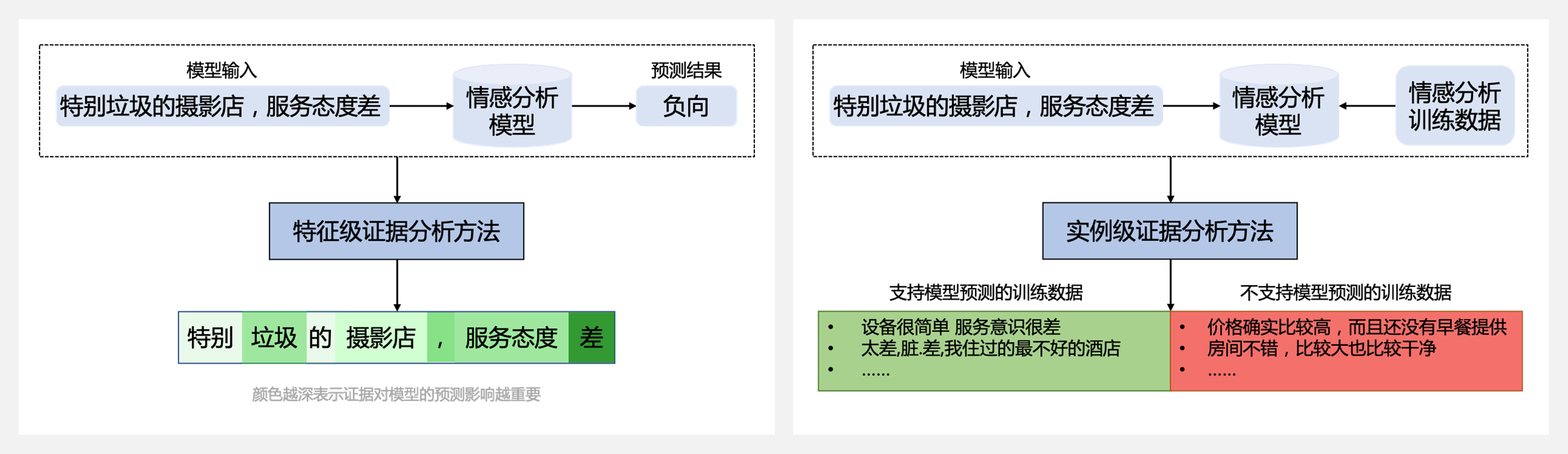
???? 『TrustAI』飞桨可信AI工具集,提升深度学习模型可信度
https://github.com/PaddlePaddle/TrustAI
基于 PaddlePaddle 开发的可信AI工具集,集可信分析与增强于一体,可以提升深度学习模型的效果和可信度,有效推动模型安全、可靠的落地与应用。TrustAI 提供特征级证据和实例级证据的分析方法,全方位解释模型的预测,帮助开发者了解模型预测机制,以及协助使用者基于证据做出正确决策。
博文&分享
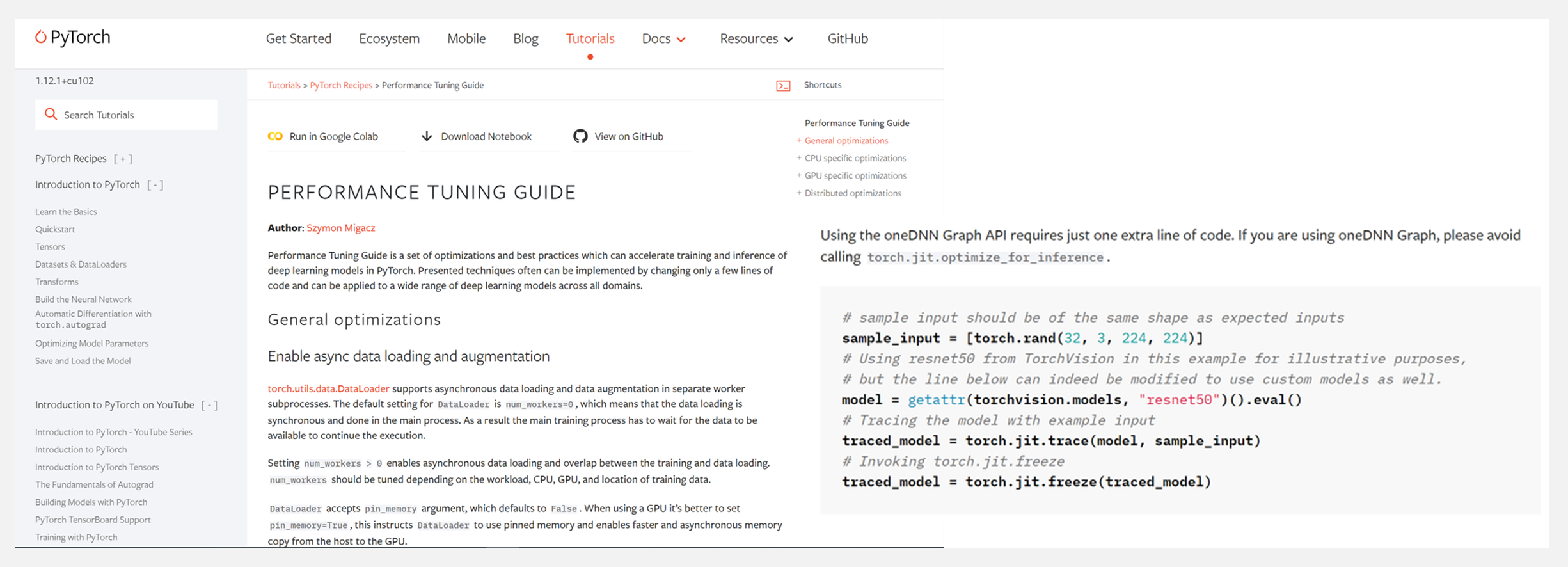
???? 『PyTorch Tutorials | Performance Tuning Guide』PyTorch模型性能调优指南
https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html
性能调优指南是一组优化和最佳实践,可以加速 PyTorch 中深度学习模型的训练和推理。所提出的技术通常可以通过仅更改几行代码来实现,并且可以应用于所有领域的广泛深度学习模型。
教程包含General optimizations (常规优化)、CPU specific optimizations (CPU 特定优化)、GPU specific optimizations (GPU 特定优化)、Distributed optimizations (分布式优化)』四个部分。
