转自:https://zhuanlan.zhihu.com/p/53264756
大家好!又到了每周一狗熊会的深度学习时间了。在上一讲中,小编给大家介绍了经典的 seq2seq,以及著名的注意力模型,并且小编在这些理论的基础上给出一个基于seq2seq和注意力模型的机器翻译实例。本讲小编将和大家继续将目光放宽,对广义的自然语言处理应用领域之一的语音识别进行一次简单而又相对完整技术综述。
1
概述
自动语音识别(Automatic Speech Recognition,ASR),也可以简称为语音识别。说新领域也有点夸张,因为语音识别可以作为一种广义的自然语言处理技术,是用于人与人、人与机器进行更顺畅的交流的技术。语音识别目前已使用在生活的各个方面:手机端的语音识别技术,比如苹果的 siri;智能音箱助手,比如阿里的天猫精灵,还有诸如科大讯飞一系列的智能语音产品等等。
为了能够更加清晰的定义语音识别的任务,我们先来看一下语音识别的输入和输出都是什么。大家都知道,声音从本质是一种波,也就是声波,这种波可以作为一种信号来进行处理,所以语音识别的输入实际上就是一段随时间播放的信号序列,而输出则是一段文本序列。

图1 语音识别的输入与输出
将语音片段输入转化为文本输出的过程就是语音识别。一个完整的语音识别系统通常包括信息处理和特征提取、声学模型、语言模型和解码搜索四个模块。语言识别系统如下图所示:
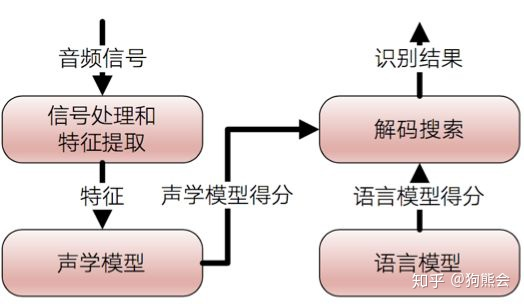
图2 语音识别系统
信号处理和特征提取可以视作音频数据的预处理部分,一般来说,一段高保真、无噪声的语言是非常难得的,实际研究中用到的语音片段或多或少都有噪声存在,所以在正式进入声学模型之前,我们需要通过消除噪声和信道增强等预处理技术,将信号从时域转化到频域,然后为之后的声学模型提取有效的特征向量。接下来声学模型会将预处理部分得到的特征向量转化为声学模型得分,与此同时,语言模型,也就是我们前面在自然语言处理中谈到的类似 n-gram 和 RNN 等模型,会得到一个语言模型得分,最后解码搜索阶段会针对声学模型得分和语言模型得分进行综合,将得分最高的词序列作为最后的识别结构。这便是语音识别的一般原理。

图3 安德雷.马尔可夫
