目录
- 0 引言
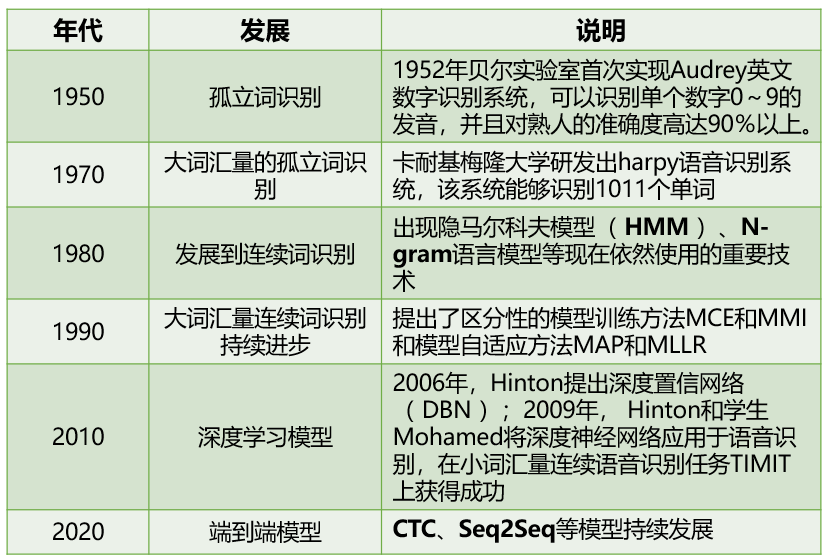
- 1 发展历程
- 2 基本原理
- 3 语言模型
- 3.1 n-gram
- 3.2 RNN
- 4 声学模型的传统模型
- 5 声学模型的深度学习模型
- 5.1 DNN
- 5.2 RNN和LSTM
- 6 声学模型的端到端模型
- 6.1 CTC
- 6.2 Seq2Seq
0 引言
这是北理计算机研究生的大数据课程的汇报作业,我负责这一部分的讲述,故通过整理这个博客来梳理一些下周一的讲演思路。
1 发展历程
2 基本原理

我录了一句自己说这句话时的音频,将这一段音频转化为声音的波形图就如下图所示。
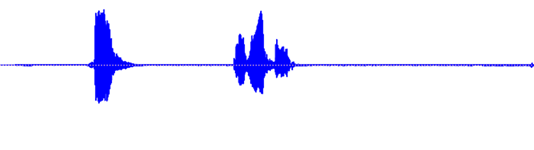
第一个波峰就是“嗨”字,后面的三个紧凑的波峰也就是剩下的三个字,这很简单。
而对这样一个波形图,为进行语音的识别需要经历三个大的步骤,分别是
- 预处理
- 声音特征提取
- 建立声学模型和语言模型
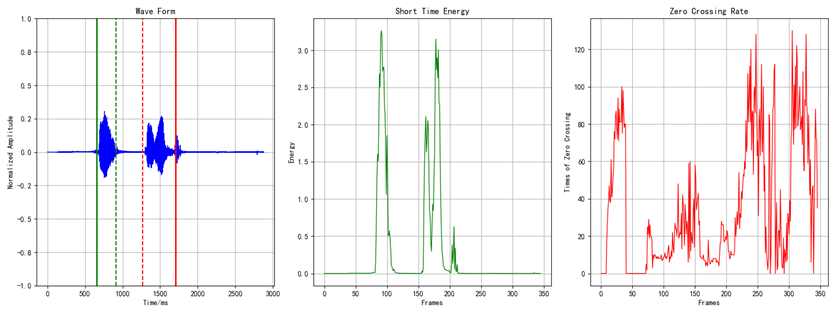
在预处理阶段,首先要做的事情叫做VAD(Voice Activity Detection),翻译过来就是语音端点检测或者说是静音抑制。
指的是从声音信号流里识别和消除长时间的静音期。
图中演示的是通过短时能量(绿)和过零率(红)来切割下“嗨大家好”声音的首尾空白。
下一步预处理的操作就是分帧。
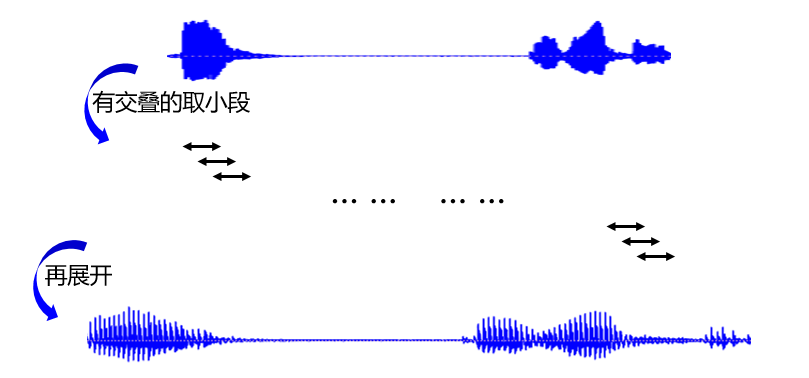
概念其实很简单,就是把刚刚的声音波形图分成一小段一小段,值得注意的是分帧时是要有交叠的;正因为如此,分帧后再展开的声音波形图比原波形图要长而且出现锯齿。
预处理阶段最重要的结束之后,再下一步就是声音特征的提取。
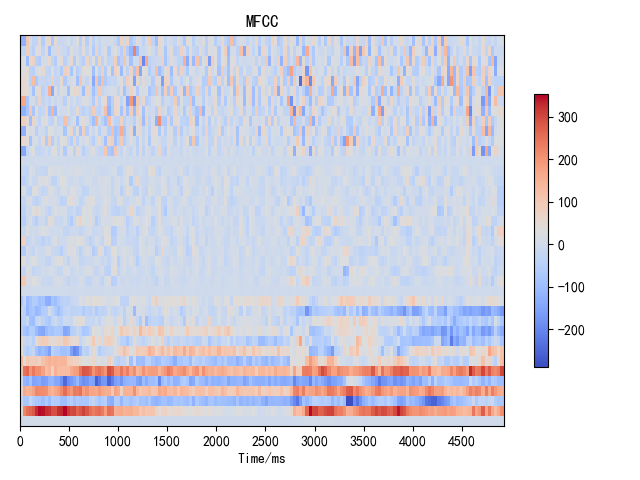
如图所示的就是将之前我说的那句“嗨,大家好”转化成MFCC特征的矩形方阵。具体转化过程会更加复杂一些,包括但不限于短时傅里叶变换、取倒谱等等。这个程序是github上找到的AcousticFeatureExtraction-master,对于声音特征的提取做的很好。