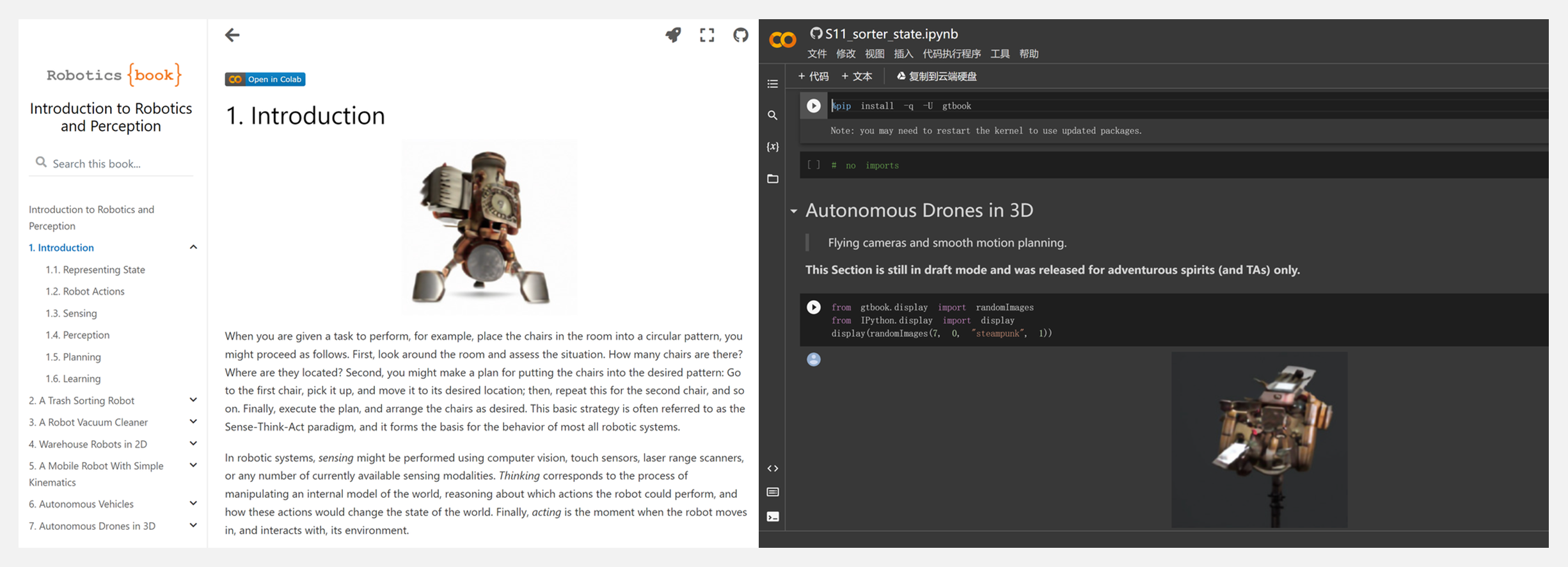
???? 『Introduction to Robotics and Perception』机器人与感知导论·开源书稿
https://github.com/gtbook/robotics
https://www.roboticsbook.org/intro.html
这是关于介绍机器人技术的书稿,完全使用 Notebook 编写,用于2022年佐治亚理工学院CS3630秋季课程。书稿包含以下主题:
- A Trash Sorting Robot(垃圾分类机器人)
- A Robot Vacuum Cleaner(吸尘器机器人)
- Warehouse Robots in 2D(2D仓库机器人)
- A Mobile Robot With Simple Kinematics(具有简单运动学的移动机器人)
- Autonomous Vehicles(自动驾驶汽车)
- Autonomous Drones in 3D(3D自动无人机)
数据&资源
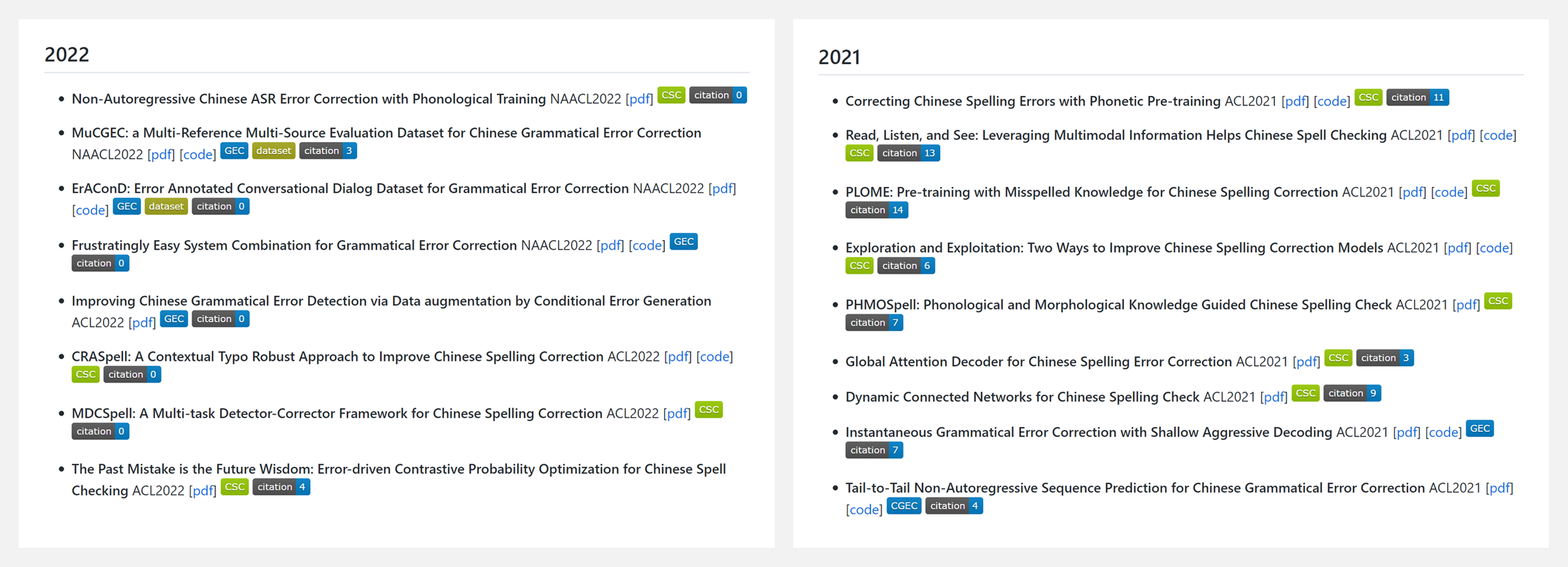
???? 『Text Correction Papers』文本纠错相关文献资源列表
https://github.com/nghuyong/text-correction-papers
该 repo 旨在持续跟踪文本校正方面的相关工作,包括中文拼写检查 (CSC) 和语法错误校正 (GEC)。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