因为语音识别相较于一般的自然语言处理任务特殊之处就在于声学模型,所以语言识别的关键也就是信号处理预处理技术和声学模型部分。在深度学习兴起应用到语言识别领域之前,声学模型已经有了非常成熟的模型体系,并且也有了被成功应用到实际系统中的案例。比如说经典的高斯混合模型(GMM)和隐马尔可夫模型(HMM)等。神经网络和深度学习兴起以后,循环神经网络、LSTM、编码-解码框架、注意力机制等基于深度学习的声学模型将此前各项基于传统声学模型的识别案例错误率降低了一个 level,所以基于深度学习的语音识别技术也正在逐渐成为语音识别领域的核心技术。
语音识别发展到如今,无论是基于传统声学模型的语音识别系统还是基于深度学习的识别系统,语音识别的各个模块都是分开优化的。但是语音识别本质上是一个序列识别问题,如果模型中的所有组件都能够联合优化,很可能会获取更好的识别准确度,因而端到端的自动语音识别是未来语音识别的一个最重要的发展方向。
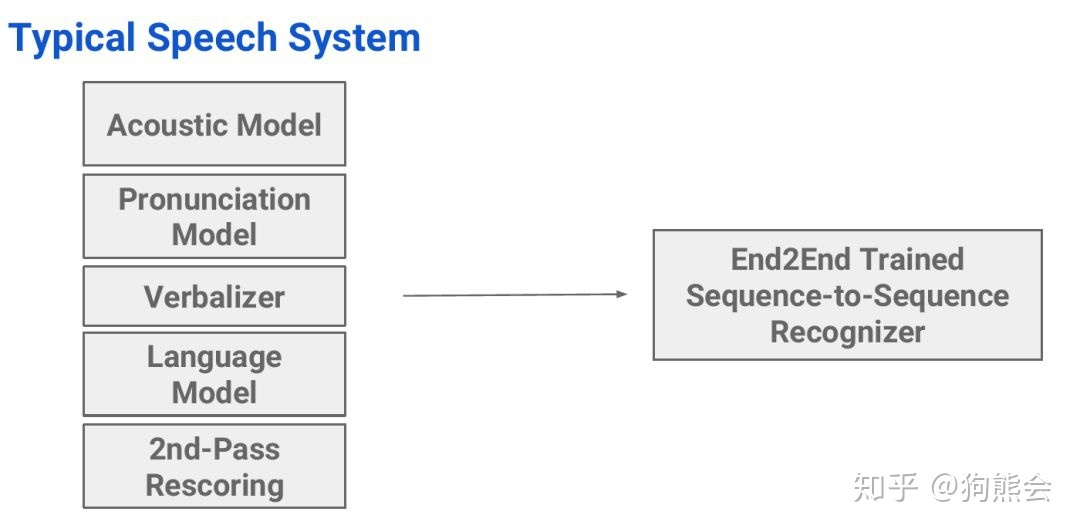
图4 End2End Speech Recognizer
所以,这一讲主要内容的介绍顺序就是先给大家介绍声波信号处理和特征提取等预处理技术,然后介绍 GMM 和 HMM 等传统的声学模型,其中重点解释语音识别的技术原理,之后后对基于深度学习的声学模型进行一个技术概览,对当前深度学习在语音识别领域的主要技术进行简单了解,最后对未来语音识别的发展方向——端到端的语音识别系统进行了解。
2
信号处理与特征提取
因为声波是一种信号,具体我们可以将其称为音频信号。原始的音频信号通常由于人类发声器官或者语音采集设备所带来的静音片段、混叠、噪声、高次谐波失真等因素,一定程度上会对语音信号质量产生影响。所以在正式使用声学模型进行语音识别之前,我们必须对音频信号进行预处理和特征提取。
最初始的预处理工作就是静音切除,也叫语音激活检测(Voice Activity Detection, VAD) 或者语音边界检测。目的是从音频信号流里识别和消除长时间的静音片段,在截取出来的有效片段上进行后续处理会很大程度上降低静音片段带来的干扰。除此之外,还有许多其他的音频预处理技术,大家可以找来信号处理相关的资料进行阅读,笔者这里不多说。
然后就是特征提取工作。音频信号中通常包含着非常丰富的特征参数,不同的特征向量表征着不同的声学意义,从音频信号中选择有效的音频表征的过程就是语音特征提取。常用的语音特征包括线性预测倒谱系数(LPCC)和梅尔频率倒谱系数(MFCC),其中 LPCC 特征是根据声管模型建立的特征参数,是对声道响应的特征表征。而 MFCC 特征是基于人的听觉特征提取出来的特征参数,是对人耳听觉的特征表征。所以,在对音频信号进行特征提取时通常使用 MFCC 特征。