基本的事情处理结束之后,最重要也是最复杂的一步就是声学模型和语言模型的建模了。
在这一部分,只简单介绍一下这俩模型什么意思,后续会详细说明不同的模型。
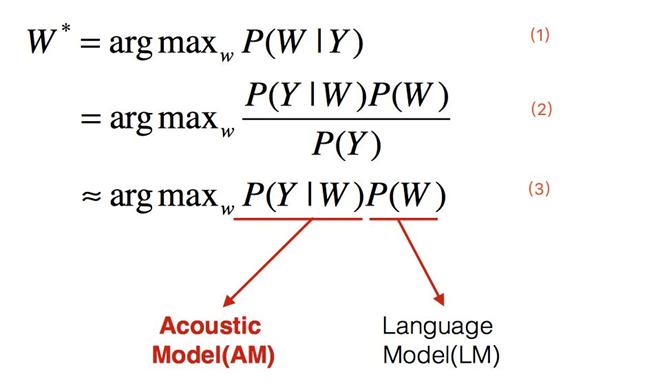
如上图的公式所示,其中W表示文字序列,Y表示语音输入。在语音文字识别当中,就是要把语音输入转化为对应的文字序列;而将这句话转化成数学表达,就是(1)式中的条件概率。将(1)通过贝叶斯定理转化成(2),又由于(2)中分母的概率对整个式子影响不大,所以约等于不考虑分母,这样就得到了(3)式。
而(3)式当中的两个,就分别是声学模型和语言模型。
声学模型是对声学、语音学、环境的变量、说话人性别、 口音等的差异的知识表示, 即给定文字之后发出这段语音的概率;而语言模型是对一组字序列构成的知识表示,即判定一个文字序列出现的概率。 声学模型一般得到语音特征到音素的映射; 语言模型一般得到词与词、词与句子的映射。
3 语言模型
首先说明一下较为好说的语言模型。

仍以刚才这段“嗨大家好”举例。
当通过声学模型建立出声音对应的发音音素之后,语言模型就要考虑这样一段发音因素对应的文字最大的概率是什么文字。比如说刚出来“hai”之后,对应的就是“嗨”,而不是“害”“还”“海”,因为在语言模型当中,单个“hai”对应“嗨”字的概率最大。其余的也同理。
更刁钻一点,同音字问题也要通过语言模型去进行处理。

比如说这一段有名的《季姬击鸡记》。
为了处理这些问题,在这里介绍两个语言模型。
3.1 n-gram

仍以这一段为例,对于“haidajiahao”,这一串词是一个个词组成的。好像是废话,但总结成数学表示就是
T是由词序列 A 1 , A 2 , A 3 , … A n A1,A2,A3,…An A1,A2,A3,…An组成的,即使得
P ( T ) = P ( A 1 A 2 A 3 … A n ) P(T)=P(A1A2A3…An) P(T)=P(A1A2A3…An)最大