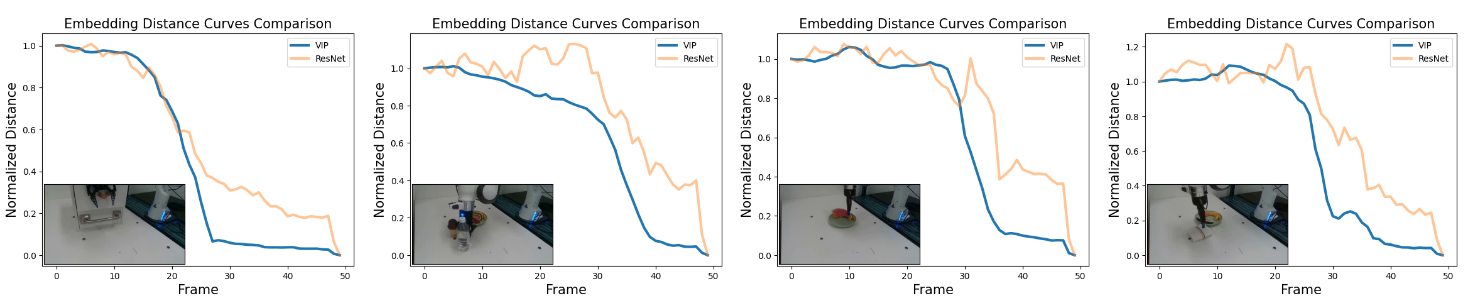
- 2022.09.30 『表征学习』 VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
- Preprint 2022 『语音识别』 Robust Speech Recognition via Large-Scale Weak Supervision
- 2022.10.04 『问答系统』 Mintaka: A Complex, Natural, and Multilingual Dataset for End-to-End Question Answering
⚡ 论文:VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
论文时间:30 Sep 2022
领域任务:Offline RL, Representation Learning,离线强化学习,表征学习
论文地址:https://arxiv.org/abs/2210.00030
代码实现:https://github.com/facebookresearch/vip
论文作者:Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, Amy Zhang