MFCC 主要由预加重、分帧、加窗、快速傅里叶变换(FFT)、梅尔滤波器组、离散余弦变换几部分组成,其中FFT与梅尔滤波器组是 MFCC 最重要的部分。一个完整的 MFCC 算法包括如下几个步骤:
- 快速傅里叶变换(FFT);
- 梅尔频率尺度转换;
- 配置三角形滤波器组并计算每一个三角形滤波器对信号幅度谱滤波后的输出;
- 对所有滤波器输出作对数运算,再进一步做离散余弦变换(DTC),即可得到MFCC。
图5 傅里叶变换
实际的语音研究工作中,也不需要我们再从头构造一个 MFCC 特征提取方法,Python 为我们提供了 pyaudio 和 librosa 等语音处理工作库,可以直接调用 MFCC 算法的相关模块快速实现音频预处理工作。
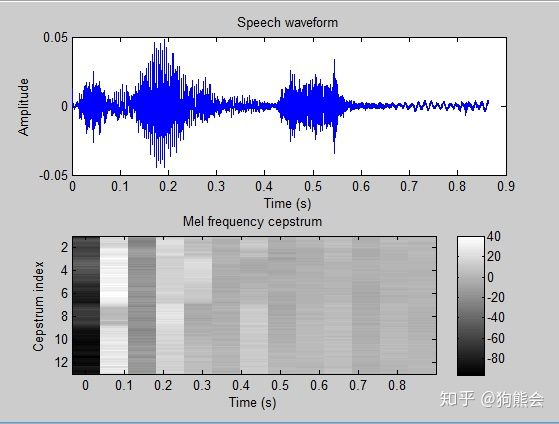
图6 MFCC
过去在语音识别上所取得成果证明 MFCC 是一种行之有效的特征提取方法。但随着深度学习的发展,受限的玻尔兹曼机(RBM)、卷积神经网络(CNN)、CNN-LSTM-DNN(CLDNN)等深度神经网络模型作为一个直接学习滤波器代替梅尔滤波器组被用于自动学习的语音特征提取中,并取得良好的效果。
3
传统声学模型
在经过语音特征提取之后,我们就可以将这些音频特征进行进一步的处理,处理的目的是找到语音来自于某个声学符号(音素)的概率。这种通过音频特征找概率的模型就称之为声学模型。在深度学习兴起之前,混合高斯模型(GMM)和隐马尔可夫模型(HMM)一直作为非常有效的声学模型而被广泛使用,当然即使是在深度学习高速发展的今天,这些传统的声学模型在语音识别领域仍然有着一席之地。所以,作为传统声学模型的代表,我们就简单介绍下 GMM 和 HMM 模型。
所谓高斯混合模型(Gaussian mixture model,GMM),就是用混合的高斯随机变量的分布来拟合训练数据(音频特征)时形成的模型。原始的音频数据经过短时傅里叶变换或者取倒谱后会变成特征序列,在忽略时序信息的条件下,这种序列非常适用于使用 GMM 进行建模。
图7 高斯混合分布
如果一个连续随机变量服从混合高斯分布,其概率密度函数形式为:
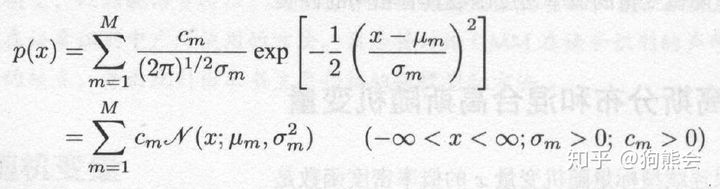
图8 高斯混合分布概率密度函数
在实际的 GMM 训练中,通常采用 EM 算法来进行迭代优化,以求取GMM中的加权系数及各个高斯函数的均值与方差等参数。