P ( T ) = P ( A 1 A 2 A 3 … A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) … P ( A n ∣ A 1 A 2 … A n − 1 ) P(T)=P(A1A2A3…An)=P(A1)P(A2|A1)P(A3|A1A2)…P(An|A1A2…An-1) P(T)=P(A1A2A3…An)=P(A1)P(A2∣A1)P(A3∣A1A2)…P(An∣A1A2…An−1)
而最后一行的公式在实际运算中显然是过于苦难和繁琐了。因此,我们要引入马尔科夫假设。
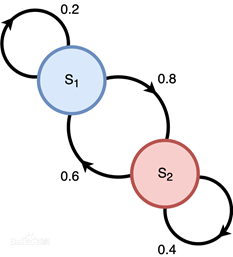
马尔科夫假设:一个item的出现概率,只与其前m个items有关
举个例子来说明的话就是,假设你一直在转圈(原地改变方向),那么你下一刻所处什么方向,只与你现在在什么方向有关,与之前的积累量无关。
上面那个圈圈图说明的就是,一个状态到另一个状态建立这种概率连接,它能否从一个状态转移到另一个状态只与当前状态有关,这样就不需要为之前众多的变化而费心了。
在语言模型中,以2-gram举例说明,之前的概率就可以简化为
P ( T ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 2 ) … P ( A n ∣ A n − 1 ) P(T)=P(A1)P(A2|A1)P(A3|A2)…P(An|An-1) P(T)=P(A1)P(A2∣A1)P(A3∣A2)…P(An∣An−1)
3.2 RNN
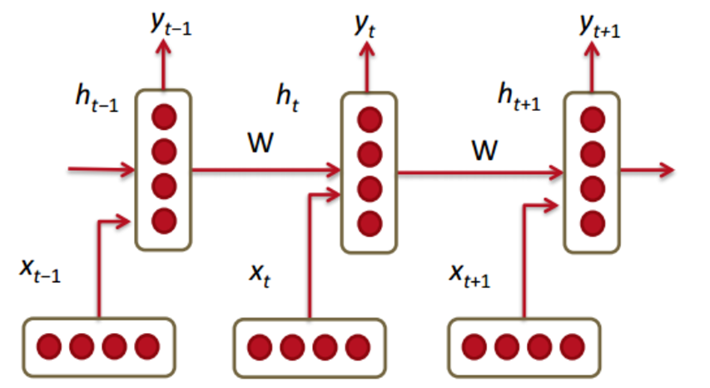
RNN(循环神经网络)也是常用的一个语言模型。当把词依次输入到网络中,每输入一个词,循环神经网络就输出截止到目前为止下一个最可能的词。在此不详细展开了。
4 声学模型的传统模型
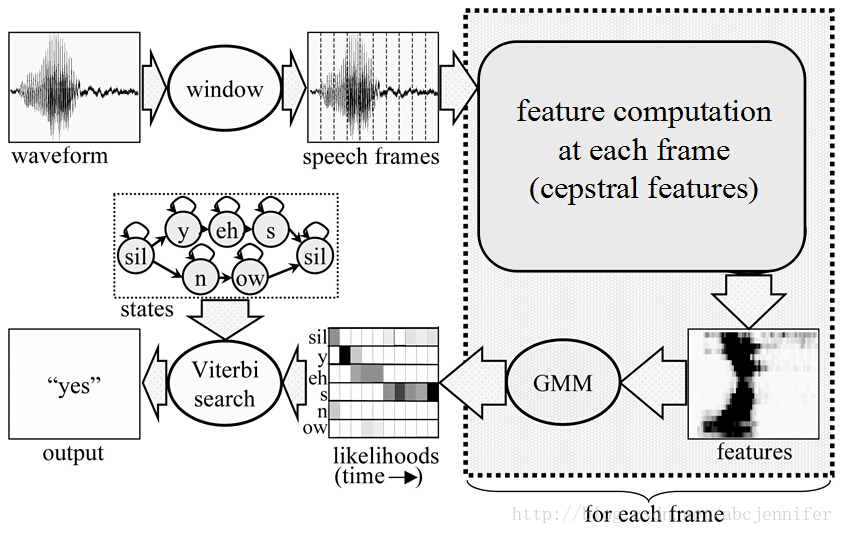
传统的声学模型一般基于GMM(高斯混合模型)和HMM(隐马尔可夫模型)。
GMM指的是将多个正态分布(高斯分布)的数据进行混合的一种概率模型。在语音识别中,可以通过高斯混合模型将先前得到的声音特征进一步转化为声音的状态。