论文简介:Given the inherent cost and scarcity of in-domain, task-specific robot data, learning from large, diverse, offline human videos has emerged as a promising path towards acquiring a generally useful visual representation for control; however, how these human videos can be used for general-purpose reward learning remains an open question./鉴于领域内特定任务的机器人数据的固有成本和稀缺性,从大型、多样、离线的人类视频中学习已经成为获得普遍有用的控制视觉表征的有希望的途径;然而,这些人类视频如何用于通用的奖励学习仍然是一个开放的问题。
论文摘要:奖励和表征学习是两个长期存在的挑战,即从感官观察中学习一套不断扩大的机器人操纵技能。鉴于领域内特定任务的机器人数据的固有成本和稀缺性,从大型、多样、离线的人类视频中学习已经成为获得普遍有用的控制视觉表征的有希望的途径;然而,这些人类视频如何用于通用的奖励学习仍然是一个开放的问题。我们介绍了价值隐含预训练(VIP),这是一种自我监督的预训练视觉表征,能够为未见过的机器人任务生成密集而平滑的奖励函数。VIP将人类视频中的表征学习作为一个离线目标条件强化学习问题,并推导出一个不依赖于行动的自我监督的双目标条件价值函数目标,从而能够在未标记的人类视频上进行预训练。从理论上讲,VIP可以被理解为一个新的隐性时间对比目标,它产生了一个时间上平滑的嵌入,使得价值函数可以通过嵌入距离隐性定义,然后可以用来构建任何目标图像指定的下游任务的奖励。在大规模的Ego4D人类视频上进行训练,在没有对领域内特定任务数据进行任何微调的情况下,VIP的冻结表示可以为一组广泛的模拟和真实的机器人任务提供密集的视觉奖励,实现多样化的基于奖励的视觉控制方法,并明显优于所有先前的预训练表示。值得注意的是,VIP可以在一套只有20条轨迹的真实世界机器人任务中实现简单的、少量的离线RL。
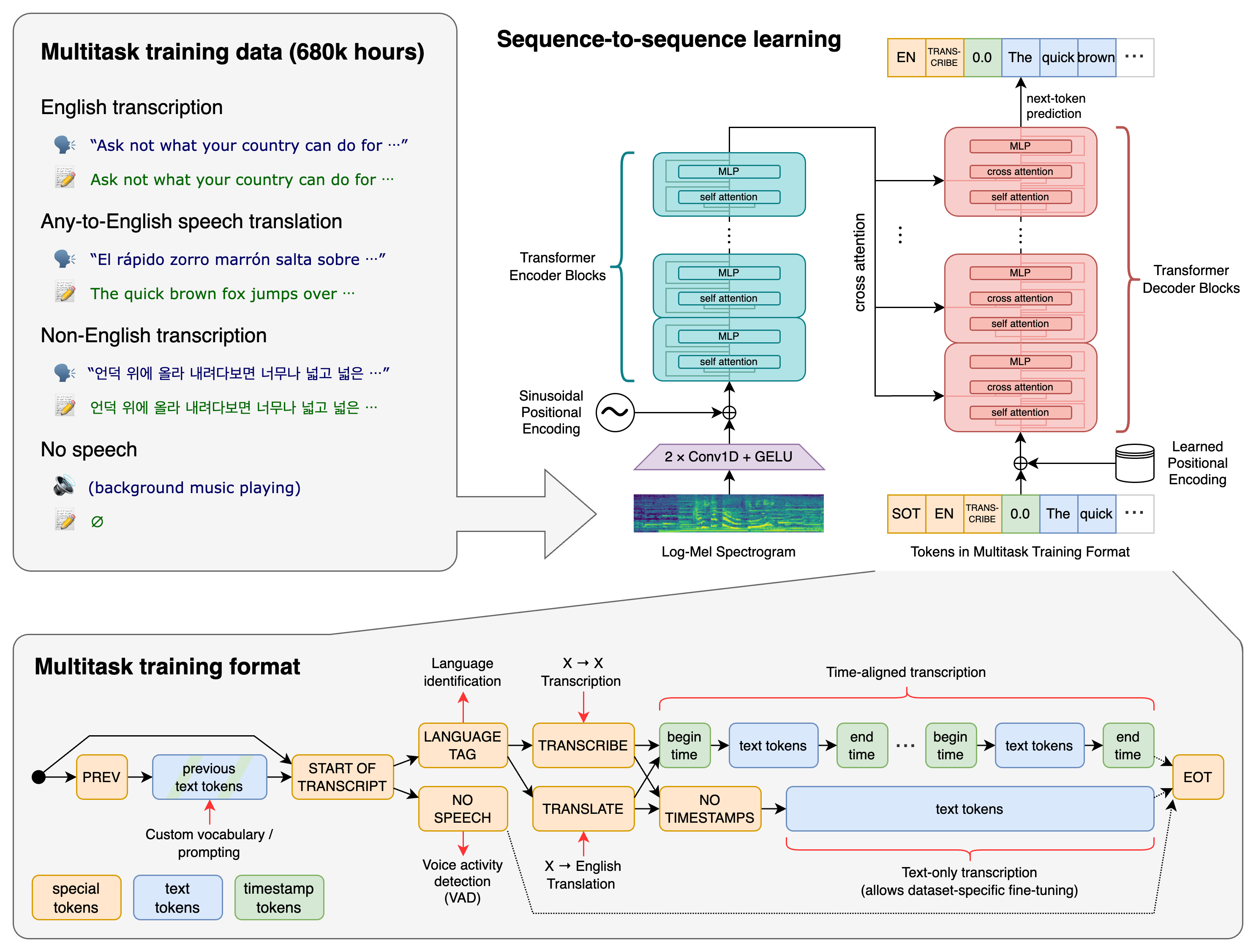
⚡ 论文:Robust Speech Recognition via Large-Scale Weak Supervision
论文时间:Preprint 2022
领域任务:Robust Speech Recognition,语音识别
论文地址:https://arxiv.org/abs/https://openai.com/blog/whisper/
代码实现:https://github.com/openai/whisper
论文作者:Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever
论文简介:We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet./我们研究了仅仅为了预测互联网上大量的音频转录而训练的语音处理系统的能力。