GMM 作为一种基于傅里叶频谱语音特征的统计模型,在传统语音识别系统的声学模型中发挥了重要的作用。其劣势在于不能考虑语音顺序信息,高斯混合分布也难以拟合非线性或近似非线性的数据特征。所以,当状态这个概念引入到声学模型的时候,就有了一种新的声学模型——隐马尔可夫模型(Hidden Markov model,HMM)。
在随机过程领域,马尔可夫过程和马尔可夫链向来有着一席之地。当一个马尔可夫过程含有隐含未知参数时,这样的模型就称之为隐马尔可夫模型。HMM 的核心概念是状态,状态本身作为一个离散随机变量,马尔可夫链的每一个状态上都增加了不确定性或者统计分布使得 HMM 成为了一种双随机过程。
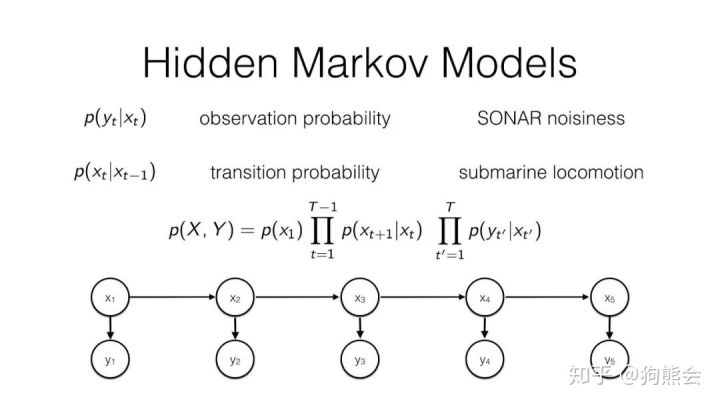
图9 隐马尔可夫模型
HMM 的主要内容包括参数特征、仿真方法、参数的极大似然估计、EM估计算法以及维特比状态解码算法等细节知识,笔者将在手动实现机器学习算法系列中详细介绍,本篇作为综述这里不做详细的展开。
4
基于深度学习的声学模型
一提到神经网络和深度学习在语音识别领域的应用,可能我们的第一反应就是循环神经网络 RNN 模型以及长短期记忆网络 LSTM 等等。实际上,在语音识别发展的前期,就有很多将神经网络应用于语音识别和声学模型的应用了。
最早用于声学建模的神经网络就是最普通的深度神经网络(DNN),GMM 等传统的声学模型存在音频信号表征的低效问题,但 DNN 可以在一定程度上解决这种低效表征。但在实际建模时,由于音频信号是时序连续信号,DNN 则是需要固定大小的输入,所以早期使用 DNN 来搭建声学模型时需要一种能够处理语音信号长度变化的方法。一种将 HMM 模型与 DNN 模型结合起来的 DNN-HMM 混合系统颇具有效性。
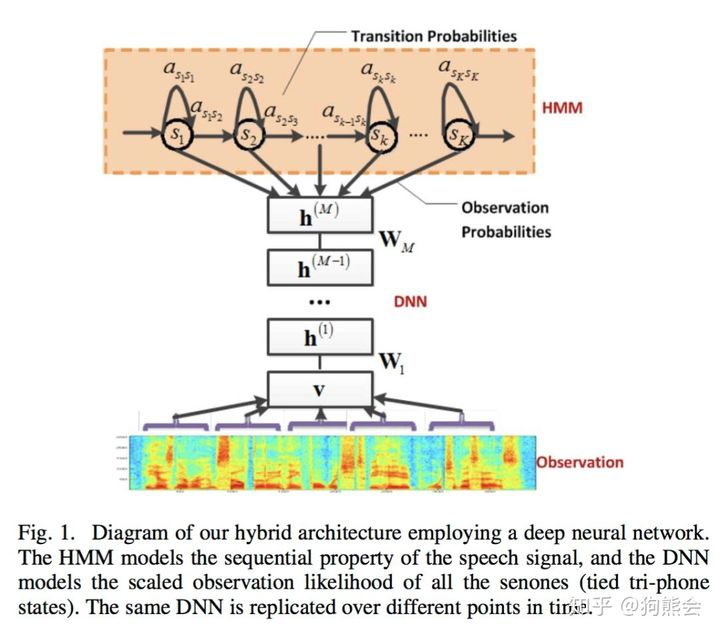
图10 DNN-HMM框架
在上图这个框架中,HMM 用来描述语音信号的动态变化,DNN 则是用来估计观察特征的概率。在给定声学观察特征的条件下,我们可以用 DNN 的每个输出节点来估计 HMM 某个状态的后验概率。由于 DNN-HMM 训练成本不高而且相对较高的识别概率,所以即使是到现在在语音识别领域仍然是较为常用的声学模型。
除了 DNN 之外,经常用于计算机视觉的 CNN 也可以拿来构建语音声学模型。当然,CNN 也是经常会与其他模型结合使用。CNN 用于声学模型方面主要包括 TDNN、CNN-DNN 框架、DFCNN、CNN-LSTM-DNN(CLDNN)框架、CNN-DNN-LSTM(CDL)框架、逐层语境扩展和注意 CNN 框架(LACE)等等。这么多基于 CNN 的混合模型框架都在声学模型上取得了很多成果,这里小编仅挑两个进行简单阐述。