隐马尔可夫模型是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。马尔可夫过程之前提到过,就是当下状态只与前一个或几个状态有关,与再往前的状态无关。之前得到的状态需要通过HMM来判定是否保留或跳转。
图中的viterbi是一种找寻有向无环图中最短路径的算法。声音特征再处理得到的状态会构成一个庞大的状态网络,而利用viterbi算法就可以方便的找到状态网络中的最短路径,也就是最终的文字序列。
5 声学模型的深度学习模型
5.1 DNN
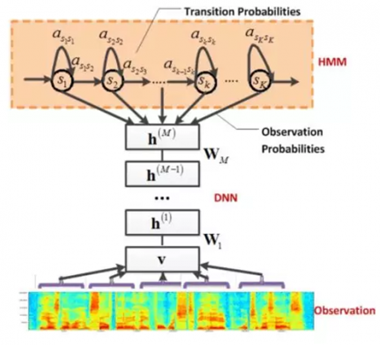
DNN实际上就是用DNN替换了GMM来对输入语音信号的观察概率进行建模。与GMM采用单帧特征作为输入不同,DNN将相邻的若干帧进行拼接来得到一个包含更多信息的输入向量。
相比于GMM-HMM,DNN-HMM具有如下优点:
- DNN不需要对声学特征所服从的分布进行假设
- DNN由于使用拼接帧,可以更好地利用上下文的信息
- DNN的训练过程可以采用随机优化算法来实现,可以接受更大的数据规模
5.2 RNN和LSTM
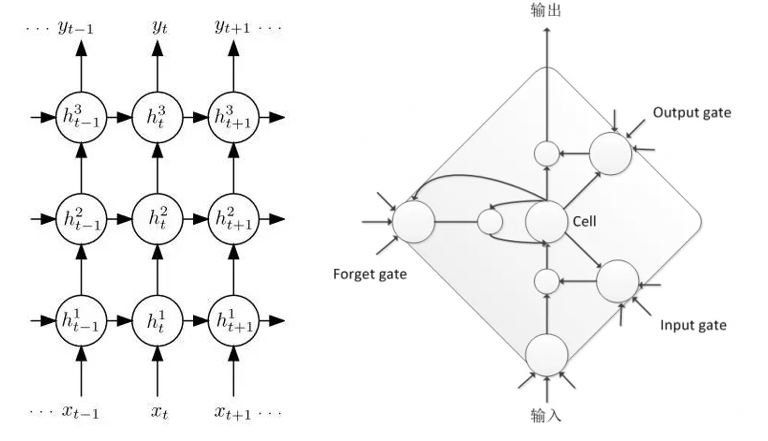
语音的协同发音现象说明声学模型需要考虑到语音帧之间的长时相关性,尽管上文中DNN-HMM通过拼帧的方式对上下文信息进行了建模,但是毕竟拼接的帧数有限,建模能力不强,因此引入了RNN(循环神经网络)增强了长时建模的能力,RNN隐层的输入除了接收前一个隐层的输出之外,还接收前一时刻的隐层输出作为当前输入,通过RNN的隐层的循环反馈,保留了长时的历史信息,大大增强了模型的记忆能力,语音的时序特性通过RNN也得到了很好的描述。但是RNN的简单结构在模型训练进行BPTT(Backpropagation Through Time)时很容易引起梯度消失/爆炸等问题,因此在RNN的基础上引入了LSTM(长短时记忆模型),LSTM是一种特殊的RNN,通过Cell以及三个门控神经元的特殊结构对长时信息进行建模,解决了RNN出现的梯度问题,实践也证明了LSTM的长时建模能力优于普通RNN。