论文摘要:我们研究了语音处理系统的能力,这些系统被简单地训练来预测互联网上大量的音频转录。当扩展到680,000小时的多语言和多任务监督时,所产生的模型对标准基准有很好的概括性,并且通常与先前的完全监督结果相竞争,但在零样本迁移的设置中,不需要任何微调。当与人类比较时,这些模型接近其准确性和稳健性。我们正在发布模型和推理代码,作为鲁棒性语音处理的进一步工作的基础。
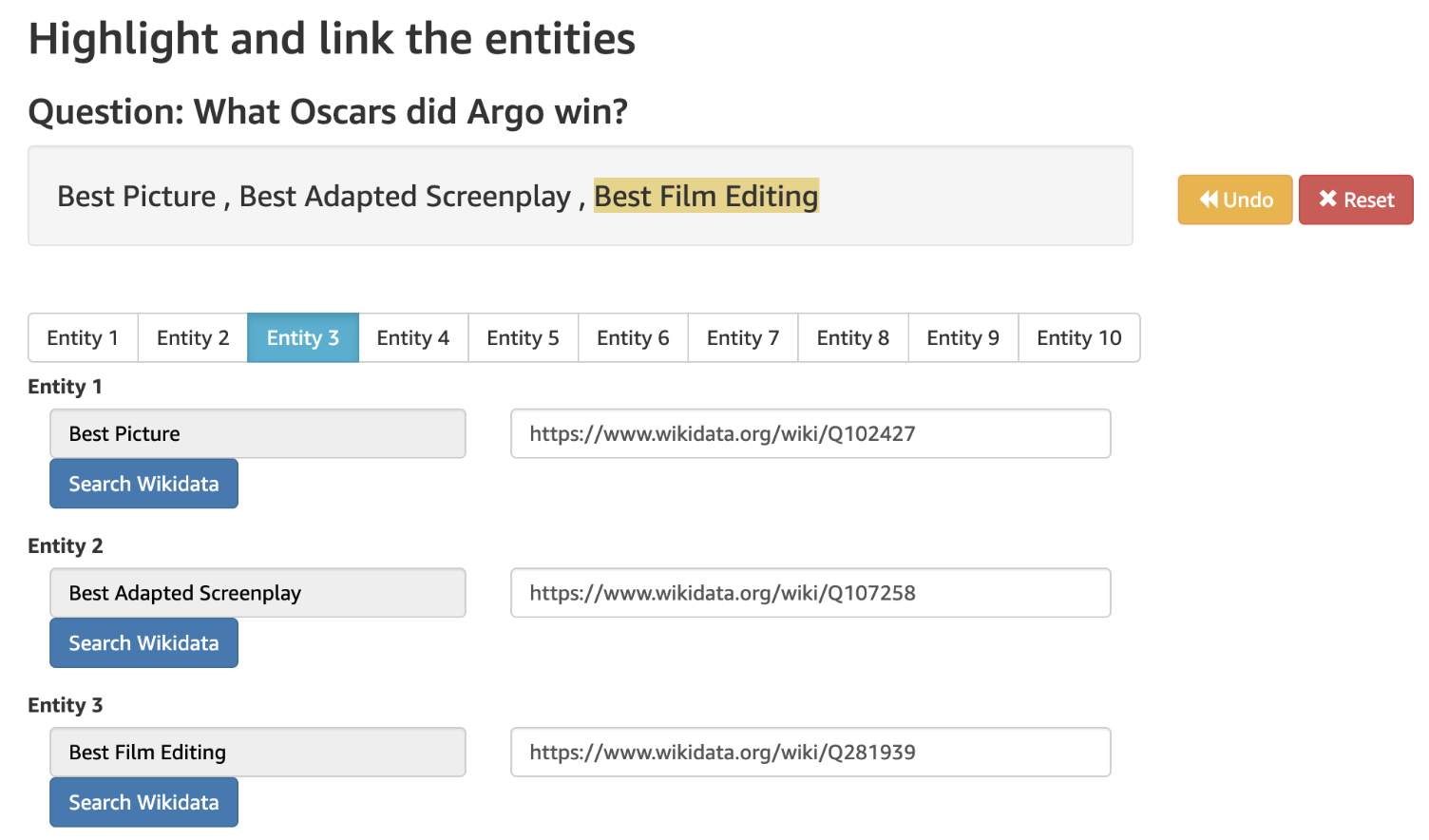
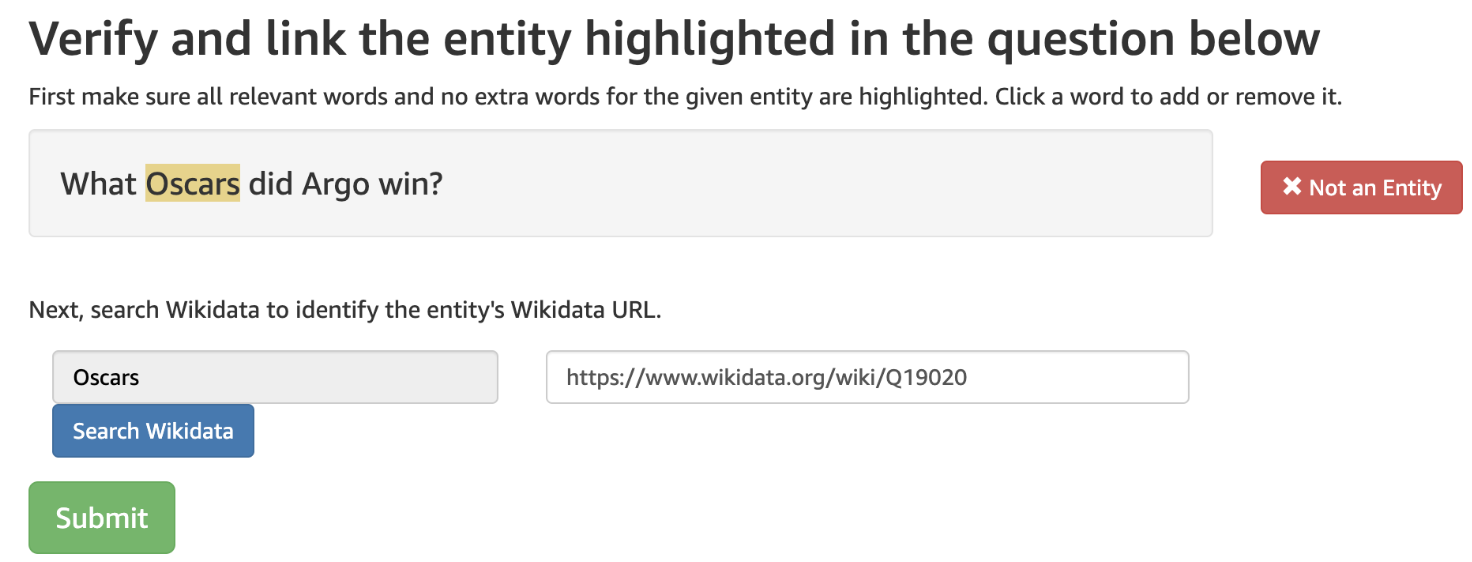
⚡ 论文:Mintaka: A Complex, Natural, and Multilingual Dataset for End-to-End Question Answering
论文时间:4 Oct 2022
领域任务:Question Answering,问答系统
论文地址:https://arxiv.org/abs/2210.01613
代码实现:https://github.com/amazon-research/mintaka
论文作者:Priyanka Sen, Alham Fikri Aji, Amir Saffari
论文简介:We introduce Mintaka, a complex, natural, and multilingual dataset designed for experimenting with end-to-end question-answering models./我们介绍了Mintaka,这是一个复杂的、自然的、多语言的数据集,旨在实验端到端的问答模型。