TDNN是最早基于 CNN 的语音识别方法,TDNN 会沿频率轴和时间轴同时进行卷积,因此能够利用可变长度的语境信息。TDNN 用于语音识别分为两种情况,第一种情况下:只有TDNN,很难用于大词汇量连续性语音识别(LVCSR),原因在于可变长度的表述(utterance)与可变长度的语境信息是两回事,在 LVCSR 中需要处理可变长度表述问题,而 TDNN 只能处理可变长度语境信息;第二种情况:TDNN-HMM 混合模型,由于HMM能够处理可变长度表述问题,因而该模型能够有效地处理 LVCSR 问题。
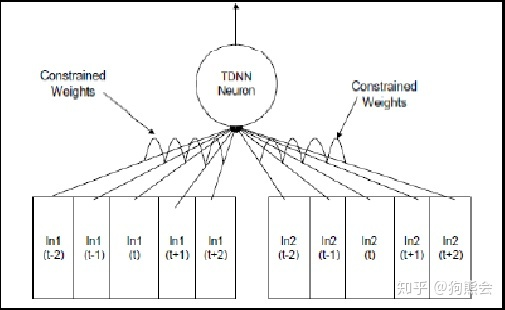
图11 TDNN模型
DFCNN 的全称叫做全序列卷积神经网络(deep fully convolutional neural network),是由国内语音识别领域的翘楚科大讯飞于2016年提出的一种语音识别框架。DFCNN 先对时域的语音信号进行傅里叶变换得到语音的语谱图,DFCNN 直接将一句语音转化成一张图像作为输入,输出单元则直接与最终的识别结果(比如音节或者汉字)相对应。DFCNN 的结构中把时间和频率作为图像的两个维度,通过较多的卷积层和池化(pooling)层的组合,实现对整句语音的建模。DFCNN 的原理是把语谱图看作带有特定模式的图像,而有经验的语音学专家能够从中看出里面说的内容。
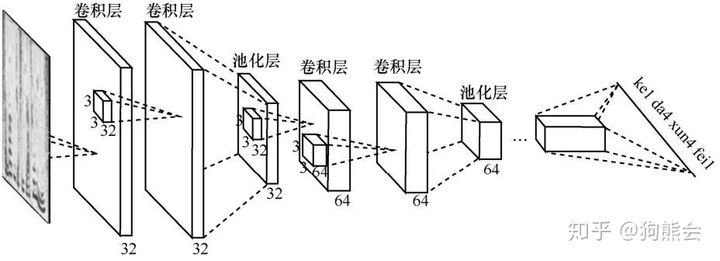
图12 DFCNN模型
最后就是循环神经网络 RNN,其中更多是 LSTM 网络。音频信号具有明显的协同发音现象,因此必须考虑长时相关性。由于循环神经网络RNN具有更强的长时建模能力,使得 RNN 也逐渐替代 DNN 和 CNN 成为语音识别主流的建模方案。比如说常见的基于 seq2seq 的编码-解码框架就是一种基于 RNN 的模型。关于 RNN 在语音识别和声学模型中的应用小编不做过多解释,感兴趣的朋友可以自行查找相关资料了解。
长期的研究和实践证明:基于深度学习的声学模型要比传统的基于浅层模型的声学模型更适合语音处理任务。语音识别的应用环境常常比较复杂,选择能够应对各种情况的模型建模声学模型是工业界及学术界常用的建模方式。但单一模型都有局限性。HMM能够处理可变长度的表述,CNN能够处理可变声道,RNN/CNN能够处理可变语境信息。声学模型建模中,混合模型由于能够结合各个模型的优势,是目前乃至今后一段时间内声学建模的主流方式。