6 声学模型的端到端模型
6.1 CTC
CTC(Connectionist temporal classification )翻译过来叫做连接时序分类,主要用于处理序列标注问题中的输入与输出标签的对齐问题。

传统的语音识别的声学模型训练,对于每一帧的数据,需要知道对应的label才能进行有效的训练,在训练数据之前需要做语音对齐的预处理。采用CTC作为损失函数的声学模型序列,不需要预先对数据对齐,只需要一个输入序列和一个输出序列就可以进行训练。CTC关心的是预测输出的序列是否和真实的序列相近,而不关心预测输出序列中每个结果在时间点上是否和输入的序列正好对齐。
CTC建模单元是音素或者字,因此它引入了Blank。对于一段语音,CTC最后输出的是尖峰的序列,尖峰的位置对应建模单元的Label,其他位置都是Blank。
6.2 Seq2Seq
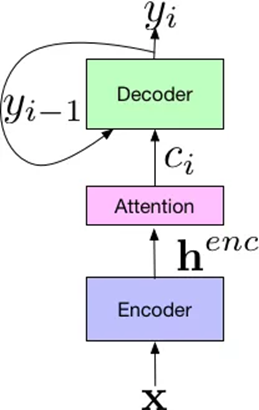
Sequence-to-Sequence方法原来主要应用于机器翻译领域。给定序列 X,输出 Y,最直白的一种办法就是延伸在机器翻译中所使用的 Seq2Seq 模型。2017年,Google将其应用于语音识别领域,取得了非常好的效果,将词错误率降低至5.6%。
如图所示,Google提出新系统的框架由三个部分组成:Encoder编码器组件,它和标准的声学模型相似,输入的是语音信号的时频特征;经过一系列神经网络,映射成高级特征henc,然后传递给Attention组件,其使用henc特征学习输入x和预测子单元之间的对齐方式,子单元可以是一个音素或一个字。最后,attention模块的输出传递给Decoder,生成一系列假设词的概率分布,类似于传统的语言模型。
最后
以上就是糟糕盼望最近收集整理的关于语音文字识别基本原理和经典综述0 引言1 发展历程2 基本原理3 语言模型4 声学模型的传统模型5 声学模型的深度学习模型6 声学模型的端到端模型的全部内容,更多相关语音文字识别基本原理和经典综述0内容请搜索靠谱客的其他文章。








发表评论 取消回复