论文摘要:我们介绍了Mintaka,这是一个复杂的、自然的、多语言的数据集,旨在实验端到端问题回答模型。Mintaka由20,000个问题-答案对组成,这些问题-答案对以英语收集,并以Wikidata实体作为注释,然后翻译成阿拉伯语、法语、德语、印地语、意大利语、日语、葡萄牙语和西班牙语,共18万个样本。Mintaka包括8种类型的复杂问题,包括超限、交叉和多跳问题,这些问题是由人群工作者自然引出的。我们在Mintaka上运行基线,其中最好的是英语达到38%的top1命中率,多语种达到31%的top1命中率,表明现有模型有改进的余地。我们将Mintaka发布在 https://github.com/amazon-research/mintaka
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。

最后
以上就是羞涩戒指最近收集整理的关于硬刚PS?微软推出AI设计软件;一键下载多篇论文Latex源码;PyTorch教程·模型性能调优指南;电子书·机器人与感知导论 | ShowMeAI资讯日报工具&框架博文&分享数据&资源研究&论文的全部内容,更多相关硬刚PS?微软推出AI设计软件;一键下载多篇论文Latex源码;PyTorch教程·模型性能调优指南;电子书·机器人与感知导论内容请搜索靠谱客的其他文章。








发表评论 取消回复