5
端到端的语音识别系统简介
无论是 GMM 和 HMM 这样的传统声学模型,还是基于深度学习的声学模型,它们对于整个语音识别系统都是分开优化的,但是语音识别本质上是一个序列识别问题,如果模型中的所有组件都能够联合优化,很可能会获取更好的识别准确度,所以我们需要一种端到端(End2End)的语音识别处理系统。
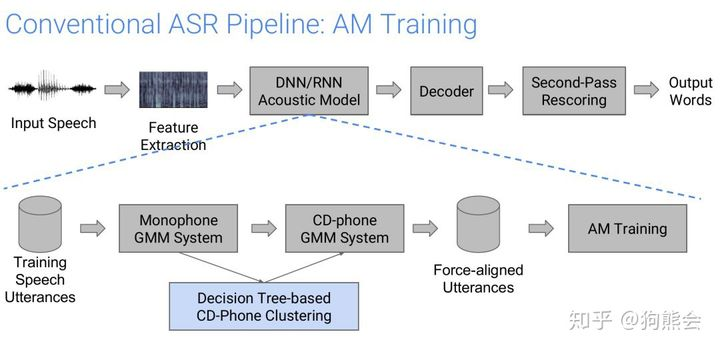
传统的语音识别系统中的声学模型训练:
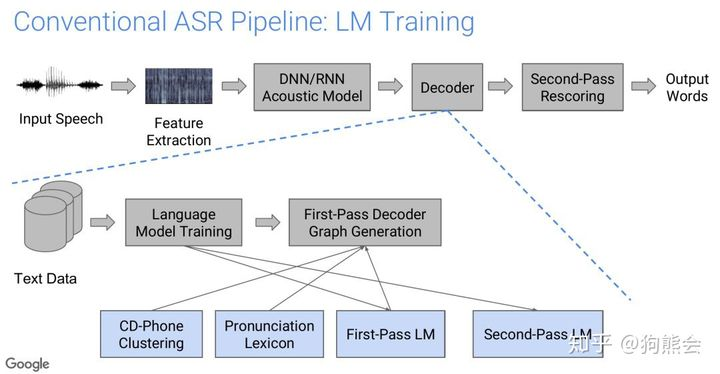
传统的语音识别系统中的语言模型训练:
谷歌的 Listen-Attend-Spell (LAS) 端到端语音识别系统:
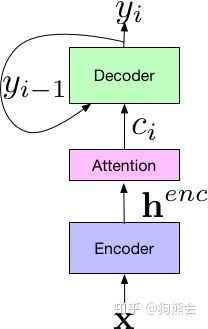
关于端到端的语音识别系统,小编做的调研程度有限,更多的内容需要后续不断的学习和实践,也感谢读者朋友有做语音识别方向的朋友给出一些建设性的意见。
以上便是本讲内容。
![]()
在本节内容中,小编和大家按照5个小部分给大家介绍了语音识别的概念和技术。先是对语音识别做了一个概述,然后介绍了声波信号处理和特征提取等预处理技术,之后介绍 GMM 和 HMM 等传统的声学模型,其中重点解释语音识别的技术原理,之后对基于深度学习的声学模型进行一个技术概览,对当前深度学习在语音识别领域的主要技术进行简单了解,最后对未来语音识别的发展方向——端到端的语音识别系统进行了简单了解。咱们下一期见!
![]()
【参考资料】
Supervised Sequence Labelling with Recurrent
https://www.zhihu.com/question/20398418/answer/18080841
俞栋 邓力 解析深度学习 语音识别实践
http://www.eeboard.com/news/yuyinshibie/
https://ai.googleblog.com/2017/12/improving-end-to-end-models-for-speech.html
最后
以上就是任性御姐最近收集整理的关于语音识别——一份简短的技术综述的全部内容,更多相关语音识别——一份简短内容请搜索靠谱客的其他文章。








发表评论 取消回复